- The paper introduces PhyGround, a benchmark that evaluates generative world models using a per-law taxonomy across 13 physical laws in mechanics, fluid dynamics, and optics.
- It combines rigorous human annotation with an open-source PhyJudge-9B to provide fine-grained, reproducible scoring and identify specific simulation weaknesses.
- The diagnostics reveal domain-specific strengths and bottlenecks, informing targeted improvements in model training and deployment for enhanced physical plausibility.
PhyGround: A Fine-Grained Benchmark for Physical Reasoning in Generative World Models
Motivation and Benchmark Design
Generative world models have seen significant advances in multi-modal generation, notably in text-conditioned and image-conditioned video synthesis. However, these models frequently produce outputs that violate basic physical principles, limiting their utility for simulation, visual reasoning, and scientific discovery. Prior evaluation frameworks tended to produce domain- or scenario-level scores, often relying on binary violation rubrics or closed-source evaluators, which obscure law-specific shortcomings and constrain reproducibility.
PhyGround introduces a criteria-grounded benchmarking suite for physical reasoning in generative world models. The central innovation is a per-law evaluation taxonomy encompassing three observable domains—solid-body mechanics, fluid dynamics, and optics—mapped to thirteen distinct physical laws. Each law is operationalized via multiple binary observational probes (violation checks) and scored on a 1–5 Likert scale, enabling fine-grained diagnostic analysis across models and scenarios.
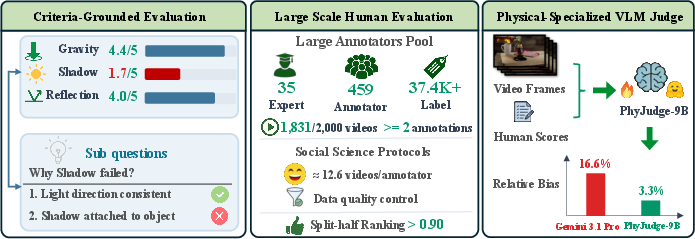
Figure 1: PhyGround decomposes each video model's holistic physical reasoning score into scores for 13 physical laws; a large-scale human study and the open-source PhyJudge-9B facilitate reproducible automated evaluation.
The benchmark comprises 250 explicit prompts, each specifying a unique, visually verifiable physical outcome. Prompts are drawn from complementary sources and meticulously filtered for domain alignment, visual observability, and physical determinacy. Each prompt is paired with a first frame as image-conditioning to ensure explicit outcome expectations and scenario reproducibility.

Figure 2: Inventory of per-law sub-question probes for Solid-Body Mechanics, Fluid Dynamics, and Optical Physics; each law is decomposed into multiple binary violation checks.
Human Evaluation Protocol
PhyGround leverages large-scale, quality-controlled human annotation for video generation evaluation. The annotation protocol is structured to mitigate response biases prevalent in social science studies. Annotators operate under randomized video assignment and presentation order, capped workloads, desktop-only viewing, and a comprehensive training module emphasizing the distinction between visual plausibility and physical correctness. Each video is scored on three general adherence dimensions (semantic alignment, temporal validity, object persistence) and its applicable subset of physical laws.
