- The paper introduces CodeTracer, a scalable framework that decomposes agent execution into hierarchical trace trees for precise failure onset localization.
- It employs evolving extraction and tree indexing to standardize diverse agent logs, enhancing traceability and actionable debugging signals.
- Empirical analysis on CodeTraceBench reveals systematic failure patterns, highlighting evidence-to-action gaps and efficiency trade-offs in code agents.
Code agents powered by frontier LLMs have become increasingly capable in executing complex software engineering tasks, yet their debugging, process transparency, and failure diagnosis remain underdeveloped. The agent orchestration of heterogeneous actions, including parallel tool calls and multi-stage workflows, obfuscates the provenance of failures and error chains. Traditional evaluation, relying primarily on coarse outcome-level metrics, fails to provide actionable insight into how agent trajectories diverge from optimality. Trace analyses of real agent workflows require scalable approaches to systematically localize the onset and propagation of critical errors.
CodeTracer Architecture and Trace Standardization
CodeTracer implements a scalable trajectory tracing framework, decomposing agent logs from heterogeneous execution environments into hierarchical trace trees with persistent and reusable memory. The pipeline consists of three modular stages:
- Evolving Extraction: Automatically discovers run directory layouts and adapts parsers for step normalization, enabling artifact standardization across diverse agent frameworks.
- Tree Indexing: Converts normalized step sequences into a hierarchical trace tree, distinguishing exploration steps (non-state-changing) from state-changing actions. This structure supports compressed and navigable indexing of execution traces, crucial for context-aware diagnosis.
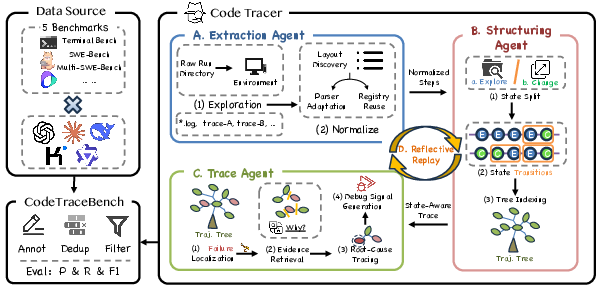
Figure 1: Overview of the CodeTracer pipeline, from trajectory normalization to hierarchical trace creation and failure onset localization.
- Failure Onset Localization: Traverses the trace tree to pinpoint the earliest causally critical error stage and extracts a compact set of failure-relevant steps and supporting evidence. This stage outputs actionable debugging signals designed for reflective replay.
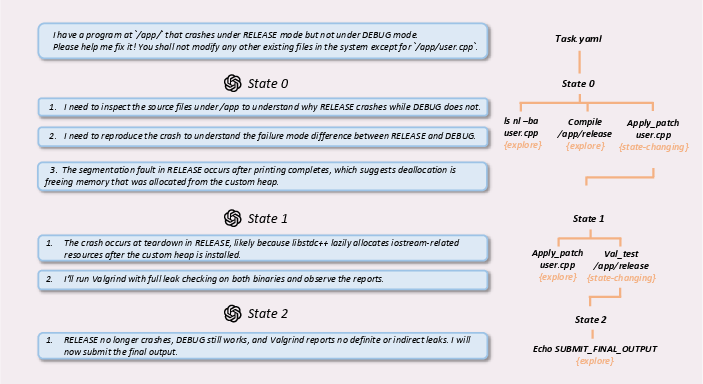
Figure 2: Hierarchical trace tree construction, differentiating exploration and state-changing steps for compressed trace navigation.
CodeTraceBench: Benchmark Construction
To drive systematic evaluation, CodeTraceBench aggregates 4,354 standardized and annotated trajectories spanning five model backbones (including Claude-sonnet-4, GPT-5, DeepSeek-V3.2, Qwen3-Coder-480B, Kimi-K2-Instruct) and four agent frameworks (SWE-Agent, MiniSWE-Agent, OpenHands, Terminus 2) across 236 tasks and 26 categories. Each instance features granular step-level supervision, failure critical stage labels, and incorrect step annotations. Annotation reliability is confirmed with interannotator agreement (κ=0.73), attesting to consistent error critical labeling.
