- The paper introduces CodeAnchor, a framework using in-band static annotations from lightweight static analysis to improve deterministic behavior in LLM-based code agents.
- It employs static analysis to inject call, inheritance, and data-flow tags into source code, achieving up to +2.2pp accuracy improvement and halving run-to-run variance.
- The findings suggest that deterministic anchoring stabilizes tool invocations, reduces redundant explorations, and provides actionable insights for deploying safer code agents.
Deterministic Anchoring for Code Agents: Quantifying the Value of Static Structure
Introduction
This essay presents a detailed analysis of the techniques and findings in "How Much Static Structure Do Code Agents Need? A Study of Deterministic Anchoring" (2606.26979). The paper addresses a pivotal issue in LLM-based code agents: despite strong empirical performance, agents that rely on lexical/keyword-based retrieval ("grep-first" agents) lack access to the structural relationships—such as call graphs, inheritance, and data-flow—that underpin real software. This representation mismatch leads to stochastic, brittle, and unreproducible navigation trajectories. The central research question posed is whether lightweight static analysis, injected as in-band structural annotations, can serve as deterministic anchors that (a) improve accuracy, (b) reduce stochasticity, and (c) impose behavioral discipline on code agents, without altering the overall agent control loop.
The paper introduces CodeAnchor, a framework that augments existing grep-based agents with structural representations derived from lightweight static analysis. The core contribution is to encode call, inheritance, and data-flow relationships as "CodeAnchor tags"—syntactic comments embedded directly within source code. These tags are generated offline (using PyCG and AST-based extractors for Python) and inserted at relevant code entities (functions, classes, modules).
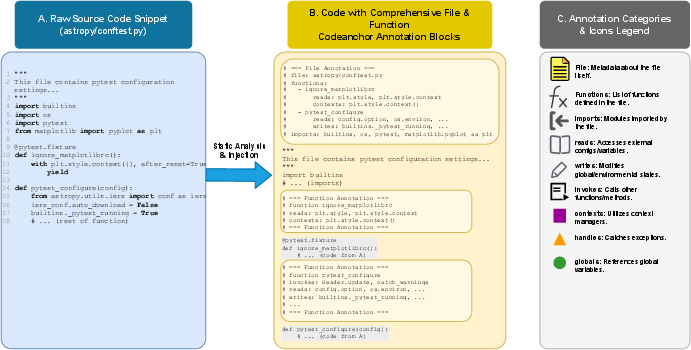
Figure 1: The CodeAnchor workflow: static analysis emits code structure as tags injected directly into source files, which are then consumed by the agent through unmodified grep-text retrieval.
At runtime, because tags are treated as plain-text comments, agent operation is unchanged: text queries (e.g., grep) now retrieve both raw code and structured tags. This enables agents to perceive repository structure without explicit graph-based navigation APIs, maintaining the practical simplicity of the grep-first paradigm.
Motivation and Deterministic Anchoring Effect
The paper formalizes a key behavioral phenomenon—the "deterministic anchoring effect." Rather than yielding smarter semantic reasoning per se, static structure acts as an inductive bias that constrains agent behavior to be more consistent and less sensitive to stochastic LLM decision noise. In practical settings, identical prompts in existing agents can yield divergent tool invocation paths, file visits, and patch suggestions—impeding interpretability and debuggability.
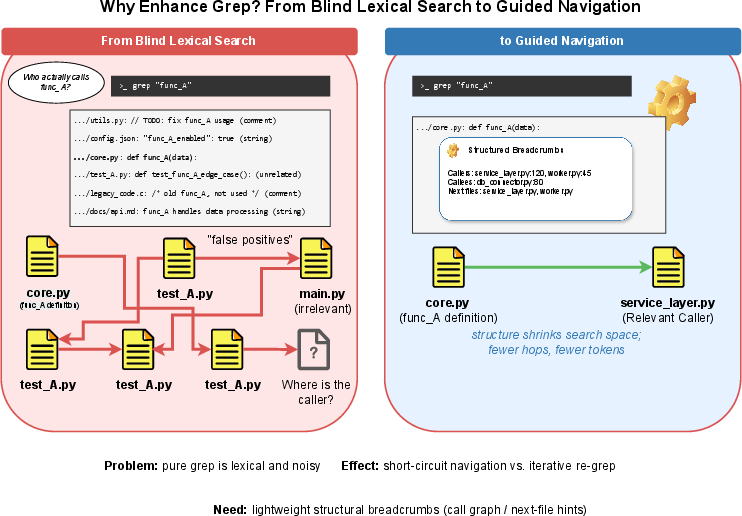
Figure 2: Inline CodeAnchor tags correct for the lexical noise of pure grep by providing explicit structural breadcrumbs, such as call relationships and cross-file hints.