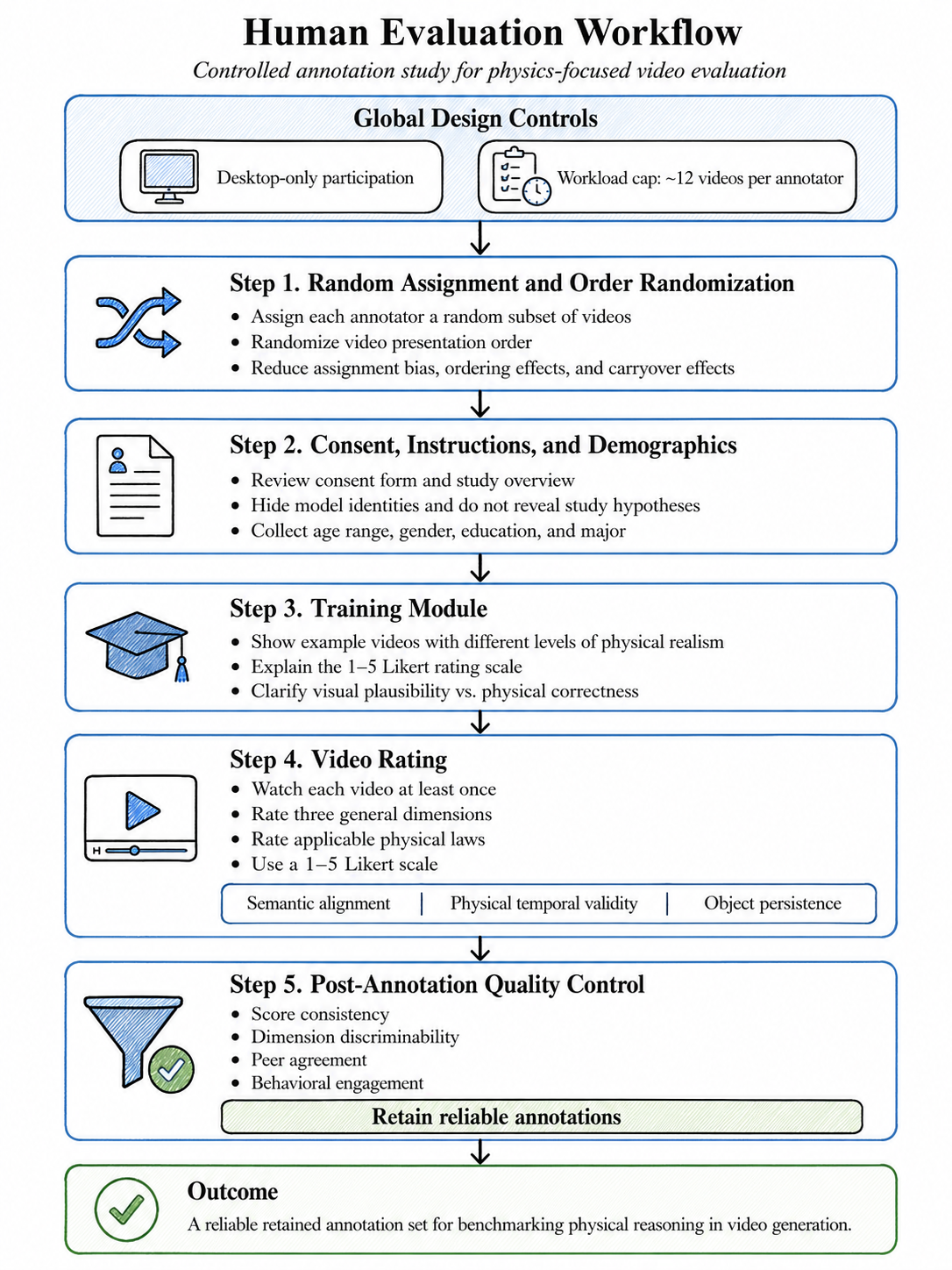
Figure 3: Design workflow for human annotation, exhibiting randomized assignment and rigorous task clarity.
Prior to annotation, subjects undergo worked examples with full dimension scoring, ensuring rubric internalization.
