Ask, Don't Judge: Binary Questions for Interpretable LLM Evaluation and Self-Improvement
Abstract: Evaluating LLM outputs remains a major bottleneck in NLP: human evaluation is expensive and slow, lexical metrics correlate poorly with human judgments on open-ended generation, and holistic LLM judges often produce opaque scores that are hard to debug. We propose BINEVAL, a framework that decomposes evaluation criteria into atomic binary questions and aggregates the resulting verdicts into interpretable, multi-dimensional scores. Given a task prompt, a meta-prompt generates fine-grained evaluation questions, and an LLM answers them independently for each output, yielding transparent question-level feedback together with calibrated overall scores. This decomposition makes evaluation easier to inspect, easier to diagnose, and directly usable for prompt improvement. Across SummEval, Topical-Chat, and QAGS, BINEVAL matches or outperforms strong baselines including UniEval and G-Eval, with especially strong results on factual consistency benchmarks such as QAGS. Beyond competitive correlation with human judgments, BINEVAL better matches human score distributions and avoids the ceiling effects common in prior LLM judges, leading to better discrimination between borderline and clearly flawed outputs. We further show that the same question-level feedback supports iterative prompt optimization, improving evaluator prompts on summarization and generation prompts on IFBench under both self-update and cross-model update settings. Overall, BINEVAL provides a task-agnostic, training-free, and interpretable evaluation framework that combines strong empirical performance with practical diagnostic and optimization value.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine you’re grading a classmate’s book report. If you just give one overall score like “7/10,” it’s hard to say what went right or wrong. Was it the facts, the writing, or the relevance? This paper says: don’t give one vague judgment—ask lots of small, clear yes/no questions and add up the answers.
The authors introduce BinEval, a way to judge AI-written text (like summaries or chat replies) by breaking the job into tiny checks, such as “Are all names correct?” or “Does the answer stay on topic?” Each tiny check is answered yes/no, and those answers are combined into easy-to-understand scores. This makes the grading more transparent and more helpful for improving the AI.
The main goals and questions
The paper focuses on three big goals, written here in everyday language:
- Can we evaluate AI writing using many small yes/no questions so the results are clearer and easier to trust?
- Does this yes/no checklist method match human opinions better than older methods?
- Can this detailed feedback help us improve prompts (the instructions we give to AIs) so both the “judge AI” and the “writer AI” get better over time?
How the method works (with simple analogies)
Think of BinEval as turning a messy task (“Is this good?”) into a checklist:
- Turn one big task into requirements
- The system reads the task (for example, “Summarize this article.”) and lists what matters: accuracy, relevance, clarity, grammar, etc. This is like making a rubric for a book report.
- Write tiny yes/no questions for each requirement
- For each requirement, it makes small, specific questions, such as:
- “Does the summary include the main point?”
- “Are important names and numbers correct?”
- “Are there grammar mistakes?”
- Each question is simple enough to check on its own.
- For each requirement, it makes small, specific questions, such as:
- Let an AI judge answer each question
- An evaluator AI reads the original text and the AI’s output, answers each yes/no question, and explains why.
- The system then computes scores per category (like accuracy or writing quality) by counting how many “yes” answers you got in that category. It also combines everything into one overall score.
- Use the feedback to improve prompts
- If two different judge AIs disagree on certain yes/no questions, the system learns “lessons” from those disagreements and updates the judge’s instructions to be clearer and fairer.
- The same idea can improve the writer AI: when it fails certain questions (say, “kept the right format”), those failures are turned into concrete tips to rewrite its prompt so it does better next time.
Key terms explained simply:
- “Prompt”: the instructions given to the AI (like the assignment sheet).
- “Evaluator”: an AI that checks the work (like a grader).
- “Binary/yes-no questions”: tiny checks that are clear and specific (like checkboxes on a rubric).
- “Dimensions”: the main categories you care about (accuracy, relevance, clarity/fluency, coherence).
What they tested and found (and why it matters)
They ran BinEval on three well-known evaluation tasks:
- SummEval: judging the quality of summaries (how coherent, factual, fluent, and relevant they are).
- Topical-Chat: judging the quality of chat replies (naturalness, engagingness, etc.).
- QAGS: specifically checking if summaries are factually consistent (no made-up facts).
What they found:
- Better match with humans, especially on facts
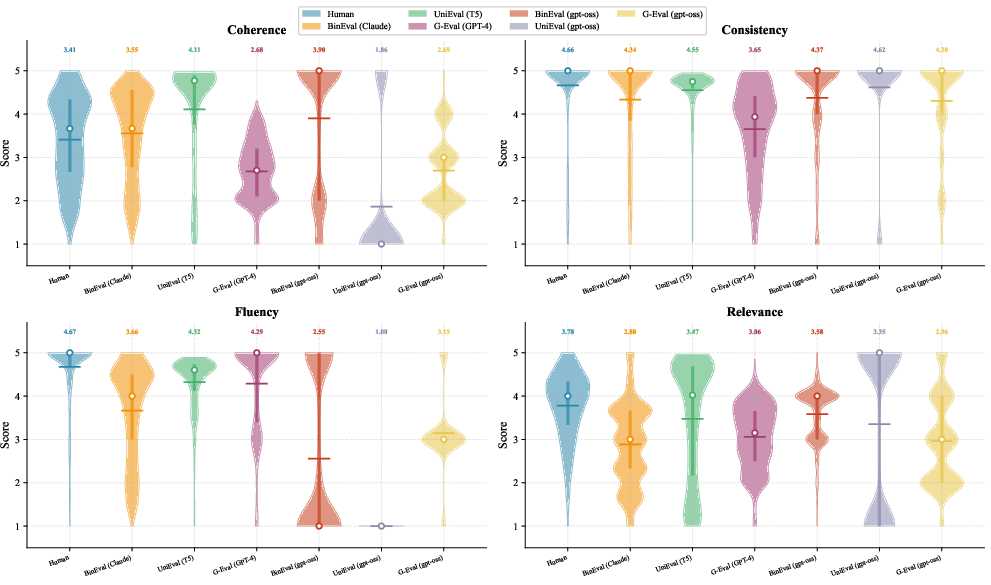
- BinEval’s scores line up with human ratings as well as—or better than—popular alternatives. It’s especially strong on factual consistency (catching made-up or wrong details), which is a common problem in AI writing.
