- The paper introduces a two-tiered benchmark that disentangles intuitive physics from precise parameter estimation to diagnose video generative models.
- The paper reveals that current WFMs show high variance and reliance on training priors, failing to accurately model key physical parameters.
- The paper highlights the necessity for architectural innovations to achieve robust physical grounding in next-generation generative models.
Concept-Specific Diagnostic Benchmarking of Physical Scene Understanding in World Foundation Models
Introduction
The evolution of world foundation models (WFMs) for video generation raises persistent questions about their fidelity in simulating authentic physical processes. "WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models" (2601.21282) presents a rigorous, disentangled diagnostic benchmark expressly tailored to quantify and localize the physical reasoning capabilities and deficiencies of video-generative WFMs. This work identifies and addresses a significant deficiency in prevailing benchmarks: the entanglement of multiple physics concepts in single tests and the excessive reliance on coarse or binary metrics, which impede nuanced model diagnosis. WorldBench thus establishes a two-tiered framework—intuitive physics and parameter estimation—facilitating in-depth, concept-specific model assessment and highlighting the current generation’s deficiencies in both generalization and parameter adherence.
Benchmark Structure and Methodology
WorldBench is specifically architected to evaluate WFMs’ capacity for concept-level physical scene understanding via video prediction tasks. The benchmark comprises two principal subsets: one targeting intuitive physics concepts and the other evaluating precise estimation of physical parameters. Synthetic and real videos are leveraged, with all simulated videos generated via Kubric (PyBullet for physics, Blender for rendering).
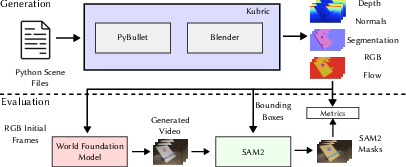
Figure 1: Overview of the generation and evaluation process: video continuation generation (top), evaluation pipeline using object segmentations (bottom).
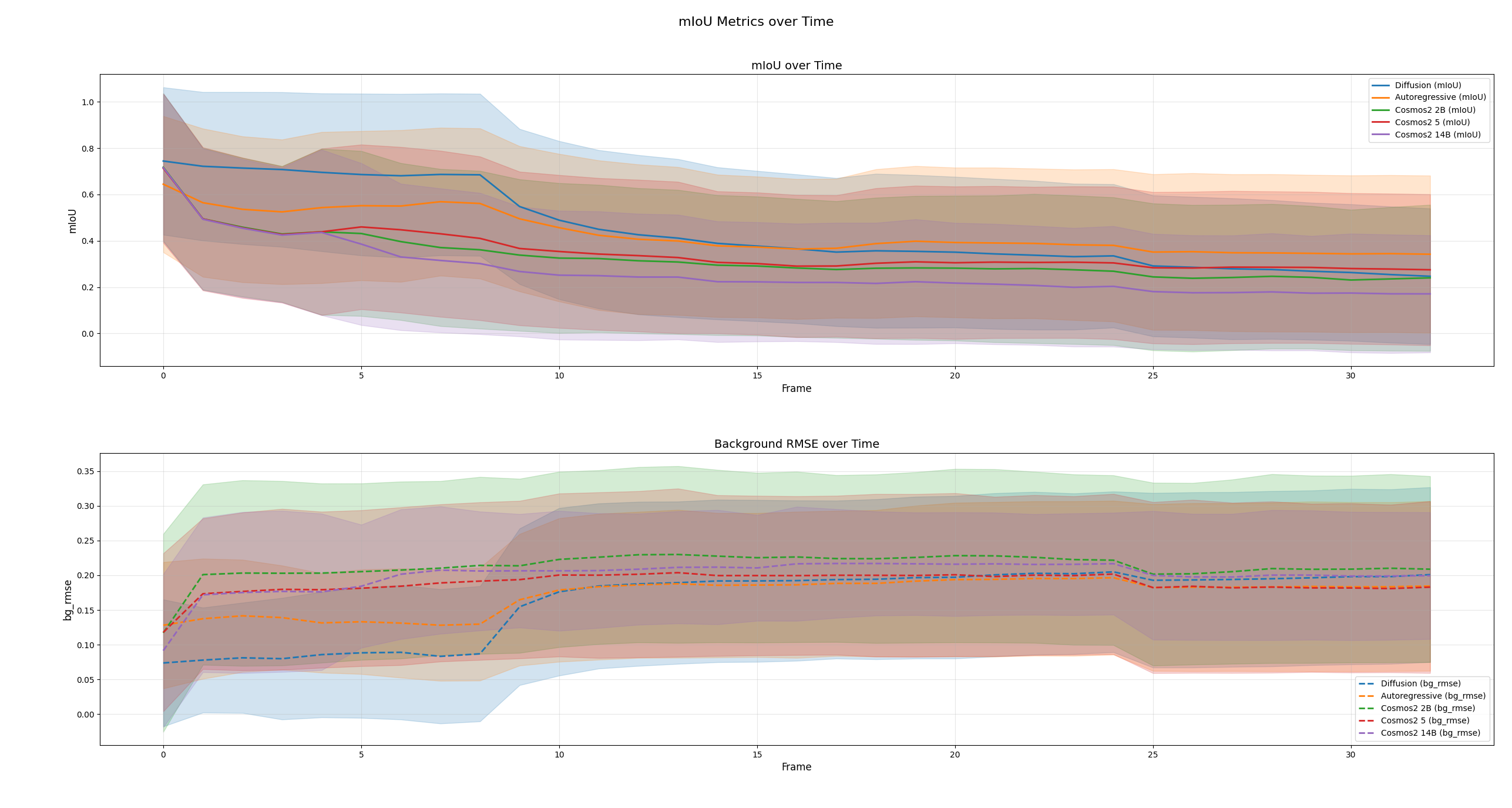
The evaluation protocol involves feeding WFMs several initial frames and requiring them to predict video continuations under a constrained setup designed to test single physics concepts. Post-prediction, the video sequences are passed to the SAM2 segmenter for object tracking; predicted segmentations are compared framewise to ground truth via metrics such as foreground mIoU and background RMSE.
Intuitive Physics Module
This module targets four fundamental concepts: motion physics, support relations, object permanence, and scale/perspective. Each scenario is systematically constructed, with multiple videos per scenario undergoing controlled randomization in object type, initial conditions, and material. This design isolates the core property under assessment and avoids confounding factors.

