- The paper introduces PhyEditBench, a benchmark that fills the gap in evaluating physics-aware image editing through multi-stage trajectories and counterfactual anti-physics cases.
- The methodology employs a hierarchical taxonomy of physical phenomena and combines automated VLM evaluation with expert human verification for rigorous testing.
- Experimental results reveal that video-based editors like PhyWorld excel in maintaining temporal causality and physical plausibility compared to static editing models.
PhyEditBench: A Real-World Multi-Stage Benchmark for Physics-Aware Image Editing
Motivation and Benchmark Design
PhyEditBench is developed to fill a critical gap in the current landscape of instruction-based image editing evaluation, which predominantly targets semantic manipulation without rigorous assessment of physical reasoning. Prior benchmarks such as KRIS-Bench, RISEBench, and UniREditBench focus on spatial, conceptual, and logical reasoning, but they fail to systematically probe an editing model’s ability to understand and simulate real-world physics. PhyEditBench addresses this deficiency by curating a high-quality dataset with 238 real-world instances and 35 synthetic anti-physics cases, extracted from authentic videos depicting complex physical phenomena. This hierarchical taxonomy encompasses four primary classes—Deformation, Fluid Dynamics, Rigid Body Interaction, and State Change—further subdivided into 12 subclasses to permit both coarse and fine-grained evaluation.

Figure 1: PhyEditBench contains diverse, high-resolution examples reflecting authentic multi-stage physical processes.
