- The paper demonstrates that focusing on incorrect student-generated outputs enhances reasoning performance, achieving up to 8.90% gains on benchmarks.
- The methodology employs pivotal token selection and log-ratio normalization to emphasize key student-teacher disagreements during prefix-based training.
- Empirical results reveal that negative trajectory emphasis reduces training cost while promoting exploratory and self-reflective reasoning.
Essay on "ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation"
Motivation and Empirical Findings
This work addresses on-policy distillation (OPD) for post-training LLMs on reasoning-centric tasks. While OPD offers advantages in token-level supervision density and efficient prefix-based training compared to Reinforcement Learning (RL), conventionally it applies uniform weighting to all student-generated outputs (SGOs). Through controlled filtering experiments, the authors discover a consistent asymmetry: models trained exclusively on incorrect SGOs outperform those trained solely on correct ones, for both OPD and on-policy self-distillation (OPSD). Incorrect-only training yields significant gains (e.g., +3.60 on AIME24 under OPD; see Figure 1).
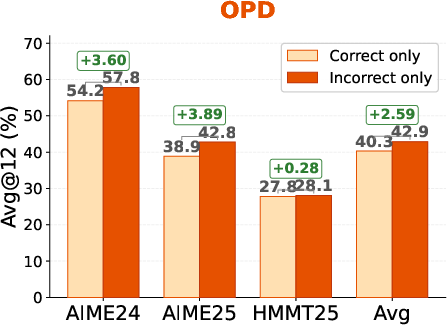
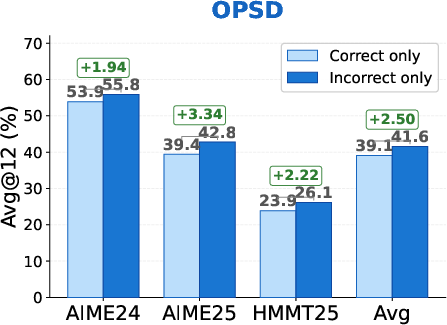
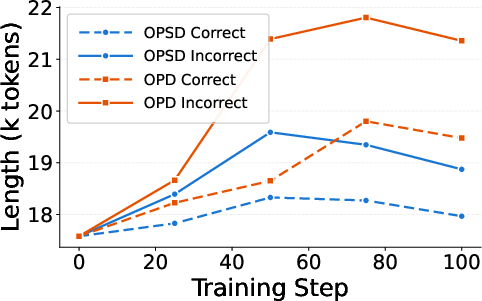
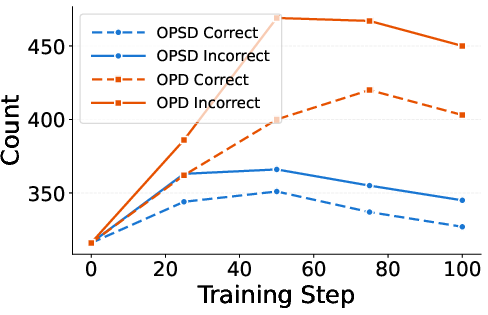
Figure 1: Correct-only vs. incorrect-only training under OPD. Incorrect-only supervision consistently outperforms correct-only supervision in mathematical reasoning benchmarks.
Additional behavioral metrics reveal that incorrect-only training induces longer response traces and increased epistemic marker counts, indicative of enhanced exploratory and self-reflective reasoning. This suggests that negative trajectories supply rich correction signals and preserve cautious reasoning near the student’s capability boundary. Theoretical implications include a departure from the intuition that correct SGOs are optimally informative for distillation, and a practical need to exploit negative trajectories without requiring full final-answer rollouts.
