- The paper introduces ActiveMem, a novel distributed active memory architecture that decouples reasoning from memory consolidation.
- It employs parallelized Memorizers, Memory Shards, and an Operator to efficiently extract and consolidate semantic gists, reducing redundant computation.
- Experiments on benchmarks like BrowseComp-Plus and GAIA show improved accuracy (LasJ 0.79) and lower computational cost (2,145 PFLOPs) versus centralized baselines.
ActiveMem: Distributed Active Memory for Long-Horizon LLM Reasoning
Motivation and Central Problem
Long-horizon task-solving with LLM agents is fundamentally limited by the context-window constraints of current model architectures. Vanilla and summary-based centralized memory mechanisms exhibit an inherent trade-off: aggressive pruning or compression preserves bounded context length at the cost of irreversible information loss, while unconstrained context expansion degrades inference quality ("lost-in-the-middle" effect) and inflates computational cost. Existing distributed memory frameworks (e.g., MIRIX) lack explicit coordination with the task’s evolving information demands, instead relying on static memory taxonomies that do not provide dynamic, active, or semantic interaction with the agent's cognitive process. The lack of decoupling between memory storage and reasoning computation is the principal architectural bottleneck inhibiting scalable and efficient long-horizon LLM agents.
Architecture: Decoupled and Distributed Active Memory
ActiveMem introduces a structurally decoupled framework inspired by cortical-hippocampal complementarity in human cognition. It segregates reasoning from memory consolidation as follows:
A high-level Planner (instantiated with a full-scale LLM) is dedicated to compact, stepwise reasoning using distilled semantic gists, maintaining minimal recent interaction history and sub-query context. The distributed memory system, executing in parallel, consists of three major modules:
- Memorizers: Efficient, trainable small LMs that process retrieved documents in parallel, producing concise, query-conditioned semantic gists.
- Memory Shards: Persistent key-value stores that accumulate and consolidate these gists, maintaining a logically isolated and recoverable memory space throughout the episode.
- Operator: A lightweight controller responsible for memory routing, similarity-based memory reuse (via semantic query-history matching), and asynchronous gist consolidation.
The division enables expansive, document-level memory accumulation without polluting the Planner's context window, avoiding both quadratic cost scaling and lossy compression.
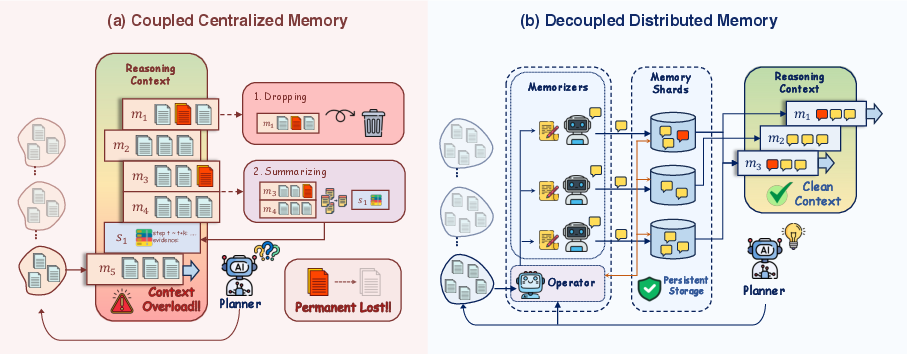
Figure 1: Comparison between coupled centralized memory and the decoupled distributed ActiveMem memory architecture; ActiveMem enables semantic gist persistence and parallel distillation, circumventing truncation-induced information loss.
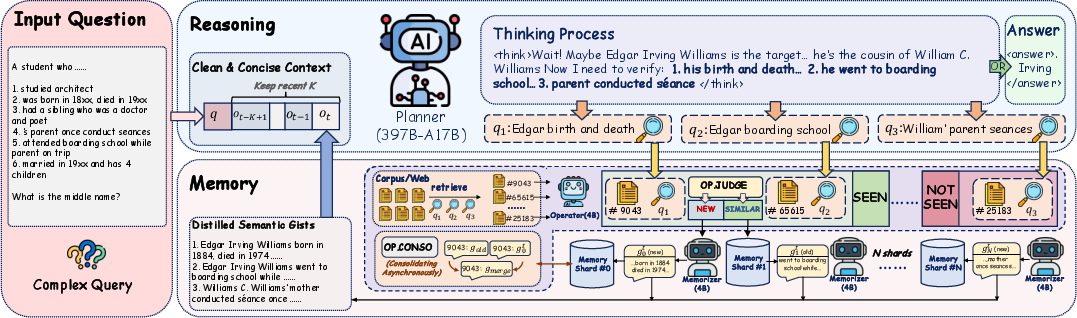
Figure 2: Overview of the ActiveMem framework, highlighting the clean separation of reasoning and memory management pipelines with parallelized gisting and persistent storage.
