Self-Compacting Language Model Agents
Abstract: Long agent traces composed of chains of thought and tool calls accumulate stale content that anchor subsequent generations, and eventually outgrow the context window. Existing scaffolds mitigate it with fixed-interval compaction triggered at a token threshold. Such triggers pay no heed to trajectory structure, risking discard of partial results mid-derivation or mid-search. We propose SelfCompact, a scaffold that allows the model itself to decide when and how to compact. Specifically, it pairs two inference-time elements: (i) a compaction tool the model invokes to summarize the accumulated context, and (ii) a lightweight rubric specifying when to fire (a sub-task has resolved, or the trajectory is converging) and when to suppress (mid-derivation, or when stuck). Both are needed. The tool alone is unevenly used across open-weight models, often invoked at unhelpful moments or not at all; the rubric alone cannot act. Together, they elicit effective adaptive compaction without any fine-tuning or external supervision. We present empirical results on six benchmarks (competitive math and agentic search) and seven models. Our results show that SelfCompact matches or exceeds fixed-interval summarization at a fraction of the token cost, improving over a no-summarization baseline by up to 18.1 points on math and 5-9 points on agentic search at 30-70% lower per-question cost. Our results expose a meta-cognitive gap: although unprompted models cannot reliably tell when their own context is rotting, a lightweight rubric closes this gap, reframing when to compact as a capability that scaffolds can supply without training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (the big picture)
This paper looks at a problem that happens when AI assistants think for a long time. As they write long chains of thoughts and make many tool calls (like web searches), they keep everything in one big “memory” called a context. Old, wrong, or no-longer-useful bits pile up and start to mislead the AI—a problem the authors call “context rot.” The paper introduces a simple, training-free way for the AI to clean up its own notes at the right moments so it stays focused and accurate. They call this method SelfCompact.
The main questions the authors ask
The authors focus on one core idea:
- Can an AI notice when its own notes are going stale and clean them up—by itself—without retraining?
More specifically, they ask:
- When should an AI summarize and shrink its running notes?
- How can it do that without cutting off important steps mid-thought?
- Can a simple set of rules help the AI choose good times to clean up?
How their method works (in everyday terms)
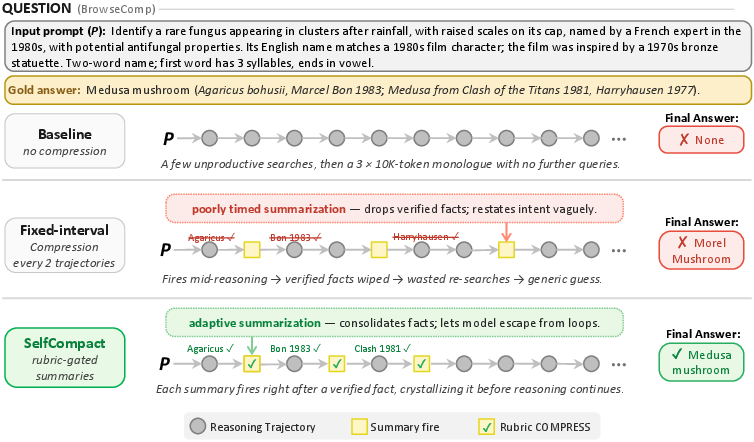
Imagine you’re solving a big puzzle and keeping a messy notebook. If you never clean it, your notebook gets huge and confusing. If you clean it on a fixed timer (say, every 10 minutes), you might erase something important in the middle of a step. The best time to tidy up is right after you finish a small sub-task—when your work has a natural stopping point.
SelfCompact gives the AI two things to make that happen:
- A “summarize” tool: When used, the AI writes a short, clean summary of what matters so far and continues from that smaller summary instead of the messy full history.
- A tiny checklist (a rubric): Every so often, the AI asks itself simple questions like “Did I just finish a sub-task?” “Is my search converging on an answer?” “Am I in the middle of a calculation?” If the checklist says “now is a good stopping point,” it summarizes; if not, it keeps going.
A few key details, explained simply:
- The AI reuses its recent “thinking shortcuts” (called a cache) so asking the checklist and writing the summary is cheap.
- The AI doesn’t need to be retrained. Both the judge (using the checklist) and the summarizer are the same AI you’re already using—just with good instructions.