- More useful score shapes
- Instead of giving everything high marks (a “ceiling effect”), BinEval spreads scores out more like humans do, making it easier to tell “okay” from “great” and “bad.”
- Clearer debugging
- Because each score comes from many tiny questions with explanations, you can see exactly what went wrong (e.g., “wrong number,” “off-topic sentence,” “misattributed quote”). That makes fixing issues much easier than a single mysterious score.
- Helps improve prompts
- For judge AIs (evaluators): Using disagreement between a strong judge and a weaker judge, BinEval updates the weaker judge’s prompt to be more consistent and fair. This improved alignment on several summary quality categories.
- For writer AIs (generators): Turning failed yes/no checks into prompt tips helped in tasks like keeping the right format or sentence structure. It helped less on tasks that need precise counting or ratios (things that are hard for text models to do reliably by just changing instructions).
A simple example of why this works:
- A summary might “sound right” but quietly get facts wrong (like mixing up who said what). A single overall score can miss that. A checklist that asks, “Are names and attributions correct?” will catch the mistake and show you where it happened.
Why this approach is powerful (in everyday logic)
- It simplifies a big, fuzzy task
- Many tiny checks are easier than one giant judgment—like grading with a detailed rubric rather than a gut feeling.
- It covers different failure types
- Different questions catch different mistakes (e.g., grammar vs. relevance vs. facts). Together, they see more problems.
- It averages out noise
- If some questions are tricky, using many of them reduces random errors, giving a steadier overall score.
Limits to keep in mind
- Not all qualities break down nicely
- Some things, like “relevance,” can be holistic. If you over-slice them into too many tiny checks, you can become unfairly strict.
- It’s slower and costs more compute
- Asking lots of questions takes more AI calls than asking for a single score.
- It depends on good questions
- If the checklist misses something important, the score will miss it too.
- Prompts can’t fix everything
- Clearer instructions help with structure and style. But tasks like exact counting or ratio enforcement are still hard for text models to execute perfectly just by rewording prompts.
What this means going forward
- More transparent AI grading
- Instead of a black-box score, you get a checklist with reasons. That’s better for trust, debugging, and learning.
- Faster improvement cycles
- Because the feedback is specific, both judges and writers (AIs) can be improved by targeting the exact weaknesses shown by failed questions.
- Safer, more reliable AI systems
- This approach is especially useful for tasks where facts matter (news summaries, reports, answers based on documents). It helps reduce subtle mistakes that are easy to miss with one-score judges.
In short, “Ask, don’t judge” turns evaluation into a set of simple questions. That makes AI assessment more honest, more helpful, and, in many cases, more accurate—especially when facts and precision matter.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future work:
- Calibration and aggregation: The method assumes a linear mapping from fraction of “yes” answers to overall quality; no study of learned or non-linear aggregators, per-question weights, or per-dimension weights tuned to human labels.
- Question-set design and selection: No principled procedure to generate, prune, or weight binary questions (e.g., optimizing coverage vs. redundancy); lacks ablations on how the number and content of questions affect performance–cost trade-offs.
- Comparability and stability of question sets: It is unclear whether questions are fixed per task or vary per instance; effects on cross-system comparability, fairness, and score stability when question sets differ are not evaluated.
- Per-question validity and fidelity: No ground-truth, item-level evaluation of binary answers (precision/recall) or of explanation faithfulness; lacks datasets with labeled sub-criteria to measure if the binary decisions and rationales are correct.
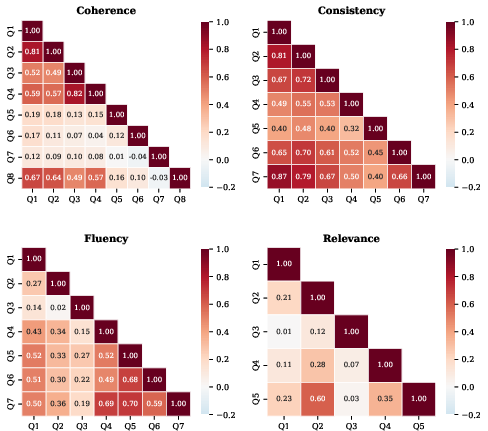
- Inter-question dependence and double counting: Correlations among questions are observed but not handled; there is no method to decorrelate, cluster, or adjust for dependence to avoid double-counting closely related checks.
- Relevance decomposition failure mode: Over-decomposition makes relevance too strict; no strategy to detect or mitigate over-strictness (e.g., hybrid holistic+binary signals, learned strictness calibration, or adaptive granularity).