A key innovation is the multi-stage trajectory format: each instance is represented by four temporally ordered states and corresponding stepwise and global instructions. This design enables benchmarking both step-wise and holistic reasoning, crucial for assessing temporal causality and intermediate state fidelity in physical transitions.

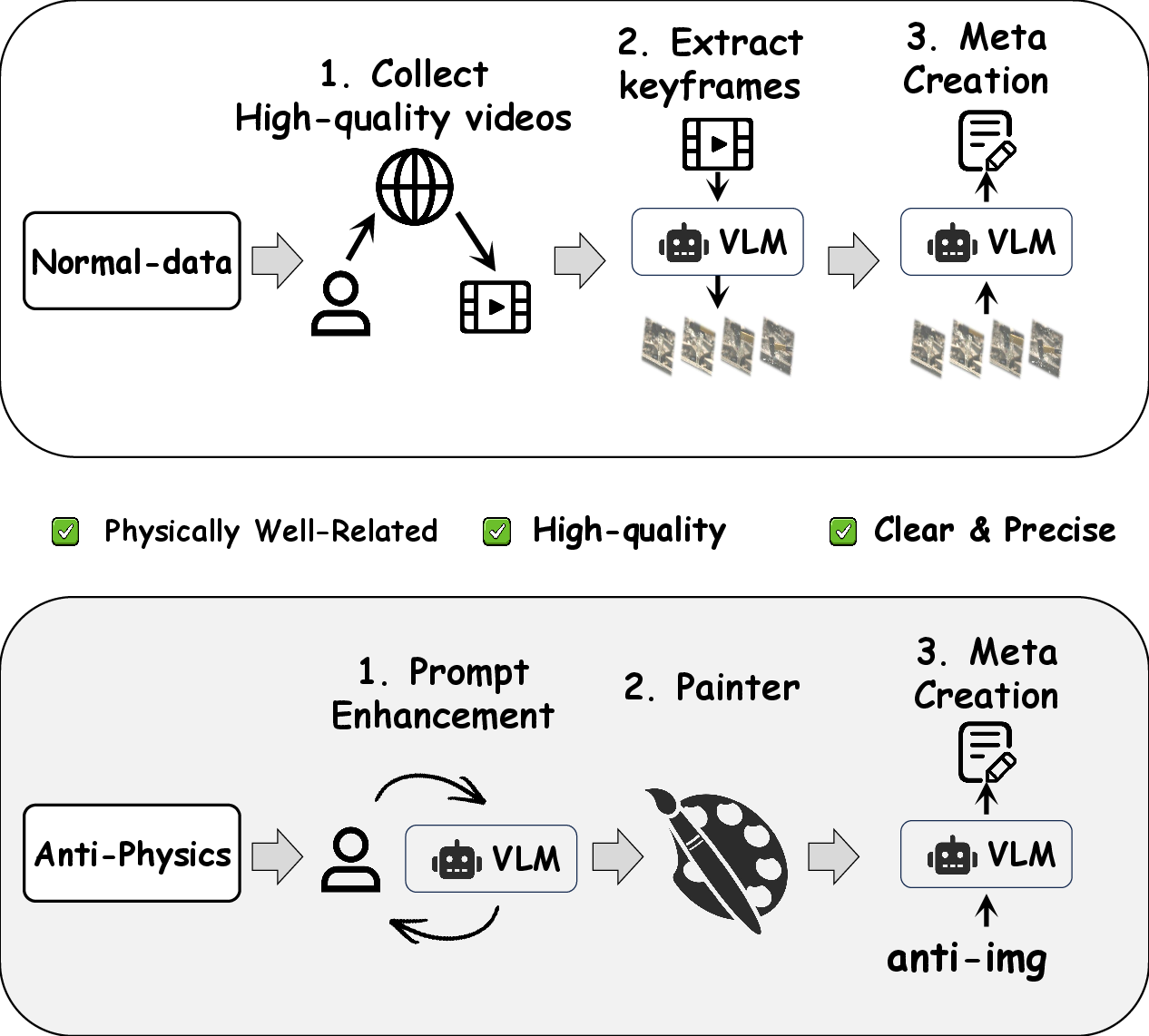
Figure 2: Benchmark overview illustrating taxonomy and data volume distribution across subclasses and physical types.
Data Construction and Evaluation Protocol
Data curation leverages Vision-LLMs (VLMs) for initial keyframe selection and semantic annotation, followed by expert human verification to ensure physical consistency, temporal ordering, and invariant preservation (e.g., background, viewpoint). Anti-physics cases are synthesized through generative models with explicit prompts violating physical laws, serving to decouple genuine reasoning from statistical memorization biases.
Each data point includes images, detailed instructions, physical explanations, and invariants, fostering granular diagnosis of reasoning failures. The evaluation pipeline employs an automated VLM judge (GPT-4o), scoring outputs across four dimensions: Consistency, Instruction Following, Physical Plausibility, and Image Quality. The reliability of this VLM-based protocol is validated by human studies, showing strong alignment (Kendall τ up to 0.65 for core metrics).
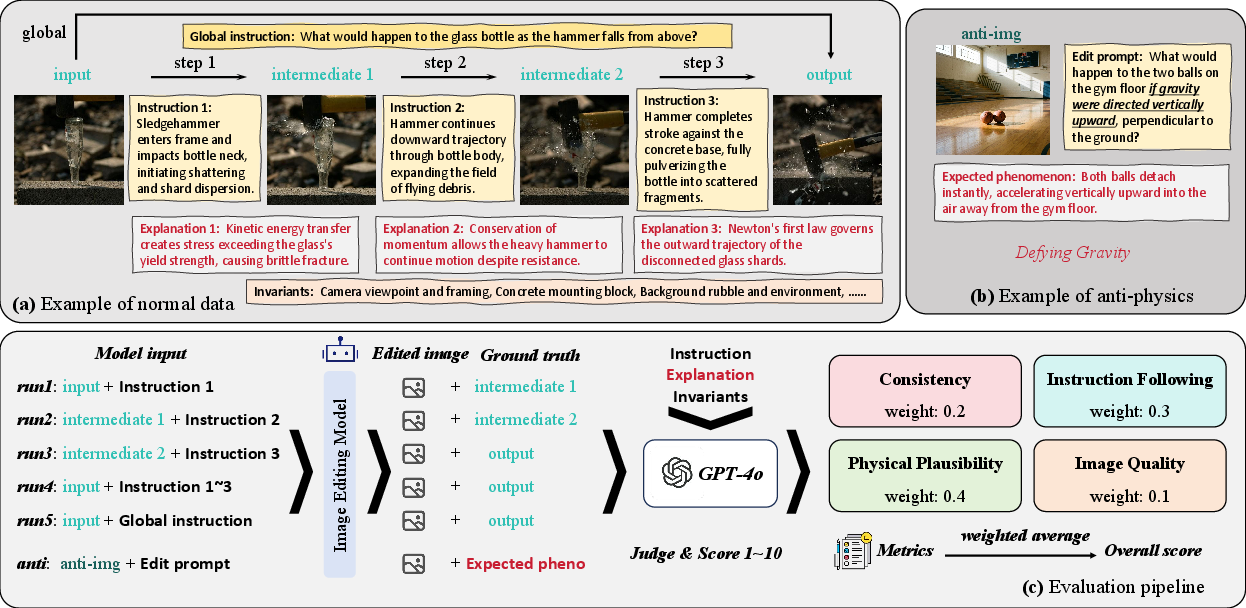
Figure 3: Example annotation formats for normal and anti-physics cases and the unified scoring pipeline used by VLM judges.