- Timing matters: compressing right after a sub-task prevents chopping off a calculation mid-step and keeps important facts that were already verified.
What they tested and how
The authors tried SelfCompact on two types of tasks:
- Competition math problems: these require multi-step reasoning (like long scratch work).
- Agentic web search: the AI browses and checks facts across many pages before answering.
They compared four strategies:
- No compaction (keep everything, which gets messy and expensive).
- Fixed-interval compaction (summarize at a fixed size or time, regardless of what’s happening).
- Simple deletes (throw away lots of history on a fixed schedule).
- SelfCompact (summarize only when the checklist says it’s a good time).
They measured:
- Accuracy: How often the AI gets the correct answer.
- Cost: How many tokens (and therefore money) it spends per question.
The main results (what they found and why it matters)
Here are the main takeaways:
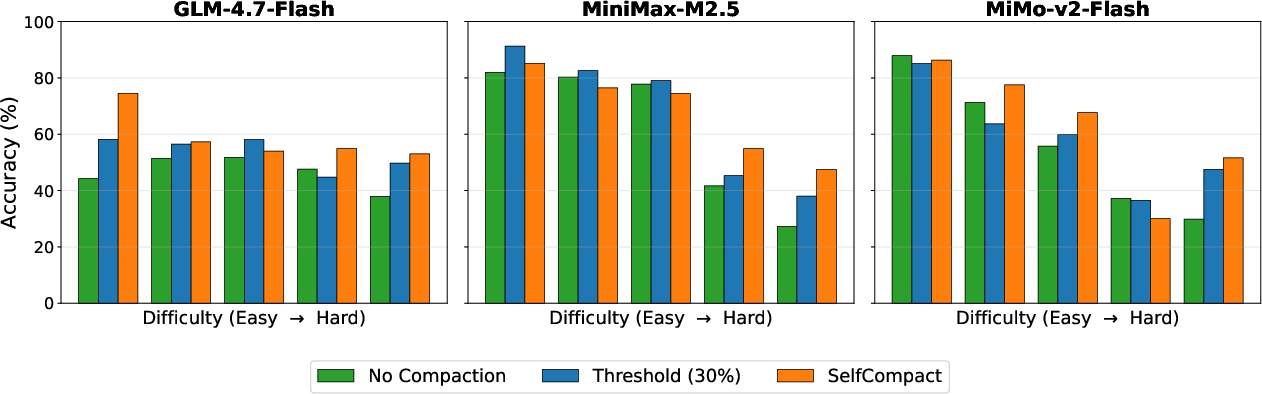
- SelfCompact improves accuracy while costing less.
- On math problems, it beat “no compaction” by up to about 18 points and matched or beat fixed schedules in most cases.
- On web search tasks, it added around 5–9 accuracy points while using 30–70% less cost per question.
- Timing is everything.
- Fixed schedules often summarize at bad moments (like mid-derivation), which can erase useful steps.
- SelfCompact’s checklist tends to trigger summaries earlier and at more natural breakpoints (right after a sub-goal is done), keeping key facts and dropping stale or distracting text.
- The checklist (rubric) is crucial.
- Giving the AI just the summary tool (without the checklist) led to messy timing—sometimes summarizing too often or not at all.
- Adding a short, clear checklist made the AI choose better moments to compress, which consistently improved results.
- It helps most on harder problems.
- The tougher the question (the longer the AI needs to think), the bigger the benefit from smart, well-timed cleanups.
Why this is important (the impact)
As AIs tackle longer, more complex tasks, they need to manage their own “notebooks” wisely. This paper shows that:
- A simple, training-free scaffold (a tool + a tiny checklist) can give AIs a kind of “meta-cognition”—the ability to notice when their notes are getting messy and clean them up at the right time.
- This makes them more accurate, faster, and cheaper to run.
- It also means you don’t have to retrain or build a new model—just layer this method onto the AI you already use.
In short, SelfCompact is a practical way to keep long-thinking AIs sharp: summarize when it makes sense, not just when a timer goes off.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide immediate follow-up research:
- Frontier-model generalization: Does SelfCompact still help with frontier LMs (e.g., GPT, Claude, Gemini) that may exhibit stronger metacognitive abilities? Run controlled comparisons to quantify incremental gains (or redundancy) of rubrics for such models.
