Physics Question Scene Graph: Fine-grained Evaluation of Physical Plausibility in Text-to-Video Generation
Abstract: Video generation models are increasingly capable of producing realistic videos, but they still struggle to generate videos that follow basic physical laws. Compounding this is a lack of reliable granular evaluation methods for localizing and specifying physical law violations in videos. We address this by introducing Physics Question Scene Graph (PQSG), a hierarchical question-based evaluation pipeline. PQSG evaluates generated videos by checking their faithfulness to a prompt across objects, actions, and adherence to physical laws using a graph-based hierarchy of questions generated by a vision-LLM (VLM), guided by high-quality in-context examples. By representing questions as a graph, PQSG introduces logical dependencies within questions, ensuring that each query is contextually valid. Moreover, PQSG provides granular assessments of which qualities of the video violate physical plausibility constraints. We validate PQSG by creating FinePhyEval, a dataset with physics-based prompts and corresponding generated videos from diverse state-of-the-art video generation models (Sora 2, Veo 3, and Wan 2.1), with each video annotated across multiple categories by humans. Using FinePhyEval, we measure the correlation between PQSG's fine-grained scores and human judgments, showing higher overall correlations than prior work. We also find that PQSG ranks closed-source models higher than Wan 2.1 on physical realism. Lastly, we show that the annotations we provide in FinePhyEval can also be used for subtask evaluation: we benchmark two strong VLMs on generating and answering questions, finding that while models can create human-like questions, they still fall short of human performance in answering them.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a big problem with AI systems that make short videos from text: many of these videos look real but break basic physics (like liquids flowing the wrong way or objects not falling correctly). The authors introduce a new way to judge these videos called Physics Question Scene Graph (PQSG). It’s like a smart checklist that asks step-by-step questions to see if a video matches the text prompt and follows the laws of physics.
