Are We Ready For An Agent-Native Memory System?
Abstract: Memory for LLM agents has rapidly evolved from simple retrieval-augmented mechanisms into a data management system that supports persistent information storage, retrieval, update, consolidation, and dynamic lifecycle governance throughout agent execution. Despite this evolution, existing evaluations still benchmark agent memory mainly through end-to-end task success metrics (e.g., F1, BLEU), while treating the underlying system as a monolithic black box. As a result, critical system-level concerns, including operational costs, architectural trade-offs across memory modules, and robustness under dynamic knowledge updates, remain insufficiently explored. In this paper, we present a systematic experimental study of agent memory from a data management perspective. We propose an analytical framework that decomposes agent memory into four core modules: memory representation and storage, extraction, retrieval and routing, and maintenance. Under this framework, we evaluate 12 representative memory systems and two reference baselines across five benchmark workloads spanning 11 datasets. Our extensive end-to-end evaluation shows that no single architecture dominates across all scenarios; instead, effectiveness depends heavily on how well the memory structure aligns with the workload bottleneck. Furthermore, through fine-grained ablation studies, we quantify their individual effects on representation fidelity, retrieval precision, update correctness, and long-horizon stability. Finally, we reveal cost-performance trade-offs under realistic workloads, showing localized maintenance is more cost-efficient than global reorganization. Based on these findings, we identify promising directions towards building truly agent-native memory systems. The code is publicly available at https://github.com/OpenDataBox/MemoryData.