- Robustness to gaming and Goodhart’s law: No tests showing whether generators can optimize to “pass” fixed binary checks while degrading human-perceived quality; lacks adversarial or controlled studies with rotating or adversarial question sets.
- Prompt-injection and security: No evaluation of whether evaluated outputs can manipulate the evaluator or note-taker (e.g., embedded instructions) to flip binary decisions or corrupt prompt updates.
- Cross-model prompt update risks: The procedure aligns a target to a single source judge, risking propagation of source biases; no safeguards or objective that preserves human alignment during alignment-to-source, and no convergence analysis.
- Methodological leakage: Evaluator prompt updates are “early-stopped on test performance,” which risks overfitting; a proper validation split and out-of-domain test set are needed to assess generalization.
- Fragility and prompt bloat: Iterative updates degrade after a few iterations; no mechanisms (e.g., regularization, mutation budgets, revert/rollback, hierarchical prompts, or constraint solvers) to prevent instruction bloat and drift.
- Capability vs. promptability boundary: IFBench results show instruction tweaks can’t fix computational constraints (count/ratio); no integration with stronger mechanisms (tool use, constrained decoding, planners, or external checkers) to overcome capability limits.
- Efficiency and cost characterization: The framework increases calls and token usage, but there is no quantitative analysis of latency, tokens, or cost; no exploration of batching, caching, question reuse, or early-exit to reduce overhead.
- Stability and reproducibility: Only two runs at temperature 0 are reported; no analysis of run-to-run variance, seed sensitivity, temperature effects, or consistency of generated questions/answers across runs.
- Breadth of benchmarks: Evaluations are limited to English news summarization, dialogue, and QAGS; no tests on multilingual settings, scientific/technical domains, code/math reasoning, safety/toxicity, long-context, or multi-modal tasks.
- Multi-turn and agentic settings: The approach is not tested on multi-step agent tasks where state and temporal dependencies matter; no design for stateful question sets or cross-turn consistency checks.
- Human-centered evaluation of interpretability: While explanations are produced, there is no user study assessing whether question-level feedback is actually more actionable for developers (e.g., time-to-fix, perceived utility).
- Bias and fairness audits: No analysis of demographic, stylistic, or dialectal biases in binary decisions; no tests for judge biases (position/verbosity/self-enhancement) in the decomposed setting or debiasing strategies.
- Alternative and stronger baselines: No comparison to fact-focused metrics like FActScore/QAFactEval, or to strong prompt-optimization baselines (OPRO, APE, DSPy, MIPRO); limits the strength of empirical claims.
- Aggregation across dimensions: Overall scores average dimensions uniformly; no study of learned inter-dimension weights, non-linear aggregation, or dependency modeling across dimensions to better match human judgments.
- Confidence and uncertainty: Binary answers lack calibrated probabilities or “uncertain” states; no exploration of probabilistic judgments, confidence-weighted aggregation, or uncertainty propagation to scores.
- Sensitivity to content complexity: No analysis of performance as a function of input length, number of entities, or paraphrastic variation; robustness to long/complex documents and heavy rewording is untested.
- Dependence on model backbones: Results show strong dependence on evaluator backbone (Claude vs. gpt-oss); no systematic study across a range of open-source sizes/families or strategies to maintain performance under constrained models.
- Question regeneration policy: Gains depend on regenerating questions, but policies for when/how to regenerate, and the impact of changing the question set on longitudinal comparability, are unspecified.
- Tool-augmented answering: The evaluator relies purely on the LLM; no exploration of retrieval, fact-checkers, or verifiers to improve binary-answer accuracy on factual checks.
- Code, prompts, and reproducibility: The paper does not indicate releasing code, prompts, question banks, or seeds; replicability and exact meta-prompt details remain unclear.
Practical Applications
Immediate Applications
The following applications can be deployed today with current LLMs and the BinEval framework as described in the paper. Each item notes candidate sectors, suggested tools/workflows, and key assumptions or dependencies.
- Interpretable quality gates for LLM outputs in production
- Sectors: software, customer support, knowledge management, search
- Use case: Gate or approve model outputs (e.g., summaries, answers, chat replies) by decomposing evaluation into binary checks for coherence, factuality/consistency, fluency, and relevance. Failures trigger rejection, revision, or fallback workflows.
- Tools/workflows: A “BinEval scoring service” that generates questions via a meta-prompt, runs per-question evaluations, aggregates per-dimension scores, and stores question-level verdicts/explanations; integrate with CI/CD for prompts and model updates; logging/telemetry dashboards.
- Assumptions/dependencies: Requires access to strong evaluator LLMs for best alignment (e.g., Claude-/GPT-4-class); higher compute costs due to multiple question evaluations; question quality/calibration must be monitored; data privacy controls for model calls.
- Hallucination detection and triage for summarization and RAG pipelines
- Sectors: media, enterprise content, research knowledge bases, legal ops (non-advisory), healthcare documentation (non-diagnostic)
- Use case: Automatically flag summaries/answers with likely factual errors or unsupported claims using targeted binary questions (e.g., entity correctness, fabrication checks).
- Tools/workflows: Insert BinEval after generation to score factual consistency; automatically route “failed question” items to human review; maintain a question bank tuned to the content type (news vs. FAQs vs. policy docs).
- Assumptions/dependencies: Strongest on factuality (paper shows gains on QAGS); relevance judgments can be more holistic and harder to decompose; human oversight for high-stakes content.