Computational and Behavioral Advantages
Accuracy and Efficiency Trade-off
Extensive benchmarking on BrowseComp-Plus and GAIA demonstrates that ActiveMem consistently yields state-of-the-art accuracy (LasJ) while significantly reducing total and per-case PFLOPs relative to both vanilla and centralized memory agent baselines. On BrowseComp-Plus, it achieves a LasJ of 0.79 versus 0.72 for the best centralized baseline, and an ACT (accuracy–cost trade-off) score of 0.785, with only 2,145 PFLOPs, the lowest among agents with comparable accuracy. On GAIA, the system outperforms all baselines in both accuracy and cost metrics.
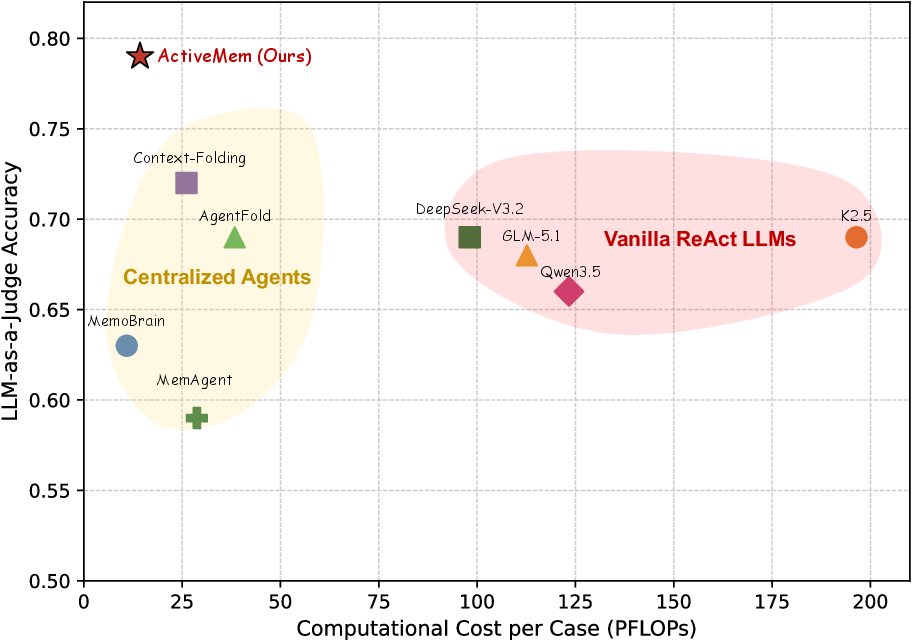
Figure 3: ActiveMem outperforms modern centralized memory agents and vanilla ReAct LLMs on LLM-as-a-Judge accuracy, while incurring substantially lower computational cost.
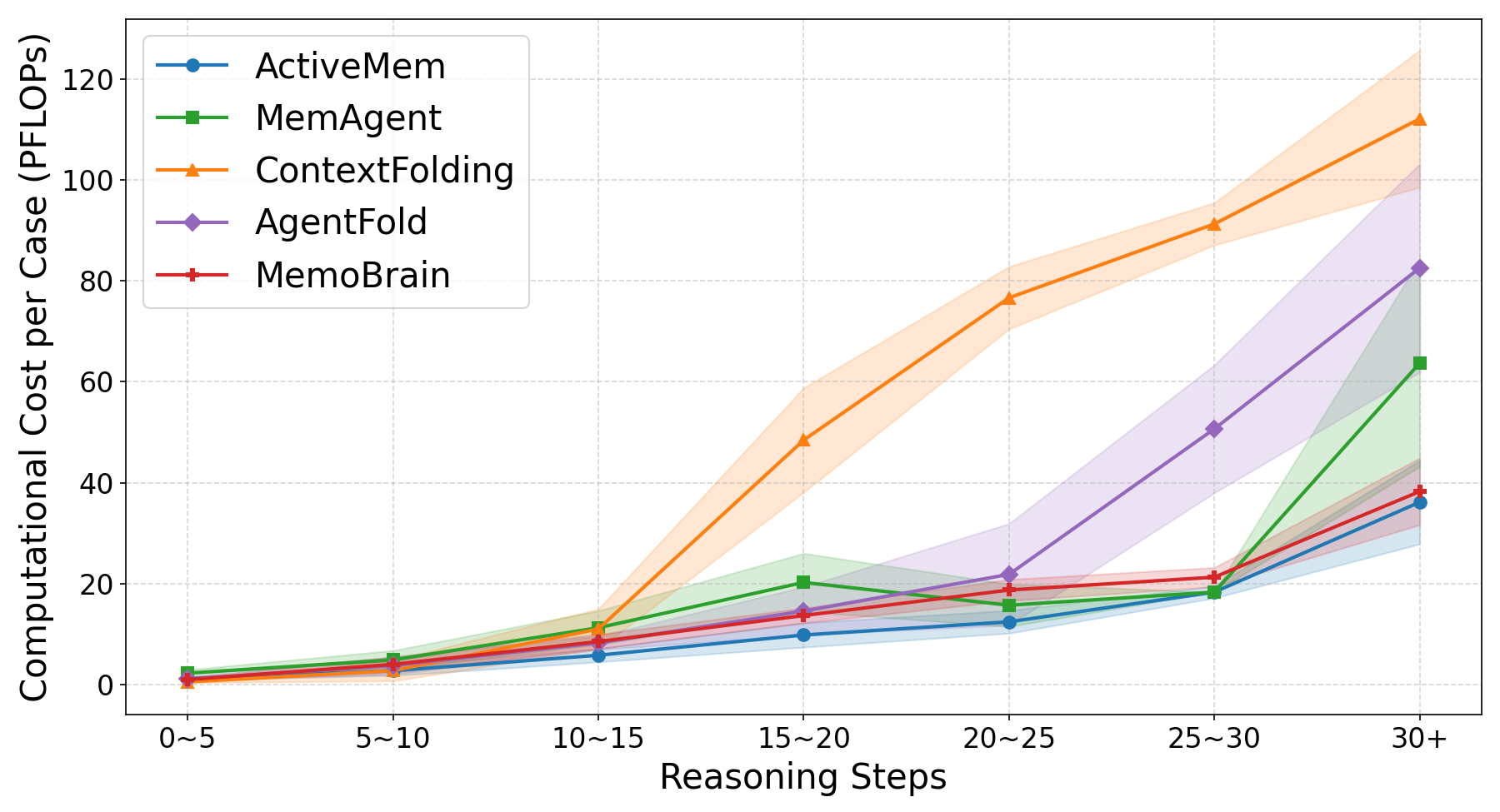
Figure 4: Average PFLOPs per case remain flat for ActiveMem as reasoning trajectories lengthen, highlighting its superior scalability versus baseline approaches.
The efficiency gain is primarily due to three mechanisms: (a) offloading token-intensive processing to small Memorizers (~4B), (b) opportunistic memory reuse via high-hit-rate semantic matching in Memory Shards, and (c) strict bounding and trimming of the Planner’s context window, which is only weakly sensitive to the total number of reasoning steps.
Task Scaling and Robustness
