- The paper introduces a novel taxonomy categorizing agent memory systems along four axes, defining paradigms like long-context and agentic control flow.
- It empirically profiles ten architectures, revealing that construction cost, not just accuracy, primarily governs energy and latency tradeoffs.
- The study recommends system designs employing batching, active memory management, and tool iteration caps to optimize fleet-scale, long-horizon deployments.
Systems Characterization of Agent Memory for Long-Horizon LLM Agents
Introduction
As the deployment of LLM-based agents extends to long-horizon tasks, persistent stateful memory becomes a critical system requirement. The study "Agent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads" (2606.06448) conducts the first systematic characterization of agent memory systems, focusing on their computational, energetic, and latency tradeoffs. An in-depth taxonomy is introduced, organizing memory paradigms along four axes: construction, storage, retrieval, and mutability. The work empirically profiles ten architectures, spanning deterministic and LLM-mediated pipelines, and exposes how design choices fundamentally impact system-level behavior. Notably, it demonstrates that cost and overhead are governed not only by accuracy but predominantly by the construction pipeline and the write/read split. Implications extend from single-user deployment to fleet-scale multi-agent operation, with practical recommendations for each regime.
Taxonomy of Agent Memory Systems
The taxonomy proposed classifies agent memory systems into four major paradigms: long-context memory, flat RAG memory, structure-augmented RAG memory, and agentic control flow. These paradigms differ fundamentally in their approach to memory construction, database representation, retrieval flow, and mutability mechanisms.
Paradigm I, long-context memory, naively leverages the model's context as memory, with previous interactions packed into the prompt window. It does not scale beyond the context size and incurs quadratic costs with history length. Flat RAG memory (Paradigm II) applies deterministic chunking/indexing and uses single-pass retrieval, minimizing construction but limiting expressiveness. Structure-augmented RAG (Paradigm III) extracts structured memory (facts, triples, summaries) via LLM-mediated or deterministic pipelines, separated into append-only and consolidating variants. Finally, agentic control flow (Paradigm IV) exposes memory operations as LLM-callable tools within the agent loop, enabling mutation and complex reasoning with compositional stores.
Memory Execution Pipeline and Profiling Methodology
A canonical execution pipeline is delineated, separating ingestion, construction, storage, retrieval, prompt assembly, generation, and maintenance. The profiling harness open-sources standardized per-phase attribution of tokens, calls, latency, hardware utilization, and energy. This enables phase-aware system characterization and cross-system comparison independent of downstream accuracy.
The suite includes both MemoryAgentBench (incremental multi-turn, single-session memory) and MemoryArena (multi-session, interdependent task structure) for comprehensive realism.
Empirical Characterization
The study reveals that per-query serving latency, when decoupled from construction, varies by two orders of magnitude across systems but does not capture the full operational cost.
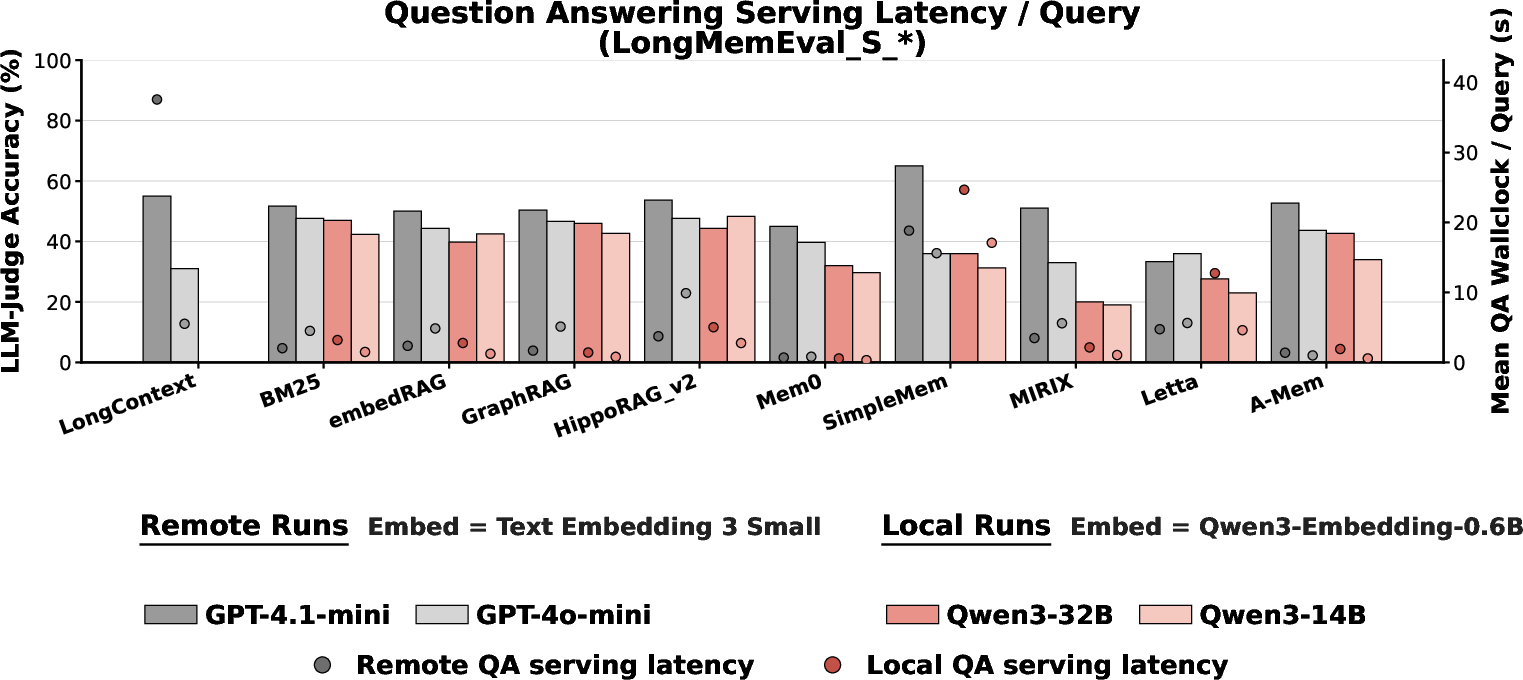
Figure 1: Comparative serving latency for long-context prompting versus external agent memory, demonstrating dramatic improvements in agent memory systems.
