End-to-End Context Compression at Scale
Abstract: Long-context LLM inference is bottlenecked by memory, as the KV cache grows with context length. Recent techniques to compress the KV cache fall short: they either degrade model quality substantially or require considerable time and compute to compress a single long prompt. Furthermore, many methods require the input to fit within the target model's context window, and are generally incompatible with modern production inference engines. Encoder-decoder compressors, which map a long token sequence to a shorter sequence of latent embeddings consumed by a decoder, are an appealing alternative in principle. However, existing approaches are not competitive with KV cache compression on the accuracy-efficiency frontier. In this work, we revisit encoder-decoder compression and close this gap. We first perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors. Guided by our findings, we continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16. We introduce Latent Context LLMs (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage. We demonstrate that LCLMs serve as efficient backbones for long-horizon agents, letting the agent skim through a compressed long context and adaptively expand relevant segments on demand.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping AI LLMs handle very long inputs (like big documents, codebases, or long chats) faster and with less computer memory. The authors build a system called Latent Context LLMs (LCLMs) that “compresses” the input before the main model reads it, so the model can work quickly and still remember important details.
What questions were the researchers asking?
They focus on a simple idea:
- Can we shrink a long input into a much shorter “summary of smart notes” that the model can read instead of the full text—without losing accuracy?
- Can this compression be fast, memory‑friendly, and easy to plug into normal AI systems?