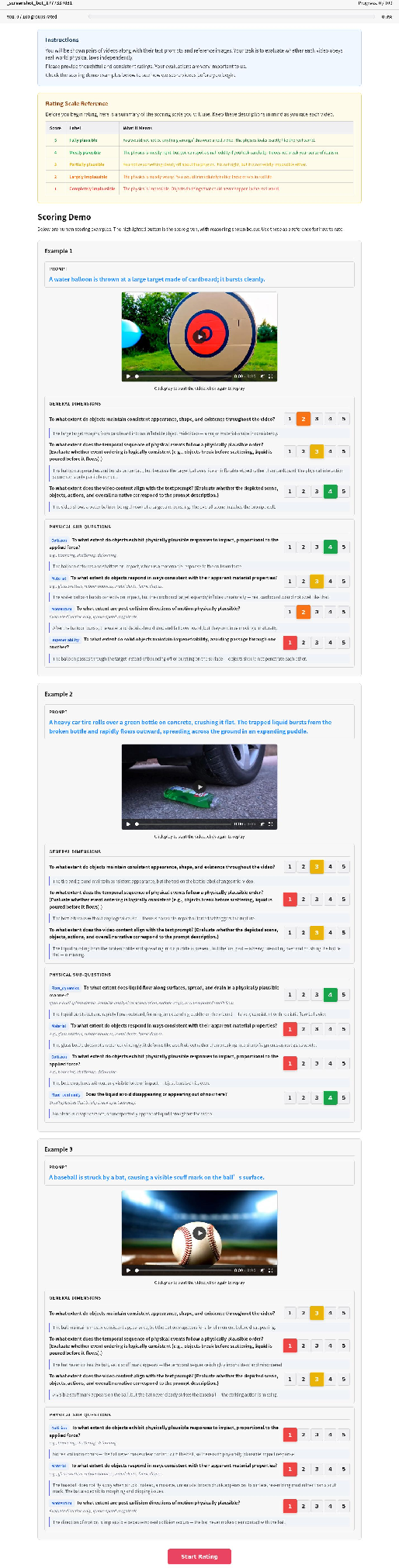
Figure 4: Scoring demo presented to annotators prior to evaluation, emphasizing the 1–5 scale and per-dimension justification.
Post-annotation, a two-round quality-control pipeline filters annotators based on score consistency, copy-paste rate, peer agreement, and engagement metrics. The final pool (352 annotators) yields robust aggregate rankings, validated with split-half and sub-sampling analyses (Spearman ρ > 0.90), and high inter-annotator agreement (73%).
Open-Source, Physics-Specialized Automatic Judge
Standard video metrics (FVD, SSIM, CLIP) and general-purpose VLM judges lack sensitivity to physical law violations. PhyGround addresses this gap with PhyJudge-9B, an open 9B-parameter VLM fine-tuned via LoRA on 29.5K law-level human supervision records. The judge is queried separately per criterion and per-law, utilizing the same sub-question violation checklist as the annotation rubric.
PhyJudge-9B achieves significantly lower aggregate relative bias than closed-source Gemini-3.1-Pro (3.3% vs. 16.6%), and its calibration remains robust across frame sampling rates and schema prompting variants. Addition of law-specific sub-questions substantially closes bias gaps in Fluid and Optical domains for baseline judges; reasoning-augmented prompts (CoT) do not consistently increase accuracy.
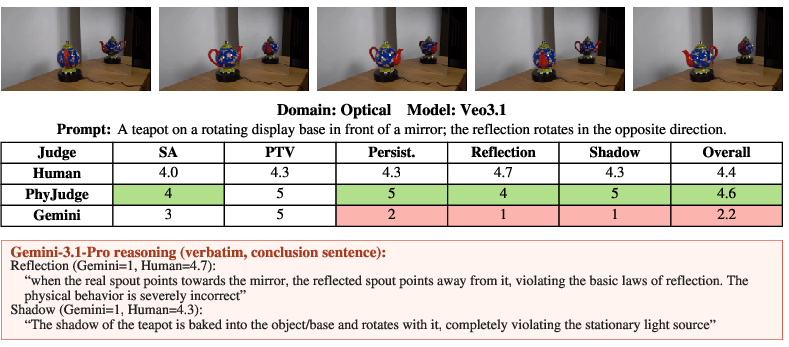
Figure 5: Representative head-to-head comparison of PhyJudge-9B vs. Gemini-3.1-Pro on Optical criteria, showing alignment with human ratings and Gemini’s misinterpretation of plausible outputs.
Eight video generation models (six open-source, one closed) are evaluated on 2,000 total videos. No model exceeds 66% mean adherence to physical laws, with substantial domain-level variation. Wan2.2-27B-A14B and Veo-3.1 achieve identical holistic scores (3.28), yet Wan2.2-27B-A14B leads in solid-body mechanics, persistence, and temporal ordering, while Veo-3.1 excels in fluid and optical realism. This domain decomposition surfaces deployment-relevant strengths/weaknesses masked by aggregate scores.