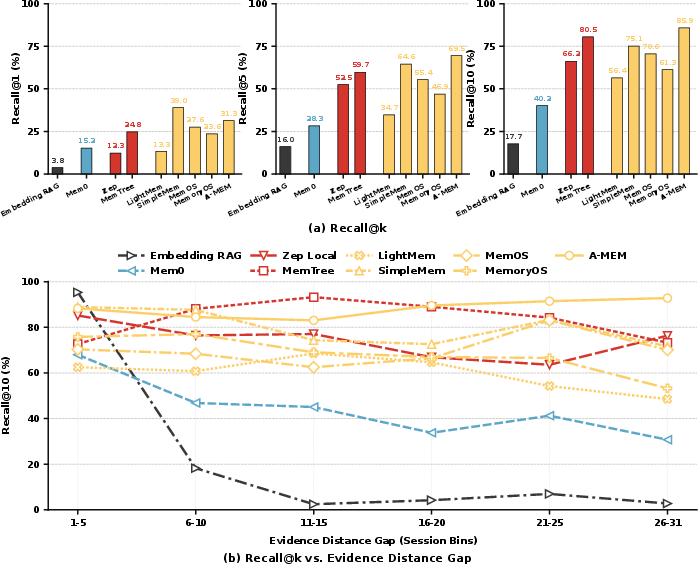
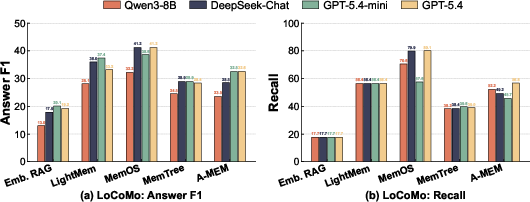
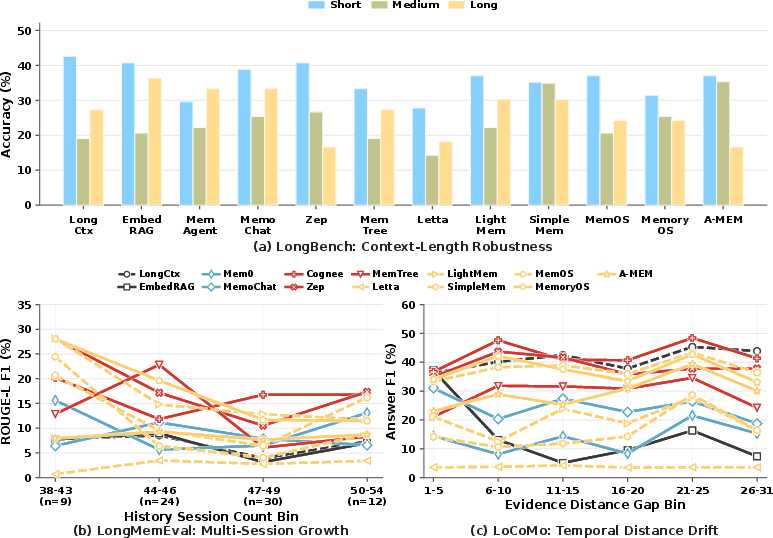
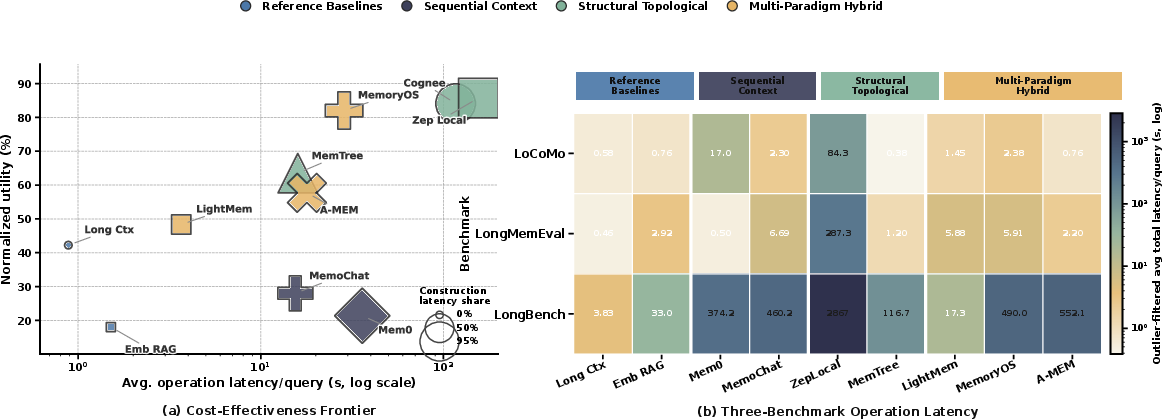
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how “memory” works for AI assistants that use LLMs. Think of an AI assistant as a smart robot that talks and helps you over time. To do that well, it needs a good memory system to save important information, find it later, update it when things change, and keep everything organized. The authors ask a big question: are today’s memory systems truly ready for these AI agents? They treat memory like a data system (similar to a library with shelves, indexes, and librarians), not just a simple note-taking tool.
What the paper tries to find out
The authors set clear goals that are easy to understand:
- Which kinds of memory designs work best for different types of AI tasks?
- How do we measure not just “did the AI answer correctly?” but also:
- How well did the memory find the right evidence?
- How well did the memory handle updates (like fixing or replacing old facts)?
- How stable is the memory over long periods?
- How much time and money does the memory system cost to run?
- Can we break memory systems into simple parts to compare them fairly?
How the research was done
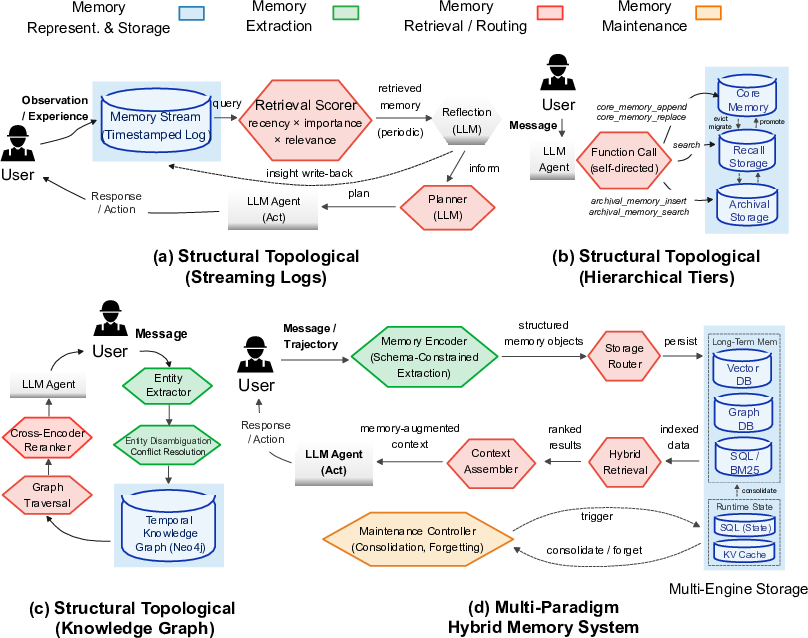
The researchers built an analytical framework that splits an AI memory system into four parts. Imagine you’re building a really good notebook plus filing cabinet for your AI:
- Memory representation and storage: how the information is shaped and saved (like plain text notes, graphs linking people and facts, or organized records).
- Extraction: what gets written into memory from the AI’s conversations or tools (like picking out key facts or summaries).