- Rubric portability and sensitivity: How robust are outcomes to rubric wording, length, and structure? Systematically vary phrasing across models and tasks to measure sensitivity and establish best practices or invariances.
- Automatic rubric induction: Can rubrics be learned or induced (e.g., from traces, heuristics, or feedback) rather than hand-crafted per task, and do learned rubrics transfer across domains and models?
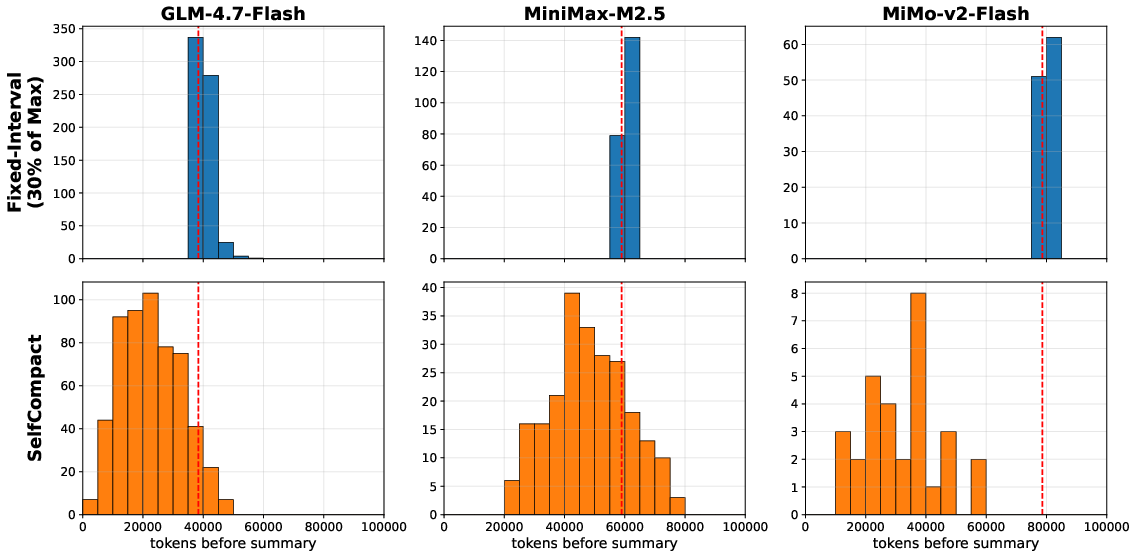
- Probe cadence optimization: The method still probes at fixed intervals N. What is the optimal, event-driven or uncertainty-aware probe scheduling, and how do different N (or adaptive N) trade off accuracy vs. cost/latency?
- Faithfulness of summaries: What fraction of summaries omit or distort needed facts? Introduce summary faithfulness audits (factuality/entailment checks, unit tests in code tasks) and quantify downstream error propagation.
- Summary length control: How does performance vary with target summary length and compression ratio L/ℓ? Develop decoding constraints or reward shaping to hit length budgets without losing critical content.
- “Hard reset” design choice: Is fully replacing history with the summary optimal? Compare against hybrid memory (summary + last-k turns, retrieval buffers, structured fact stores) and quantify retention vs. cost.
- Oracle-approximation gating: The oracle analysis shows large headroom. Evaluate practical proxies (self-consistency, verifier models, calculators/unit tests, web re-checks) to gate compaction near-oracle quality.
- Latency and systems overhead: Beyond token cost, what are the real serving impacts (latency, throughput, GPU memory) in production stacks with/without KV-cache reuse? Benchmark across providers that differ in cache semantics and billing.
- Domain coverage: Validate on code agents (e.g., SWE-bench variants), multimodal tasks, planning/robotics, and long software-debug sessions where traces span millions of tokens; report failure modes per domain.
- Multilingual and domain-shift robustness: Do English rubrics generalize to other languages or technical subdomains (law, medicine)? Test multilingual variants and domain-specific rubrics.
- Misfire analysis: When does the rubric wrongly compress (false positives) or suppress (false negatives)? Build labeled datasets of “safe-to-compact” states and report precision/recall of rubric decisions.
- Tool-noise resilience: How does noisy, delayed, or adversarial tool feedback affect the rubric’s ability to detect subtask closure vs. “stuck” states? Stress-test with injected tool errors.