Construction-Phase Energy and Cost
Crucially, construction cost dominates the agent lifecycle for LLM-mediated systems, with energy per correct answer spanning over 47× between systems of similar top-line accuracy.
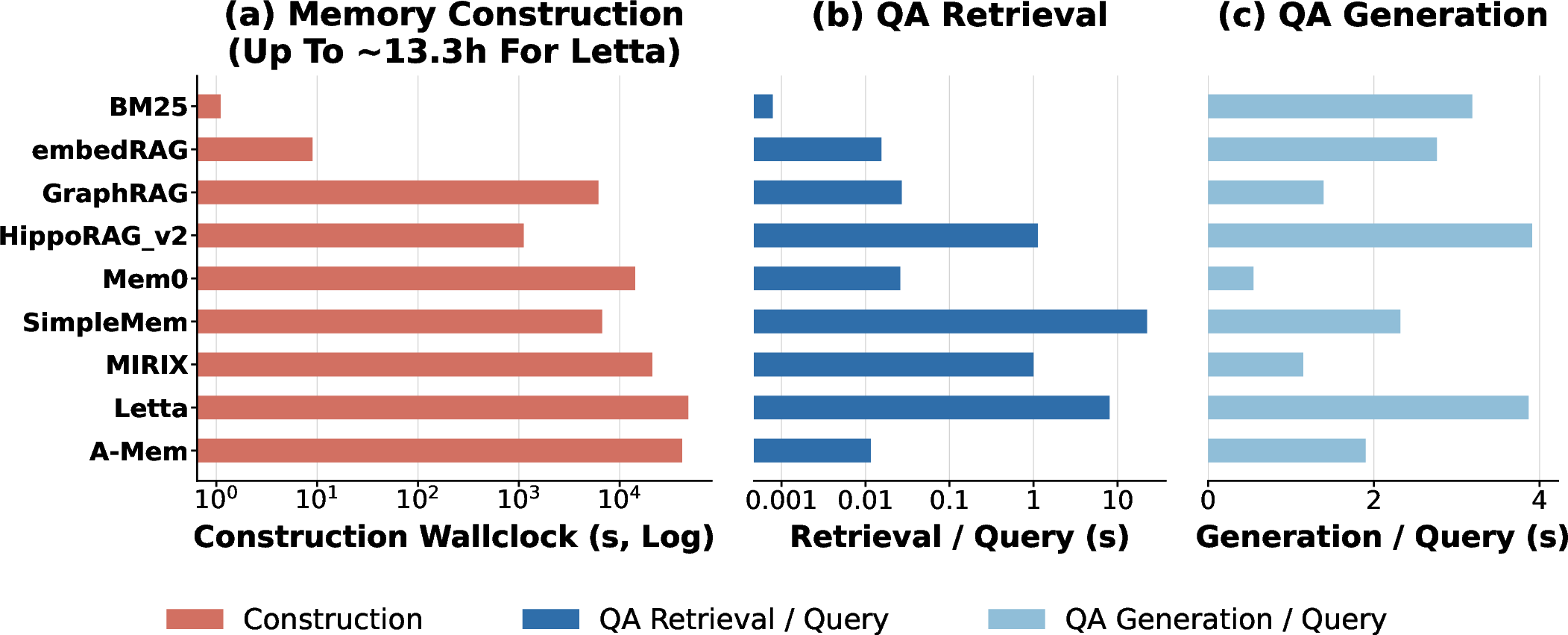
Figure 2: Breakdown of energy and wall time, emphasizing construction cost as the primary lifecycle bottleneck in most paradigms.