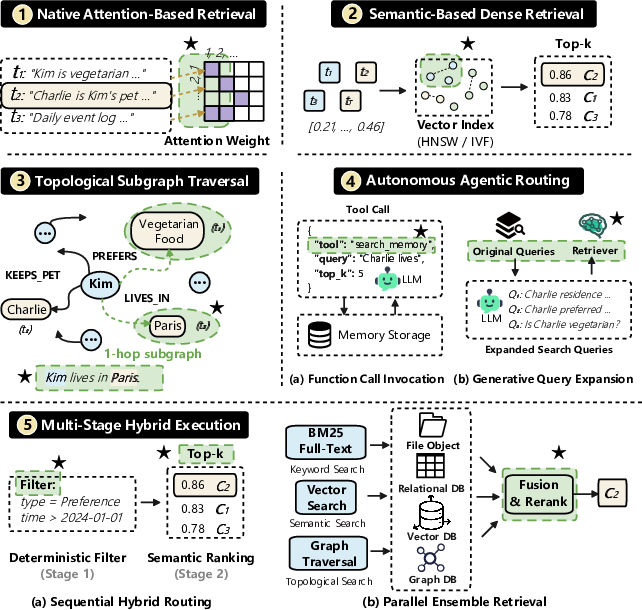
- Retrieval and routing: how the AI finds the right pieces later and decides where to look (like searching by keywords, meaning, or following links in a graph).
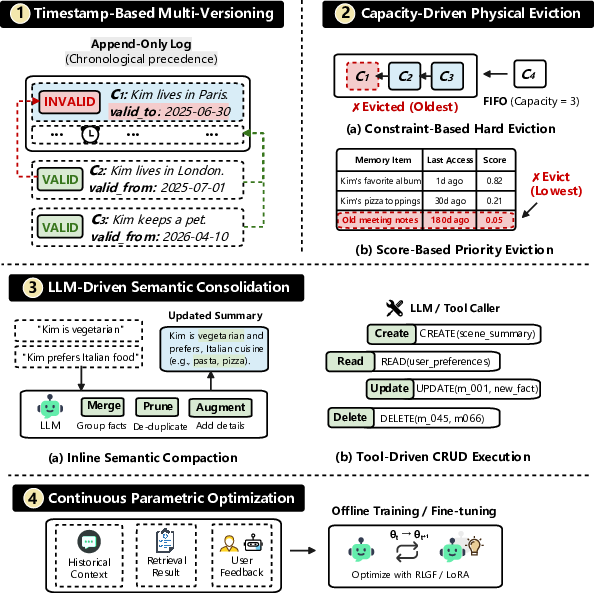
- Maintenance: how the memory is kept fresh and clean (like updating old facts, merging duplicates, and removing junk).
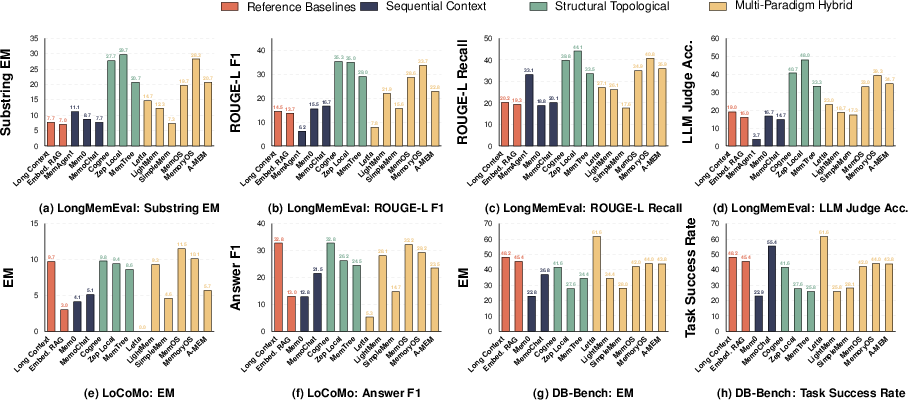
They then tested 12 well-known memory systems (plus baselines) on five different kinds of tasks using 11 datasets. They didn’t just check “final scores” like correctness; they also measured:
- Retrieval accuracy (did the system surface the right supporting evidence?)
- Update correctness (did it properly replace old facts with new ones?)
- Long-term stability (does performance drop as conversations get longer?)
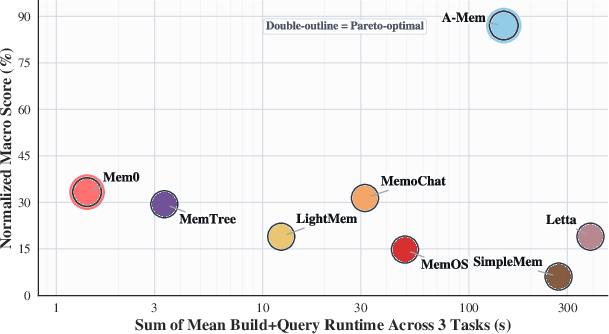
- Operational costs (index building time, query speed, token use, and money)
They also performed “ablation” studies, which means they changed one part at a time (like swapping the storage method or the retrieval strategy) to see exactly how each component affects performance. Finally, they compared maintenance strategies, such as “localized” clean-ups (fix small parts) versus “global” reorganizations (rebuild everything).