- Prompt A/B testing with actionable feedback
- Sectors: software product teams, LLM platform teams, UX for chat assistants
- Use case: Compare prompt variants with multi-dimensional, interpretable scores; identify exactly which criteria a prompt fails (e.g., adequacy, factuality, fluency) to guide revisions.
- Tools/workflows: Run BinEval across candidate prompts and datasets; view per-dimension and per-question diffs; use the self-update loop to convert failed-question explanations into prompt edits.
- Assumptions/dependencies: Works best when failures reflect missing instructions rather than underlying capability limits; risk of “prompt bloat” if too many lessons accumulate.
- Cross-model evaluator alignment during vendor or model migration
- Sectors: enterprises switching LLM providers; MLOps teams
- Use case: Use a strong “reference” evaluator to identify binary-question disagreements, then refine a target evaluator’s prompt so its scoring behavior matches the reference without retraining.
- Tools/workflows: Disagreement-driven “note-taker” and “updater” LLMs to deduplicate lessons and rewrite the target evaluator prompt; early stopping to prevent overfitting.
- Assumptions/dependencies: Access to a reliable source evaluator; domain drift may require regenerating question sets; quality depends on the meta-prompt and lesson deduplication.
- Human-in-the-loop review prioritization and cost reduction
- Sectors: annotation teams, data operations, research groups
- Use case: Triage outputs so humans only inspect samples with specific failed questions (e.g., “misattributed source,” “unsupported claim,” “redundancy”), reducing evaluation time.
- Tools/workflows: Review queues grouped by failure type; annotator UIs that display question-level rationales; targeted retraining data collection.
- Assumptions/dependencies: Question coverage must reflect the actual errors of interest; reviewer calibration to avoid over-penalizing borderline cases.
- Education: rubric-aligned formative feedback for short answers and summaries (low-stakes)
- Sectors: education technology, writing centers
- Use case: Provide learners with structured feedback tied to rubric items as decomposed binary questions (e.g., “includes key concept X,” “evidence is cited,” “no contradiction”).
- Tools/workflows: Course- or assignment-specific meta-prompts to generate question sets; dashboards showing per-criterion outcomes and explanations.
- Assumptions/dependencies: Keep human oversight for grading, particularly in high-stakes settings; ensure rubrics are faithfully captured by generated questions.
- Compliance-ready audit trails for generated content
- Sectors: finance, insurance, healthcare (administrative), public sector communications
- Use case: Store per-question verdicts and explanations as an auditable record for each generated artifact (e.g., customer letters, risk disclosures, policy summaries).
- Tools/workflows: Archive question-level logs; integrate with risk/compliance review systems; export per-dimension scores in standard formats.
- Assumptions/dependencies: Regulator acceptance varies; human sign-off recommended for regulated outputs; ensure data privacy and retention policies.
- Improving instruction-following for format/structure constraints
- Sectors: documentation, content ops, marketing, code comments/docs generation
- Use case: Use self-update to reduce format/sentence-level errors (e.g., templates, headings, bulleting, field presence), which the paper shows respond to clearer instructions.
- Tools/workflows: Iterate generator prompts using failed-question explanations; stop early to avoid instruction overload.
- Assumptions/dependencies: Limited gains on computational constraints (e.g., exact counts, ratios) noted in the paper; monitor for regressions.
- Academic and internal benchmarking with interpretable metrics
- Sectors: academia, industry research labs
- Use case: Replace or complement ROUGE/BLEU with multi-dimensional, interpretable evaluation for summarization/dialogue/consistency tasks that align better with human judgments.
- Tools/workflows: Public leaderboards and paper repos logging per-question verdicts; standard meta-prompts for comparability; distributional analyses to avoid ceiling effects.
- Assumptions/dependencies: Shared question-generation protocols; controlling evaluator bias across model families; compute costs for large-scale benchmarks.
- Debugging judge bias and evaluation drift
- Sectors: evaluation teams, governance/oversight boards
- Use case: Use question-level disagreements between judges (or over time) to diagnose systematic biases (verbosity, position, self-preference) and refine evaluator prompts.
- Tools/workflows: Disagreement heatmaps by dimension/question; lesson extraction and deduplication; controlled updates with regression tests.
- Assumptions/dependencies: Requires consistent test sets; ensure updates do not reduce relevance coverage or over-decompose criteria (a noted failure mode).
Long-Term Applications
The following applications need further research, domain adaptation, scaling, or engineering to reach robust deployment.
- Real-time guardrails and self-correction during generation
- Sectors: agentic systems, customer support bots, developer assistants
- Use case: Evaluate partial outputs on-the-fly; if a binary check fails (e.g., unsupported claim), trigger retrieval, revision, or escalation before finalizing.
- Tools/workflows: Streaming or incremental BinEval; caching/prefetching question sets; policy engines to decide revise/retrieve/escalate.
- Assumptions/dependencies: Latency and cost constraints; robust incremental evaluation; careful handling of interaction loops to avoid oscillations.
- Reward shaping and training signals for model improvement
- Sectors: LLM training/fine-tuning, RLHF/DPO pipelines
- Use case: Use per-question outcomes as dense, interpretable rewards to train models towards factuality, coherence, and format adherence without opaque scalar rewards.
- Tools/workflows: Aggregate question-level signals into rewards; curriculum over dimensions; data selection guided by failure profiles.
- Assumptions/dependencies: Avoid gaming the questions; ensure question coverage generalizes; maintain human calibration.
- Domain-specialized evaluators with verifiable checks
- Sectors: healthcare (clinical summarization), legal (cite/checklist compliance), finance (risk and disclosure checks), scientific writing
- Use case: Expand binary questions into domain-specific checklists tied to ontologies or external tools (e.g., medication-dose sanity checks, case citation validation).