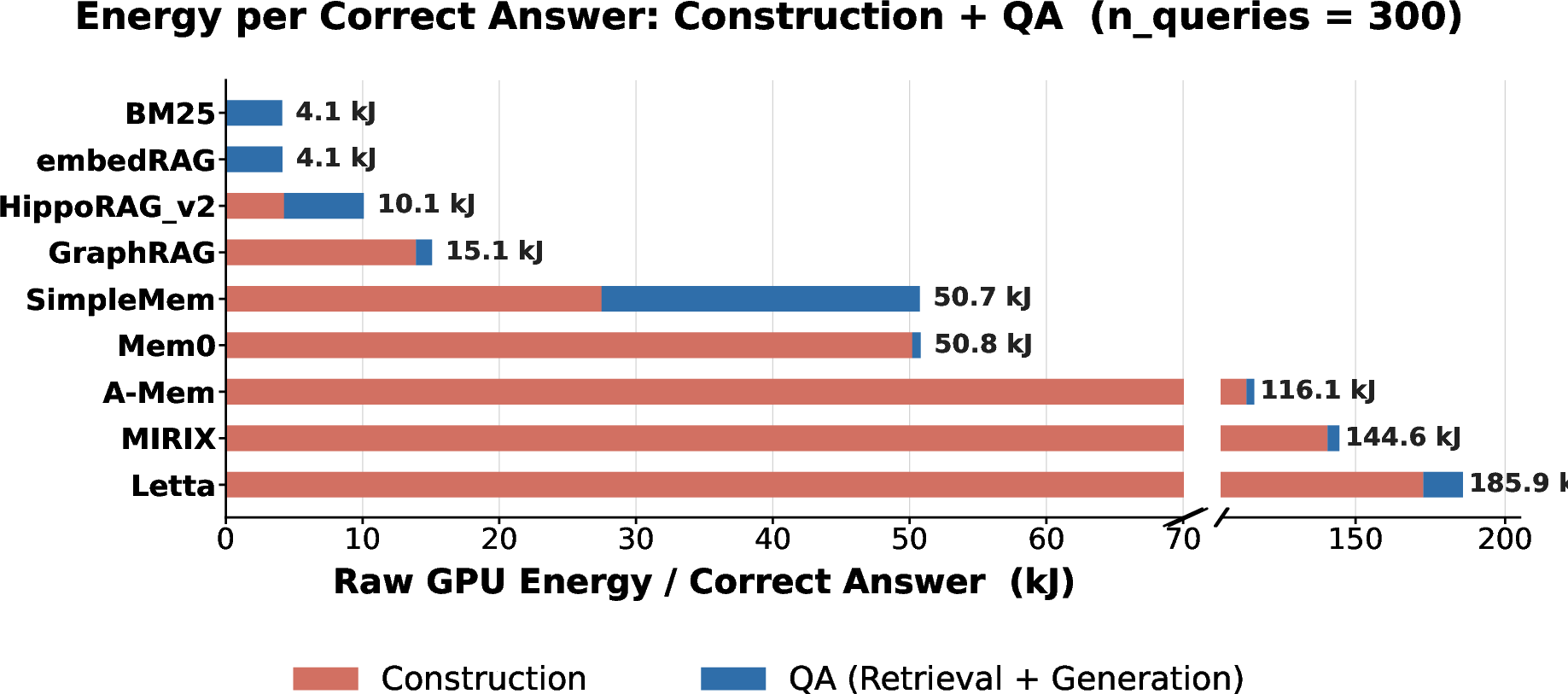
Figure 3: Energy cost per correct answer illustrating the dominant contribution of the construction phase.
Traffic Structure and System Bottlenecks
Profiling demonstrates that construction is both embedding- and prefill-dominated, entailing high memory overhead and head-of-line blocking risk for latency-sensitive QA traffic. Embedding patterns are paradigm-specific—large-batch for append-only systems, sequential for agentic/consolidating systems.