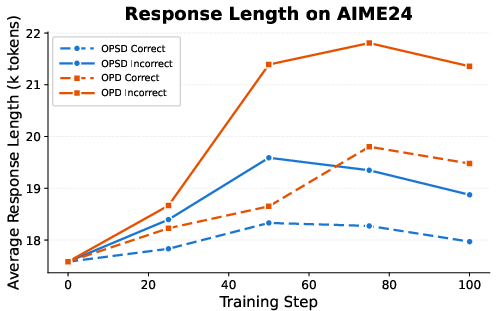
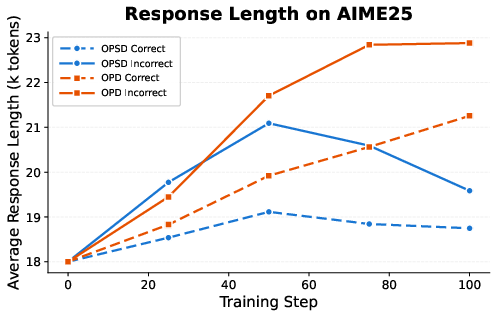
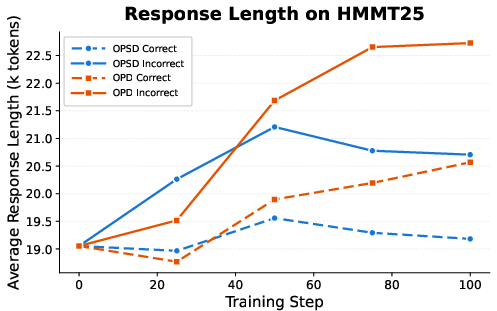
Figure 2: Average response length for correct vs. incorrect on-policy trajectories; incorrect trajectories consistently exhibit longer reasoning traces across multiple benchmarks.
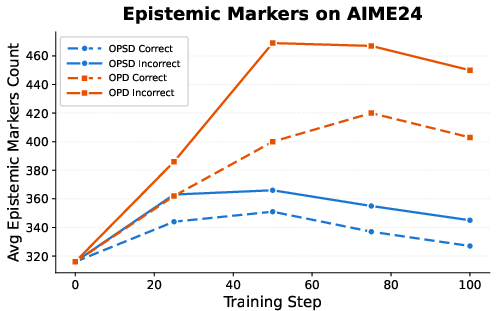
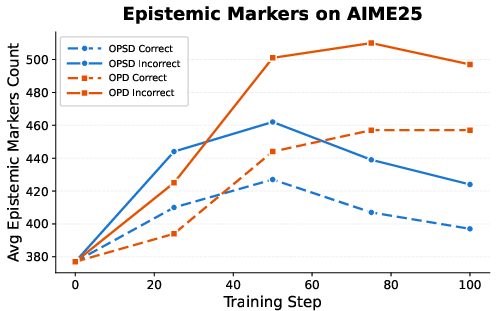
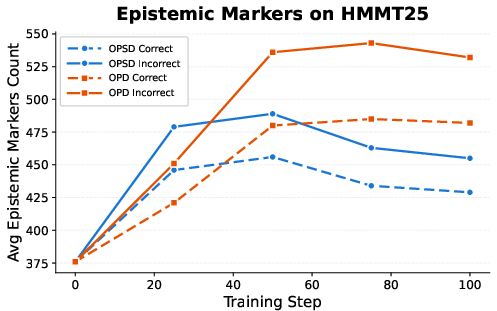
Figure 3: Epistemic marker counts for correct vs. incorrect on-policy trajectories, demonstrating increased self-reflection in incorrect trajectories.
Methodology: The ReNIO Pipeline
ReNIO (Reweighting Negative trajectory Importance for On-policy distillation) is proposed to emphasize likely negative, high-information trajectories while retaining OPD’s efficiency. Core design elements:
- Prefix-conditioned Student-to-Teacher Probability Ratio: For each token yt in y, define rt=πT(yt∣x,y<t)πS(yt∣x,y<t), with log-ratio ℓt=logrt. Tokens with a high rt indicate student-preferred, teacher-rejected branching decisions, which are critical for localizing reasoning errors.
- Fixed-Threshold Pivotal Token Selection: Employ a threshold τ to identify pivotal tokens where ℓt>τ, discarding low-disagreement tokens and focusing on salient student-teacher divergences.
- Geometric Mean Aggregation and Batch Normalization: Aggregate selected pivotal token ratios per SGO into a geometric mean, normalize within each batch to stabilize update magnitudes.
This pipeline constructs a sample-level weight w^(x,y), which modulates the standard OPD objective, redistributing learning emphasis to trajectories exhibiting substantial student-teacher disagreement. The methodology is computationally efficient as it leverages prefix-conditioned probabilities and circumvents final-answer supervision.