- Tools/workflows: Curated question libraries; integration with rule-based or symbolic checkers and knowledge bases; human-in-the-loop verification.
- Assumptions/dependencies: Requires domain expertise and curated resources; regulatory approval; rigorous evaluation against expert annotations.
- Standardized evaluation protocols for policy, procurement, and audits
- Sectors: public sector, regulated industries, standards bodies
- Use case: Adopt decomposed, multi-dimensional evaluation as part of procurement evaluations and AI audit frameworks for transparency and comparability.
- Tools/workflows: Public, versioned meta-prompts; conformance test suites; reporting formats with per-question evidence.
- Assumptions/dependencies: Consensus on dimensions and thresholds; governance for evaluator updates and drift; cost-effective implementations.
- Agent checklists and self-critique in multi-step workflows
- Sectors: robotics process automation, operations, data analysis agents
- Use case: Agents maintain explicit checklists derived from binary questions per step (e.g., “data source cited,” “constraints met”) and self-correct when failures occur.
- Tools/workflows: Integrate BinEval as a sub-policy in agent frameworks; memory modules for past failures; action-selection based on failure types.
- Assumptions/dependencies: Managing compounding costs across steps; robust credit assignment between steps and checks.
- Cost-optimized hybrid evaluators
- Sectors: platform teams, open-source tooling
- Use case: Distill frequently used binary questions into lightweight specialized evaluators or combine with deterministic rules to reduce compute while retaining interpretability.
- Tools/workflows: Question bank analytics to identify high-yield checks; small-model training or rule codification; fallback to LLM-based BinEval for hard cases.
- Assumptions/dependencies: Requires dataset creation and validation for distilled evaluators; monitor for distribution shifts.
- “BinEval-as-a-service” products and integrations
- Sectors: LLM Ops platforms, MLOps vendors, cloud providers
- Use case: Managed APIs/SDKs offering question generation, scoring, disagreement analytics, and prompt-update loops with dashboards and pipelines.
- Tools/workflows: Connectors for prompt registries, evaluation data stores, and experiment tracking; policy-based gating.
- Assumptions/dependencies: Vendor-neutral abstractions; security and privacy guarantees; SLAs for evaluation latency.
- High-quality data curation and corpus filtering
- Sectors: data engineering for LLMs, dataset publishers
- Use case: Use binary checks to filter or weight training examples (e.g., select factual, coherent passages; discard hallucination-heavy content), improving data quality.
- Tools/workflows: Batch BinEval over corpora; score-based sampling; per-dimension weighting for training objectives.
- Assumptions/dependencies: Scaling to large corpora; avoiding overfitting to question distributions; ensuring diversity.
- Consumer-facing compliance/quality assistants (advisory)
- Sectors: small businesses, freelancers, daily productivity
- Use case: A checklist-style assistant that evaluates drafted emails, proposals, or contracts for structure and completeness (e.g., “all required sections present,” “figures referenced”), with explicit pass/fail rationales.
- Tools/workflows: Templates and question sets for common documents; suggested edits tied to failed questions; exportable reports.
- Assumptions/dependencies: Not a substitute for professional/legal advice; relies on well-scoped templates to avoid misinterpretation; privacy-sensitive content handling.
Glossary
- Affine scaling: A linear transformation used to map scores from one interval to another, preserving order and spacing. "the scores can be mapped from [0, 1] to any target interval [a, b] via affine scaling:"
- AlpacaEval: An automatic evaluator/benchmark that assesses instruction-following models, often via pairwise or preference judgments. "AlpacaEval~\cite{li23} and MT-Bench / Chatbot Arena~\cite{zheng23} rely on pairwise or preference-based judgments."
- BARTScore: A generation-based evaluation metric that frames evaluation as text generation using a pretrained LLM. "generation-based metrics like BARTScore~\cite{yuan21} frame evaluation as text generation."
- Bayesian search (over instructions): An optimization strategy that searches over prompt instructions using Bayesian methods. "algorithms like MIPRO~\cite{opsahlong24mipro} perform Bayesian search over instructions and demonstrations."
- BERTScore: An embedding-based metric that uses contextualized representations to measure semantic similarity between texts. "Embedding-based metrics such as BERTScore~\cite{zhang20} and MoverScore~\cite{zhao19} improve semantic matching by operating in representation space,"
- BinEval: A framework that evaluates LLM outputs by decomposing criteria into atomic binary questions and aggregating interpretable scores. "We propose BinEval, a framework that decomposes evaluation criteria into atomic binary questions and aggregates the resulting verdicts into interpretable, multi-dimensional scores."
- Ceiling effects: A measurement artifact where scores cluster at the high end, reducing the ability to discriminate quality differences. "and avoids the ceiling effects common in prior LLM judges,"
- Chain-of-thought reasoning: A prompting style that elicits step-by-step reasoning before producing a final judgment. "G-Eval~\cite{liu23} uses chain-of-thought reasoning followed by a Likert-scale rating,"
- Cross-model update: An iterative procedure that refines a target evaluator’s prompt to align with a stronger source evaluator based on question-level disagreements. "Cross-model update is strongest on consistency (+0.136),"
- Decompose-then-verify (paradigm): An evaluation approach that breaks outputs into atomic units (e.g., facts) and verifies each individually. "FActScore~\cite{min23} pioneered the ``decompose-then-verify'' paradigm by breaking long-form generations into atomic facts and verifying them individually."