Main findings and why they matter
Here are the key results, explained simply:
- No one-size-fits-all memory: Different designs shine in different situations. Hybrid systems (that mix several methods) do well in chat-style Q&A. Graph-based systems (that link entities and facts) are great at recalling simple facts and handling updates, but they can struggle with time-based reasoning.
- Finding the right evidence is hard: Planning queries and combining multiple search methods (meaning-based + keyword + structure) improves relevance. But if the needed information is far back in time, similarity searches tend to miss it.
- Updates need structure: Systems using graphs or explicit versions handle changing facts better. Simple “append-only” memory (just adding new notes) often returns outdated info, causing “hallucinations of the past.”
- Long conversations cause trouble: Many systems get worse as the memory gets older and bigger. Summarizing can accidentally erase important timing details. Surprisingly, sometimes just putting the whole long context in the model (no fancy memory) works better for time-sensitive questions.
- Costs can outweigh benefits: Highly structured systems can be much slower and more expensive to build and query than lightweight ones, and don’t always give enough accuracy to justify the cost.
- Where components break down: Each extra layer (compression, summarization, fact extraction) can lose details. Very fine-grained extraction may slightly raise precision but can harm multi-step reasoning. Conservative maintenance (careful, timely updates) is a safer default than delaying clean-ups, which can make things look good on the surface but hurt actual answerability.
What this means going forward
The paper’s message is practical: choose memory systems based on the job, not because one looks fancy or tops a single benchmark. For developers and teams:
- Match the memory architecture to your workload. Use hybrid retrieval if your tasks vary; use graph-based approaches if you expect frequent updates and relationships among entities.
- Plan for costs. Complex structures can slow you down and increase bills; measure latency, index time, and token use.
- Keep time information alive. Avoid over-summarizing; maintain timestamps and versions so the AI respects the order of events.
- Maintain memory carefully. Prefer local fixes and conservative consolidation rather than full rebuilds unless you truly need them.
For researchers, the paper points to building “agent-native” memory systems with:
- Specialized storage that supports different kinds of memory objects (facts, timelines, preferences).
- Cost-aware memory query planning (balancing accuracy with speed and expense).
- Clear consistency rules, especially when multiple agents share or update the same memory.
Overall, the study shows that treating memory as a real data system—planned, measured, and maintained—helps AI assistants think more clearly over time, make fewer mistakes, and stay efficient.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
Below is a consolidated list of concrete limitations, gaps, and open research questions that remain unresolved by the paper and could guide future work.
- Lack of formal semantics for updates and consistency: Define precise update semantics (e.g., overwrite vs. versioning vs. reconciliation), isolation levels, and consistency models for external memory under concurrent reads/writes.
- No evaluation under multi-agent concurrency: Quantify performance and correctness when multiple agents simultaneously write to and read from shared memory; test conflict resolution, isolation, and cross-session consistency.
- Insufficient stress tests at production scale: Evaluate scalability to millions of memory objects with distributed storage, sharding, and fault tolerance; report throughput, tail latency, and recovery behavior under node failures.
- Limited exploration of real-world traces: Validate findings on long-running, production agent logs (e.g., enterprise workflows) rather than only public benchmarks; study robustness to non-stationary data and concept drift.
- Missing privacy, security, and governance analysis: Specify access control, auditability, PII redaction, compliance (e.g., GDPR/CCPA), and data retention policies for agent memory; quantify the impact of privacy-preserving mechanisms (e.g., differential privacy) on retrieval fidelity.
- No formal cost model or optimizer: Develop and evaluate a cost-based optimizer that selects representations, indexes, and routing strategies given workload, latency/price targets, and resource budgets.
- Open question on optimal memory granularity: Systematically characterize how chunk sizes, schema richness, and object granularity affect retrieval fidelity, multi-hop reasoning, and maintenance overhead across tasks.
- Temporal reasoning remains brittle: Design and benchmark temporal-aware indexing, encoding, and summarization that preserve chronological cues without sacrificing compression; quantify trade-offs between time-aware retrieval and cost.
- Update robustness under adversarial or noisy inputs is untested: Stress-test systems with conflicting, ambiguous, or malicious updates; measure stale-fact leakage, “hallucinations of the past,” and recovery mechanisms.
- Maintenance policies lack principled triggers: Formalize when to apply local vs. global reorganization, compaction, or consolidation (e.g., trigger conditions, budgets, SLOs); evaluate scheduler policies over long horizons.
- Limited analysis of information loss across abstraction layers: Quantify where and how summarization, compression, and fact extraction discard critical evidence; propose loss-aware extraction with verifiable provenance.
- Absence of a unified query language and planner: Specify an agent-native memory query language (combining Boolean, semantic, and temporal predicates) and implement cardinality estimation and plan selection for hybrid stores.