- Can this work for many kinds of tasks (not just one specific domain) and very long contexts?
How did they try to solve it?
Think of a LLM as a student. Normally, when the student reads a long text, they keep a big “notebook” of everything they saw so far (this is the model’s KV cache—its short‑term memory built while reading). With huge inputs, that notebook gets gigantic, slowing the student down and using lots of memory.
The authors take a different approach: they add a second small “student” (an encoder) whose only job is to skim and compress the long text into a short sequence of smart notes (continuous vectors, sometimes called “soft tokens”). The main “student” (the decoder) then reads these smart notes instead of the original long text.
Here’s the approach in everyday terms:
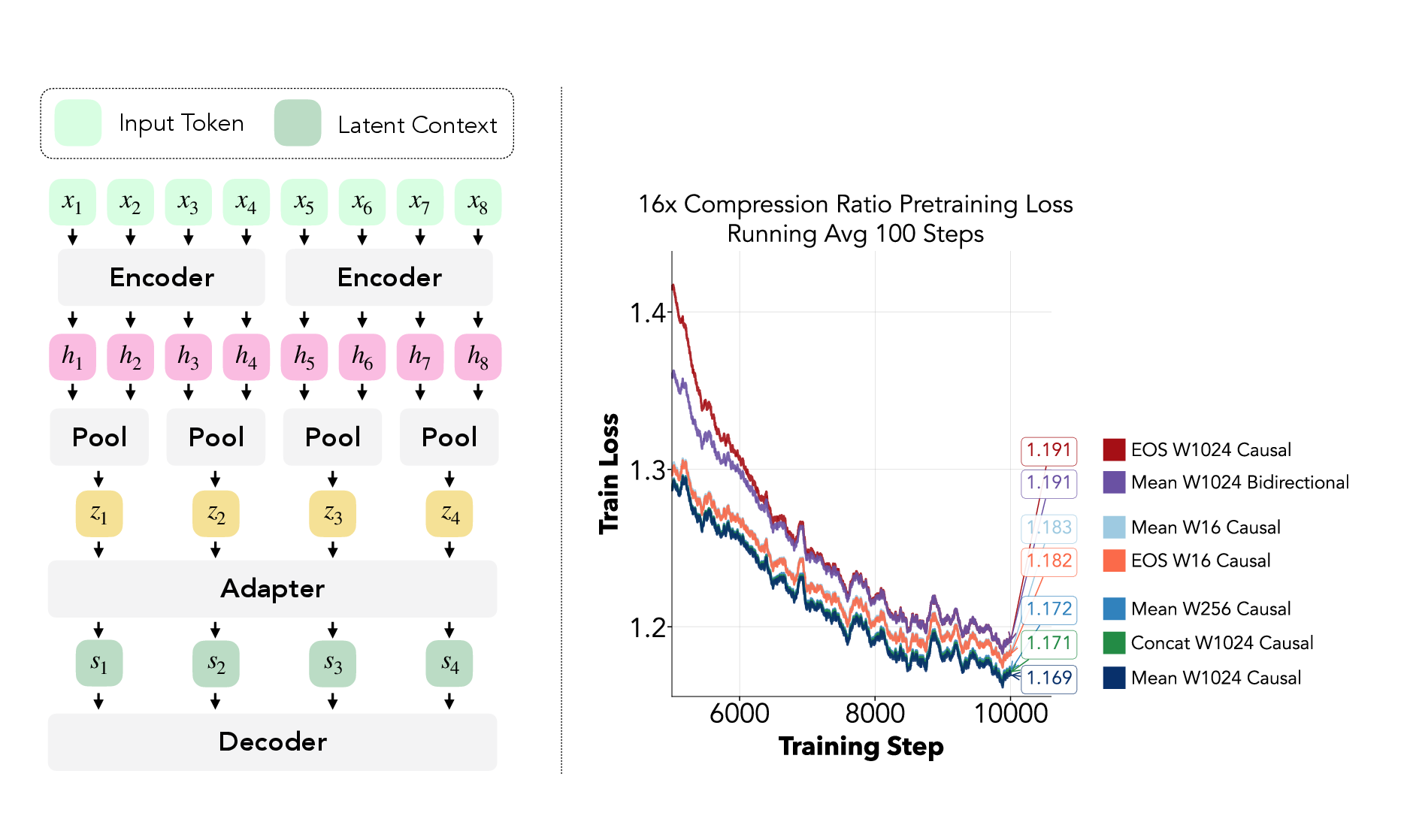
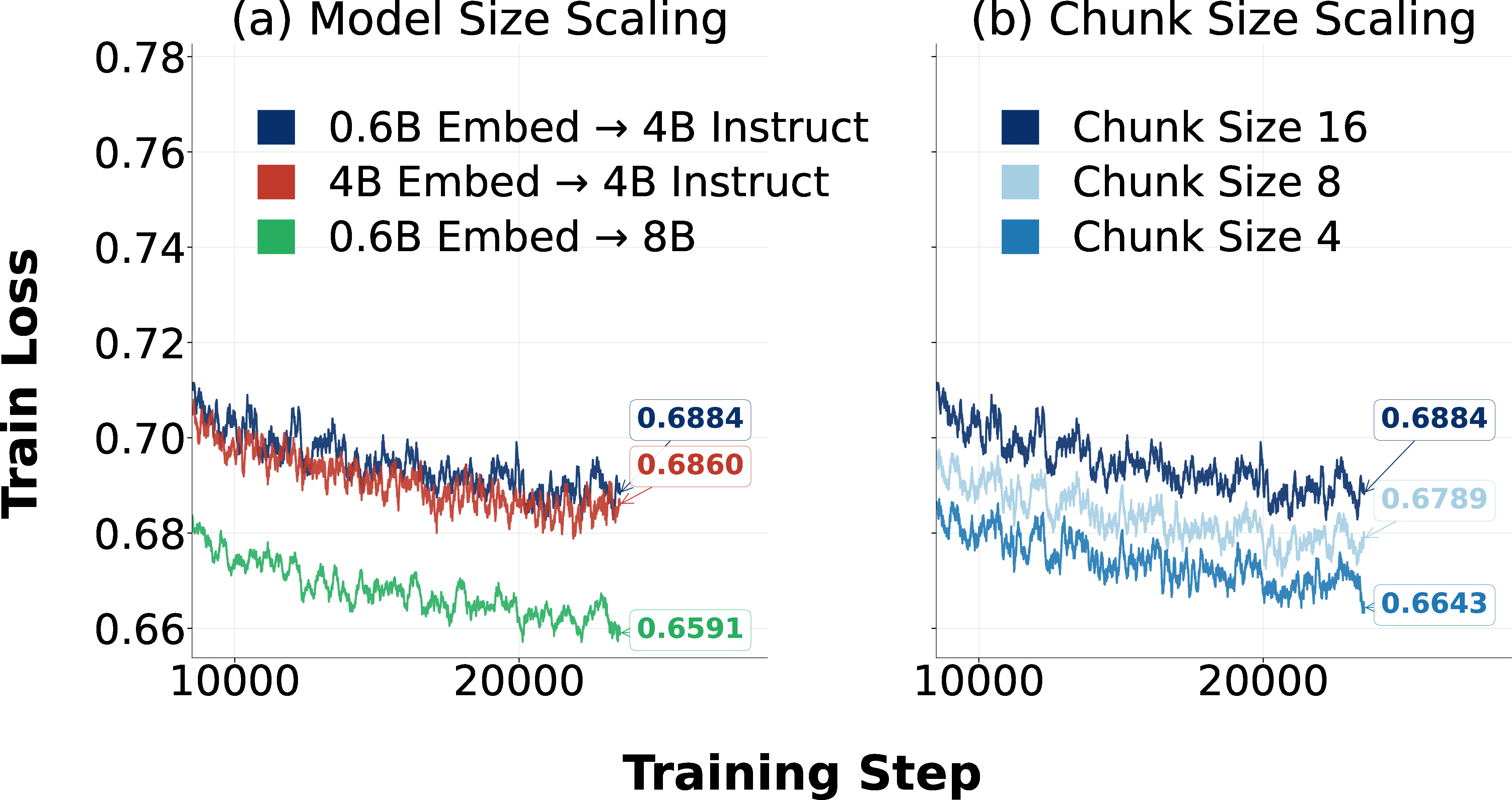
- Encoder (the skimmer): Reads chunks of the long text and turns every N words into a single, rich note. For example, with 16× compression, every 16 tokens become 1 smart note.
- Adapter (the translator): Makes sure the smart notes fit the main model’s format.
- Decoder (the main model): Uses these notes as if they were the original context, then generates the answer.
They trained and tested this system at different compression levels (4×, 8×, 16×), using:
- A small encoder (about 0.6 billion parameters) and a larger decoder (about 4 billion parameters).
- Massive training (hundreds of billions of tokens) to make sure the compressed notes keep both big-picture meaning and fine details (like exact words in code or quotes).
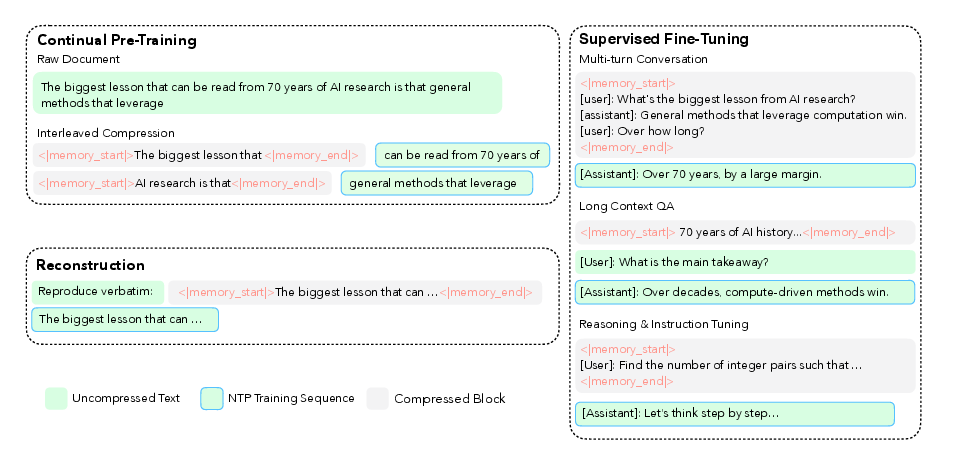
To make the training work smoothly, they used a 4‑stage plan:
- Warm up the adapter (so the two parts talk nicely),
- Train the encoder,
- Train everything end-to-end on lots of mixed data (pretraining),
- Fine‑tune on instruction and reasoning tasks (SFT) so the model follows directions well with compressed context.