What questions were the researchers asking?
In simple terms, they wanted to know:
- How can we precisely tell whether a generated video follows the prompt and basic physics?
- Can we point out exactly where the video goes wrong (missing objects, wrong actions, or bad physics), instead of giving just one overall score?
- Can an automated system (using AI) judge videos in a way that agrees with what people think?
- How well can current AI models ask good questions about physics and answer them reliably?
How did they do it?
Think of grading a science lab video. You wouldn’t jump straight to “Does the experiment follow physics?” First you’d check:
- Are the right materials there?
- Did the correct actions happen?
- Do those actions look physically believable?
That’s exactly how PQSG works, but with a little more structure.
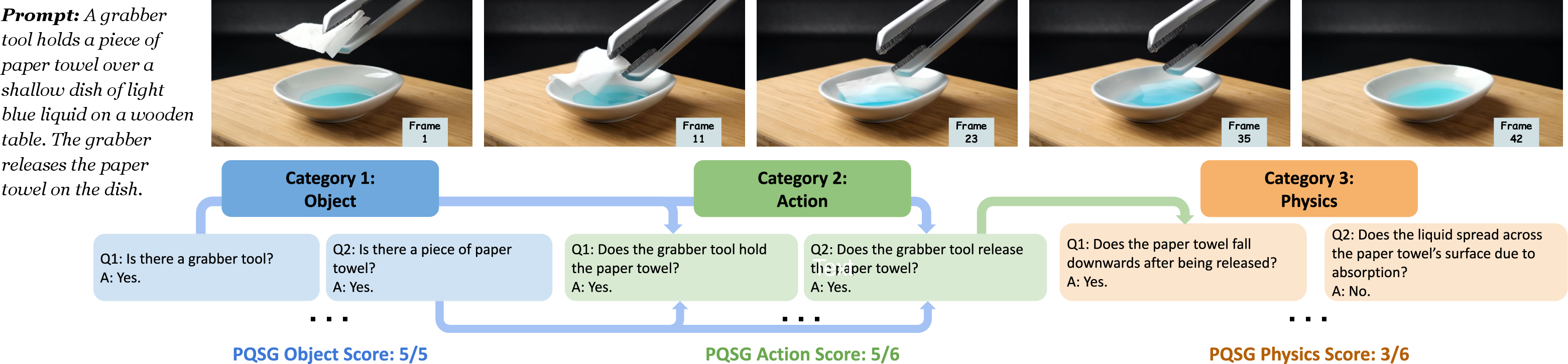
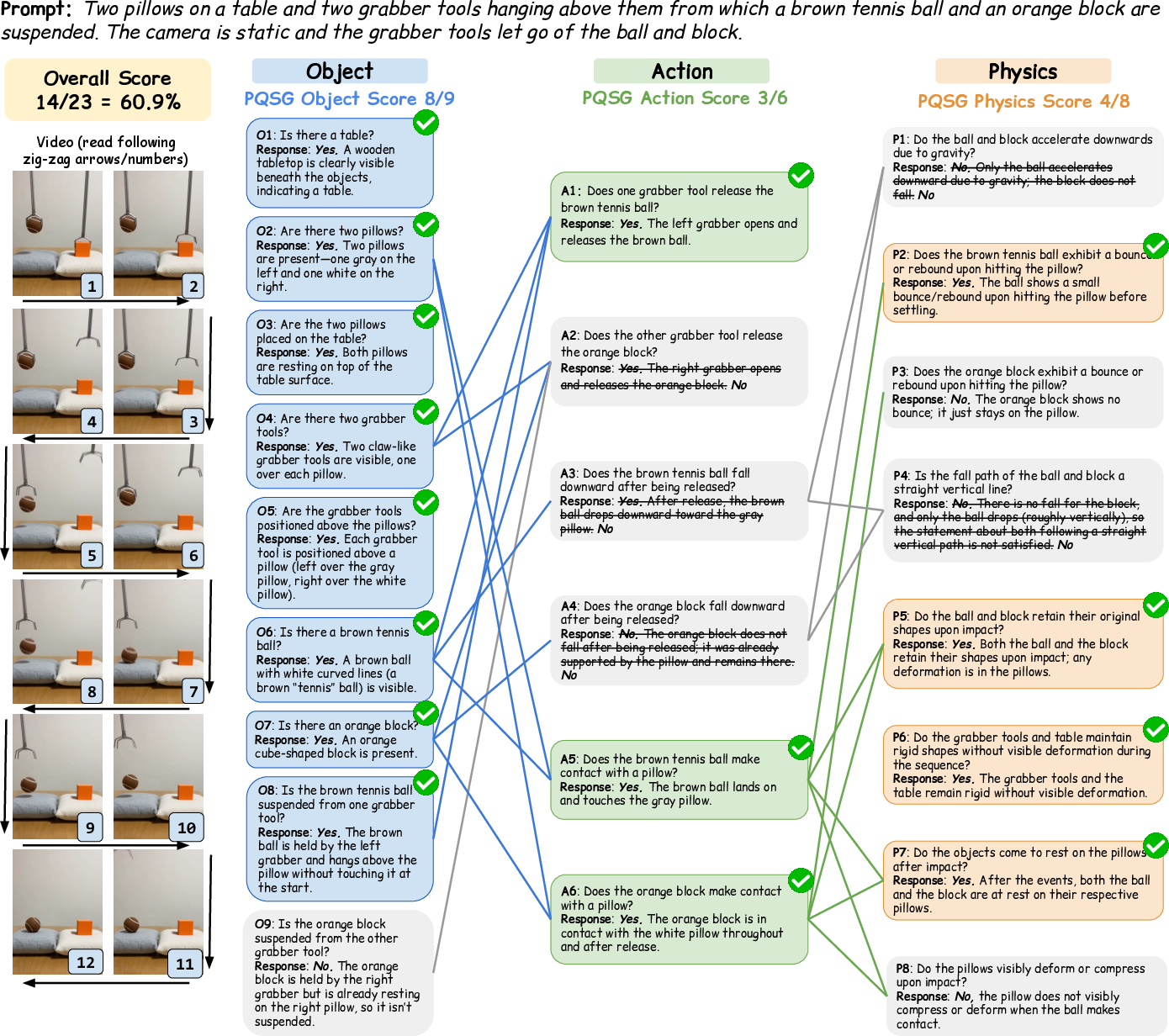
The PQSG approach (what it is, in everyday terms)
- PQSG builds a “question graph” — a structured set of yes/no questions that follow a sensible order, like a flowchart or quest tree in a game.
- The questions are grouped into three layers:
- Object: Are the right things in the video? (e.g., “Are there two pillows?”)
- Action: Are the right things happening? (e.g., “Does the grabber release the ball?”)
- Physics: Do those actions look physically correct? (e.g., “Do the pillows compress when the ball hits them?”)
The graph has dependencies: you only ask an action question if the object is actually there; you only ask a physics question if the action really happens. If the object is missing, the action and physics questions that depend on it are marked “not applicable” (and counted as “no”).