- Token/cost dynamics under varying LLMs and pricing: Systematically measure token, latency, and dollar costs across open and proprietary LLMs, context lengths, and pricing models; derive budget-aware retrieval strategies.
- Generalization beyond text is not evaluated: Extend benchmarks and systems to multimodal memory (images, code ASTs, tables, sensor logs) and measure cross-modal retrieval and update correctness.
- Interplay between parametric and external memory is unclear: Study how fine-tuning, adapters, and memory editing interact with external memory; determine when to externalize vs. internalize knowledge for stability and cost.
- Personalization and user preference modeling remain under-tested: Build datasets and metrics for preference drift, conflicting multi-user profiles, and fine-grained access control; evaluate long-term personalization fidelity.
- Benchmark coverage gaps: Add tasks for procedural memory, tool-use traces, long-horizon plan repair, and program synthesis/maintenance to complement QA/dialogue-centric datasets.
- Reproducibility threats from third-party systems: Control for implementation/version differences, hidden heuristics, and default settings; provide containerized benchmarks and fixed-time budget protocols.
- Lack of robustness evaluation under distribution shift: Test retrieval and update correctness when domain vocabulary, style, or ontology shifts; assess adaptive indexing and continual schema evolution.
- Missing study of space amplification and storage efficiency: Measure deduplication, compaction, and garbage-collection effectiveness; report long-term storage growth and its impact on latency and cost.
- No principled data quality and provenance tracking: Implement and evaluate provenance, confidence scoring, and uncertainty propagation from extraction to answer generation; auditability for decisions and updates.
- Unclear fairness and bias impacts: Analyze whether memory retrieval/maintenance amplifies demographic or topical biases; design bias-aware extraction and routing strategies.
- Scheduling under resource contention is unaddressed: Explore background maintenance scheduling (indexing, compaction) under live traffic; quantify query degradation and propose QoS-aware schedulers.
- Limited cross-lingual and code-switching evaluations: Test memory fidelity and retrieval in multilingual and mixed-language settings; assess cross-lingual indexing and translation-induced drift.
- Absence of adversarial retrieval/poisoning benchmarks: Create red-team datasets for data poisoning, prompt-injection via memory, and retrieval hijacking; evaluate defenses and detection methods.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed with current tools, informed directly by the paper’s experimental findings and four-module framework (representation and storage, extraction, retrieval and routing, maintenance).
- Workload-aware memory selection and playbooks
- Description: Use the paper’s finding that “no single architecture dominates” to create checklists for choosing vector, graph, hierarchical, or hybrid memory per workload (e.g., conversational QA, single-hop factual recall, temporal reasoning, long-horizon agents).
- Sectors: Software, enterprise AI platforms, consulting.
- Tools/Products/Workflows: Architecture review templates; decision matrices embedded in solution design; internal “memory catalog” that maps tasks to recommended systems (e.g., composite hybrid for conversational QA; graph for frequent updates).
- Assumptions/Dependencies: Access to multiple memory backends; reproducible evaluation harnesses; basic MLOps for A/B testing.
- Retrofit existing RAG stacks with explicit query planning and hybrid search
- Description: Upgrade retrieval pipelines to combine BM25 + dense embeddings + optional graph traversal, and add explicit query planning (reasoned sub-query decomposition) to maximize evidence relevance.
- Sectors: Search, customer support, knowledge management, developer tools.
- Tools/Products/Workflows: Multi-stage retrieval orchestrators; query planners that generate retrieval intents; integration with keyword and vector indices; seed-and-expand graph traversals.
- Assumptions/Dependencies: Availability of BM25/keyword indices and vector DBs; LLM function-calling or routing policies.
- Update-safe knowledge stores for dynamic domains
- Description: Adopt graph-based memory with multi-versioning for precise overwrites and conflict resolution where knowledge changes frequently; avoid append-only stores that return stale facts.
- Sectors: E-commerce catalogs, customer support, news/media, software documentation.
- Tools/Products/Workflows: Temporal knowledge graphs; entity disambiguation; timestamped versions; logical invalidation on updates.
- Assumptions/Dependencies: Entity/relationship extraction quality; governance over versioning; graph DB or hybrid storage available.
- Cost-aware memory maintenance and localized reorganization
- Description: Prefer localized maintenance (incremental index updates, targeted compaction) over costly global reindexes, aligning with the paper’s cost–performance findings.
- Sectors: Enterprise AI, SaaS copilots, cloud AI platforms.
- Tools/Products/Workflows: Incremental indexing jobs; per-partition compaction; cost dashboards tracking index construction time, query latency, token cost per successful answer.
- Assumptions/Dependencies: Observability stack; workload partitioning; SLAs on latency and cost.