They also ran an “architecture search” (lots of controlled experiments) to pick better design choices. Key choices included:
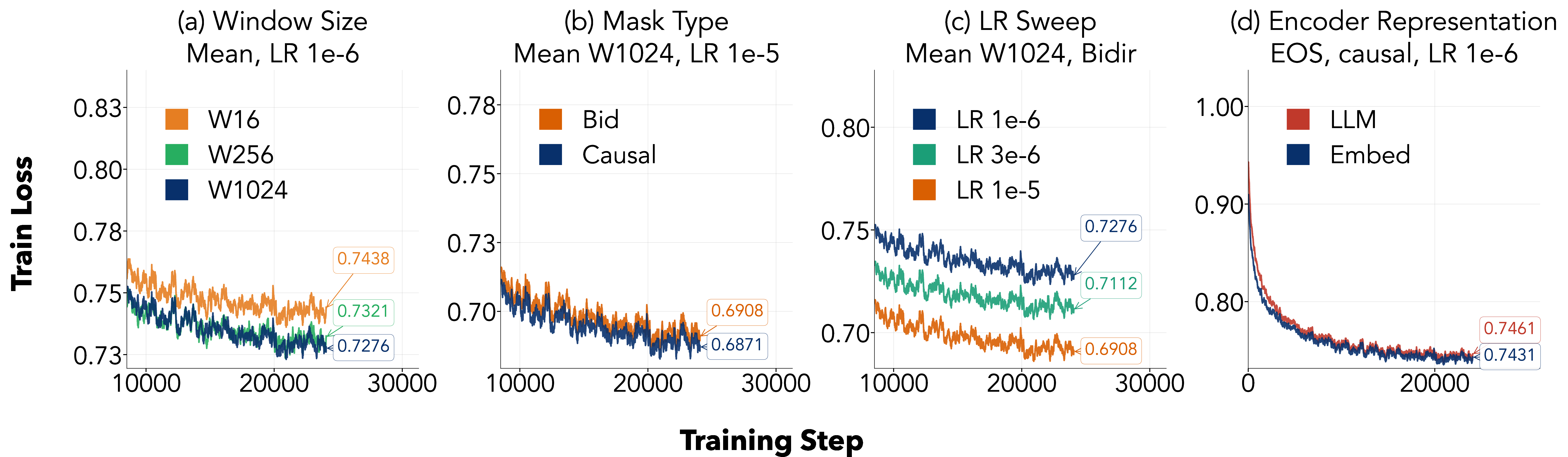
- How to summarize each chunk (mean pooling vs. concatenation vs. special tokens like CLS/EOS),
- How big each encoder window should be when reading,
- Whether the encoder should look only forward (causal) or both directions (bidirectional),
- Whether the adapter should be a simple MLP or include extra attention.
In simple terms: they systematically tried different ways of making smart notes and picked what worked best.
What did they find, and why does it matter?
Here are the main results in clear terms:
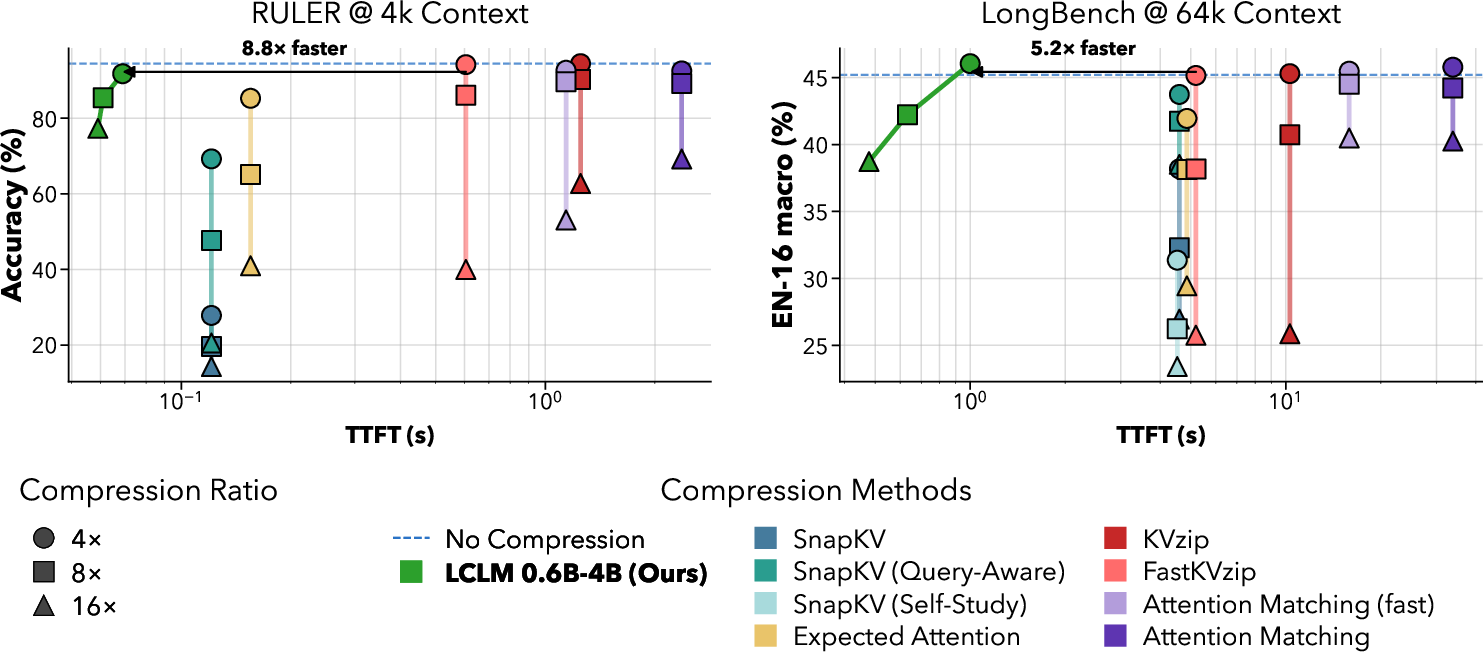
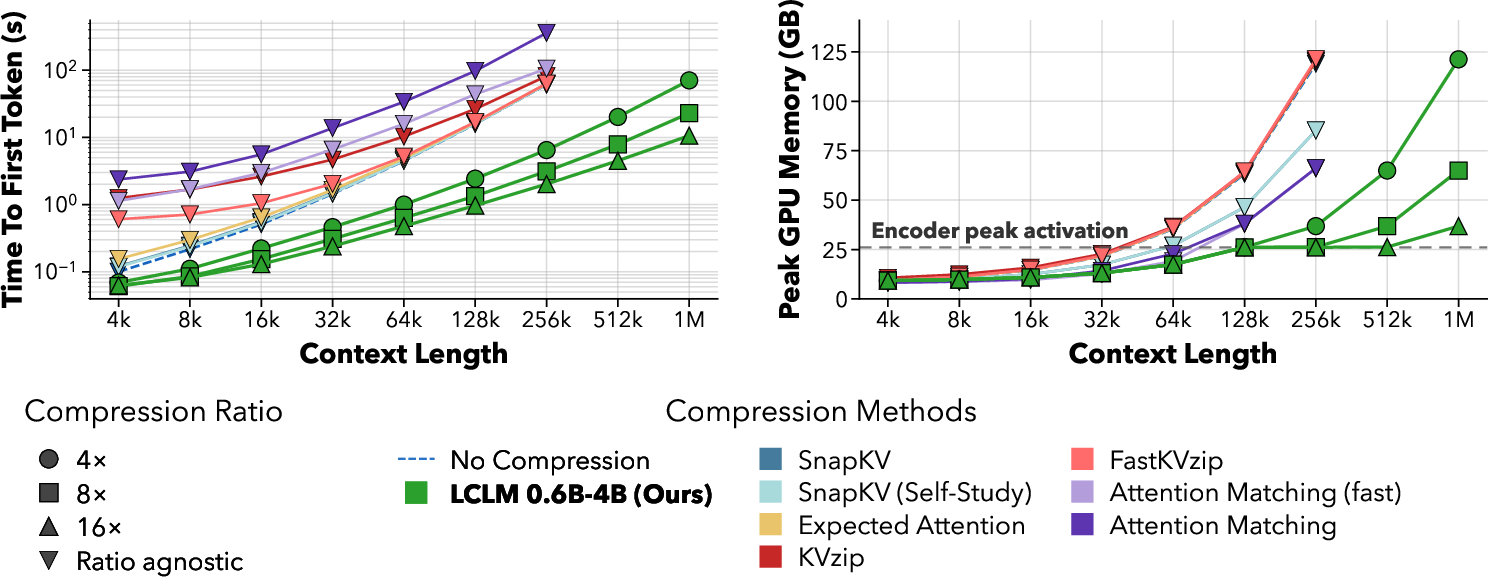