ActiveMem shows increasing margins over baselines as task difficulty and horizon increase (particularly on the BrowseComp-Plus medium and hard splits). Centralized approaches suffer from rapidly escalating context and computational cost or sharp accuracy degradation due to aggressive content summarization. The ablation studies confirm that the persistent, query-conditioned memory pool and the efficacy of consolidated gist retrieval are both necessary for the observed accuracy and cost advantages.
Component Analyses
Memory Shards and Memorizer Efficacy
Removing persistent storage (i.e., reverting to a stateless distillation) results in both higher computational expense due to gist recomputation and a notable drop in accuracy. Memory consolidation (merging gists for new queries over the same document) is indispensable for maintaining a compact, non-redundant context window for the Planner and minimizing quadratic context cost, as shown by the cost breakdown.
The Planner’s computational cost inversely correlates with the strength and alignment of the Memorizer. Task-specialized, reasoning-optimized SFT of the Memorizer produces higher-quality gists that empower the Planner to reduce incremental reasoning rounds and unnecessary query expansion.
Parallelization and Active Reuse
By leveraging parallel Routing and Memorizer invocation (max concurrency = number of shards), ActiveMem maintains a throughput advantage, absorbing greater evidence volume at lower cost. The Operator’s similarity-judging sub-module prevents superfluous recomputation and focuses consolidation efforts on augmenting the semantic coverage of the shard pool without introducing redundancy.
