- The paper introduces PhyEdit, a framework that integrates explicit 3D priors and joint 2D–3D supervision to enable accurate, physically-consistent image editing.
- It leverages a Diffusion Transformer backbone and a novel 3D transformation module to deliver precise spatial manipulation, achieving significant improvements in DIoU and Chamfer Distance.
- The study also presents RealManip-10K and ManipEval, providing comprehensive benchmarks and datasets for evaluating geometric accuracy and physical plausibility in real-world scenarios.
Physically-Grounded 3D Object Manipulation in Image Editing with PhyEdit
Motivation and Context
Accurate, physically-consistent object manipulation in image editing is a critical requirement for interactive world modeling, including robotic systems and visual planners. Existing state-of-the-art diffusion-based generative models, even when equipped with explicit coordinate instructions, lack mechanisms to harness 3D geometry and perspective projection laws, resulting in spatial inaccuracies such as erroneous scaling, depth placement, and occlusion handling. This limitation is further exacerbated by the absence of real-world datasets and benchmarks tailored to 3D-aware manipulation. The paper introduces PhyEdit, a novel image editing framework leveraging explicit geometric simulation through plug-and-play 3D priors, complemented by joint 2D–3D supervision to achieve precisely controlled object manipulation. Additionally, the authors construct RealManip-10K, a robust real-world dataset, and ManipEval, a benchmark with multi-dimensional metrics for evaluation of geometric accuracy and physical plausibility.
Methodology
PhyEdit integrates a Diffusion Transformer (DiT) backbone with a 3D foundation model to inject geometric priors and to supervise manipulation actions at both latent and depth levels. The system comprises three primary components:
- 3D Transformation Module: Processes user or ground-truth inputs to generate depth-aware previews using the predicted depth and camera pose, enabling direct 3D-space object editing. This preview is supplied to the DiT as a conditioning signal.
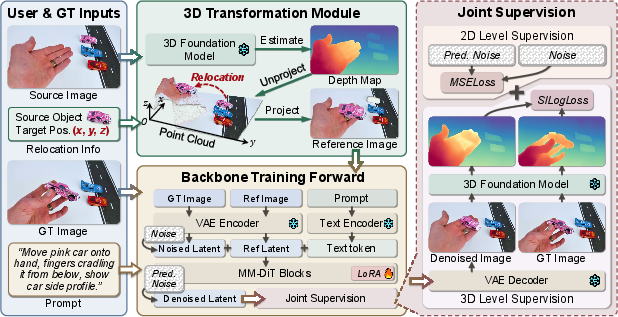
Figure 1: PhyEdit system overview, detailing the flow of user and ground-truth inputs through the 3D transformation module, followed by backbone execution and joint 2D–3D supervision.
- DiT Denoising Backbone: Accepts multi-modal tokens summarizing text prompts, noisy image latents, and preview conditions, training a velocity predictor to match ground-truth directions for generative editing steps.
- Joint 2D–3D Supervision: Augments the latent denoising loss with an explicit depth-space supervision term using pixel-wise scale-invariant logarithmic loss (SILog), thereby aligning both appearance and geometric correctness.
On the dataset side, RealManip-10K provides paired real-world images, annotated with depth maps, object masks, and 3D coordinates, curated via a pipeline involving high-quality video sources, static camera filtering using DBSCAN clustering on camera tokens, robust mask propagation, and depth-aware frame selection.

Figure 2: Examples from RealManip-10K, showing annotated objects and diverse geometric transitions in real-world scenes.
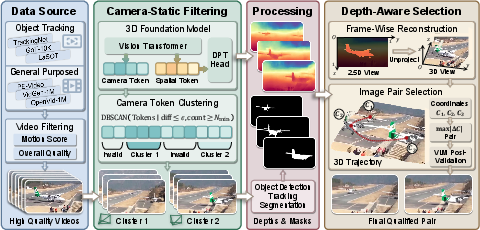
Figure 3: RealManip-10K construction pipeline, outlining data source filtering, static camera extraction, mask/depth generation, and depth-aware pair selection.
ManipEval evaluates manipulations with metrics across five axes: 2D spatial accuracy (DIoU, Mask IoU), depth accuracy (AbsRel, δ1.25), 3D geometry (Chamfer, centroid distance), image quality (RA-DINO, DeQA), and VLM-mediated physical plausibility.
Empirical Results
PhyEdit demonstrates superior manipulation accuracy and geometric consistency on ManipEval, outperforming both specialized and commercial baselines, including prominent closed-source systems. Key quantitative highlights:
- DIoU (2D spatial accuracy): PhyEdit achieves 65.33, a 5.36 point increase over Nano Banana Pro.
- Chamfer Distance (3D placement): Reduced to 18.93, a 6.40 point improvement versus Nano Banana Pro.
- RA-DINO (relocation-aware consistency): Highest among all baselines (36.91).
- Phys-VLM (physical plausibility): Best score (93.72), indicating strong realism and scene coherence.
These trends persist across both single-object and multi-object scenarios, with PhyEdit maintaining its geometry advantage as complexity rises.

Figure 4: ManipEval qualitative comparisons, illustrating PhyEdit's superiority in manipulation accuracy, geometric consistency, and multi-object control.
Ablation studies validate the joint depth supervision strategy, revealing pixel-level depth alignment to be most effective. The inclusion of reference images—3D-transformed visual previews—markedly enhances spatial fidelity, overcoming limitations of text-only conditioning.
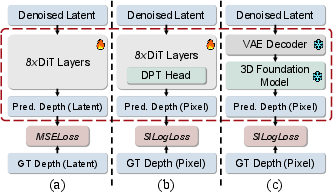
Figure 5: Architectural distinctions between depth supervision methods, emphasizing the efficacy of pixel-level supervision.

Figure 6: Visual comparison illustrating the indispensable role of depth supervision for precise object localization.
PhyEdit also generalizes to continuous manipulations along trajectories, enabling physically plausible sequence rendering for downstream video synthesis, as demonstrated with out-of-distribution robotic motion.

Figure 7: Continuous trajectory-based manipulation, affirming strong generalization to complex, unseen scenes and objects.
Practical and Theoretical Implications
Practically, PhyEdit constitutes a robust solution for physically-grounded image manipulation in real-world contexts, crucial for robotics, simulation, and interactive visual planning. It raises the performance ceiling for current open and commercial systems, particularly in multi-object and scene-constrained scenarios.
Theoretically, the results underscore the necessity of explicit 3D guidance and joint supervision. The framework establishes a methodology for plug-and-play geometric priors, highlighting the limitations of text-conditioned world models and pinpointing key pathways to enhanced spatial reasoning.
A critical bottleneck remains in translating complex spatial intent through text prompts alone. Addressing this gap, either via improved language encoders or automated visual guidance synthesis from language, is pivotal for the evolution of fully interactive world models.
Future Directions
The authors propose strengthening text-visual co-prompting, expanding the dataset with more challenging cases, integrating reinforcement learning for intent alignment, and broadening applicability to trajectory-conditioned video editing and fast inference. These efforts aim to further advance controllability, robustness, and real-world utility.
Conclusion
PhyEdit introduces an effective framework for physically-grounded image editing, establishing state-of-the-art manipulation accuracy and geometric fidelity through explicit 3D priors and joint 2D–3D loss. The accompanying RealManip-10K dataset and ManipEval benchmark provide essential resources for rigorous evaluation. Empirical and qualitative evidence positions PhyEdit as a key step towards interactive, physically consistent world models, with substantial implications for advancing spatial reasoning in AI systems.