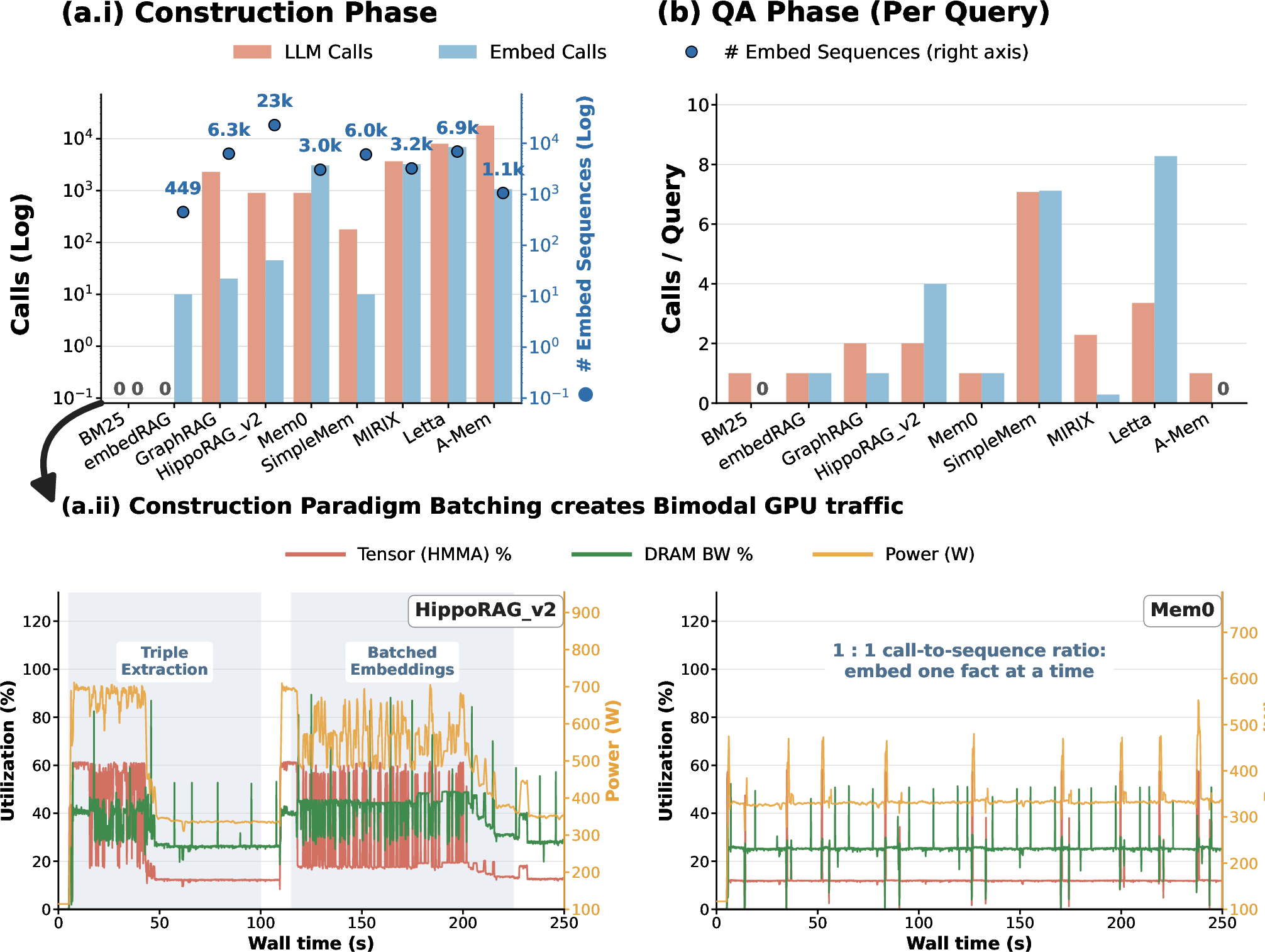
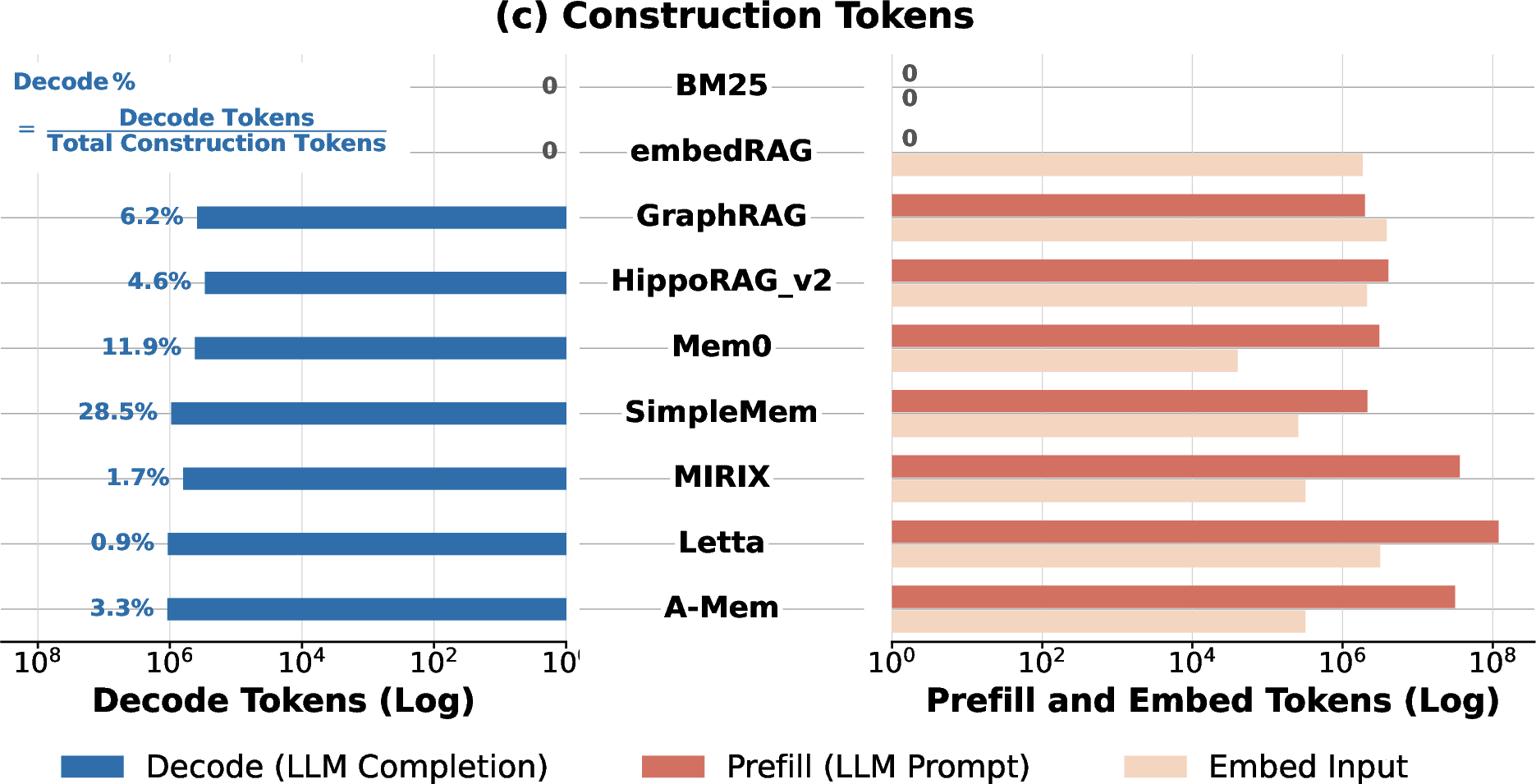
Figure 4: Decomposition of construction-phase call types and token utilization, exposing the write/read workload balance.
Construction Model Sensitivity
Investigation of model scaling on construction LLMs indicates that relaxations are only possible where the construction algorithm is robust to partial output fidelity. Strict schema requirements (as in MIRIX) establish hard lower bounds on viable LLM size and cost.
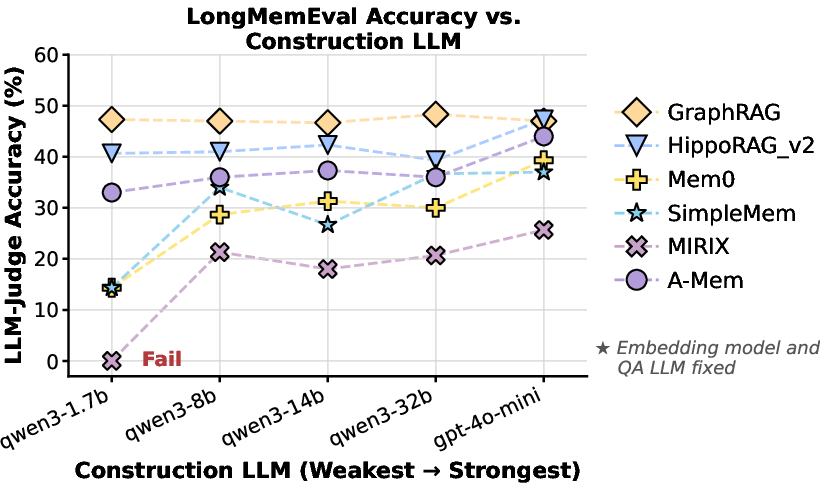
Figure 5: Performance degradation with construction LLM downscaling is algorithm-dependent, reflecting output contract rigidity.
The Construction–Serve–Accuracy Frontier
No single agent memory system optimizes for construction cost, per-query latency, and accuracy simultaneously. Flat deterministic indexing (BM25) achieves highest aggregate accuracy under some benchmarks with minimal energy, but fails on tasks demanding compositional or inferential memory.
Figure 6: Construction–serve–accuracy tradeoff surface. Fast construction, low latency, and high accuracy cannot be simultaneously maximized across paradigms or workloads.
Scheduling, Staleness, and Freshness–Latency Tradeoff
Multi-session regimes expose a fundamental tradeoff: when construction outpaces session arrival, the system must choose between serving with stale memory or blocking for synchronous completion, directly impacting user-perceived latency and result freshness.