Two main steps (using vision-LLMs, or VLMs)
- Step 1: Question Generation (QG) An AI model reads the text prompt and creates the question graph—clear, atomic yes/no questions about objects, actions, and physics, in the right order.
- Step 2: Question Answering (QA) Another AI model watches the video and answers the questions. To improve accuracy, it first writes a short explanation, then turns that into a yes/no answer.
Together, this creates fine-grained scores:
- Object score: how well objects match the prompt
- Action score: how well actions match
- Physics score: how physically believable the events are
- An overall score (from all questions)
The dataset they built: FinePhyEval
To test PQSG fairly, the authors made a dataset called FinePhyEval:
- They took physics-focused prompts from a previous set (Physics-IQ) and generated videos from several top models (like Sora 2, Veo 3, Wan 2.1, and a physics-focused model called Cosmos).
- People then rated each video on a 1–5 scale for objects, actions, physics, and an overall score.
- They also had people create and answer some of the questions so they could check how well the AI models were doing at both asking and answering.
What did they find?
Here are the main results:
- PQSG matches human judgment better than previous methods that give just one coarse score. In other words, it agrees more with what people think is good or bad in the videos.
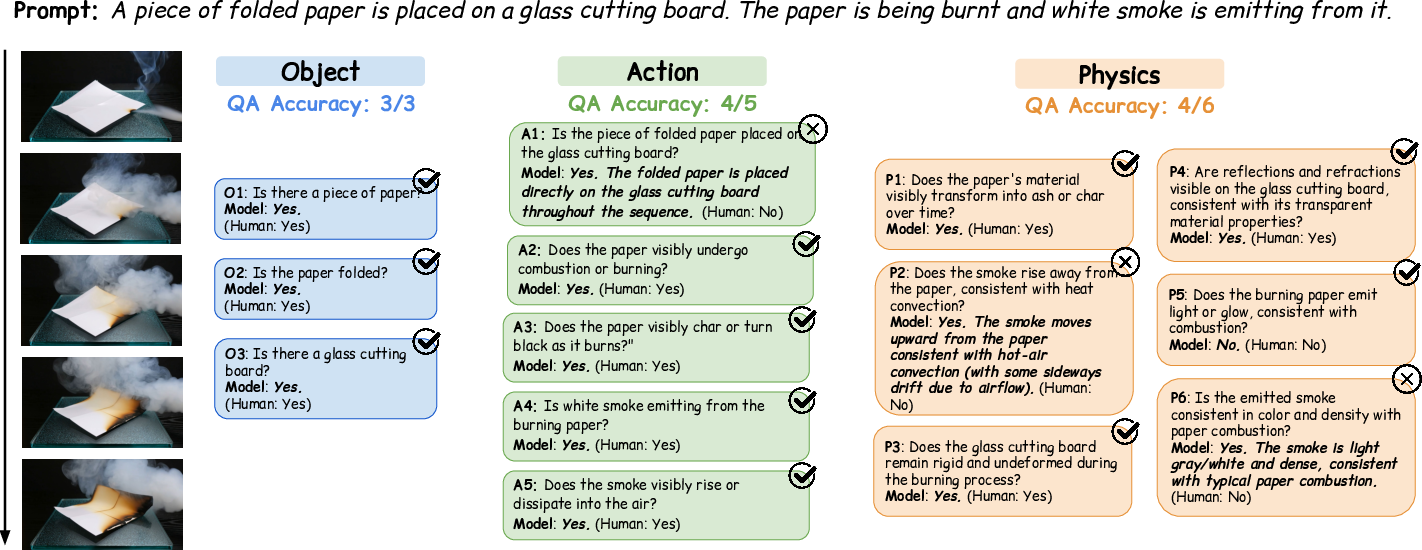
- It’s much better at telling you exactly what went wrong: missing objects, wrong or missing actions, or physics mistakes (like a towel “dissolving” into liquid instead of absorbing it).
- Across video models, objects are usually done best, actions are harder, and physics is the hardest. Even strong video generators struggle with realistic physical interactions.
- In their tests, proprietary models (like Sora 2 and Veo 3) scored better overall than open-source ones (like Wan 2.1 and Cosmos) on physical realism.
- The “question generation” part works very well — AI can create human-like questions with high precision and recall.