- Adversarial or erroneous traces: If the trace embeds confident but wrong reasoning, does the rubric prematurely “lock in” a bad summary? Evaluate robustness and design counter-checks (evidence re-verification).
- Training-based baselines: Compare against SFT/RL methods that learn when/what to compact under matched compute and cost budgets; explore distilling rubric behavior into model weights.
- Formal characterization: Provide theoretical or empirical conditions under which compaction improves vs. harms performance (e.g., subgoal separability, verification availability, stability under repeated summarization).
- Operationalizing “closed reasoning units”: Make the notion precise (e.g., via program structure, proof steps, search tree nodes) and evaluate automatic detectors for closure events independent of free-form text cues.
- Long-horizon stability: Quantify cumulative information loss and drift over many compaction cycles (100+), including “summary-of-summary” degradation and mitigation strategies (periodic re-grounding).
- Scaling laws: Map accuracy and cost as functions of context length, problem difficulty, compression frequency, and summary length; derive actionable scaling curves and recommended operating points.
- Controllability knobs: Expose and evaluate user-tunable risk/cost settings (strict vs. permissive rubric criteria, summary granularity) and their impact on accuracy, cost, and latency.
- Privacy and safety: Assess how summaries handle sensitive content (PII, secrets); develop redaction-aware compaction and measure privacy leakage reduction vs. performance.
- Reproducibility of cost claims: The paper uses a single-rate cost approximation and assumes KV reuse; report per-provider billing differences, cache hit rates, and reproducible scripts that compute exact costs.
- Integration with KV eviction: Benchmark SelfCompact combined with token-level KV eviction/compression methods; identify complementary regimes and joint policies that dominate either alone.
- Multi-agent settings: Study shared-memory compaction across collaborating agents (consistency of summaries, conflict resolution) and whether rubrics need to be agent-specific or centralized.
- Evidence quoting reliability: The rubric asks for verbatim evidence from the trajectory; measure exact-match quote rates, partial-match robustness, and whether stricter quote verification improves decision quality.
- Edge cases in tool use: Prevent compaction mid-tool-execution or mid-code block; design guards and unit tests ensuring syntactic/state integrity across compaction boundaries.
- Streaming and UX: Explore interactive/streaming settings where compaction occurs mid-output, and characterize how to communicate summary transitions to users without disrupting comprehension.
Practical Applications
Practical Applications of “Self-Compacting LLM Agents”
Below are actionable, real-world applications enabled by the paper’s findings and scaffold (SelfCompact: a rubric-gated, training-free compaction tool that compacts at closed reasoning units, improving accuracy while reducing token cost). Each item notes sectors, possible tools/workflows, and feasibility assumptions.
Immediate Applications
These can be deployed now with existing LLMs and agent frameworks using prompt-level rubrics and a summarization tool, without fine-tuning.
- Software engineering (developer copilots, code agents)
- Use case: Long-horizon coding agents (e.g., SWE-bench–style tasks) summarize after resolving sub-tasks (e.g., after passing a unit test, completing a refactor, or verifying a hypothesis), suppressing summaries mid-derivation to avoid losing partial reasoning.
- Tools/workflows:
- A “SelfCompact middleware” for LangChain/AutoGen/LlamaIndex agents to probe every N tool calls and summarize on rubric-verdict=compress.
- Git/CI integration: snapshot compacted, auditable summaries with links to test logs.
- Assumptions/dependencies:
- Tool-use capable LLMs with KV cache reuse; task-specific rubrics (e.g., “unit test passed”).
- Summarizer accuracy sufficient not to drop active constraints or TODOs.
- Web research and enterprise search assistants
- Use case: Browse/search agents summarize after verifying a fact cluster or closing a lead, preserving verified facts and citations while discarding stale exploration to cut cost and reduce “context rot.”
- Tools/workflows:
- Browser agent plug-in that fires rubric judgments every K search calls; compaction writes a concise, cite-backed evidence set.
- “Research memory” snapshots to resume efficiently across turns.
- Assumptions/dependencies:
- Access to external tools (browser, retriever), citation extraction; rubric tuned to “verified vs. open” claims.
- Customer support and CX chatbots
- Use case: Long support threads compact after resolving a ticket step (identity verified, issue diagnosed, workaround verified) while suppressing compaction during troubleshooting.