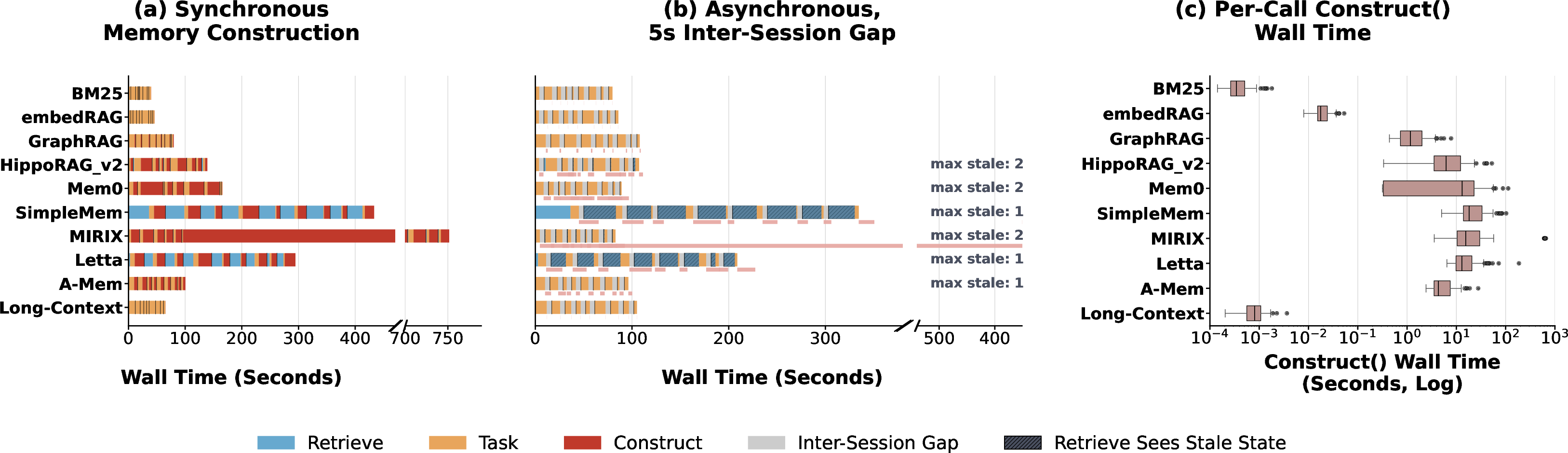
Figure 7: Scheduling and write latency under multi-session workloads, demonstrating the infeasibility of synchronous construction for agentic systems.
Memory footprint increases monotonically with history length for most systems but with up to 9× spread between paradigms. Token cost for construction can grow super-linearly (notably in agentic flows) if maintenance/purging is not implemented.
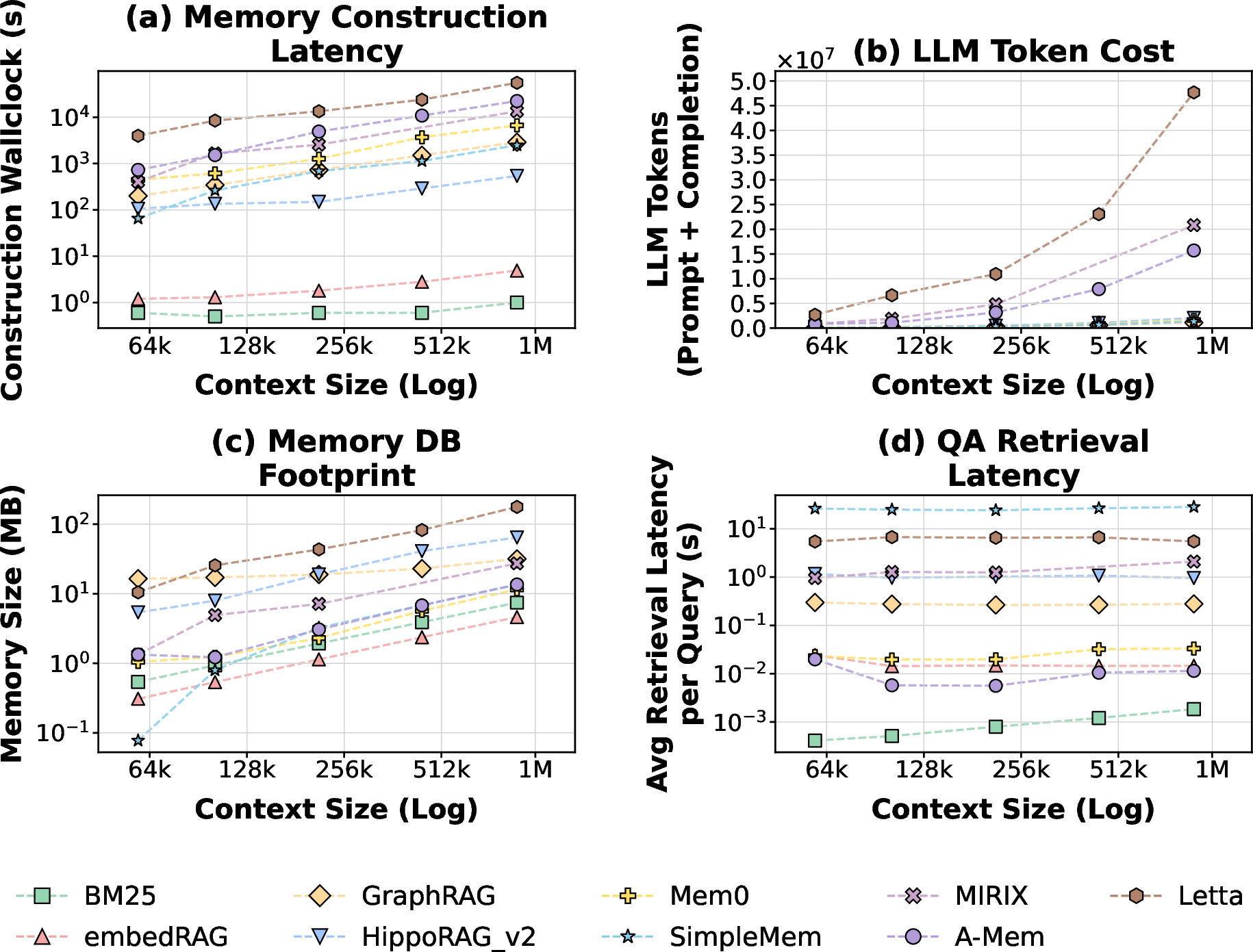
Figure 8: Growth in construction time, LLM usage, retrieval latency, and on-disk storage as user history length increases.