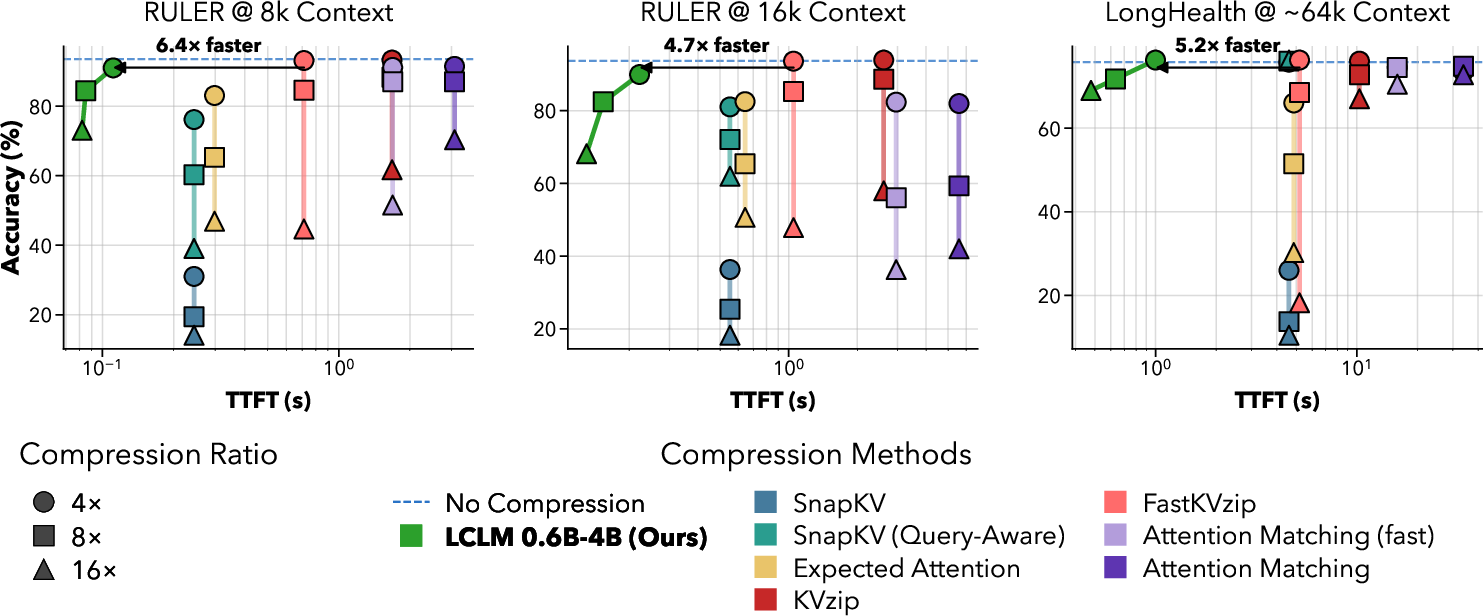
- Faster start time and lower memory: Their compressed approach gets the model generating its first token faster (lower TTFT) and uses less GPU memory, especially for very long inputs (hundreds of thousands to a million tokens). This sets a new best trade-off between speed/memory and accuracy on popular long‑context tests (RULER, LongBench, LongHealth).
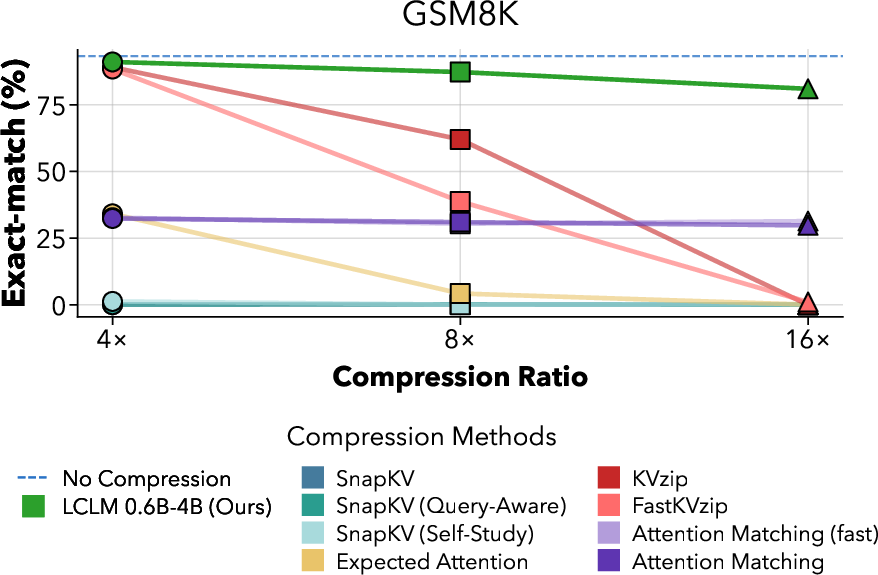
- Keeps accuracy high even at strong compression: At 16× compression, their models often matched or beat methods that compress the model’s internal memory (KV cache). Because they shrink the input before the main model reads it, they avoid the big memory cost of reading the full text first.