Per-law breakdown reveals even finer diagnostic distinctions. Dynamic-contact laws (momentum, collision) persistently lag behind free-motion and static constraints (impenetrability, inertia). Fluid realism advantages in closed-source models emerge specifically in bulk-flow and liquid-solid interaction, not conservation axes. Model profiles vary between balanced and spiky, guiding targeted improvement strategies.
Qualitative analyses supplement numerical results, showcasing typical physical law violations present in generated videos (e.g., gravity defiance, impenetrability failures, fluid discontinuities).

Figure 6: Exemplars of gravity violations—unsupported objects fail to fall, hover unnaturally, or accelerate inconsistently.

Figure 7: Typical inertia violations—objects start/stop motion absent external force.

Figure 8: Characteristic momentum violations—post-collision motion inconsistent with incoming momentum.

Figure 9: Impenetrability violations—objects erroneously merge or overlap.
Judge Alignment Across Laws
PhyJudge-9B exhibits consistent law-level agreement with human ratings and substantially outperforms Gemini-3.1-Pro and other baseline judges in both accuracy and robustness. Across all 13 physical law axes, PhyJudge-9B tracks human means closely, whereas Gemini-3.1-Pro oscillates between pessimistic under-scoring and failure to penalize violations.

Figure 10: Collision resolution example—PhyJudge-9B and humans agree, Gemini-3.1-Pro over-penalizes plausible post-impact rest.
Figure 11: Gravity violation—PhyJudge-9B matches human scoring, Gemini-3.1-Pro fails to recognize free-fall discrepancy.
Figure 12: Impenetrability—PhyJudge-9B aligns with humans, Gemini-3.1-Pro misidentifies violations.
Figure 13: Inertia—consensus between PhyJudge-9B and humans, Gemini-3.1-Pro misreads ballistic motion.

Figure 14: Material properties—PhyJudge-9B tracks plausible outcomes, Gemini-3.1-Pro over-penalizes.
Figure 15: Momentum transfer—PhyJudge-9B and humans identify absence of momentum change, Gemini-3.1-Pro hallucinates compliance.
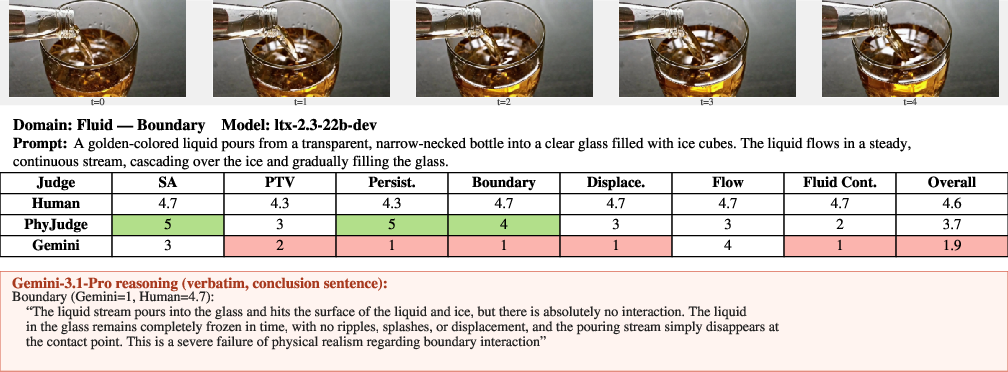
Figure 16: Boundary interaction—PhyJudge-9B follows human rating, Gemini-3.1-Pro pessimistically penalizes fluid-solid interaction.

Figure 17: Buoyancy—PhyJudge-9B concurs with humans, Gemini-3.1-Pro erroneously detects violations.