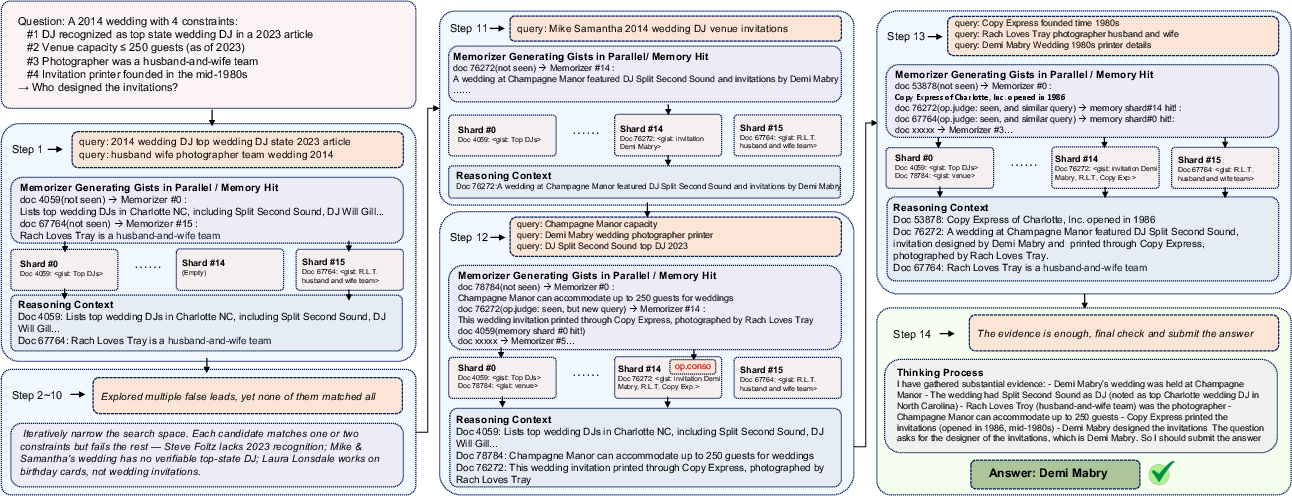
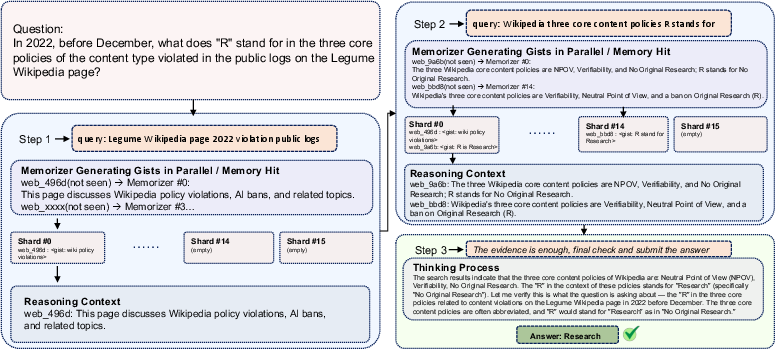
Figure 5: Case studies illustrating long-horizon multi-hop reasoning on BrowseComp-Plus (top) and shorter convergent behavior on GAIA (bottom), showcasing context compaction and evidence reuse.
Implications and Future Directions
ActiveMem’s decoupled architecture mitigates the fidelity–scalability trade-off afflicting centralized approaches and exposes several avenues for additional improvement in realistic agentic workflows:
- Extension to Multimodal/Multiagent Systems: As memory and reasoning are fully separated, each can be augmented, distributed, or hierarchically layered without revisiting core agent logic.
- Differentiable Memory Management: The persistent, shard-based memory naturally supports gradient-based or RL-based memory routing/management policies.
- Fast Test-Time Scaling: Offloading evidence processing allows for elastic scaling with memory and compute resources, surpassing the return-on-parameters limitation of monolithic LLM inference (Snell et al., 2024).
- Memory Synthesis and Domain Adaptation: Future work may integrate domain-specific gist extraction protocols, consolidation heuristics, or incorporate episodic procedural memory to further approach human-like meta-cognitive flexibility.
It is worth highlighting that the framework's efficiency arises not from any single optimization but from the systematic architectural decoupling and parallelism—making it amenable to both hardware-aware deployment and independent memory/reasoning upgrades.
Conclusion
ActiveMem operationalizes a neuroscience-inspired paradigm for scalable LLM agent memory, demonstrating that distributed, actively maintained memory with persistent, semantic gist storage and reasoning decoupling can achieve high accuracy and computational efficiency on challenging long-horizon benchmarks. This approach challenges the necessity of the context-length—information-fidelity trade-off and sets the stage for further architectural advances in scalable, robust agentic systems (2606.10532).