- Works well with standard AI systems: Their method uses normal model pipelines, so it’s easier to deploy than many KV‑cache compression tricks that need special, hard‑to‑integrate code.
- Clear design wins:
- Using mean pooling (averaging) for high compression and concatenation for lighter compression worked best overall.
- Having the encoder read 1024‑token windows was better than tiny windows.
- A simple MLP adapter was enough (and faster) than adding extra attention there.
- Causal attention in the encoder worked better than bidirectional in their setup.
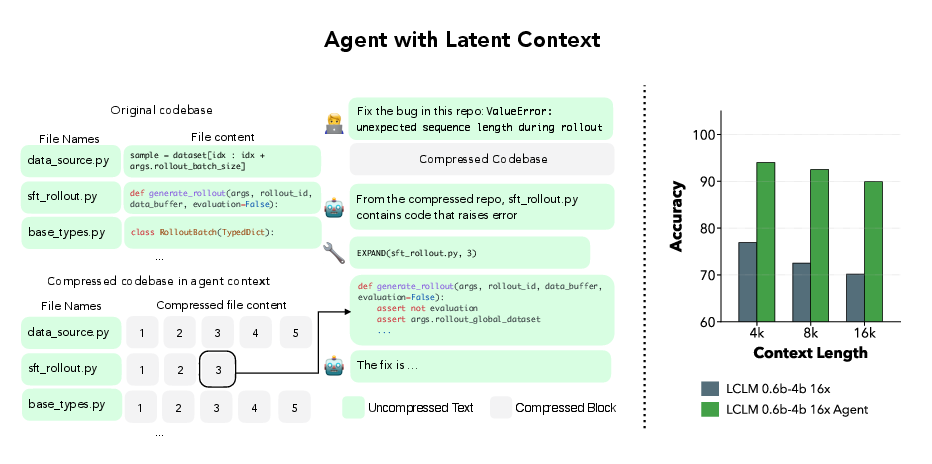
- Smarter agents with “expand on demand”: They built an agent that first skims the compressed notes of a big document and, when needed, asks to “expand” a specific compressed chunk back into the original text. This made the agent much better at tricky “needle‑in‑a‑haystack” tasks, where exact word‑for‑word details matter.
Why it matters: This lets AI handle much longer inputs with today’s hardware, at lower cost, while staying accurate. It also makes long‑horizon assistants and coding agents more practical: they can keep an entire codebase or long report in mind, skim quickly, and zoom in precisely when needed.
What could this change in the real world?
- Cheaper, faster long‑context AI: Companies could run big‑context assistants (for legal docs, medical records, or large software repos) with less memory and cost.
- More capable agents: Agents can “see” the whole picture in compressed form, then expand only the parts that matter—like scanning a library first, then opening just the right pages.
- Better user experiences: Shorter wait times before the model starts responding, even for huge inputs.
- A foundation for future research: This approach could be extended to compress not just inputs but also the model’s own long chains of thought or multi‑turn histories. It could also adaptively compress dense parts less and simpler parts more, getting even better accuracy with the same speed/memory benefits.
In short, the paper shows that end‑to‑end learned compression can make long‑context AI both practical and powerful—by turning long text into smart notes the model can read quickly without losing the details that matter.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps that remain unresolved and could guide future research:
- Ultra-long accuracy under realistic tasks: While time/memory are profiled up to 1M tokens, accuracy is not reported at these lengths on information-dense tasks. Evaluate task performance (e.g., retrieval, QA, code search) at 256K–1M tokens, not just speed/memory.
- Domain and task coverage: Benchmarks focus on RULER, LongBench, and LongHealth; comprehensive evaluations on code (HumanEval/MBPP, CodeSearchNet), math (GSM8K/MATH at long contexts), citation-sensitive QA (NarrativeQA/QuALITY), and structured data (SQL, JSON/XML-heavy prompts) are missing.
- Multilingual/generalization: No evidence that LCLMs preserve fidelity across languages/scripts (CJK, RTL languages) or domain-specific jargon. Test multilingual long-context datasets and cross-lingual retrieval under compression.
- Short-context and general instruction quality: End-to-end effects on common instruction-following and general chat quality at standard context lengths (e.g., 4–8K) are not quantified; measure potential regressions due to compressor conditioning.
- Systems-level integration: Claims of compatibility with vLLM/SGLang are not validated with end-to-end serving. Provide throughput (tokens/sec), P50/P95 latency, and memory under multi-tenant batching, tensor/pipeline parallelism, and paged attention.
- Hardware/precision robustness: Results are on a single H200 and HF Transformers. Quantify portability to other GPUs (A100, H100, consumer cards), mixed precision (FP8/bfloat16), and quantized deployment (8-bit/4-bit W8A8/W4A8) for both encoder and decoder.
- Batching and admission control: Only single-sample TTFT is reported. Characterize performance under realistic batch sizes, dynamic batching schedulers, and mixed-length workloads.
- Encoder window and boundary effects: W=1024 without overlap is chosen based on small-scale loss. Probe at scale whether overlap, learned cross-window tokens, or hierarchical windows reduce cross-boundary errors on tasks requiring long-range coherence.
- Adaptive, content-aware compression: Compression ratio is fixed globally. Study per-span adaptive ratios driven by entropy/perplexity, saliency, or learned gating; quantify gains vs. overhead and propose train-time/inference-time policies.
- Theoretical guarantees: Provide information-theoretic or learning-theoretic analyses (e.g., lower bounds on retained mutual information, error bounds vs. compression ratio, recoverability conditions) to guide ratio selection and pooling design.
- Faithfulness and exact match: Beyond GSM8K, systematically measure exact string match on code diffs, citations, bibliographies, tabular extraction, and formal proofs to surface fidelity failures induced by compression.
- Safety and robustness: Assess whether compression alters refusal behavior, increases hallucinations/omissions, or enables adversarial prompts to bypass safety. Include red-teaming, jailbreak stress tests, and toxicity calibration under various ratios.
