- The paper's main contribution is introducing LongJudgeBench, a benchmark that assesses LLMs as automated judges in long-form output scenarios.
- It systematically evaluates various prompting regimes and models, with best performance showing only 67.2% accuracy, exposing limitations in current judges.
- The study highlights critical issues such as order bias, context sensitivity, and rubric integration challenges, calling for improved evaluation methods.
Motivation and Context
As the deployment of LLMs shifts toward increasingly complex, long-form generation tasks, robust automatic evaluation methods are essential for scalable and rigorous model assessment. The paradigm of LLM-as-a-judge, where LLMs autonomously evaluate peer-generated responses, has become widespread due to its scalability compared to human annotation. However, existing meta-evaluation benchmarks overwhelmingly target short-form outputs and lack coverage of document-level criteria—such as discourse structure, cross-section consistency, and domain-specific depth—that are intrinsic to long-form scenarios.
The paper "Benchmarking LLM-as-a-Judge for Long-Form Output Evaluation" (2606.01629) directly addresses this methodological gap via the introduction of LongJudgeBench—a benchmark explicitly designed to quantify LLM-as-a-judge reliability in real-world long-form evaluation milieus.
LongJudgeBench: Design and Scope
LongJudgeBench operationalizes LLM judge evaluation for long-form generation across five diverse real-world tasks and six datasets, characterized by token lengths averaging over 9,200, an order of magnitude larger than typical prior work. Each instance comprises three formalized components: detailed instructions (including task queries, judging protocols, and auxiliary signals such as rubrics or references), target long-form content, and a response area for the LLM judgment.
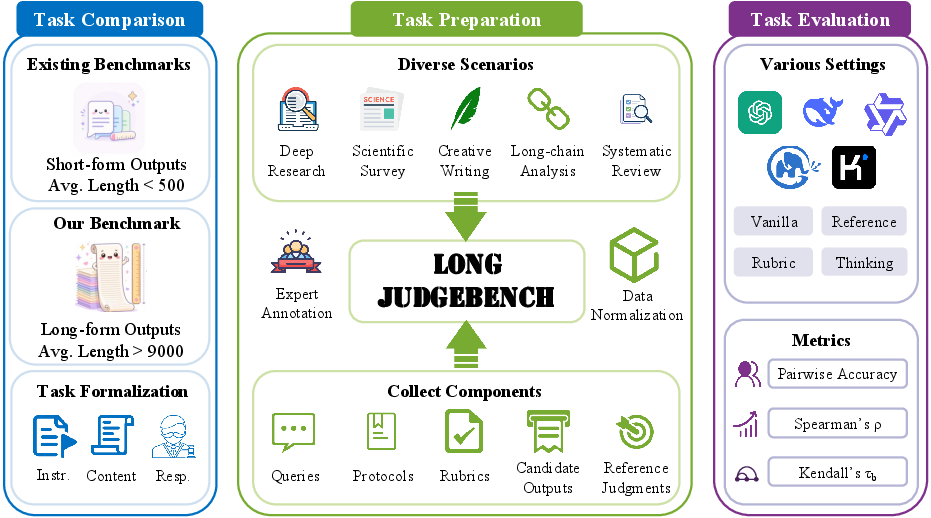
Figure 1: High-level schema of LongJudgeBench encompassing scenario-specific task construction, input formalization, and multifaceted evaluation metrics.
The benchmark spans:
- Deep research (DR-Bench, RealDeepResearch): Document-level evaluation emphasizing organization and domain-specific insight, with multilingual support and realistic DOCX-format preservation.
- Scientific survey (SurGE): Multidimensional listwise ranking of technical survey documents with explicit structural and content rubrics.
- Creative writing (WP-Bench): Subjective, preference-based pairwise comparison of long creative texts, controlling for objective confounders.
- Long-chain analysis (VerifyBench): Correctness verification under challenging reasoning settings.
- Systematic review (MA): Medical domain meta-analysis insight assessment with fine-grained expert annotation.
All datasets are normalized into a unified meta-evaluation protocol, supporting pointwise, pairwise, and listwise judging, with expert reference judgments foundational to reliability.
Experimental Setup
A broad spectrum of LLM judges is benchmarked, including high-capacity open-weight (Qwen3-32B, Qwen3-Max, DeepSeek-V4-Flash, GLM-5.1, Kimi-K2.6) and proprietary (GPT-5.2, GPT-4o-mini) models. Each judge is evaluated under four prompting regimes: vanilla (no auxiliary signals), rubric-based, reference-based, and a combined reference+rubric setting. The judgments are evaluated primarily by accuracy against human references, with auxiliary analysis via Spearman's and Kendall's rank correlations.