By preemptively surfacing stable structural facts, tags guide the agent along repository-dependent paths, mitigating the need for repeated, redundant rediscovery of the same links via multi-hop ad-hoc queries.
Empirical Evaluation: Accuracy, Efficiency, and Stability
Core Metrics and Methodology
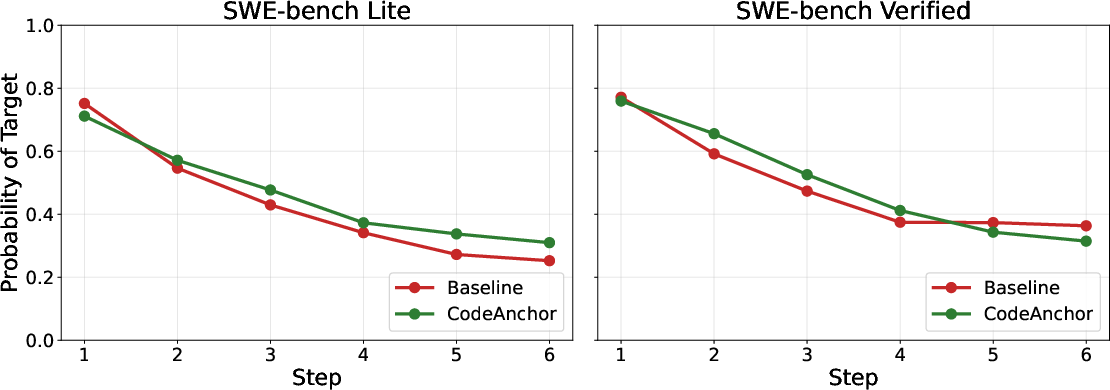
The evaluation is conducted on SWE-bench Lite and SWE-bench Verified, measuring not only classic localization metrics (File@k and Func@k), but also tool-call efficiency, link-following rate (LFR), and cross-run behavioral stability. Four configurations are assessed: Baseline (no tags), Anchor-Topo (bidirectional call/inheritance), Anchor-Dense (adds config/data-flow edges), and Anchor-Inv (inverse-only dependencies).
Key Results
Behavioral Analysis
Instrumented trace analyses prove that tags are not blindly followed: tag-guided hops land on ground-truth entities in ≈27% of cases, and in over half of sample instances. Case studies highlight scenarios where tags resolve ambiguous navigation points, enable upward traversal in class hierarchies, and eliminate redundant keyword searching.
Implications and Theoretical Significance
Architectural Guidance and Scale Sensitivity
- Agents should default to lightweight topological tags on medium-scale repositories.
- In forward-link-dense or hub-heavy codebases, inverse-only tags prevent noise amplification.
- Dense tags should be reserved for tasks diagnosable only via implicit dependency chains.
This denotes a contradictory claim to the prevailing view in LLM-for-code: structural benefits derive less from augmenting semantic performance and more from constraining stochastic, locally myopic policies.
Practical Deployment Considerations
- Tag generation incurs negligible per-snapshot cost and increases per-query tokens by ≈10%.
- Tags confer robustness to static analysis unsoundness: even with incomplete or imprecise call graphs, agents exploit available structure as a bias, not a symbolic constraint.
Theoretical Implications for AI
The findings challenge the premise that further improvements in model capacity or implicit embedding representation alone will solve the structure-grounding gap. Instead, explicit, in-context structural annotation induces deterministic behavioral regularization, essential for agents deployed in tasks with high reproducibility or inspection requirements. The distinction between improving accuracy and stabilizing behavior becomes central for future system design.
Limitations and Future Research Directions
The study is limited to Python repositories and agents based on grep-style tool-augmented LLM controllers. Cross-language transfer, deeper multi-module faults, and combination with neural or explicit structural retrieval warrant further empirical inquiry.
On the modeling front, hybrid settings could be constructed with in-band tags for routine navigation and external, explicit graph queries for challenging, deeper faults, possibly leveraging recent graph-tool agent designs or external long-context or retrieval infrastructure.
Conclusion
This work establishes that the injection of static structure through plain-text deterministic anchors yields not only modest accuracy improvements but, more importantly, induces predictable, disciplined, and reproducible behavior in LLM-based code agents. These behavioral regularization effects are critical as code agents move from benchmark labs to safety-critical or high-assurance software engineering deployments. The findings prompt reconsideration of the roles of explicit structure and the design of future code understanding AI agents (2606.26979).