- Multi-turn and memory reuse: Empirically test chat scenarios where compressed context is reused across turns, including incremental appends without recompressing the full history, and measure drift/forgetting over long dialogues.
- Streaming/online compression: Explore low-latency, streaming encoders that operate at sub-window granularity; quantify lag vs. quality trade-offs for real-time applications.
- Agentic expansion policy learning: The EXPAND tool is used heuristically. Develop and evaluate budget-aware policies (supervised, bandit, or RL) for when/what to expand, termination criteria, and credit assignment under task constraints.
- Interplay with efficient attention/KV methods: Study hybrid systems that (i) compress inputs into latents, then (ii) apply KV cache compression or linear-attention during decoding; quantify cumulative gains and incompatibilities.
- Portability across base models and scales: Experiments center on Qwen3-4B with a 0.6B encoder. Evaluate across families (Llama/Mistral, Mixtral, DeepSeek) and sizes (7B–70B+) to derive scaling laws and sensitivity to decoder architecture/positional encoding.
- Encoder pretraining choices: Systematically compare encoder initializations (embedding vs. LM, causal vs. bidirectional) and pretraining domains (code, biomedical, legal) for domain-targeted LCLMs.
- Quantization-aware training: Investigate whether training the encoder/adapter/decoder under quantization constraints preserves accuracy while enabling practical 4–8 bit deployment.
- Energy and cost accounting: Provide training/inference cost and energy/carbon footprints, and conduct amortization analyses versus KV cache methods that have large one-time corpus-specific costs.
- Privacy and invertibility: Analyze whether latent tokens can be inverted to reconstruct sensitive content (model inversion/membership inference). Explore differentially private training or obfuscation for latent storage/caching.
- Compressing generated state: Extend compression to model-generated content (chain-of-thought, tool traces, working memory) and propose mechanisms for lifelong memory compression/garbage collection.
- Failure detection and introspection: Develop confidence or “compression risk” estimators that trigger selective expansion or fallback to uncompressed context; characterize calibration under compression.
- Structured prompting and tool schemas: Evaluate interactions of latents with function-calling schemas, XML/JSON protocols, and tool-augmented prompts where formatting strictness is critical.
- Positional encoding interactions: Clarify how latent token placement interacts with RoPE/NTK scaling and whether positional distortions affect long-range recall; test alternate placement or learned positional remapping.
- Security and poisoning: Study whether compressors can be poisoned (e.g., to hide toxic strings) or used to smuggle jailbreaks in latents; propose detection/mitigation strategies.
- Caching and reuse of latents: Explore deduplication and cross-session caching of compressed latents, cache invalidation when source documents change, and storage/compression of the latents themselves.
- Human evaluation: Complement automated benchmarks with human preference and fidelity ratings under compression, especially for long-form writing, reasoning chains, and code review.
Practical Applications
Immediate Applications
The paper introduces Latent Context LLMs (LCLMs) that compress long prompts into short sequences of learned embeddings (“soft tokens”) consumed by a standard decoder. This reduces time-to-first-token and peak memory while preserving task performance at 4×–16× compression. Below are concrete applications that can be deployed now or with light engineering.
- Long-context LLM serving cost and latency reduction
- Sectors: software (LLM platforms), cloud/AI infrastructure
- Workflow/product: Add an “LCLM preprocessor” in front of existing models (e.g., Qwen, Llama) to compress long prompts before prefill; deploy via HF Transformers today and target vLLM/SGLang for production. Expose a service API with compress() and decode() that preserves standard KV cache flows.
- Value: Lower GPU memory and latency for long prompts; extend usable context to 512K–1M tokens on commodity multi-GPU servers.
- Assumptions/dependencies:
- Inference stack must support soft-token/virtual-token inputs or allow overriding input embeddings.
- Quality retention depends on compression ratio and task; keep instruction tokens uncompressed as in the paper.
- Integration is easiest with open models (e.g., Qwen3-4B); closed models may need adapter re-training.
- Repository-scale code assistants with on-demand expansion
- Sectors: software engineering, developer tools
- Workflow/product: IDE extension that compresses an entire repo to latent context for code Q&A, refactoring, and debugging. Provide an EXPAND(chunk_id) tool to reveal exact code spans when needed (as in the paper’s agent).
- Value: Repo-wide reasoning without heavy indexing; strong “needle-in-a-haystack” recovery when expansion is used.
- Assumptions/dependencies:
- Chunking strategy (e.g., 512 tokens) and mapping from compressed chunks to source files must be maintained.
- Latent context should be regenerated on change or via incremental compression.
- For safety/accuracy, set a budget for expansions per turn to manage latency.
- Enterprise document QA and e-discovery over very long corpora
- Sectors: legal, compliance, enterprise search
- Workflow/product: Compress long contracts, email dumps, and discovery corpora into latent context; answer queries directly on compressed inputs; expand only relevant sections for exact citations.
- Value: Faster turnaround on large-corpus queries, improved recall on “hidden” details without relying solely on keyword search.
- Assumptions/dependencies:
- Storage of latent representations must be governed like original documents (they are lossy but can encode sensitive content).
- Accuracy for exact-phrase recall improves when expansion tool is used; set policies for expansion triggers.
- Long-horizon customer support and CRM chat history
- Sectors: customer support, sales
- Workflow/product: Maintain years of multi-turn history as compressed latent context per customer; keep the latest turns uncompressed; expand on demand when particular past interactions are referenced.
- Value: Persistent, low-latency memory across very long threads without blowing up context budgets.
- Assumptions/dependencies:
- Data retention/PII policies apply equally to latent representations.
- Robustness requires guardrails to prevent excessive expansions during live conversations.
- Clinical document and longitudinal patient record triage (research/controlled use)
- Sectors: healthcare
- Workflow/product: Compress longitudinal EHRs, discharge summaries, and notes into latent context for clinical Q&A or cohort triage. Expand precise segments (labs, meds, imaging summaries) when needed.
- Value: Scales reasoning over long patient histories with lower latency; leverages LongHealth-like tasks the paper evaluates.
- Assumptions/dependencies:
- Must run in HIPAA-compliant environments; human-in-the-loop for clinical use.
- Domain validation/finetuning may be required for specific EHR schemas and jargon.
- Financial and regulatory filings analysis at scale
- Sectors: finance, compliance, risk
- Workflow/product: Compress 10-Ks/10-Qs/MD&As, risk reports, and audit logs; perform risk queries and compliance checks; expand referenced sections for audit trails.