Figure 2: Qualitative examples for the Motion Physics scenario of the intuitive physics subset—demonstrating object collision and subsequent dynamics.

Figure 3: Qualitative examples for the Support Relations scenario—testing balance and stability after a roll-down and collision.

Figure 4: Qualitative examples for Object Permanence—evaluating WFMs' ability to track occluded objects correctly.
Physical Parameter Estimation Module
Designed for explicit, engineering-grade testing, this subset isolates the capacity to simulate and infer specific material constants or physical laws (e.g., gravitational acceleration, friction coefficients, viscosity). For each controlled scenario, physical parameters are systematically varied, and object trajectories are designed to minimize ambiguity. The calibration protocol employs checkerboard-based pose estimation and careful depth standardization, enabling accurate 3D object localization and parameter extraction via curve-fitting.
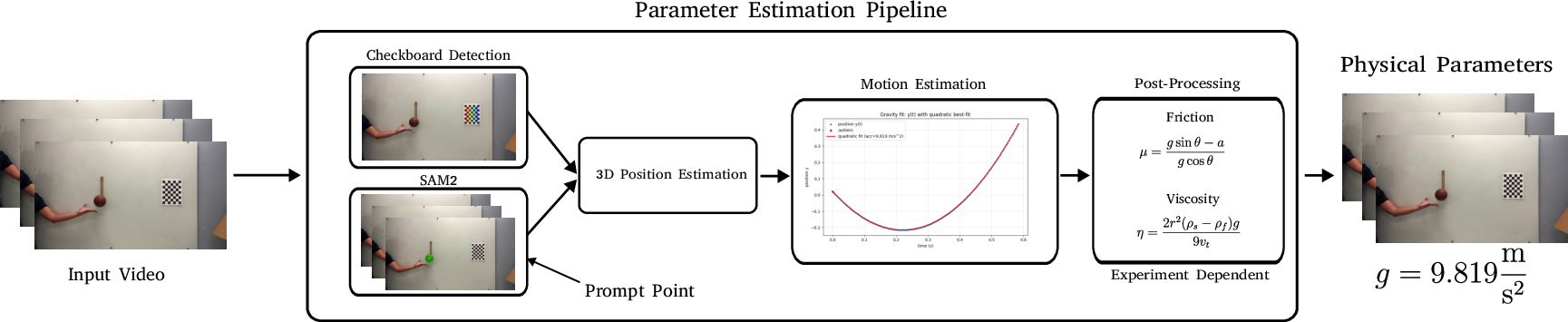
Figure 5: Pipeline for physical parameter estimation: checkerboard and SAM2-based 3D object localization, parameter curve fitting.

Figure 6: Samples from the friction coefficient scenario: a steel block's trajectory on material-varied ramps.
Experimental Results and Empirical Findings
State-of-the-art WFMs (notably, various Cosmos variants and several prominent I2V models) were comprehensively evaluated. Strong empirical observations were established:
Implications for Physical AI and Diagnostic Evaluation
WorldBench’s contributions transcend benchmarking: the explicit disentanglement of physical concepts exposes the lack of genuine parameterization in current WFMs and provides actionable diagnostic granularity. The video-first, concept-targeted design makes it uniquely aligned to contemporary model architectures, as previous benchmarks require binary selection or confound multiple concepts per sample.
From an application perspective, the benchmark unmasks a critical roadblock for physically grounded generative models as simulators—to be reliable as synthetic data sources or for autonomous planning, WFMs must internalize true physical constants and not merely replicate plausible video patterns. The demonstrated limits further imply that simply scaling video datasets or models will not automatically confer physical grounding; architectural advances or explicit physical inductive biases may be necessary.

Figure 8: Model-specific qualitative failures: autoregressive model distorts shapes, diffusion model hallucinates unrealistic features.

Figure 9: SAM2 sustaining object identities through occlusion; supporting robust mask-based metric computation.
Future Prospects
The WorldBench diagnostic framework provides an extensible foundation for future physical reasoning benchmarks. Its modularity permits the addition of new physical concepts (e.g., optics, collision mechanics) and could incorporate more complex multi-object or interactive scenarios. Integrating more diverse sensors/modalities or supporting fine-grained intervention-based physical probing remains important future work. In model development, progress in physically grounded neural architectures or hybrid data-driven/analytical training may be catalyzed by such rigorous, isolating diagnostics.
Conclusion
WorldBench (2601.21282) represents a substantive advancement in model benchmarking for physical scene understanding: it forgoes entangled, coarse metrics in favor of meticulously designed concept-specific, video-continuation-based evaluations, and reveals the pronounced limitations of current WFMs in both physical abstraction and parameter adherence. This diagnostic granularity is a necessary step for advancing toward physically reliable generative models and sets a baseline for both model and benchmark evolution in physical AI research.