- The “question answering” part is decent for objects and okay for actions, but weaker for physics. For example, a strong model got about 88% correct on object questions but only around 65% on physics questions.
- PQSG can help improve videos through iterative prompt refinement. Using the detailed feedback, they refined prompts and saw clear score improvements after one or two rounds.
- Removing key design choices (like the logical dependencies or fine-grained questions) made the system worse, showing those pieces are important.
Why does this matter?
- Better evaluation = better videos. If we can pinpoint whether a video fails because it’s missing objects, shows the wrong actions, or breaks physics, creators and researchers can fix the right things.
- It’s crucial for real-world uses. For example, training robots, virtual agents, or making safety-critical simulations needs physically believable videos—not just pretty ones.
- It pushes AI to understand the real world. Moving beyond “looking real” toward “being physically correct” makes AI more reliable and useful for science, engineering, and education.
- PQSG has room to grow with better AI. Since the system uses AI to answer questions, as those models get better at reasoning about physics, the evaluations (and guided improvements) will get even more accurate.
In short
- The paper presents PQSG, a clear, step-by-step way to evaluate AI-made videos for objects, actions, and physics.
- It uses a smart question graph so it doesn’t ask nonsense questions (like judging a fall when the ball isn’t even there).
- It aligns better with human opinions than past methods and shows exactly where a video went wrong.
- Today’s AI is good at spotting objects, fair at actions, and still learning physics — but PQSG helps chart the path forward.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Reliance on VLM QA accuracy: PQSG’s ceiling is bounded by VLM QA (≈65% accuracy on physics). How can QA be improved (e.g., via fine-tuned video-VLMs, temporal CoT, debiasing, or hybrid symbolic–numeric checks)?
- Yes-bias and calibration: The QA models show a “yes-bias,” especially on nuanced physics. What methods best mitigate this (balanced question sets, calibrated likelihoods, adversarial prompts, or confidence scoring)?
- Binary answers only: PQSG uses yes/no labels, which cannot capture partial compliance, frequency, or degree (e.g., “sometimes,” “slightly deforms”). Can node-level probabilistic/graded scoring or temporal coverage metrics yield better alignment with human judgments?
- Conflation of unanswerable vs. violation: Children of failed parent nodes are auto-marked “no,” conflating “not applicable due to missing prerequisites” with genuine violations. Would a tri-state labeling (pass/fail/not-applicable) or separate attribution scores improve interpretability and fairness?
- Aggregation and weighting: Overall scores are simple averages of node-level yes/no, which may over-weight categories with more nodes and may not reflect human emphasis on physics (r=0.85 with overall). How should node/category weights be learned or calibrated to human preferences?
- Edge/DAG quality unvalidated: QG evaluation covers question precision/recall but not the correctness of dependency edges. How accurate are edges, and what is the impact of edge errors on downstream scores?
- Small subtask annotations: QG (20 prompts) and QA (30 prompt–video pairs, 444 QA pairs) human labels are limited. Larger-scale, publicly released edge- and QA-annotated sets are needed to robustly evaluate QG/QA reliability.
- Dataset diversity and coverage: FinePhyEval (195 videos, 65 prompts) is relatively small and may underrepresent key physics (non-Newtonian fluids, friction, elasticity, soft-body deformation, optics). Expand prompts to a standardized physics taxonomy with balanced coverage.
- Short clips and limited temporal complexity: Experiments use 4–6 second clips; long-horizon dynamics, cumulative effects, and delayed consequences remain untested. Can PQSG scale to minute-long videos and multi-stage interactions?
- FPS/resolution confounds: Video generators output different fps/resolutions, and QA models process differing fps. How much do these factors confound rankings, and should frames/resolution be normalized to ensure fairness?
- Generalization beyond prompt-entailment: PQSG evaluates only prompt-specified interactions; unprompted violations (e.g., background objects violating gravity) are ignored. Can unsupervised physics-consistency checks complement prompt-conditioned evaluation?
- Use of reference videos: The paper mentions experimenting with adding reference videos in QG but reports no results. What is the effect of reference videos on QG/QA quality, and can they anchor quantitative checks (e.g., motion similarity)?
- Perception bottlenecks: QA failures often involve occlusion, small fast-moving objects, smoke/fluids. Would integrating perception modules (tracking, depth, optical flow, segmentation) improve answerability and reduce hallucinations?
- Statistical significance and uncertainty: Correlation improvements are reported without formal significance tests/intervals. Provide bootstrap CIs and significance for model comparisons and ablations.