- Value: Reduces GPU memory and time for very long filings while preserving detailed retrieval when expanded.
- Assumptions/dependencies:
- Establish an expansion trace for auditability.
- Domain-specific evaluation (e.g., numeric consistency) may need additional prompts/validators.
- Security operations and observability log triage
- Sectors: cybersecurity, DevOps/SRE
- Workflow/product: Compress multi-million-line logs (auth events, network flow, traces) into latent context; issue anomaly or incident queries; expand suspect chunks for forensics.
- Value: Improves “needle-in-a-haystack” detection and speeds triage over large logs.
- Assumptions/dependencies:
- Log schemas vary; may benefit from light domain adaptation.
- Tooling must rate-limit expansions to stay within latency SLAs.
- Education and personal knowledge management (PKM)
- Sectors: education, productivity
- Workflow/product: Study assistants that ingest entire textbooks/course materials or personal note archives as latent context; expand specific sections during problem solving.
- Value: Skim large volumes quickly while retaining access to exact formulations or proofs.
- Assumptions/dependencies:
- Multilingual/discipline-specific content may require additional post-training.
- Interfaces should make expansion transparent to the user for trust.
- Literature review and scientific assistant
- Sectors: academia, R&D
- Workflow/product: Compress large paper corpora (PDF text/LaTeX) for cross-paper reasoning and hypothesis generation; expand relevant methods/appendices for exact detail.
- Value: Faster iteration across thousands of papers with access to exact equations or dataset descriptions when expanded.
- Assumptions/dependencies:
- Reliable parsing of PDFs/LaTeX into text before compression is required.
- Domain-heavy math may still benefit from targeted expansions.
- Latent-RAG pipelines (hybrid search + compressed skimming)
- Sectors: software, enterprise AI
- Workflow/product: First skim compressed latent context globally, then optionally perform vector/lexical search and expand top-k chunks; integrate with LangChain/LlamaIndex agents.
- Value: Reduces dependence on brittle keyword queries and improves coverage.
- Assumptions/dependencies:
- Storage layer for latent sequences per document; alignment between chunk IDs and indexes.
- Expansion budgets and caching policies need to be tuned per workload.
Long-Term Applications
These applications require further research, integration, or validation (e.g., larger-scale training, domain adaptation, or systems support for soft embeddings).
- Adaptive compression and expansion learned end-to-end
- Sectors: software, agent frameworks
- Product idea: Train LCLMs to dynamically allocate compression across the input (e.g., by information density/perplexity) and learn when to expand without hand-crafted tools.
- Dependencies/assumptions:
- Requires new objectives/feedback signals and scheduling to avoid catastrophic forgetting.
- Serving stacks must support dynamic expansion mid-session efficiently.
- Unified long-term agent memory (compressing generated state)
- Sectors: robotics, autonomy, enterprise agents
- Product idea: Compress chain-of-thought, tool outputs, and episodic histories into latent memory to support long-horizon planning and reasoning.
- Dependencies/assumptions:
- Safety concerns with compressed CoT storage; requires memory governance and retention policies.
- May require bi-directional integration with external knowledge stores.
- Cross-modal latent context (vision/audio/code AST/logs)
- Sectors: multimodal assistants, robotics, media
- Product idea: Extend LCLMs to compress images, video transcripts, sensor/robot logs, or program structure (ASTs) into shared latent context for multimodal reasoning.
- Dependencies/assumptions:
- New encoders and training data per modality; alignment with decoder embeddings.
- Benchmarks for long-horizon multimodal understanding.
- Edge and on-device long-context assistants
- Sectors: mobile, IoT, embedded
- Product idea: Run the small encoder locally to compress user context and transmit latents to a server-side decoder, reducing bandwidth and privacy exposure.
- Dependencies/assumptions:
- Efficient, quantized encoder and secure link between device and server.
- Privacy review to ensure latents don’t leak sensitive content.
- Health-system integration for clinical decision support
- Sectors: healthcare
- Product idea: EHR-native LCLM modules for longitudinal summarization, guideline compliance checks, and chart audits with auditable expand-on-demand traces.
- Dependencies/assumptions:
- Regulatory approvals, bias/robustness audits, and prospective clinical validation.
- Tight coupling with EHR vendors and standardized chunk mappings (labs, meds, notes).
- Financial “living memory” for compliance/audit
- Sectors: finance, insurance
- Product idea: Maintain compressed latent histories of communications, trades, and risk reports; provide auditors with selective expansions and provenance trails.
- Dependencies/assumptions:
- Strong governance for data lineage and immutability of latent stores.
- Performance audits on numeric fidelity and regulatory interpretations.
- Government-scale document analysis and archival search
- Sectors: public sector, policy
- Product idea: Compress FOIA archives and legislative records to enable broad skimming and precise expansion in policy analysis tools.
- Dependencies/assumptions:
- Procurement and security constraints; multilingual/format heterogeneity.
- Public transparency requirements on expansion traces and model behavior.
- KV cache + latent compression hybrids
- Sectors: LLM systems research, platforms
- Product idea: Combine LCLM for large-scale prompt compression with lightweight KV eviction during generation to push to tens of millions of tokens.
- Dependencies/assumptions:
- Specialized kernels or engine changes to realize end-to-end memory savings.
- Careful evaluation to avoid quality loss from stacking compressions.
- Domain-specialized compressors (code, math, legal, biomedical)
- Sectors: software, legal, healthcare, scientific computing
- Product idea: Train task/domain-specific encoders or pooling strategies (e.g., AST-aware, math-expression-aware) to improve high-ratio compression fidelity.
- Dependencies/assumptions:
- Curated domain datasets and evaluation suites.
- Compatibility with production decoders and inference stacks.
- Provenance-preserving and privacy-aware latent stores
- Sectors: compliance, privacy, data governance
- Product idea: Treat latent sequences as first-class records: encrypt at rest, apply retention/redaction policies, and log expansion events for audits.
- Dependencies/assumptions:
- Formal analyses of information leakage in latents; differential privacy or encryption-in-use may be needed.
- Organizational policy updates to reflect latent data handling.
- Training-time accelerations and curriculum for ultra-long contexts
- Sectors: model training infrastructure
- Product idea: Use LCLMs during pretraining to reduce effective context length costs (e.g., interleaving compressed/uncompressed spans as in the paper), enabling cheaper long-context pretraining.
- Dependencies/assumptions:
- Careful curriculum to avoid degrading base model capability.