PhyWorld: Training-Free Physics-Aware Editing via Video Generation
To probe the limits of physical reasoning in image editing, the paper introduces PhyWorld, a novel training-free baseline that harnesses pretrained video generation models as implicit world simulators. PhyWorld reformulates editing as a temporal transformation process, with the intermediate frames serving as reasoning tokens. Editing prompts are enhanced via Qwen-3.5 Max VLM to generate detailed temporal captions, improving grounding in physical transitions.
The generation pipeline integrates evolutionary Test-Time Scaling (TTS), wherein multiple Gaussian noise samples are denoised; a video reward model selects optimal sequences, and a latent reduction strategy is applied to compress intermediate frames for efficiency without compromising fidelity.
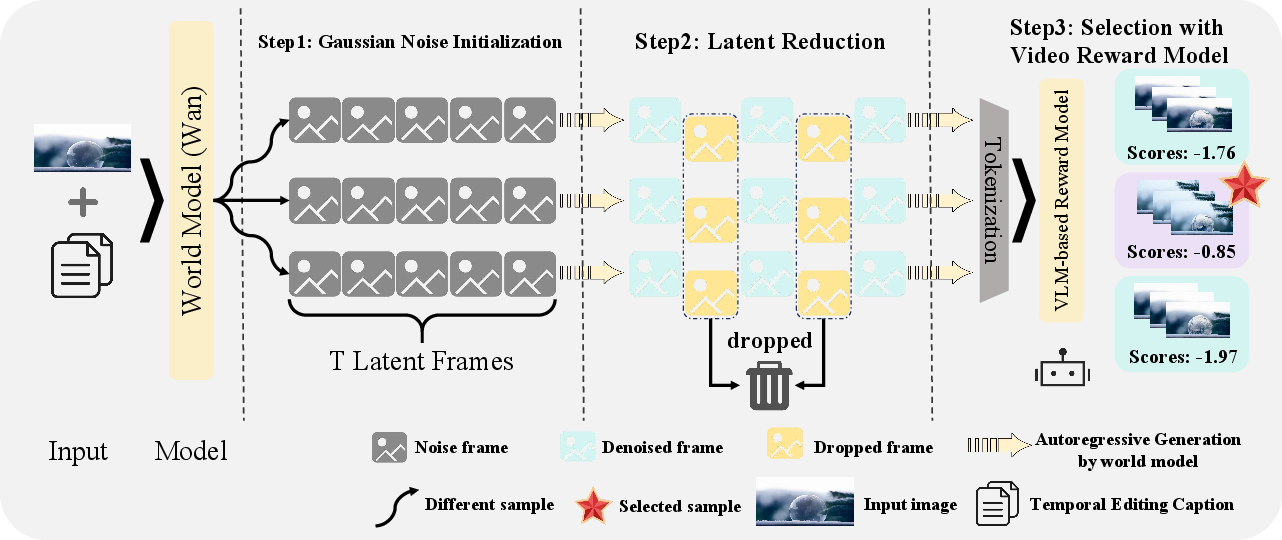
Figure 4: PhyWorld pipeline: from noise initialization, latent reduction, evolutionary selection, to extracting the final edited frame.