- Scalability and cost: PQSG performs two-step QA per node. What are the latency/cost profiles for large graphs, longer videos, and large-scale benchmarking, and how can batching/sparse querying/frame caching reduce cost?
- Robustness to language variation: QG uses a single in-context example and English prompts. How robust is PQSG to multi-lingual prompts, adversarial phrasing, or domain-specific jargon? What is the effect of ICL count and prompt templates?
- Edge-case physics and camera effects: Complex optics (reflections, refractions, motion blur), contact/friction nuances, and non-Newtonian behaviors are not explicitly stress-tested. Design targeted prompts and node templates for these regimes.
- DAG learning vs. prompting: Edges are prompt-generated by VLMs. Could edge structures be learned/verified (e.g., with causal discovery or human-in-the-loop review) to reduce spurious dependencies?
- Human–metric alignment: Correlations are moderate and higher with human QA (Pearson r≈0.80). Which components (QG, QA, aggregation) most limit alignment, and can learning-to-rank or meta-evaluation close the gap?
- Iterative refinement validation: PQSG-guided prompt refinement shows score gains, but no human-perception validation is reported. Do PQSG improvements translate to human-rated improvements and downstream task performance (e.g., robotics)?
- Real-world validation: PQSG is evaluated on generated videos; it is unclear how well it identifies physics plausibility in real-world videos with ground-truth outcomes. Create a real-video benchmark to test external validity.
- Reproducibility and openness: Heavy reliance on proprietary VLMs/APIs limits reproducibility. Establish open-source baselines, fixed seeds, and versioned model cards; examine consistency across multiple open VLMs.
- Safety against gaming: Models could overfit to PQSG’s question style. Develop question randomization, adversarial test sets, and rotation of node templates to detect and discourage metric gaming.
- Node/question taxonomy: Physics nodes lack a standardized mapping to labeled physics categories. Introduce a canonical taxonomy with per-law failure analytics to guide targeted model improvements.
- Uncertainty reporting: PQSG provides point scores without per-node confidence or disagreement modeling. Add uncertainty estimates (e.g., via self-consistency, ensembles, or human–model disagreement flags) to inform decision-making.
Practical Applications
Immediate Applications
These applications can be implemented now with current PQSG capabilities, off-the-shelf VLMs, and short video lengths (≈4–6 seconds), as demonstrated in the paper.
- Physics-aware evaluation suite for text-to-video model developers
- Sector: Software/AI; Media/Entertainment
- What: Integrate PQSG as a QA “linter” that scores generations by Objects, Actions, and Physics, with a dependency graph that localizes failures and reduces hallucinated checks.
- Tools/workflows:
- PQSG-as-a-service API or internal microservice.
- CI/CD gates for model releases; nightly regression dashboards with per-category leaderboards; slice analysis by prompt types (fluids, deformation, collisions).
- Automatic report generation for each model checkpoint (with confidence intervals across repeated QG runs).
- Assumptions/dependencies:
- Access to a capable VLM for QA (e.g., GPT‑5.5, Gemini‑2.5‑Pro) and acceptable inference costs.
- Prompts are available for every video (PQSG only evaluates prompt-entailments).
- Best results on short clips; physics QA accuracy currently ~65% for complex dynamics.
- Fine-grained prompt debugging and iterative refinement for creators
- Sector: Media/Entertainment; Creative tooling; Advertising
- What: Use PQSG’s node-level feedback to automatically refine prompts and re-generate videos until target physics/object/action scores are met.
- Tools/workflows:
- “Physics Linter” panel in video-gen UIs that shows a graph of failed checks and suggested prompt edits (as shown in the paper’s refinement loop with ~15% gain in one iteration).
- Batch refinement for shots in a storyboard; stop criteria based on category thresholds (e.g., Physics ≥ 0.8).
- Assumptions/dependencies:
- Generator accepts iterative prompt updates; additional latency/cost for multiple rounds.
- VLM QA bias (e.g., yes-bias) should be mitigated via two-step reasoning used in PQSG.
- Dataset curation for synthetic training data
- Sector: Robotics; Autonomous systems; Perception research; Simulation
- What: Filter out physically implausible or action-inaccurate synthetic videos before using them for training perception or world models.
- Tools/workflows:
- PQSG batch scoring on large corpora; threshold-based pruning; category-specific sampling (keep high-Physics clips).
