- The paper presents a unified multi-agent framework that decomposes video editing into shot planning, semantic retrieval, and fine-grained trimming.
- It employs a graph-based orchestration using iterative textual gradient descent to dynamically optimize multi-modal editing pipelines.
- Experimental results show 87-95% orchestration success and 60% cost savings, achieving near-human quality in automated video production.
VideoAgent: A Unified Multi-Agent Framework for Automated Video Understanding and Editing
Introduction and Motivation
Automated video creation systems have consistently lagged behind the emergent demands of digital media workflows, primarily due to insufficient long-form comprehension and limited support for complex, multi-modal editing operations. The VideoAgent framework (2606.23327) directly addresses these deficiencies by introducing a highly modular, agentic architecture capable of end-to-end video understanding, shot planning, semantic retrieval, and compositional editing—scaling beyond short-form or domain-constrained automation.
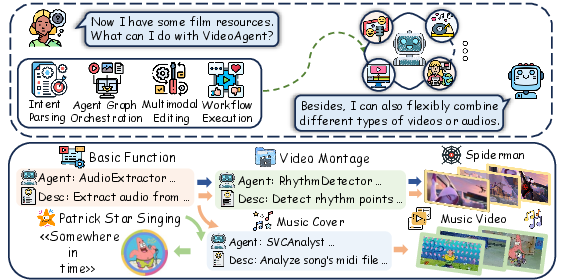
Figure 1: Automated video editing with VideoAgent.
By uniting over thirty domain-specialized agents into a graph-optimized orchestration framework, VideoAgent demonstrates robust generalization for arbitrary production requirements. The system’s global-aware shot planning, cross-modal retrieval, and fine-grained control position it as a practical tool for video montage, rhythm-synced cuts, storytelling, meme adaptation, and more—all orchestrated through natural language instructions.
System Architecture and Technical Innovations
Automated Shot Planning and Visual Content Retrieval
VideoAgent’s core innovation is the hierarchical decomposition of editing instructions into shot-level narrative planning, followed by semantically aligned retrieval and subshot extraction. The shot planning agent leverages LLM-driven prompts and global context compression—built from content captions of all resource segments—to construct storyboarded sequences matching the user’s creative intent and available footage.

Figure 2: Automated video shot creation with shot planning, video retrieval and trimming.
Subsequently, cross-modal retrieval employs embedding-level alignment via ImageBind/CLIP to match shot descriptions to segment keyframes, maximizing both semantic consistency and retrieval efficiency. The fine-grained video trimming step further corrects temporal discrepancies, leveraging a VLM to select optimal sub-segments in accordance with narrative tempo and dialogue constraints.
Multi-Agent Graph Orchestration
To generalize across multi-modal editing tasks, VideoAgent structures its editing pipeline as a directed acyclic agent graph. The agent library encompasses basic preprocessing (audio extraction, normalization, beat detection), advanced manipulation (face swapping, lip sync, style transfer), and specialized creative logic (script adaptations, rhythm-aware montage, meme synthesis, etc.). All agents are dynamically selected and composed based on natural language intent parsing.
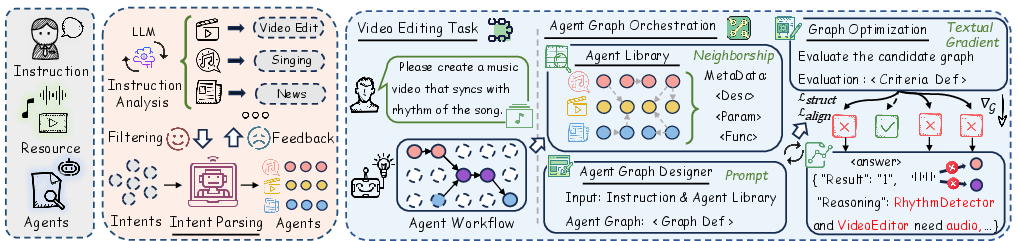
Figure 3: Video editing with agent graph orchestration and execution.
Unlike heuristic, single-pass orchestrators, VideoAgent optimizes the agent graph via iterative “textual gradient descent.” Here, the LLM receives a structured quality signal—enforcing acyclicity, connectivity, and intent coverage—and updates the graph via natural language-specified topology transformations. The process converges when both structural and semantic alignment objectives are satisfied.
Experimental Evaluation
Quantitative Benchmarks
VideoAgent outperforms a wide range of baselines across workflow orchestration, video retrieval, and segment alignment metrics, including specialized VLMs (Qwen2.5-VL, VideoMind), RAG-based multi-modal models, and agentic systems (GPTSwarm, GraphCounselor). On the VideoEdit and Shot2Story datasets, VideoAgent achieves orchestration success rates of 87-95%, often exceeding existing systems by 2–25% and delivering Recall@1 improvements of up to 18% over top commercial backbones.