- DSPy: A framework for declarative, self-improving language-model pipelines. "DSPy~\cite{khattab23} provides a framework for declarative, self-improving language-model pipelines,"
- Executable constraint checkers: Programmatic tests that deterministically verify whether generated outputs satisfy specified constraints. "which is verifiable via executable constraint checkers."
- Factual consistency: The extent to which a generated text’s claims are supported by the source content. "with especially strong results on factual consistency benchmarks such as QAGS."
- G-Eval: An LLM-as-judge method that uses GPT models (e.g., GPT-4) to rate outputs, often with chain-of-thought and scoring. "BinEval matches or outperforms strong baselines including UniEval and G-Eval,"
- Hallucination evaluation: The assessment of fabricated or unsupported content in generated text. "A benchmark specifically targeting hallucination evaluation in summarization,"
- Holistic LLM judges: LLM-based evaluators that provide an overall score without decomposing criteria, which can be opaque. "and holistic LLM judges~\cite{zheng23,liu23} often return opaque scores that are difficult to diagnose."
- IFBench: A benchmark for instruction-following with verifiable constraints used to test prompt optimization. "generation prompt optimization on IFBench~\cite{pyatkin2025generalizingverifiableinstructionfollowing}, which is verifiable via executable constraint checkers."
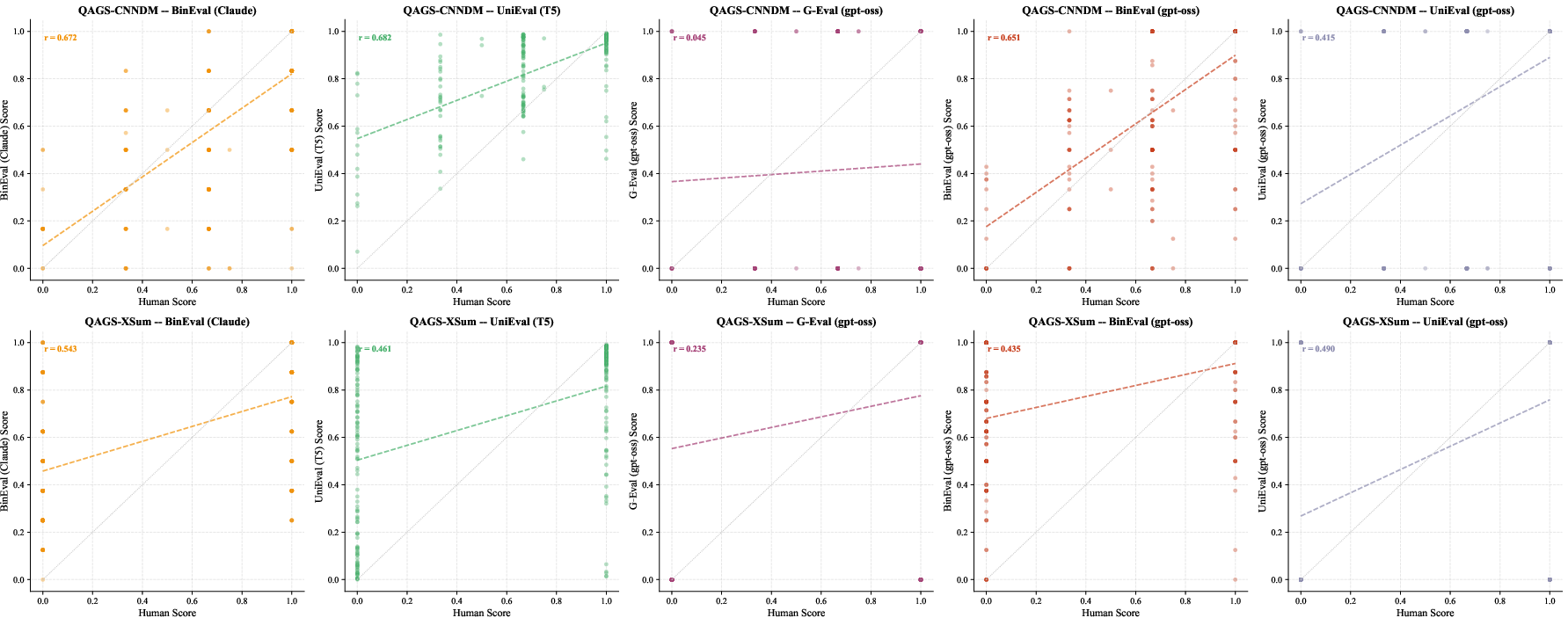
- Kendall's tau: A rank correlation coefficient measuring ordinal association between two rankings. "we report Spearman's rank correlation (), Kendall's rank correlation (), and Pearson correlation () between method scores and human judgments at the summary level."
- Likert scale: An ordinal rating scale (e.g., 1–5) commonly used for human judgments. "Ratings are on a 1--5 Likert scale."
- Meta-prompt: A higher-level prompt that instructs an LLM to generate evaluation questions or decompose tasks. "Given a task prompt, a meta-prompt generates fine-grained evaluation questions,"
- METEOR: A lexical-overlap metric for text evaluation that accounts for stemming, synonymy, and alignment. "Lexical overlap metrics--ROUGE~\cite{lin04}, BLEU~\cite{papineni02}, and METEOR~\cite{banerjee05}--remain standard for summarization and translation evaluation,"
- Mixture of Evaluators: An ensemble-style approach combining multiple evaluators to assess open-ended generation. "QAEval~\cite{yue25qaeval} combine rule-based reliability with a Mixture of Evaluators for open-ended generation tasks."