Experimental Analysis and Numerical Results
Extensive benchmarking covers closed-source (e.g., GPT-Image-1.5, Gemini-2.5, Seedream4.0), open-source, and video-based editors (e.g., Frame2Frame, ChronoEdit-14B, PhyWorld). ChronoEdit-14B achieves superior overall scores, with Seedream4.0 close behind. Among open-source editors, UniWorld-V2 is strong, but PhyWorld attains competitive performance with a significantly smaller model (5B parameters). Notably, BAGEL-Think’s improvement over BAGEL underscores the challenge imposed by physical reasoning tasks.
On anti-physics cases—requiring counterfactual deduction—closed-source models struggle; PhyWorld is the best open-source performer, narrowing the gap with proprietary solutions. Stepwise (TypeA/B) editing consistently outperforms global or joint-edit (TypeD/E), revealing error accumulation and temporal causality deficits in static models. Video-based editors, benefiting from continuous temporal modeling, robustly mitigate such degradation, demonstrating pronounced superiority in long-horizon reasoning tasks.

Figure 5: Qualitative comparison across physical categories, with PhyWorld achieving superior plausibility and alignment, especially under anti-physics constraints.
Evaluation metric-wise, models generally excel at Consistency and Instruction Following, but Physical Plausibility remains challenging for all except advanced video-based approaches. Closed-source Seedream4.0 and ChronoEdit-14B are particularly effective in classes with complex topological and fluid changes; static open-source editors underperform due to lack of physical modeling priors.
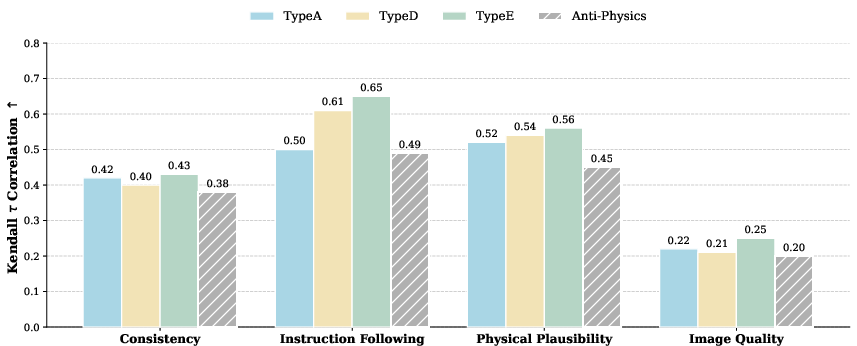
Figure 6: Human vs. VLM evaluation correlation for different editing stages and reasoning metrics (Kendall τ coefficients).
Implications and Future Directions
PhyEditBench redefines the standard for evaluating generative editing models by integrating real-world physics, multi-stage trajectories, and counterfactual scenarios. The empirical results unequivocally demonstrate that state-of-the-art models—even with large-scale pretraining—are fundamentally limited in their capacity for physical reasoning, frequently violating laws of motion, fluid dynamics, or material deformation. Video-generation-based world models, as exemplified by PhyWorld and ChronoEdit-14B, unlock deeper reasoning capabilities by leveraging temporal causality and implicit simulation, suggesting a paradigm shift: editing should be treated as state evolution rather than static transformation.
Practically, PhyEditBench’s granular evaluations will drive the development of editing frameworks capable of robust physical deduction, alignment with real-world dynamics, and counterfactual reasoning. From a theoretical standpoint, this work paves the way for compositional world models integrating explicit physical simulators, hybrid vision-language architectures, and evolutionary test-time optimization. Future research may focus on scaling world-model training, integrating differentiable physical engines, and extending benchmarks to multi-modality (audio, haptics) and interactive editing.
Conclusion
PhyEditBench provides an indispensable testbed for physics-grounded image editing, capturing the nuanced requirements of real-world visual reasoning. The evaluation unequivocally exposes the limitations of prevailing approaches and highlights the advantages of temporal modeling via pretrained video generation. PhyWorld, as a training-free baseline, advances the field and establishes a new upper bound on physically plausible editing. This benchmark and its associated methodology are poised to catalyze further research into physically aware generative models, ultimately improving their deployment in real-world applications requiring dynamic and robust reasoning (2606.26551).