- Tools/workflows:
- Inline rubric: “Is a step resolved, or are we mid-troubleshoot?”; compact into a case note with next-step plan.
- Assumptions/dependencies:
- Accurate detection of resolution states; data retention and privacy compliance for compacted state.
- Knowledge management and meetings (PMO/ops)
- Use case: Meeting assistants or project-bot agents compact after each agenda item into action-item summaries, preserving decisions and owners while collapsing discussion.
- Tools/workflows:
- Agenda-aware rubric (“agenda item closed?”) triggered at set intervals; per-item summary log with due dates and dependencies.
- Assumptions/dependencies:
- Agenda segmentation detection or calendar metadata; human-in-the-loop review for critical decisions.
- Education and tutoring (math, STEM)
- Use case: Tutors compact only after completing a sub-proof or solved sub-problem, preventing mid-derivation truncation that confuses learners and the model.
- Tools/workflows:
- Rubric for “closed reasoning unit” (proof step completed, sub-answer verified); summary with explicit formulas and intermediate results.
- Assumptions/dependencies:
- Task-specific math rubrics (as in the paper); guardrails to avoid hallucinated derivations.
- Retrieval-augmented generation (RAG) and “conversation memory” modules
- Use case: Long conversations or multi-document reading compress into verified, query-specific memory chunks; reduces prompt size while improving recall.
- Tools/workflows:
- Memory controller that queries a rubric (e.g., “is the current hypothesis supported by cited sources?”) to compact into a structured memory store.
- Assumptions/dependencies:
- RAG pipeline compatibility; citation tracking; stable summaries outperform raw-history retention.
- Finance and analyst assistants
- Use case: Compact after closing an analysis phase (data import validated, KPIs computed, anomaly triaged), maintaining auditable snapshots with formulas and source references.
- Tools/workflows:
- “Analysis phase rubric” and snapshot ledger of compacted states; cost-efficient scenario exploration.
- Assumptions/dependencies:
- Audit requirements (retain quotes/links); data governance; summary fidelity.
- Legal review, e‑discovery, and compliance
- Use case: Summarize after resolving sub-issues (e.g., establishing a fact, completing a statutory factor analysis) with citation-labeled facts; suppress mid-argument compactions.
- Tools/workflows:
- Rubric that demands quoted evidence snippets for each retained fact; compaction pipeline produces an evidence matrix.
- Assumptions/dependencies:
- High-precision citation extraction; legal safety review; data access controls.
- Contact centers and field service workflows
- Use case: Agents handling multi-step diagnosis compact after each verified step (device checked, configuration confirmed, symptom reproduced) to reduce cost and accelerate next steps.
- Tools/workflows:
- Rubric integrated into ticketing systems (e.g., ServiceNow) to auto-update case summaries.
- Assumptions/dependencies:
- Robust detection of “step complete”; seamless CRM integration.
- AgentOps/MLOps cost control and observability
- Use case: Introduce a “context-rot guardrail” that probes rubric every N turns; track compaction rate, tokens saved, and answer deltas.
- Tools/workflows:
- SDK for token accounting and KV-cache reuse; dashboards for cost/performance trade-offs.
- Assumptions/dependencies:
- Providers with cache-friendly billing and API semantics; ops instrumentation.
- Personal assistants and daily productivity
- Use case: Long email threads or travel planning sessions compress after each sub-decision (dates fixed, budget accepted), keeping the assistant fast and coherent.
- Tools/workflows:
- Rubric tuned to task milestones; snapshot timeline with decisions and open questions.
- Assumptions/dependencies:
- Calendar/email access; safeguards to prevent premature compaction when preferences are unsettled.
Long-Term Applications
These require further research, validation, scaling, or ecosystem changes.
- Safety-critical clinical decision support (healthcare)
- Use case: Compaction only after clinically “closed” assessments (lab interpretation finalized, differential narrowed), with verifiable references; suppress mid-diagnostic steps.
- Potential tools/workflows:
- Clinically validated rubrics; dual-model verification (summarizer + verifier); EHR integration with audit trails.
- Assumptions/dependencies:
- Regulatory approval, rigorous trials, bias/recall assessments; human oversight; robust citation tracking on clinical evidence.