- MIPRO: A prompt-optimization algorithm that searches over instructions using Bayesian techniques. "algorithms like MIPRO~\cite{opsahlong24mipro} perform Bayesian search over instructions and demonstrations."
- MoverScore: An embedding-based metric that evaluates semantic similarity by aligning word embeddings with minimal transport cost. "Embedding-based metrics such as BERTScore~\cite{zhang20} and MoverScore~\cite{zhao19} improve semantic matching by operating in representation space,"
- Note-taker LLM: A model specialized to analyze disagreements or errors and extract generalizable lessons for prompt updates. "A note-taker LLM $L_{\text{note}$ analyzes each disagreement in context, extracting generalized lessons:"
- OmniScore: A deterministic evaluator framework designed for scalable, multilingual assessment. "and frameworks like OmniScore~\cite{alam26omniscore} use deterministic learned evaluators to support scalable multilingual assessment."
- OPRO: A method that uses LLMs to iteratively generate and refine prompts. "OPRO~\cite{yang23} and APE~\cite{zhou23ape} likewise use LLMs to iteratively generate and refine prompts."
- ParaPLUIE: A reference-free evaluation method that uses perplexity to gauge meaning preservation without gold references. "More recent reference-free methods like ParaPLUIE~\cite{lemesle25parapluie} measure meaning preservation using model perplexity without requiring gold references,"
- Pearson correlation: A coefficient measuring linear correlation between two variables. "we report Spearman's rank correlation (), Kendall's rank correlation (), and Pearson correlation () between method scores and human judgments at the summary level."
- Phi-coefficient: A correlation measure for binary variables indicating association strength. "Pairwise phi-coefficient correlation matrices within each SummEval dimension."
- Prompt bloat: The degradation in performance caused by overly long or overloaded prompts. "they accumulate into prompt bloat, which eventually harms even categories that were previously working well."
- QAEval: A hybrid evaluation framework combining rule-based and learned components for open-ended generation tasks. "hybrid frameworks such as QAEval~\cite{yue25qaeval} combine rule-based reliability with a Mixture of Evaluators for open-ended generation tasks."
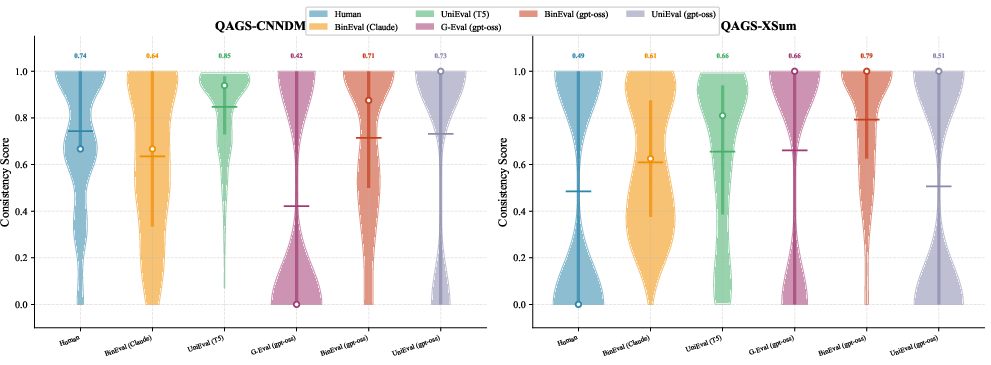
- QAGS: A benchmark focused on evaluating factual consistency and hallucinations in summarization. "A benchmark specifically targeting hallucination evaluation in summarization, comprising 235 samples from CNN/DM and 239 from XSum~\cite{narayan-etal-2018-dont}."
- Retrieval-augmented generation: A generation paradigm where external documents are retrieved to ground or support outputs. "Related frameworks such as ARES~\cite{saadfalcon24} and RAGAS~\cite{es24} extend similar decomposition ideas to retrieval-augmented generation,"
- ROUGE: A family of lexical-overlap metrics commonly used for summarization evaluation. "Lexical overlap metrics--ROUGE~\cite{lin04}, BLEU~\cite{papineni02}, and METEOR~\cite{banerjee05}--remain standard for summarization and translation evaluation,"
- Self-update: An iterative prompt refinement process where a model updates its own prompt using feedback on its outputs. "Self-update achieves a modest improvement, peaking at at iteration 3,"
- Spearman's rank correlation: A nonparametric measure of rank-order association between two variables. "we report Spearman's rank correlation (), Kendall's rank correlation (), and Pearson correlation () between method scores and human judgments at the summary level."