- Lifecycle governance to reduce “hallucinations of the past”
- Description: Implement conservative consolidation, recency-aware retention, and stale-fact detection; store provenance and timestamps; avoid aggressive summarization that discards crucial chronological cues.
- Sectors: Healthcare, finance, legal, regulated industries.
- Tools/Products/Workflows: Data retention policies; provenance tagging; time-aware ranking features; scheduled audits surfacing contradictions and aged facts.
- Assumptions/Dependencies: Policy alignment with compliance; storage overhead for raw + summarized artifacts.
- Temporal queries with long-context or pinned chronological snippets
- Description: For time-dependent questions, route to raw long-context retrieval or pin chronological snippets rather than relying solely on semantically consolidated summaries.
- Sectors: Compliance, incident response, operations logs, journalism.
- Tools/Products/Workflows: Heuristics on temporal distance; “pinned” timeline segments alongside semantic context; user-facing “as of” query controls.
- Assumptions/Dependencies: Context-window budget; log/timeline availability; clock and timestamp consistency.
- LLMOps/LLMOps checkpoints for memory quality and stability
- Description: Add component-level metrics to CICD and production monitors: evidence-level Recall@k, update robustness tests (conflicting knowledge), long-horizon stability under growth.
- Sectors: Software, platform engineering.
- Tools/Products/Workflows: CI gates for retrieval fidelity; synthetic update tests; canary sessions measuring degradation with temporal distance.
- Assumptions/Dependencies: Test datasets and harnesses; telemetry; automated regressions.
- Teaching, reproducible research, and in-house benchmarking
- Description: Adopt the four-module decomposition in courses and lab settings; reuse the open-source code and datasets to run fair, system-level comparisons.
- Sectors: Academia, corporate research labs.
- Tools/Products/Workflows: Course modules; reproducible notebooks; benchmark leaderboards covering cost, latency, and update correctness.
- Assumptions/Dependencies: Access to the public repo and datasets; compute credits.
- Procurement and policy checklists for AI memory systems
- Description: Require vendors to disclose cost–latency–accuracy trade-offs, explain lifecycle maintenance, and support multi-versioning/auditability.
- Sectors: Government, enterprise IT procurement, compliance.
- Tools/Products/Workflows: RFP/RFQ templates; compliance checklists (multi-version retention, conflict resolution, provenance).
- Assumptions/Dependencies: Policy authority; evaluation capacity.
- Personal assistant memory hygiene
- Description: End-user settings for overwrite vs. append-only, manual flush schedules, and conflict-resolution prompts to prevent stale or contradictory personal facts.
- Sectors: Consumer AI, productivity apps.
- Tools/Products/Workflows: “Review and confirm” memory updates; recency decay controls; “forget this” one-click operations.
- Assumptions/Dependencies: UX support; on-device or user-consented storage.
Long-Term Applications
These opportunities require further research, scaling, or standardization to realize the paper’s vision of agent-native memory as a data management system.
- Agent-native memory DBMS
- Description: Specialized storage engines that natively support multi-granularity memory objects (raw artifacts, atomic notes, graphs), with unified indexes and transactional updates.
- Sectors: Database and AI infrastructure vendors, cloud platforms.
- Tools/Products/Workflows: Multi-model stores (graph + vector + relational); memory-aware transaction logs; unified memory schema catalog.
- Assumptions/Dependencies: New engine development; performance benchmarks; ecosystem integration.
- Cost-based memory query optimizers
- Description: Planners that balance retrieval fidelity, latency, token cost, and maintenance overhead, selecting among long-context, hybrid retrieval, or graph traversal plans per query.
- Sectors: AI platforms, enterprise search, developer tools.
- Tools/Products/Workflows: Optimizer with learned/selectivity models; what-if cost simulators; plan visualizers.
- Assumptions/Dependencies: Rich telemetry; standardized cost models; pluggable retrieval operators.
- Auto-adaptive memory controllers
- Description: Self-tuning policies for routing, tiering, consolidation, and eviction; RL or bandit-based strategies that adapt to evolving workloads.
- Sectors: SaaS copilots, contact center AI, developer assistants.
- Tools/Products/Workflows: Closed-loop performance feedback; adaptive tiering (hot/cold); query intent classifiers driving routing.
- Assumptions/Dependencies: Safe exploration; guardrails; drift detection.
- Temporal- and update-aware representations
- Description: Embeddings, indices, and ranking functions that encode time, recency, and version semantics; native support for “as of” queries.
- Sectors: Finance, healthcare, audit/compliance, news.
- Tools/Products/Workflows: Time-aware embeddings; bi-temporal indices; temporal KG operators.
- Assumptions/Dependencies: Research on temporal semantics in embeddings and retrieval; ground-truth temporal datasets.