Retrieval Latency Structure and Tail Behavior
Deterministic retrieval systems achieve tightly bounded latency tails, while agentic and LLM-bounded flows exhibit wide-tailed worst-case runtimes necessitating explicit iteration capping for SLO satisfaction.
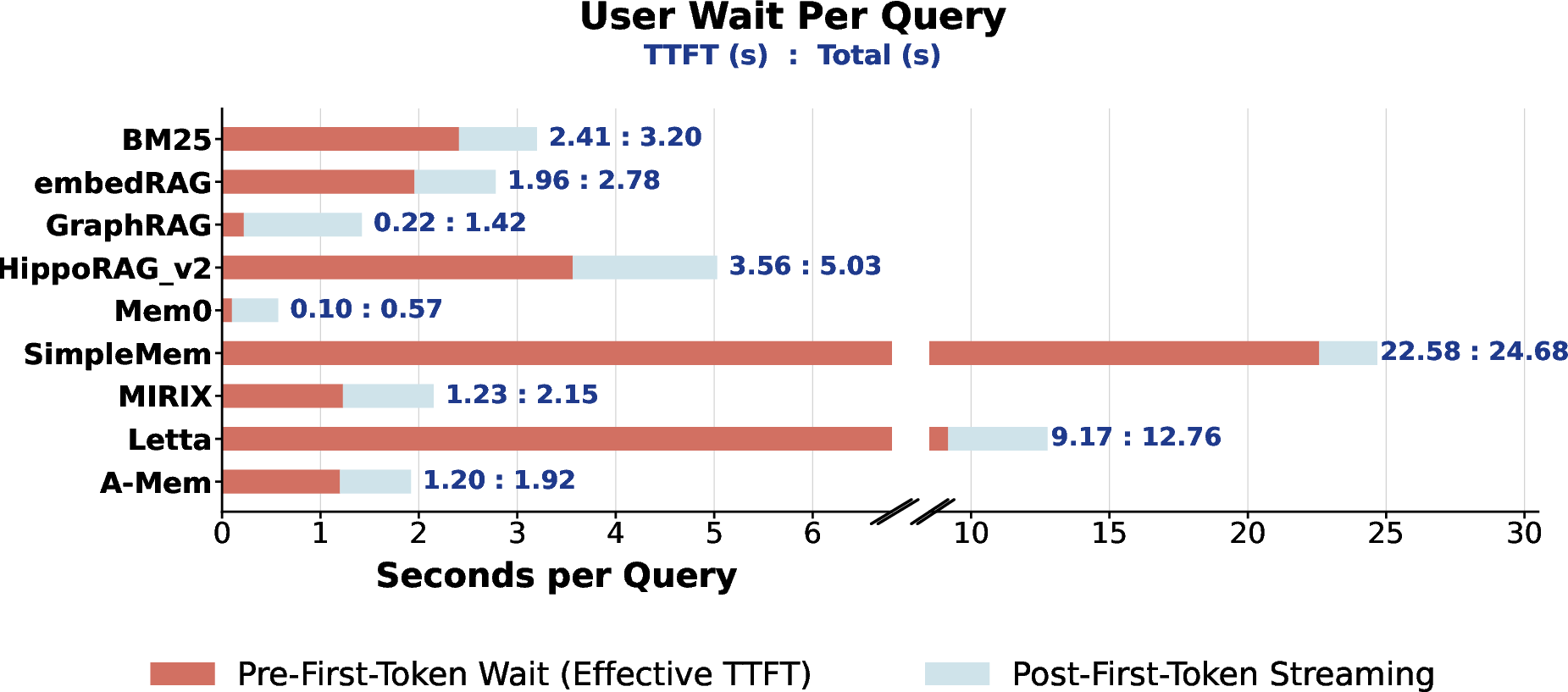
Figure 9: Time-to-first-token decomposed by retrieval pipeline depth and organizational paradigm.