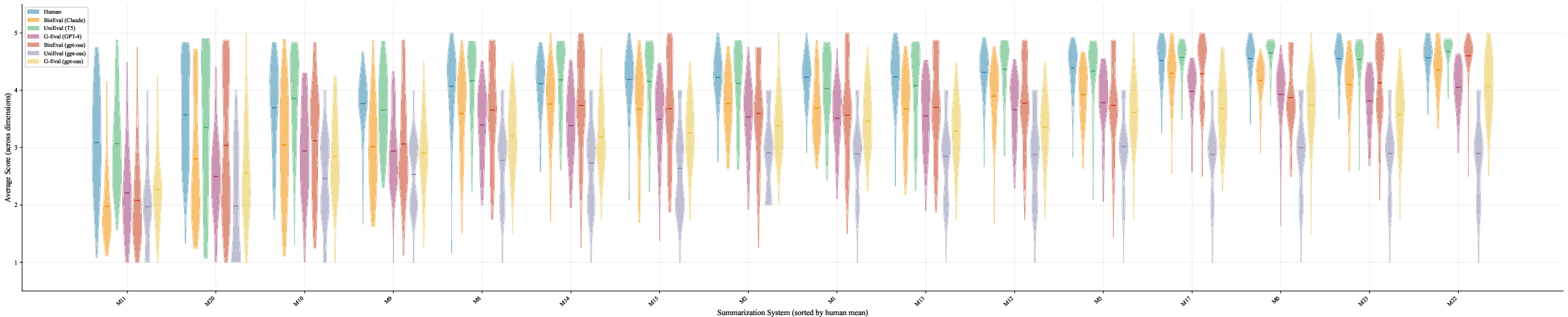
- SummEval: A summarization evaluation benchmark with human ratings across multiple quality dimensions. "A benchmark of 100 CNN/DM~\cite{see2017pointsummarizationpointergeneratornetworks} source articles, each summarized by 16 different summarization models, yielding 1,600 summary-level annotations."
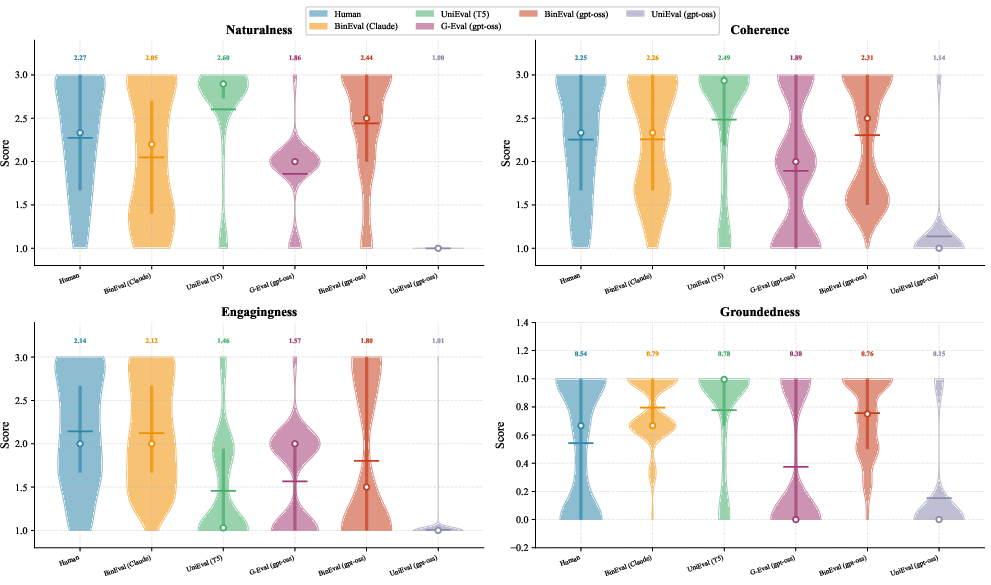
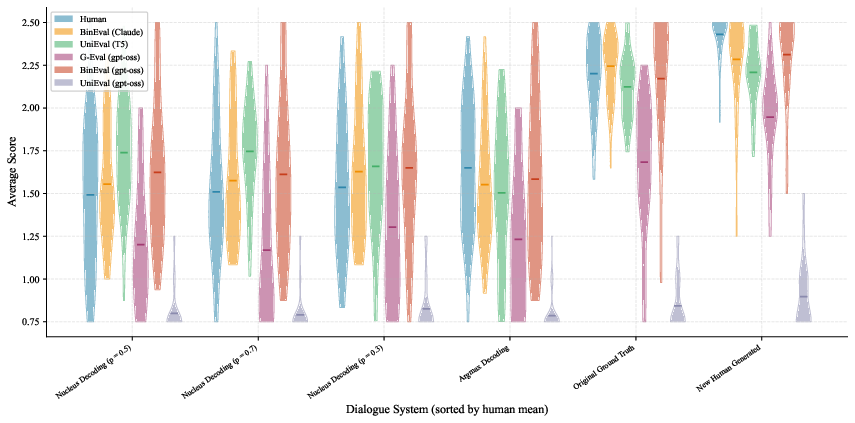
- Topical-Chat: A dialogue evaluation benchmark with human annotations across conversational quality dimensions. "A benchmark of 60 dialogue responses generated by 6 dialogue models, annotated on six dimensions: naturalness, coherence, engagingness, groundedness, understandability, and an overall quality rating."
- UniEval: A multidimensional evaluator that reformulates evaluation as Boolean QA and fine-tunes a T5-based model. "UniEval~\cite{zhong22} is a key prior example: it reformulates evaluation as Boolean question answering and fine-tunes a T5-based evaluator for multiple dimensions."
- Updater LLM: A model that edits prompts to incorporate distilled lessons from evaluation disagreements. "an updater LLM identifies the relevant substring in the current prompt and produces a revised substring that incorporates the lesson:"
- Violin plots: Distribution visualizations that combine density estimation with summary statistics. "The figure presents violin plots of score distributions on SummEval across four evaluation dimensions comparing human annotations with different methods."
- XSum: A dataset for extreme summarization, often used in factual consistency and hallucination studies. "comprising 235 samples from CNN/DM and 239 from XSum~\cite{narayan-etal-2018-dont}."
Collections
Sign up for free to add this paper to one or more collections.