Key Empirical Findings
Long-form judgment remains fundamentally unsolved. Even the best-performing configuration—Qwen3-Max with reference—achieves only 67.2% accuracy. Across all models and settings, the mean accuracy is 56%, marginally above random-choice for pairwise preference. Strongest open-weight models (Qwen3-Max, DeepSeek-V4-Flash, GLM-5.1) outperformed proprietary GPT variants in aggregate, indicating that raw general-purpose generative strength does not guarantee high-quality document-level evaluation.
Scenario-level breakdowns reveal large variation in results, with tasks featuring explicit evaluation anchors (e.g., correctness-based VerifyBench) yielding significantly higher judge agreement than open-ended or subjective evaluations (e.g., RealDeepResearch, WP-Bench, MA).
Effect of Rubrics and References
Providing human-designed rubrics or high-quality reference outputs improves judge agreement, particularly for tasks with well-defined, objective targets. However, these benefits are not universal; in some settings, rubric inclusion either has marginal impact or even introduces inconsistency in pairwise and rank correlation. The combination of references and rubrics does not yield additive improvements, suggesting unresolved challenges in integrating heterogeneous auxiliary signals during evaluation.
Output Length Sensitivity
Analysis on output length sensitivity (Figure 2) demonstrates that judge performance does not monotonically decrease with output length. Some tasks (e.g., Verify, SurGE) exhibit clear negative correlation between content size and agreement, while others display non-monotonic or model-specific effects. This indicates that difficulties in long-form evaluation are less a function of raw token count and more determined by demands such as task ambiguity, subjectivity, or domain complexity.
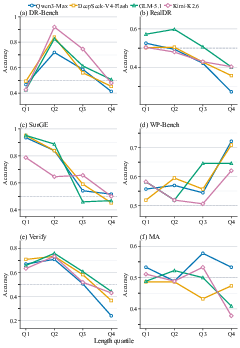
Figure 2: Output length sensitivity across datasets, quantifying judge reliability as a function of long-form content size.
Failure Modes and Biases
Systematic biases emerge in various forms. Position bias, wherein model preferences invert upon swapping the order of presented outputs, is observed to be severe in select models and datasets (e.g., up to 78.7% inconsistency on WP-Bench for GPT-4o-mini). Judges struggle to reliably disregard superficial coverage in favor of core issue resolution and exhibit scenario-specific misgrounding, especially in technical or domain-specialized queries.
Practical failures are non-negligible; judges often hit context-window limits or trigger safety-policy refusals, especially when long candidate outputs are further augmented with reference or rubric material. The frequency of such failures is summarized in Figure 3.
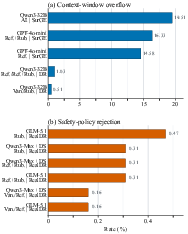
Figure 3: Frequency of invalid judgment instances resulting from context overflows or safety-triggered refusals, stratified by model and judging setting.
Implications
Practical Impact
The instability of LLM judges in long-form scenarios raises fundamental concerns for automatic evaluation pipelines, particularly for research, scientific writing, and domains demanding high factual or structural precision. The nontrivial gap between current automatic judging and human expert assessment necessitates further investigation into context management, robustness to prompt and task structure, and domain adaptation.
The non-additive and sometimes detrimental interaction between rubrics and references highlights a significant open problem in prompt engineering for evaluation. Models currently lack mechanisms for reliable signal integration and weighting, demanding advances both in prompt structuring and possibly in neuro-symbolic approaches to judgment.
Theoretical Perspective and Future Directions
These results underscore that progress in long-form output evaluation will require:
- Enhanced judge training paradigms, potentially incorporating retrieval augmentation, explicit document representation, hierarchical context summarization, and multi-agent debate.
- Systematic de-biasing for order sensitivity and prompt artifacts.
- Expansion and annotation of even more heterogeneous datasets covering additional domains, modalities (e.g., code, multimedia), and tasks.
- Exploration of compositional evaluation methods, hybridizing human-in-the-loop and LLM-driven protocols.
The release of LongJudgeBench sets a new standard for rigor in LLM evaluation research and will serve as an essential diagnostic tool as architectures and judging strategies evolve.
Conclusion
LongJudgeBench operationalizes the shift in LLM evaluation needs triggered by large-scale, long-form generation, rigorously exposing reliability deficits in current LLM-as-a-judge approaches. The benchmark's open-source release furnishes the community with both a testbed and a challenge, driving research toward scalable, reliable, and human-aligned long-form automatic evaluation. The findings strongly suggest that improving LLM-as-a-judge robustness and context sensitivity remains a critical open problem as LLMs advance toward real-world long-form tasks.