- Multi-agent shared memory with consistency and access control
- Description: A shared memory fabric enabling teams of agents to read/write with isolation levels, conflict resolution, and fine-grained ACLs.
- Sectors: Enterprise automation, software engineering, robotics swarms.
- Tools/Products/Workflows: Namespaces; CRDTs or transactional protocols; lineage/provenance across agents.
- Assumptions/Dependencies: Formal consistency models for uncertain, unstructured data; security frameworks.
- Standard APIs and schemas for memory operations
- Description: Interoperable interfaces (e.g., evolution of MCP) for write/update/version/query/route across memory substrates and vendors.
- Sectors: Standards bodies, cloud AI, open-source ecosystems.
- Tools/Products/Workflows: Open schemas for entities, events, notes; conformance tests; portability tooling.
- Assumptions/Dependencies: Community consensus; cross-vendor collaboration.
- Privacy, safety, and right-to-be-forgotten in agent memory
- Description: Differential privacy for extraction, selective forgetting, retention windows, and explainable provenance to meet regulatory requirements.
- Sectors: Healthcare, finance, public sector, consumer apps.
- Tools/Products/Workflows: Deletion propagation across indices; privacy budgets; redaction-aware summarization.
- Assumptions/Dependencies: Legal standards; performant privacy-preserving algorithms; auditable logs.
- Edge/on-device and federated agent memory
- Description: Personal or enterprise on-device stores with periodic federated sync; optimize for latency, privacy, and energy.
- Sectors: Mobile, IoT, personal productivity, assistive tech.
- Tools/Products/Workflows: Compact indices; energy-aware maintenance; conflict resolution under intermittent connectivity.
- Assumptions/Dependencies: Hardware constraints; efficient embeddings; secure federation protocols.
- Robotics and embodied agents’ persistent world models
- Description: Update-robust, low-latency memory for dynamic maps, objects, and tasks; seamless integration of symbolic/metric information.
- Sectors: Robotics, logistics, manufacturing.
- Tools/Products/Workflows: Spatial-temporal KGs; sensor-to-memory extraction pipelines; hybrid planning with memory lookups.
- Assumptions/Dependencies: Real-time constraints; fusion of perception and language memory.
- Sector-specific, memory-centric benchmarks and SLOs
- Description: Industry consortia to create benchmarks that measure retrieval fidelity, update correctness, long-horizon stability, and operational cost under realistic workloads.
- Sectors: Finance (market events), healthcare (EHR change logs), software (code evolution), customer support (policy updates).
- Tools/Products/Workflows: Public datasets; red-team tests for stale facts; SLO templates per sector.
- Assumptions/Dependencies: Data-sharing agreements; anonymization; ongoing maintenance of benchmarks.
- Government and enterprise governance frameworks
- Description: Policy requiring multi-version auditability, update mechanisms, and explicit maintenance plans for AI systems that store memory.
- Sectors: Public sector, regulated enterprises.
- Tools/Products/Workflows: Compliance audits for memory operations; certification programs; incident reporting for memory failures.
- Assumptions/Dependencies: Regulatory adoption; auditing capacity; standardized reporting formats.
Glossary
- Agent-Native Memory System: A memory architecture designed specifically for LLM agents, aligning storage, retrieval, and maintenance with agent workflows. "Are we ready for an agent-native memory system?"
- Append-Only Logs: Write-once storage that records new versions without in-place updates, useful for auditability and versioning. "Timestamp-Based Multi-Versioning (Append-Only Logs)"
- Autonomous Agentic Routing: LLM- or policy-driven decision-making that routes queries to appropriate memory modules or indices. "Autonomous Agentic Routing (LLM Topic Selection)"