Empirical Analysis and Failure Patterns
The empirical study reveals key behavioral and architectural insights:
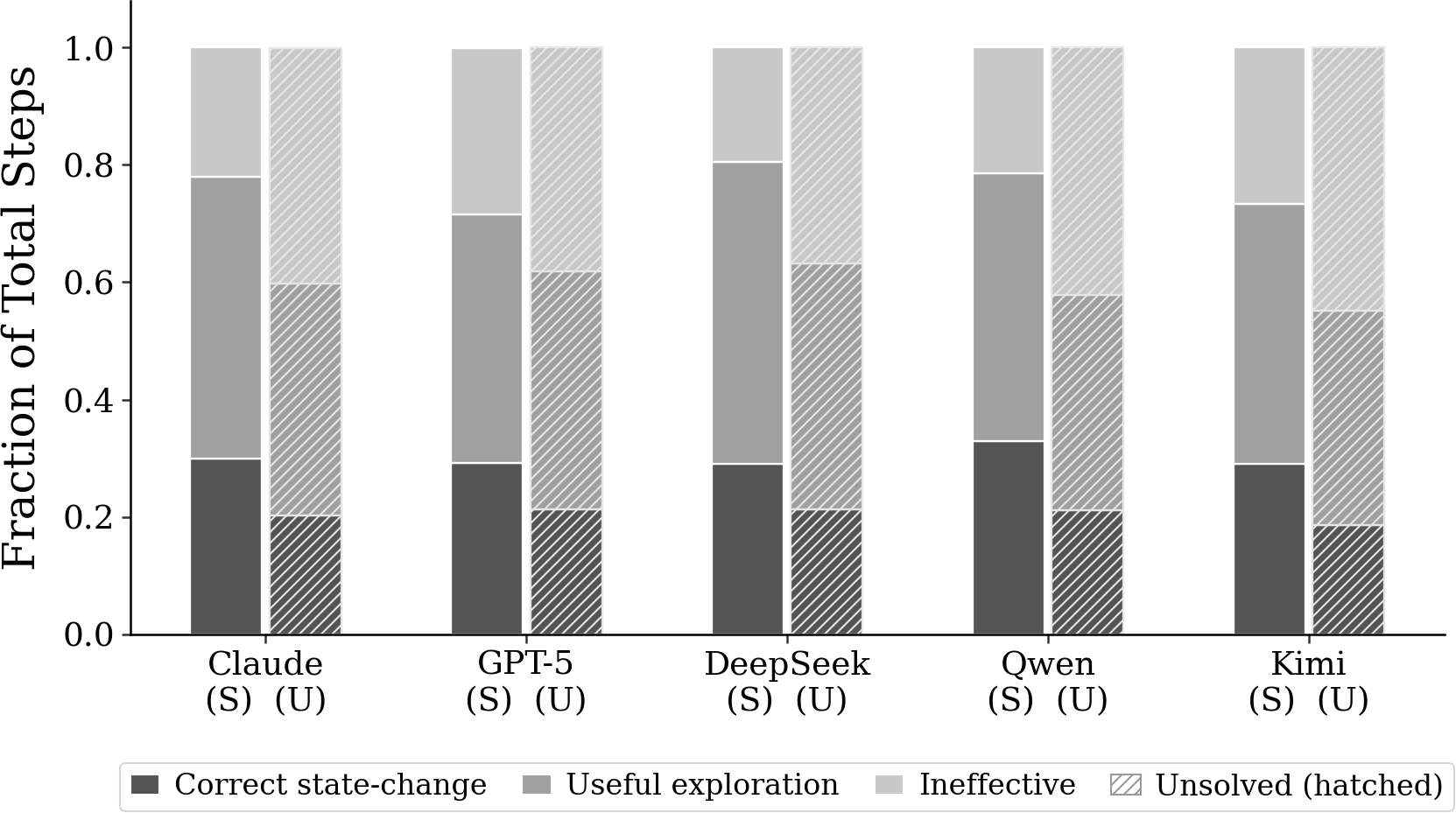
- Task Regime Preference and Masked Failures: Backbones exhibit task-specific reliability, diverging more on regime coverage than aggregate resolved count, yet converge to identical fabrication and stagnation patterns on universally hard categories.