- Autonomous robotics and task planning
- Use case: High-level LLM planner compacts when waypoints/subgoals complete, reducing memory load and plan drift during long missions.
- Potential tools/workflows:
- Planner–controller loop with rubric gating; summaries translated into formal subgoal graphs.
- Assumptions/dependencies:
- Reliable subgoal completion signals; tight integration with symbolic/optimization planners.
- Scientific agents and automated research
- Use case: Compaction after closing experiment phases (hypothesis set, protocol fixed, results verified), preserving provenance and versioned context across hundreds of trials.
- Potential tools/workflows:
- Lab notebook auto-compaction with evidence links; experiment orchestration systems that resume from compacted states.
- Assumptions/dependencies:
- Structured data logging; reproducibility standards; multi-agent coordination.
- Enterprise multi-agent memory and knowledge curation
- Use case: Organization-wide agents compact and exchange closed-unit summaries, maintaining lean, auditable cross-team context.
- Potential tools/workflows:
- Memory routers that accept only rubric-verified summaries; governance policies for evidence-backed memory ingestion.
- Assumptions/dependencies:
- Standardized summary schemas, access control, lineage tracking.
- On-device/edge agents and low-resource deployments
- Use case: Compaction to extend effective horizons on devices with small contexts or limited compute (call center kiosks, mobile assistants).
- Potential tools/workflows:
- Local KV caching and rubric gating; hybrid on-device/cloud fallback.
- Assumptions/dependencies:
- Efficient caching APIs on-device; compressed models; resilience to connectivity.
- Training-time distillation of “when-to-compact”
- Use case: Use the rubric as a behavioral target for RL/SFT so models internalize compaction timing, reducing inference overhead for probes.
- Potential tools/workflows:
- Offline logs with rubric labels; policy distillation into base weights.
- Assumptions/dependencies:
- Quality of supervision; avoidance of overfitting to narrow rubrics; safety/robustness guarantees.
- Standards and policy for context management in public-sector AI
- Use case: Procurement and governance frameworks mandate rubric-gated compaction, logging of summaries with citations, and reporting of compaction-induced answer changes.
- Potential tools/workflows:
- Compliance checklists; audit APIs for summary snapshots and evidence.
- Assumptions/dependencies:
- Interoperable specs; regulator and vendor alignment; privacy constraints.
- Cost-aware, dynamic compaction controllers
- Use case: Controllers that trade off accuracy vs. spend in real time, adapting probe intervals and rubric strictness to budget and task difficulty.
- Potential tools/workflows:
- Token-cost forecasters; difficulty estimators (as in the paper’s binning analysis) to modulate compaction policy.
- Assumptions/dependencies:
- Stable pricing signals; model introspection reliability on difficulty.
- Cross-modal planning (vision, code, language)
- Use case: Vision-language-code agents summarize closed units (e.g., a verified perception hypothesis, a tested code patch) before switching modalities.
- Potential tools/workflows:
- Modality-aware rubrics; structured summaries linking images/snippets to claims.
- Assumptions/dependencies:
- Robust cross-modal grounding; verifiers per modality.
Notes on Feasibility and Dependencies (common across applications)
- Task-specific rubrics are essential: the paper shows the tool alone is uneven; simple, well-designed guidance closes the “meta-cognitive gap.”
- Provider/API capabilities:
- KV cache reuse across appended messages is crucial for cost benefits.
- Some APIs bill caches differently; savings assume cache-friendly pricing.
- Model behavior:
- No fine-tuning is required, but model must follow tool instructions reliably.
- Summary fidelity matters; hallucinated or overly aggressive compaction can harm downstream steps.
- Auditing and safety:
- For regulated domains, retain snapshots with verbatim quotes/citations; require human oversight.
- Generalization:
- Results are demonstrated on open-weight and several deployed “Flash” agents; behavior may vary on frontier models (which may have stronger metacognition), though the scaffold remains complementary.
By adopting rubric-gated, training-free compaction, organizations can deploy longer-horizon agents that are both cheaper and more accurate, especially on complex tasks where context rot and poorly-timed summaries are most damaging.