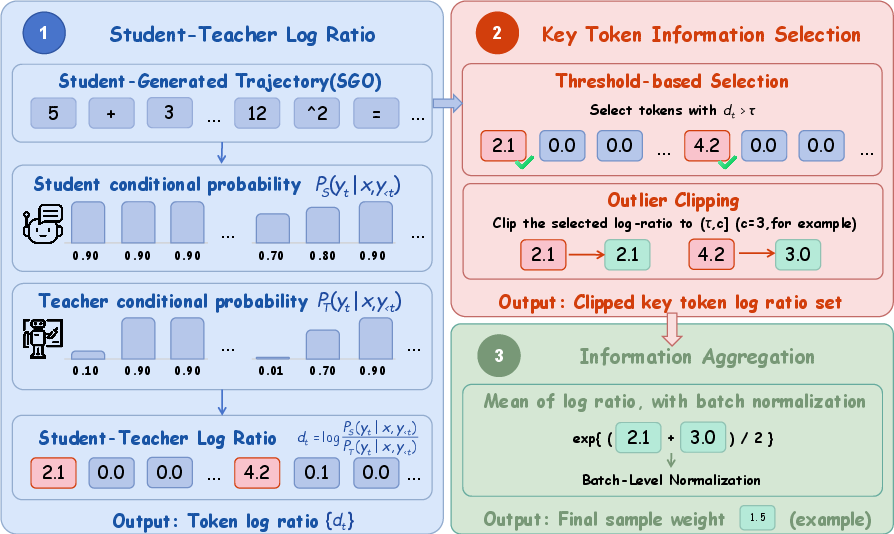

Figure 4: Overall pipeline of ReNIO highlighting log-ratio computation, pivotal token selection, and weight aggregation.
Empirical Results and Analysis
ReNIO is evaluated across mathematical reasoning (AIME24/25, HMMT25) and code-generation benchmarks (HumanEval+, MBPP+) using Qwen3 and DeepSeek-R1-Distill-Qwen model families. Across both teacher-based OPD and teacher-free OPSD, ReNIO consistently yields significant average performance improvements— for instance, up to 8.90% relative gain for Qwen3-1.7B on math tasks and yt0 for R1-Distill-Qwen-7B on AIME25.
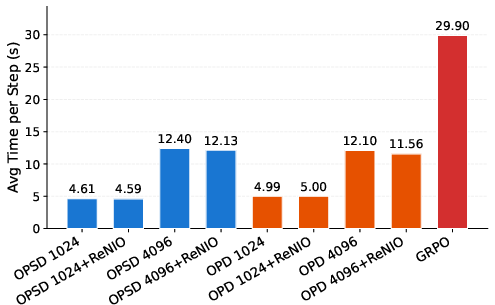
Figure 5: Training-time comparison demonstrates OPD’s efficiency advantage over RL-based GRPO, especially with truncated prefixes.
Notably, ReNIO retains OPD’s core efficiency proposition by enabling "short SGO" prefix training. Performance with 1024-token prefixes often matches or surpasses 4096-token rollouts, while offering substantial reductions in training cost and computational resources.
Ablation studies validate the necessity of pivotal token selection, log-ratio clipping, and batch normalization for optimal sample weighting and stable training. Removing batch-wise normalization, for example, results in marked performance degradation. Hyperparameter analysis further supports moderate threshold and clipping values to balance the amplification of informative disagreements and numeric stability.