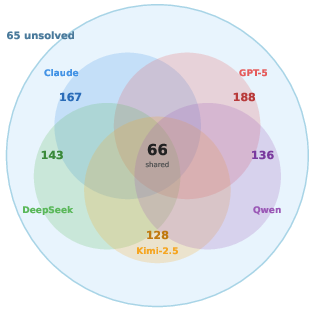
Figure 3: Task categories solved per backbone, evidencing convergent failure patterns on unsolved tasks.
- Architectural Complexity vs. Performance: Increasing orchestration and token budget in agent frameworks yields diminishing returns; backbone LLM capability is the primary determinant of success. Lightweight agents (MiniSWE-Agent) are competitive in end-to-end metrics, highlighting the inefficacy of overengineering.
- Workflow Stage-Dependent Error Types: Error critical steps cluster predictably by workflow stage—environment and dependency errors are early, mislocalized edits and incorrect hypotheses late—enabling stage-aware guardrails and preemptive interventions.
Figure 4: Distribution of error critical steps across workflow stages for solved and unsolved runs.
- Iteration Budget Saturation: Resolved rate curves saturate rapidly (~40 steps), with additional iterations primarily amplifying unproductive loops rather than enabling recovery. Model capability, not budget, sets the success ceiling.
Step-Level Failure Localization: CodeTracer vs. Baselines
On CodeTraceBench, CodeTracer substantially outperforms direct log prompting and lightweight baselines. Macro F1 scores for step-level localization reach 48.02% (GPT-5), 46.57% (Claude-sonnet-4), and 46.14% (DeepSeek-V3.2), with token-efficiency tradeoffs determined by search depth strategy: GPT-5 exhibits early commitment and higher precision, Claude-sonnet-4 exhaustive search and higher recall, DeepSeek-V3.2 a balanced approach.
Reflective Replay and Recovery
CodeTracer's diagnostic outputs, when injected via reflective replay under matched budgets, reliably recover failed runs, enhancing Pass@1 across all backbones. The diagnosis pass incurs minimal token overhead and isolates the benefit to localization quality rather than increased computation.
Figure 6: Reflective replay improves pass rates on originally failed runs after injecting CodeTracer's diagnostic signals.
Action Efficiency and Industrial Agent Comparison
Analysis of effective action ratios reveals broad distributions irrespective of backbone strength—every model has numerous trajectories with suboptimal action efficiency, accentuating the necessity for early detection of unproductive behavior and targeted intervention.
Figure 7: Effective action ratio histogram for Claude-sonnet-4.
- Industrial agents (e.g., Claude Code) feature specialized tooling, aggressive context management, and parallel tool execution, resulting in lower exploration-to-change ratios and higher trajectory efficiency. However, parallelism introduces ordering-sensitivity challenges absent from academic frameworks.
Implications and Future Directions
The study underscores the limits of outcome-only evaluation, advocating for process-level, step-wise diagnostic supervision. CodeTracer structurally enables failure onset localization, supporting both empirical analysis and practical agent improvement via reflective replay. The evidence-action gap and stage-dependent error clustering motivate integrating hierarchical trace analyses and diagnosis signals into agent architectures as dense feedback sources.
Future research should expand trace standardization to cover richer agent toolsets and diverse repository environments, enhance annotation schemas for more granular supervision, and develop online adaptive replay strategies for interactive environments. The localization pipeline could serve as the foundation for reinforcement and offline RL, leveraging per-step deviation signals to close the behavioral gap between industrial and academic agents.
Conclusion
CodeTracer delivers scalable hierarchical tracing and automated failure onset localization for code agent trajectories, validated on CodeTraceBench—a large benchmark of step-level annotated runs across multiple backbones and frameworks. Experimental results reveal systematic failure patterns, actionable evidence-to-action gaps, and agent architecture inefficiencies, with CodeTracer achieving robust gains in step-level localization and effective replay-driven recovery. The framework constitutes a powerful diagnostic tool for structured evaluation and targeted improvement in software-engineering-oriented autonomous agents (2604.11641).