Glossary
- Ablation: The experimental removal or modification of system components to assess their contribution. "Ablations find that the rubric is crucial for effective self-compaction"
- Agentic search: An LLM-driven procedure that performs tool-based web/search actions to answer queries. "on agentic search (BrowseComp, BrowseComp-Plus, DeepSearch QA), it adds 5--9 points"
- Autoregressive generation: Token-by-token generation where each token is conditioned on the prompt and all previous tokens. "generates a continuation autoregressively"
- Compaction tool: A model-invoked mechanism that summarizes accumulated context during inference. "a compaction tool the model invokes to summarize the accumulated context"
- Context compaction: Summarizing or condensing the dialogue/history to control length and mitigate degradation. "context compaction has become a standard built-in feature to prevent multi-rounds of long reasoning chains from blowing up the context window."
- Context rot: Performance degradation caused by stale or erroneous prior content anchoring subsequent generations. "This phenomenon is known as context rot"
- Context window: The maximum number of tokens a model can condition on at once. "eventually outgrow the context window."
- Fine-tuning: Post-training adaptation of a model on task-specific data to refine behavior. "without any fine-tuning or external supervision."
- Fixed-interval compaction: Triggering compaction based solely on a fixed token/turn threshold. "fixed-interval compaction triggered at a token threshold."
- Frontier models: The most capable, often proprietary, state-of-the-art LLMs. "Context compaction in frontier models."
- Hard reset: Replacing the existing context with its summary and resuming generation from that condensed state. "hard reset; resume from summary"
- Inference-time: Operations performed during generation (not training), often controlled via prompts/tools. "pairs two inference-time elements"
- KV cache: Cached key/value attention states that allow efficient reuse of prior computations. "To maximize KV-cache reuse, we implement "
- KV-cache eviction: Removing or compressing entries in the key/value cache during inference to save memory/compute. "evicting or compressing KV cache entries during inference."
- Long-horizon tasks: Problems requiring many steps, turns, or extended reasoning/search over large contexts. "LM agents on long-horizon tasks accumulate tokens in a single rolling context"
- Meta-cognitive gap: A shortfall in a model’s ability to monitor and control its own reasoning/context quality. "Our results expose a meta-cognitive gap: although unprompted models cannot reliably tell when their own context is rotting, a lightweight rubric closes this gap"
- Open-weight models: Models whose parameters are publicly available for local inference and customization. "Across seven open-weight models"
- Oracle policy: A hypothetical ideal decision rule used to estimate the upper bound of possible performance. "an oracle policy which suppresses summarization calls whenever the current answer is correct"
- Periodic compaction: Compaction that fires at regular intervals irrespective of trajectory content. "Periodic compaction fires on a fixed interval---every turns or every tokens---regardless of what the trajectory contains"
- Prefill: The initial forward pass to encode prompt/context into the KV cache before decoding. "pays prefill only on the appended instruction"
- Probe interval: The periodic step at which the rubric is consulted to decide whether to compact. "at periodic probe intervals"
- Reactive compaction: Compaction triggered only when nearing the model’s context limit, as overflow prevention. "Reactive compaction triggers only when the rolling context approaches the model's token budget"
- Rubric: A lightweight, explicit set of criteria guiding when to trigger or suppress compaction. "a lightweight rubric specifying when to fire (a sub-task has resolved, or the trajectory is converging) and when to suppress (mid-derivation, or when stuck)."
- Scaffold: An external prompting/control structure that organizes a model’s behavior without modifying weights. "a scaffold that allows the model itself to decide when and how to compact."
- Search–judge–summarize loop: An iterative cycle where the agent searches, evaluates, and summarizes before continuing. "on agentic search this yields a search--judge--summarize--search loop"
- SelfCompact: The proposed rubric-gated, training-free method for adaptive context compaction. "We propose {SelfCompact, a scaffold that pairs two inference-time elements"
- Summarizer: The model-invoked instruction/component that produces a condensed version of the trajectory. "The summarizer is the only real overhead"
- Token budget: The allocation/limit of tokens per question or trajectory used for fair comparison or cost control. "a token budget matched to fixed-interval summarization"
- Tool call: An invocation of an external capability (e.g., web search, code execution) within an agent trajectory. "chains of thought and tool calls"
- Trajectory: The evolving sequence of thoughts, actions, tool outputs, and summaries generated during problem solving. "the trajectories LMs generate to solve them keep growing."
Collections
Sign up for free to add this paper to one or more collections.