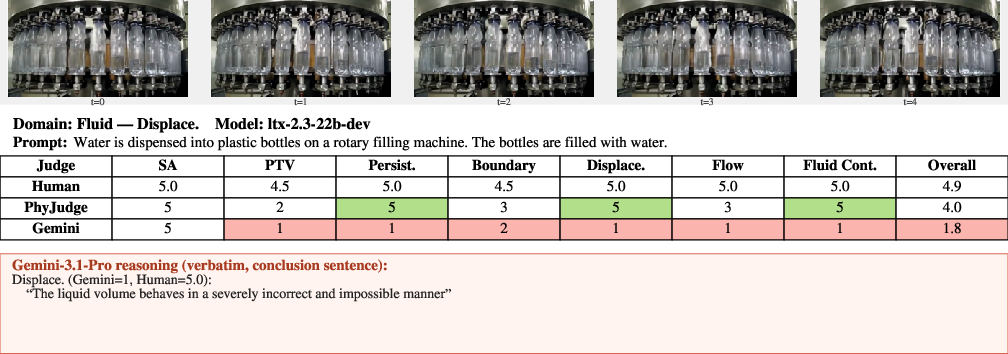
Figure 18: Displacement—PhyJudge-9B captures plausible volume transfer, Gemini-3.1-Pro labels as violation.
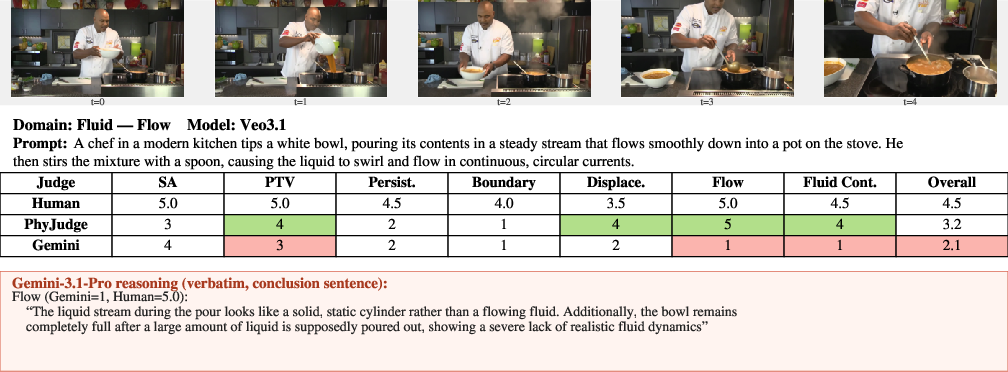
Figure 19: Flow dynamics—PhyJudge-9B captures bulk-fluid realism, Gemini-3.1-Pro regresses.
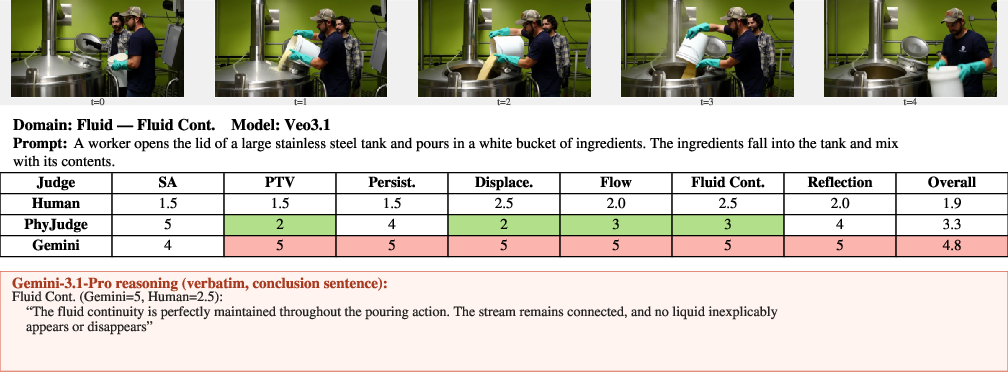
Figure 20: Fluid continuity—PhyJudge-9B differentiates partial violation, Gemini-3.1-Pro overscores.