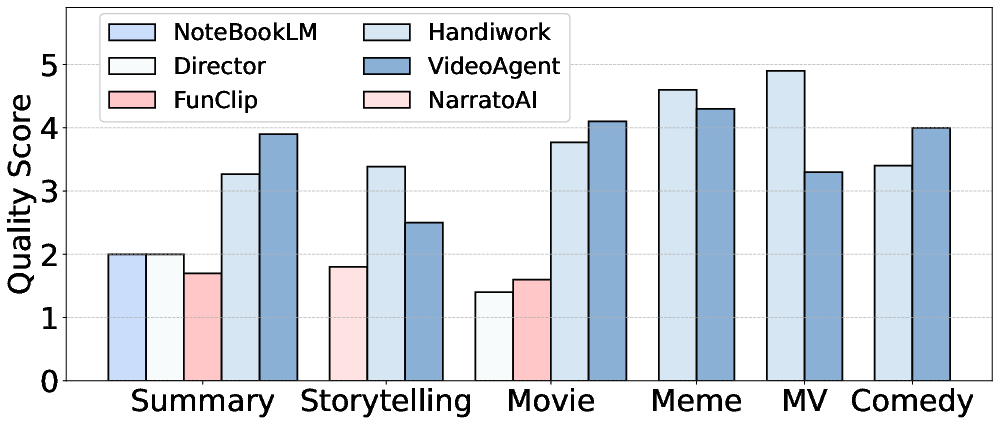
Figure 4: Human-rated video quality assessment.
Critically, API costs are reduced by approximately 60%, attributable to the system’s early intent filtering and targeted subsegment inference, which contrast with the excessive token/context usage of “brute-force” multimodal LLM workflows.
Human Evaluations
In extensive human evaluation (26 participants, 49 video demos), VideoAgent maintains consistency, scene diversity, and audio quality ratings within 4% of professional human-crafted outputs—often surpassing baseline agents in reliability and production fitness.
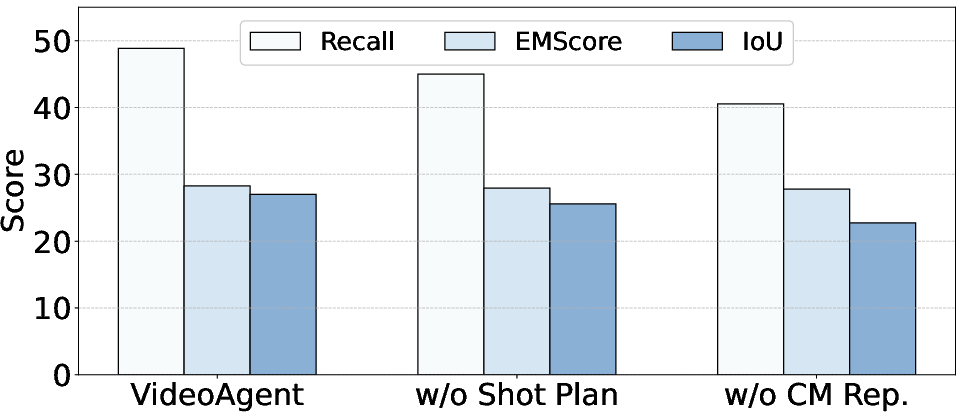
Figure 5: VideoAgent ablation study results.
Ablation studies reveal that global-aware shot planning and gradient-driven graph optimization each provide major performance boosts; removal of either step degrades both success rates and qualitative metrics by substantial margins.
Generalization and Case Studies
On additional benchmarks such as VideoRepurpose and a variety of real-world scenarios (e.g., rhythm-synced montage, meme edits, cross-lingual adaptations), VideoAgent retains high retrieval and orchestration accuracy, validating the modularity and agentic scalability of its architectural design.
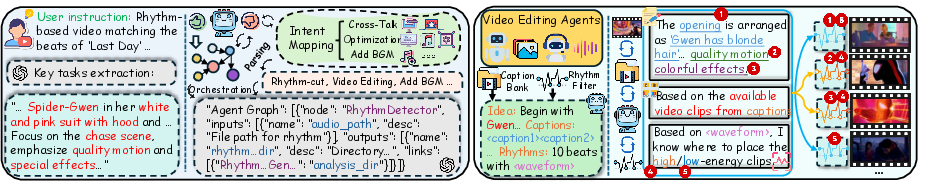
Figure 6: Case study: Creating a rhythm-synced Spiderman movie montage with VideoAgent.
Practical and Theoretical Implications
Practically, VideoAgent offers significant reductions in both labor and cost for mass video post-production, live event summarization, and derivative content creation. Its flexible agent library and compositional pipeline enable direct application to beat-edited clips, AI-dub meme videos, cross-modal remixes, and domain-specific adaptations (e.g., stand-up, crosstalk narratives). The modular orchestration logic facilitates the integration of new generative agents (e.g., for data augmentation) and enables workflow refinement aligned with evolving editing conventions.
Theoretically, the textual-gradient graph optimization approach demonstrates that natural language can effectively guide symbolic search over combinatorial action spaces, with convergence grounded in explicit workflow correctness signals. This presents generalizable methods for graph-based agent coordination in other domains characterized by multi-stage, multi-modal tool use (e.g., scientific data pipelines, multi-agent simulation environments, or interactive storytelling systems).
Limitations and Future Work
While VideoAgent establishes a scalable, retrieval-centric paradigm, its performance is bounded by the diversity and quality of available source footage. Integration with generative video synthesis models could mitigate such constraints. Additionally, the power of automated editing demands ethical oversight—particularly to prevent the potential misuse of highly realistic content for misinformation or deepfake applications. Future work must focus on robust moderation frameworks and context-aware content validation.
Conclusion
VideoAgent represents a comprehensive leap in practical, editable video AI, bridging the usability and scope gaps of current multimodal agentic approaches. Through a unified framework that solves shot-level narrative planning, content retrieval, and graph-based compositional editing, it sets the technical foundation for next-generation automated media creation pipelines. The ability to combine robust quantitative gains with competitive human-level output quality demonstrates the viability of VLM-driven, multi-agent graph orchestration as a standard architecture for complex multimodal workflows.