- Tooling for mixed-format datasets at scale.
Notes on Feasibility and Dependencies
- Engine support: Although HF Transformers supports soft tokens, production engines (vLLM/SGLang) may need soft prompt/embedding injection paths for seamless deployment.
- Model coupling: The paper’s strongest results use a Qwen3-0.6B encoder with a Qwen3-4B decoder. For other decoders, you may need to re-train adapters or conduct end-to-end tuning.
- Data/domain coverage: General-purpose performance is strong, but specialized domains (e.g., legal, biomedical) may need SFT or reconstruction data aligned to their distributions.
- Security/Privacy: Latent representations can encode sensitive information; treat them as governed data with encryption and access controls.
- Expansion policy: Many high-stakes applications depend on robust criteria for when/how much to expand; implementing budgets, user-confirmed expansions, and audit trails is recommended.
- Multilingual and non-text robustness: Compression fidelity can vary across languages and formats (PDF, code syntax, LaTeX); pre-processing quality and domain-specific prompts matter.
These applications leverage the paper’s core advances—fast, memory-efficient context compression with minimal quality loss and an agentic “skim-then-expand” workflow—to unlock practical, real-world deployments today and enable new long-horizon systems over time.
Glossary
- Adapter: A projection module that maps encoder outputs to the decoder’s embedding dimension. "Stage 0: Adapter warmup."
- Agentic: Referring to systems that act as agents, orchestrating tools or steps over long horizons. "Agentic systems are commonly used to handle large amounts of information"
- Attention Matching: A KV cache compaction method that fits a smaller set of keys/values to match original attention behavior. "We use the official implementation for Attention Matching."
- Auxiliary reconstruction task: An additional training objective where the model reconstructs original text from compressed latents to preserve fine details. "we introduce an auxiliary reconstruction task."
- Bidirectional attention: An attention pattern where tokens can attend to both past and future tokens (non-causal). "The encoder can therefore use either causal or bidirectional attention"
- Causal masking: An attention mask that restricts each token to attend only to previous tokens. "we compare these two masking choices and find that causal masking consistently achieves lower pre-training loss."
- Compression ratio: The factor by which the input context is compressed into fewer latent tokens. "at compression ratios of 1:4, 1:8, and 1:16."
- Decoder prefill: The initial pass to build the KV cache over the prompt before generation. "Many methods still require the full context to be prefilled before compression"
- Encoder window size: The number of input tokens processed by the encoder per forward pass. "Let W denote the encoder window size, i.e., the number of input tokens processed by the encoder in one forward pass."
- Expected Attention: A pruning method that ranks keys by their expected attention under a distribution over future queries. "Expected Attention \citep{devoto2025expected} predicts KV importance by approximating future queries with a Gaussian distribution"
- KV cache: The stored keys and values from attention layers used to speed up autoregressive decoding. "the KV cache grows with context length."
- KV cache compression: Techniques that reduce KV cache size by removing less important entries. "KV cache compression methods reduce the memory footprint of cached activations by evicting cache entries"
- KVzip: A query-agnostic KV cache pruning approach that assigns importance via attention during reconstruction. "Compression methods such as KVzip allocate eviction budgets non-uniformly across attention heads and layers"
- Latent Context LLMs (LCLMs): Encoder–decoder compressors that map long inputs to shorter latent sequences for the decoder. "We introduce Latent Context LLMs (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage."
- Latent tokens: Continuous embeddings produced by the encoder that represent compressed chunks of the input. "We concatenate the latent tokens from all encoder windows to obtain the full compressed latent sequence"
- LoRA: A parameter-efficient fine-tuning technique using low-rank adapters. "or use LoRA \citep{e2llm, GMSA, mean-pooling}, but we find them to substantially underperform compared to full-parameter training in early experiments"
- Mean pooling: A pooling operator that averages encoder hidden states within each compression block. "Mean pooling averages encoder hidden states over each block of N input tokens"
- MLP adapter: An adapter implemented as a lightweight multilayer perceptron used to project encoder latents to the decoder space. "the MLP-only adapter achieves lower pre-training loss"
- Needle-in-a-haystack (NIAH): Retrieval-style tasks that require finding specific details buried in long contexts. "We use the needle-in-a-haystack tasks from RULER as a testbed"
- Paged-attention engines: Inference systems that manage KV memory in pages to improve throughput and memory efficiency. "forfeiting the memory and throughput benefits of these paged-attention engines."
- Pareto frontier: The set of methods that optimally trade off accuracy versus efficiency (e.g., speed/memory). "Latent Context LLMs establish a new Pareto frontier on long-context benchmarks in terms of time to first token."
- Pooling operator: A function that aggregates a block of encoder hidden states into one latent representation. "A pooling operator then aggregates these hidden states into M_i = \left\lceil \frac{|w_i|}{N} \right\rceil latent tokens"
- Prefix-LM: A modeling setup where a prefix can be bidirectionally encoded and then used to condition autoregressive decoding. "as in prefix-LMs~\citep{raffel2020exploring}"
- Query-agnostic methods: Compression approaches that operate without knowledge of the specific downstream query. "Query-agnostic methods, such as KVzip and FastKVzip, compress a cache without access to the downstream query"
- Query-aware methods: Compression approaches that use the specific query to guide what context to keep. "Query-aware methods, such as SnapKV, are designed to compress a context given a known query"
- Self-study: A strategy that uses synthetic queries generated from the context itself to guide compression. "Self-study, as introduced by \citet{cartridges}, performs compression using synthetic queries to expand coverage over potential inference-time queries."
- SGLang: An optimized inference engine for serving LLMs. "inference engines such as vLLM \citep{kwon2023efficient} or SGLang \citep{zheng2024sglang}"
- Soft-token compression: Methods that replace long token sequences with shorter sequences of learned continuous embeddings. "soft-token methods rely on offline preprocessing and do not convincingly preserve the base model's broad in-context behavior."
- Supervised fine-tuning (SFT): Post-training with labeled instruction-following or task data to improve capabilities. "we further post-train the model with supervised fine-tuning"
- Time to first token (TTFT): The latency until the model emits its first generated token. "We define compression time as time-to-first-token (TTFT), i.e., the time required for a method to reach the point at which it can generate the first token."
- vLLM: A high-throughput inference engine for LLMs with paged attention. "inference engines such as vLLM \citep{kwon2023efficient} or SGLang \citep{zheng2024sglang}"
Collections
Sign up for free to add this paper to one or more collections.