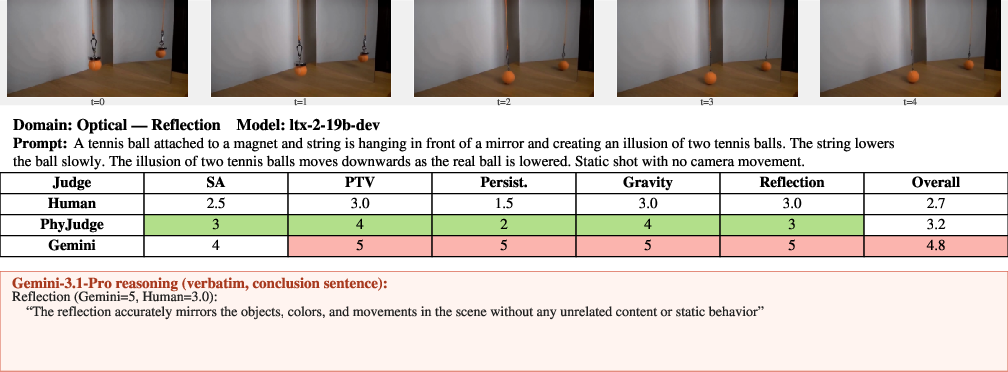
Figure 21: Reflection—PhyJudge-9B penalizes object identity changes, Gemini-3.1-Pro fails to notice.
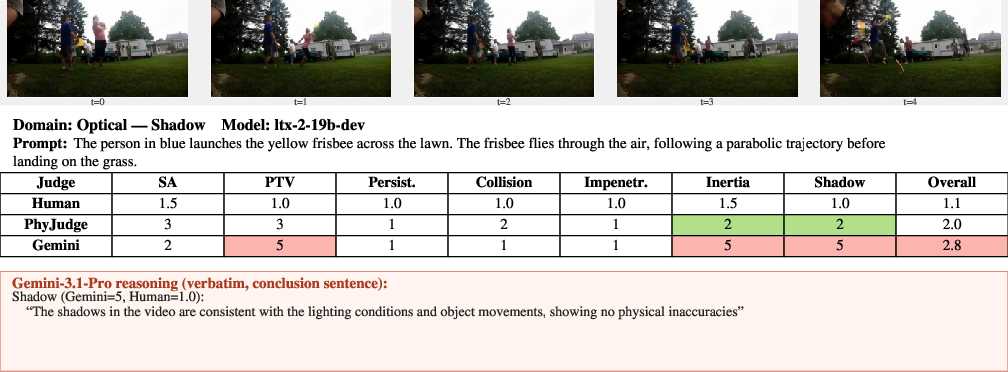
Figure 22: Shadow—PhyJudge-9B approximates human evaluation, Gemini-3.1-Pro overscores.
Implications and Future Directions
PhyGround’s per-law taxonomy and sub-question operationalization expose non-uniform physical reasoning competence in generative models and provide a rigorous foundation for benchmarking and ablation studies. The open-source PhyJudge-9B ensures reproducible, auditable evaluation and circumvents drift inherent in closed-source VLMs.
Practical implications include:
- Model selection for deployment in simulation or scientific reasoning must consider per-domain performance, not holistic adherence.
- Training or finetuning approaches should target low-performing laws (especially dynamic contact, conservation, and continuity axes) with domain-specific losses or synthetic data.
- Evaluation pipelines in generative modeling should adopt per-law decomposition to unmask latent failure modes and accelerate targeted improvement.
Theoretical implications affect directions in world modeling and visual commonsense reasoning:
- Explicit law-wise measurement sets the groundwork for learning structured simulators with physical abstraction.
- Incorporating human-style observational checklists in VLM prompts enhances scoring calibration for physics-dependent visual tasks.
- Large-scale, diverse, and controlled human annotation is essential for mitigating bias and producing stable diagnostic metrics.
Anticipated future work includes expansion of the prompt suite to rare physical phenomena, integration of additional domains (e.g., thermodynamics, electromagnetism, chemistry), and the development of cross-law transfer mechanisms in generative models to generalize from high-fidelity axes to deficient ones.
Conclusion
PhyGround establishes a new standard in physical reasoning evaluation for generative world models, leveraging a law-level taxonomy, structured human annotation, and an open-source, specialized judge. The benchmark reveals domain-specific bottlenecks, non-uniform model strengths, and persistent gaps in physics adherence. PhyGround’s methodology enables reproducible, fine-grained, and diagnostic evaluation, informing both practical deployment and theoretical model development in AI-driven world modeling.