- Weighted sampling based on PQSG Physics scores for curriculum learning.
- Assumptions/dependencies:
- Training tasks benefit from physically plausible synthetic data; short-clip physics checks are adequate proxies for downstream tasks.
- Compute budget for large-scale evaluation.
- Benchmarking and academic evaluation
- Sector: Academia/Research; Standards communities
- What: Adopt FinePhyEval and PQSG to compare models on fine-grained physics, action, and object fidelity, beyond single-score metrics.
- Tools/workflows:
- Public leaderboards reporting category-wise scores and human correlation statistics.
- Subtask benchmarks (QG, QA) to track VLM progress on spatiotemporal/physical reasoning.
- Assumptions/dependencies:
- Broad availability of model outputs on a public prompt set; willingness to report per-category metrics.
- Post-generation quality control for ads and e-commerce content
- Sector: Advertising; E-commerce; Compliance
- What: Automatically flag product videos that depict physically impossible behavior (e.g., “paper towel dissolves into liquid”) before publication.
- Tools/workflows:
- PQSG run with known creative brief/prompt; violations routed to human reviewers; remedial prompt suggestions.
- Assumptions/dependencies:
- Prompts or structured briefs are available; physics checks are “commonsense” rather than domain-specific standards.
- Legal/compliance teams accept model-assisted triage.
- Educational content authoring support
- Sector: Education
- What: Help teachers/students generate short physics demonstration videos and receive structured feedback on whether key phenomena (e.g., gravity, deformation, absorption) are visible and plausible.
- Tools/workflows:
- PQSG-backed rubric for lab video assignments; question graphs converted to checklists; automated hints for re-shoot or re-generation.
- Assumptions/dependencies:
- Focus on short, commonsense physics clips; PQSG does not evaluate phenomena not entailed by prompts.
- MLOps health monitoring for deployed generative services
- Sector: Software/AI operations
- What: Track drift in physics plausibility across releases, deployments, or A/B experiments.
- Tools/workflows:
- PQSG telemetry on sampled generations; alerting on Physics score drops; root-cause via node-level diffs across versions.
- Assumptions/dependencies:
- Access to representative prompts and permission to run periodic evaluations.
- Model training signals via reward shaping or sample reweighting
- Sector: Software/AI research
- What: Use PQSG scores as auxiliary objectives for RLHF/RLAIF, preference optimization, or rejection sampling to emphasize physics-consistent outputs.
- Tools/workflows:
- Off-policy filtering (keep top‑physics samples); reward models distilled from PQSG labels; per-category loss weighting.
- Assumptions/dependencies:
- Latency of PQSG scoring during training; careful handling of QA noise (especially for physics) to avoid reward hacking.
Long-Term Applications
These opportunities require advances in VLM QA accuracy for physical reasoning, broader domain coverage, longer videos, or integration into safety-critical systems.
- Physics-aware guardrails and disclosures for generative media platforms
- Sector: Policy/Regulation; Media platforms
- What: Standardized “Physics Score” disclosures or badges for AI-generated videos; automatic warnings when scenes conflict with basic laws (to avoid misleading claims).
- Tools/workflows:
- Industry benchmarks (built on PQSG/FinePhyEval extensions) for reporting; platform APIs for badge rendering; audit trails of PQSG graphs.
- Assumptions/dependencies:
- Regulatory consensus on acceptable thresholds; governance around prompts/metadata; improved robustness beyond short clips and general physics.
- Real-time generation steering via physics feedback
- Sector: Software/AI; Media production; Game/VR engines
- What: Use fast, streaming PQSG-like checks (or distilled surrogates) to steer diffusion or autoregressive generation toward plausible trajectories in the loop.
- Tools/workflows:
- Lightweight, differentiable surrogates trained on PQSG-labeled data; token-level control policies for physics-aware guidance.
- Assumptions/dependencies:
- Sub‑second physics scoring; stability of control signals; efficient integration into generation kernels.
- Autonomous robotics and embodied agent training
- Sector: Robotics; Industrial automation; Logistics
- What: Verify the physical plausibility of imagined rollouts or synthetic demonstrations used for training policies; downweight unrealistic training episodes.
- Tools/workflows:
- PQSG-inspired evaluators for multi-view or egocentric videos; pipeline hooks in imitation learning/simulation-to-real workflows.
- Assumptions/dependencies:
- Extension to longer horizons and task-specific physics; alignment between visual plausibility and dynamics relevant to control.