- BM25: A classical probabilistic information retrieval ranking function often combined with dense retrieval. "(Dense + BM25 + BFS)"
- Capacity-Driven Physical Eviction: Removing items from memory when capacity thresholds are reached, often guided by heuristics. "Capacity-Driven Physical Eviction"
- Catastrophic Forgetting: Loss of previously acquired knowledge due to new updates or flawed memory designs. "catastrophic forgetting"
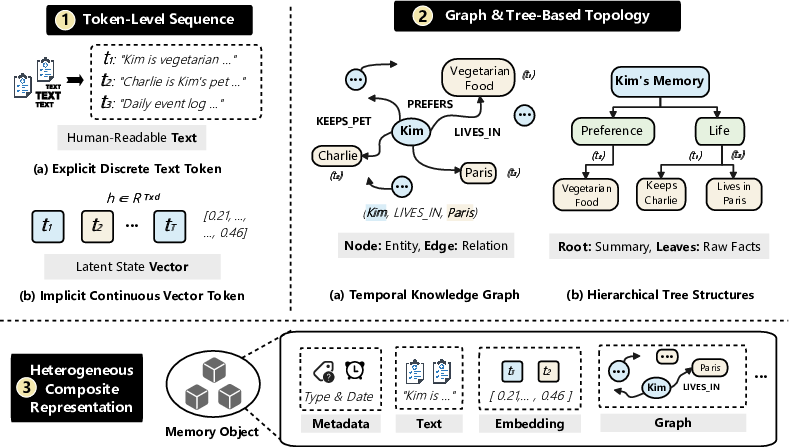
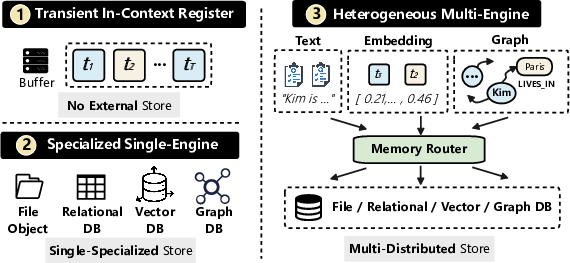
- Composite Hybrid Memory System: An architecture that integrates multiple storage substrates (e.g., vector, graph, keyword) with coordinated routing and maintenance. "Composite Hybrid Memory System"
- Differential Writes: Update strategy that records only changes relative to prior versions to reduce write amplification. "Timestamp-Based Multi-Versioning (Differential Writes)"
- Entity Disambiguation: Resolving mentions that refer to different real-world entities to maintain accurate knowledge. "often incorporating entity disambiguation and conflict resolution;"
- Evidence Localization: The process of surfacing relevant supporting information before answer generation. "they externalize evidence localization before answer generation"
- Graph DB: A database optimized for storing and querying graph-structured data like entities and relationships. "Specialized Single-Engine (Graph DB)"
- Hierarchical Tiered Memory System: Multi-level memory with distinct capacities and access costs, supporting promotion/eviction across tiers. "Hierarchical Tiered Memory System"
- Index Construction Time: The time overhead to build indexing structures for efficient retrieval. "such as index construction time and query latency"
- Knowledge Graph Memory System: A memory design that represents knowledge as entities and relations, often with temporal dynamics. "Knowledge Graph Memory System"
- KV Caches: Key–value caches used to store transient runtime state separate from persistent memory. "explicitly separating runtime state (e.g., KV caches) from long-term storage"
- Logical Invalidation: Marking outdated versions as inactive without physically deleting them to maintain history. "Timestamp-Based Multi-Versioning (Logical Invalidation)"
- Long-Context Retrieval: Retrieving relevant information directly from very long input contexts. "raw long-context retrieval still outperforms most memory-backed approaches"
- Long-Horizon Stability: The ability of a system to maintain reliability and performance over extended interactions and growth of memory. "long-horizon stability"
- Multi-Stage Hybrid Execution: Retrieval pipelines that combine multiple methods (e.g., dense, lexical, graph traversal) in stages. "Multi-Stage Hybrid Execution (Dense + BM25 + BFS)"
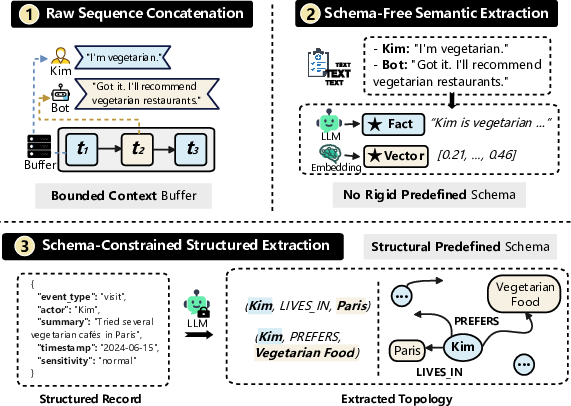
- Schema-Constrained Extraction: Structuring extracted information according to a predefined schema to ensure consistency. "Schema-Constrained Extraction"
- Schema-Free Extraction: Extracting information without a predefined schema, allowing flexible but less controlled structures. "Schema-Free Extraction"
- Semantic Consolidation: Combining and summarizing semantically related items to reduce redundancy and improve coherence. "LLM-Driven Semantic Consolidation"
- Temporal Knowledge Graph: A knowledge graph that captures time-stamped facts and evolving relations. "(e.g., temporal knowledge graphs)"
- Timestamp-Based Multi-Versioning: Maintaining multiple versions of data indexed by timestamps for temporal queries and updates. "Timestamp-Based Multi-Versioning"
- Topological Subgraph Traversal: Querying by navigating graph structure to locate relevant subgraphs for answering a query. "Topological Subgraph Traversal"
- Vector DB: A database specialized for storing and querying vector embeddings via similarity search. "Specialized Single-Engine (Vector DB)"
Collections
Sign up for free to add this paper to one or more collections.