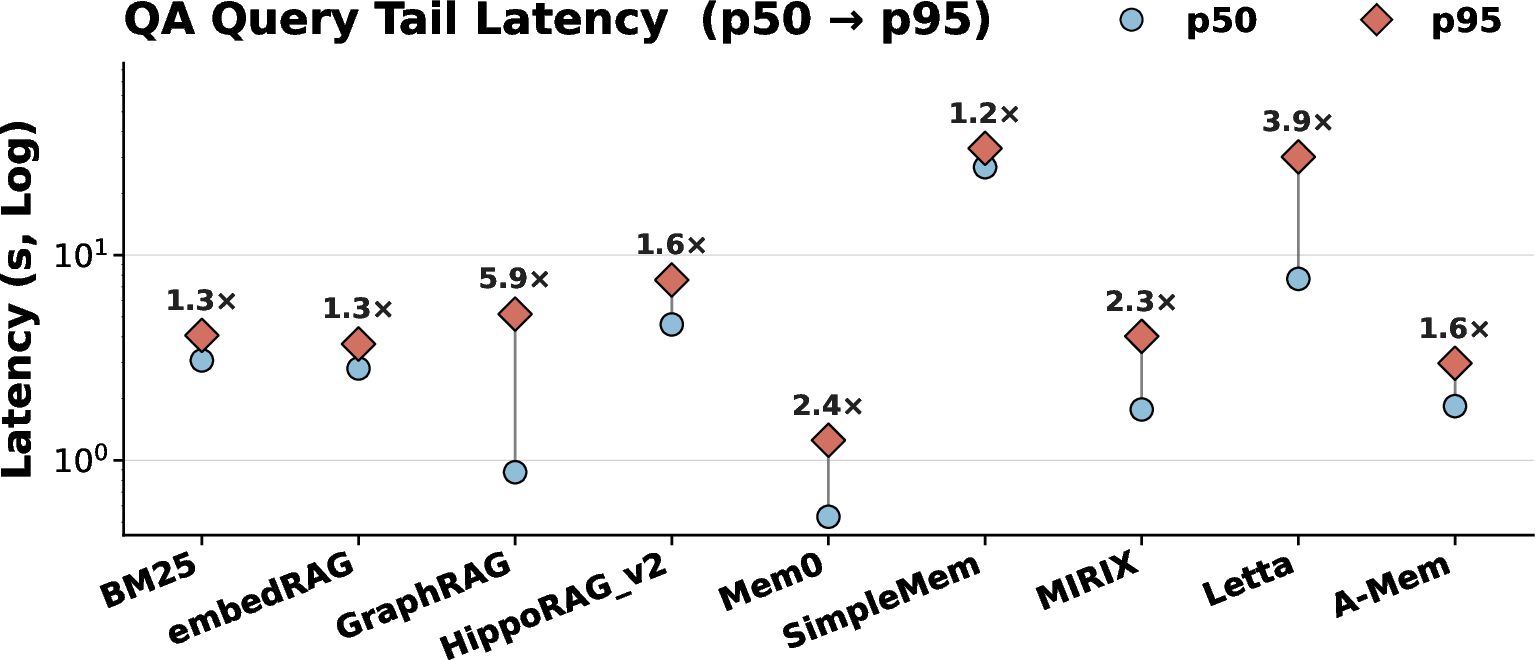
Figure 10: Tail latency statistics highlighting the necessity for system- or operator-imposed bounds on iterative or tool-driven agentic pipelines.
Implications and Recommendations
The central finding is that agent memory system choice is a systems engineering decision, not reducible to accuracy-based metrics. Construction cost dominates both energy and time in most modern agentic or structured paradigms, requiring scheduling, admission control, and hardware resource allocation distinct from traditional prompt-based serving. For inter-session or multi-agent deployment, compounded memory growth and freshness-latency restrictions put practical limits on what is feasible without new summarization/compaction policies.
Operators should:
- Match memory paradigm to task requirements, balancing construction/serving energy and capability.
- Enforce batching, admission, and prioritization in serving stacks to prevent construction-induced head-of-line blocking.
- Instrument and cap iteration/tool calls in LLM-driven pipelines to guarantee latency bounds.
- Monitor and manage memory growth—not just footprint but also construction token cost growth—with active forgetting, pruning, or summarization.
- Profile and validate minimal construction LLM for algorithmic viability, not just top-line QA accuracy.
Conclusion
This work establishes definitive characterization of agent memory as a novel workload class, distinct from both naive long-context LLM and classical RAG architectures. Cost and system design are dictated by the details of the construction and retrieval pipeline, with deeper implications for fleet-scale, multi-tenant, and real-time serving. As agentic workflows grow to encompass more modalities and reasoning depth, the profiling methodology and paradigm taxonomy here provide essential structure for future AI systems research.