- Domain-specialized physics evaluators (e.g., surgical training, automotive, energy)
- Sector: Healthcare; Automotive/AV; Energy/Utilities
- What: Extend PQSG with domain ontologies and physics-specific question banks (e.g., tissue deformation, fluid perfusion, tire-road interaction, turbine mechanics) for simulation and training content QA.
- Tools/workflows:
- Co-designed taxonomies with SMEs; integration with simulators and multi-modal data (e.g., telemetry); human-in-the-loop validation sets.
- Assumptions/dependencies:
- Availability of domain-labeled datasets; higher QA accuracy on fine-grained, domain physics; risk management for high-stakes use.
- Open-world physical plausibility checking without prompts
- Sector: Safety; Misinformation moderation
- What: Generalize beyond prompt-entailments to detect physically impossible events in arbitrary videos (e.g., moderation of fabricated stunts).
- Tools/workflows:
- Unprompted scene graph induction; learned priors over feasible dynamics; anomaly detection calibrated to temporal context.
- Assumptions/dependencies:
- Robust unprompted understanding of scene goals; expanded training corpora and benchmarks; strong safeguards against false positives.
- Multi-modal world modeling verification for planning systems
- Sector: Autonomous systems; Digital twins; Industrial simulation
- What: Evaluate predicted rollouts from learned world models with PQSG-like graphs, conditioning on task-relevant objects/actions and their physics.
- Tools/workflows:
- Pluggable verification layer in model-based planners; per-timestep consistency checks; feedback for model re-training.
- Assumptions/dependencies:
- Handling of long sequences and partial observability; correlating visual plausibility with true dynamics fidelity.
- Curriculum learning and targeted data acquisition
- Sector: AI research; Robotics; Education tech
- What: Use per-category error profiles (e.g., fluids vs. rigid-body) to prioritize data collection or synthetic generation where models are weakest.
- Tools/workflows:
- Active learning loops guided by PQSG distributions; procurement specs for new datasets; automatic prompt generators targeting rare physics.
- Assumptions/dependencies:
- Stable measurement across versions; availability of data sources for underrepresented phenomena.
- Human-in-the-loop authoring and assessment in STEM education
- Sector: Education
- What: Convert question graphs into interactive tutors that assess student videos or simulations and suggest precise improvements (e.g., “increase frame rate to resolve acceleration profile”).
- Tools/workflows:
- LMS plug-ins; rubric generation; alignment with curricula and standards (NGSS, AP Physics).
- Assumptions/dependencies:
- Better physics QA accuracy, longer video support, and explainability suitable for pedagogy.
- Compliance and risk analytics for financial/insurance exposure to AI media
- Sector: Finance; Insurance; Legal
- What: Screen AI-generated media in campaigns or filings for implausible physical depictions that could trigger consumer complaints or liability.
- Tools/workflows:
- PQSG-backed risk scoring; audit documentation; integration into procurement and vendor review pipelines.
- Assumptions/dependencies:
- Acceptance of physics scores as evidentiary signals; alignment with legal standards; traceability of prompts and generation metadata.
Cross-cutting assumptions and dependencies
- VLM QA performance: Present physics QA accuracy (~65% for complex scenes) limits reliability; correlation with humans improves as VLMs improve. Two-step QA (rationale then Y/N) mitigates some issues.
- Prompt availability: Current PQSG only assesses phenomena entailed by the prompt; unconstrained physics errors are out-of-scope without extensions.
- Clip length and fps: Experiments use short videos; longer horizons and subtle dynamics need higher fps and improved temporal reasoning.
- Cost and latency: Large-scale evaluation requires GPU budget and batching strategies.
- Closed-source reliance: Paper shows results with closed-source VLMs; open-source alternatives work but may reduce accuracy; reproducibility depends on model access.
- Bias management: Yes-bias and hallucinations need prompt engineering and dependency-graph gating (a core PQSG feature) to avoid invalid queries.
Glossary
- Ablation study: A controlled analysis where specific components of a system are removed or altered to measure their impact. Example: "As shown in our ablation study (\Cref{tab:ablation}), this dependency structure yields stronger human correlation than unstructured approaches."
- Action binding: The association of actions with specific objects, ensuring an action is evaluated only in relation to the correct entities. Example: "most of the action binding nodes have object existence nodes as parents, and most of the physics nodes have action binding nodes as parents."
- Attribute binding: Verifying that object attributes (e.g., color, size) are correctly realized. Example: "object existence (e.g., 'Is there a ball?') and attribute binding (e.g., 'Is the ball brown?')."
- Chain-of-thought reasoning: An LLM’s step-by-step reasoning process used to improve answer quality. Example: "we find that letting the QA model answer only with yes/no responses often discourage the use of chain-of-thought reasoning."
- Directed acyclic graph (DAG): A directed graph with no cycles, often used to encode dependencies. Example: "by defining the physical scene as a directed acyclic graph (DAG)."
- Force-based conditioning: Conditioning a generative model on inferred or specified physical force information to guide generation. Example: "implicit physical priors injected through vision-language reasoning or force-based conditioning"
- In-context examples: Demonstrations included in a prompt to steer a model’s behavior on a new instance. Example: "guided by high-quality in-context examples."
- Intraclass correlation coefficient (ICC): A statistic measuring consistency or agreement among raters. Example: "We also calculate the intraclass correlation coefficient (ICC) on a subset of FinePhyEval and find a high inter-annotator agreement of 0.84 across categories"
- Inter-annotator agreement: The degree to which different annotators provide consistent judgments. Example: "find a high inter-annotator agreement of 0.84 across categories"
- Kendall's tau (τ): A non-parametric rank correlation coefficient assessing ordinal association. Example: "We evaluate Pearson's , Kendall's , and Spearman's ."
- Likert scale: A psychometric scale (often 1–5) for measuring attitudes or judgments. Example: "Each score is measured in Likert-scale (1-5)."
- Pearson's r: A linear correlation coefficient measuring the strength of linear association between variables. Example: "We evaluate Pearson's , Kendall's , and Spearman's ."
- Physical commonsense: Implicit knowledge about everyday physical interactions and plausibility. Example: "leverages VLMs for assessing physical commonsense."
- Program-based generative models: Generative approaches that explicitly encode rules or programs (e.g., physics) to produce outputs. Example: "program-based generative models that explicitly encode physical laws"
- Prompt refinements: Iterative modifications to a text prompt to improve generation quality. Example: "Following previous work in prompt refinements \cite{hao2023optimizing, manas2024improving}, we design an iterative generation loop"
- Question Answering (QA): The task of answering verification questions about a video or scene. Example: "In the second stage -- question-answering (QA) -- these physics scene graphs are then passed with the generated video to a VLM to answer questions about the video"
- Question Generation (QG): The task of producing verification questions from a prompt or specification. Example: "first, in the question-generation stage (QG), we task vision-LLMs (VLMs) with generating hierarchical physics-aware graphs of questions from text prompts."
- Semantic adherence (SA): The degree to which generated content matches the semantic intent of the prompt. Example: "PQSG increases both semantic adherence (SA) and physical commonsense (PC)"
- Spearman's rho (ρ): A non-parametric rank correlation coefficient measuring monotonic association. Example: "We evaluate Pearson's , Kendall's , and Spearman's ."
- Spatio-temporal reasoning: Reasoning that jointly involves spatial and temporal relationships, crucial for video understanding. Example: "struggle with physical reasoning \cite{chowphysbench2025} and spatio-temporal reasoning \cite{zhou2025vlm4d}."
- Temporal consistency: The coherence of visual content across successive frames in a video. Example: "videos that are visually realistic and temporally consistent, but may still be physically implausible"
- Text-to-video generation: Automatically synthesizing videos conditioned on textual prompts. Example: "Progress in text-to-video generation has accelerated rapidly with the advent of video diffusion models"
- Video diffusion models: Generative models that synthesize videos by denoising from noise through a diffusion process. Example: "with the advent of video diffusion models~\cite{hong2022cogvideo, ho2022imagen, ho2020denoising, yangcogvideox, bao2024vidu, ni2024ti2v, wang2026anchorweave, wang2025epic}."
- Vision-LLM (VLM): A multimodal model that jointly processes visual and textual inputs. Example: "generated by a vision-LLM (VLM), guided by high-quality in-context examples."
- World modeling: Building a representation that predicts and reasons about future states of the physical world. Example: "This capacity, often called 'world modeling,' has long been a goal of video generation models"
- Yes-bias: A tendency of models to overproduce affirmative answers in binary questions. Example: "we find that the model generally suffers from 'yes-bias' \cite{ross2024what, tjuatja2024llms}"
Collections
Sign up for free to add this paper to one or more collections.