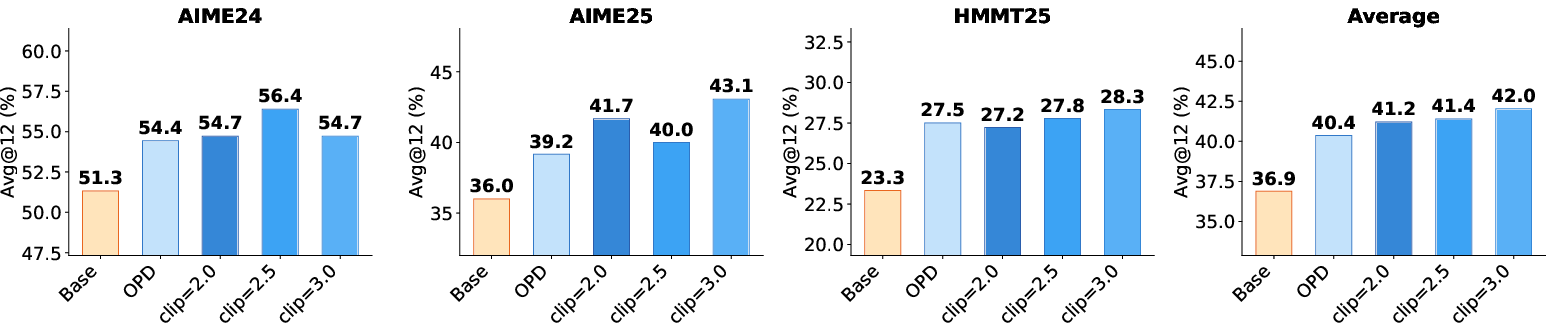
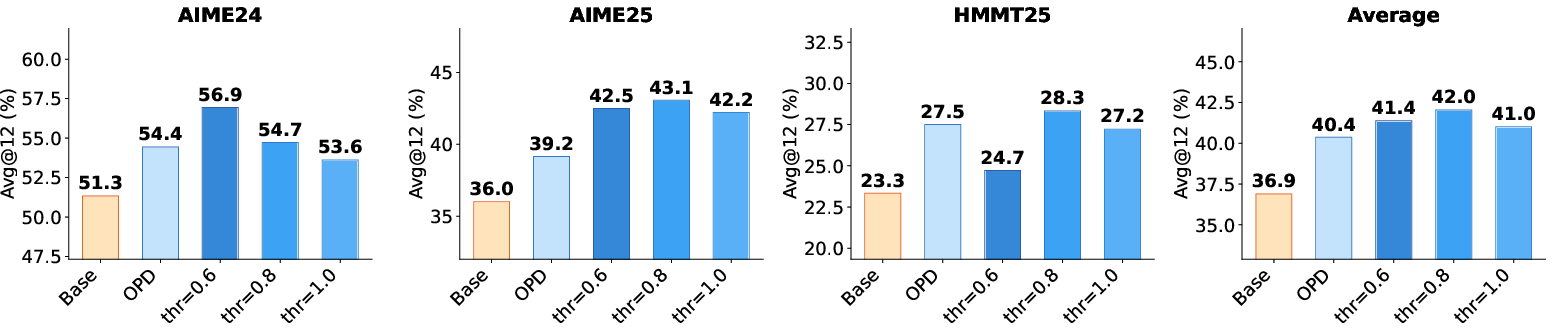
Figure 6: Effect of the clipping bound on OPD. Threshold fixed to 0.8, illustrating the importance of controlling outlier token ratios.
Theoretical and Practical Implications
- Process-level Correction: The findings indicate that negative SGOs capture valuable process-level correction signals, not only the final-answer correctness. This undermines uniform weighting strategies and supports principled sample selection.
- Efficient, Flexible Distillation: By leveraging prefix-conditioned information, ReNIO enables efficient distillation without expensive reward labeling or full-trajectory generation, aligning with the growing requirements for scalable LLM post-training.
- Exploration vs. Confidence: Longer responses and increased epistemic markers signal enhanced exploration and less overconfidence, a desirable property in robust reasoners.
- Compatibility with Both OPD and OPSD: ReNIO is agnostic to teacher-based or self-distillation, suggesting broad applicability within the on-policy distillation framework.
Qualitative analysis further confirms that models trained with ReNIO are able to preserve the full solution process, including symmetry handling and overlap correction, leading to more accurate and robust mathematical reasoning.
Limitations and Future Directions
Limitations include restricted validation on massive-scale LLMs due to computational constraints. Future directions may focus on integrating ReNIO with curriculum-based distillation, extending pivotal token identification to multi-step reasoning tasks, and exploring cross-domain generalization. Theoretical analysis of the asymmetry in negative SGO effectiveness and its interplay with model uncertainty remains a promising avenue.
Conclusion
ReNIO concretely establishes the utility of negative trajectory emphasis in OPD for LLM reasoning. The sample-level reweighting mechanism is theoretically sound, computationally efficient, and empirically validated across both mathematical and code-generation tasks. By presciently exploiting prefix-conditioned student-teacher disagreement signals, ReNIO preserves OPD's efficiency regime and achieves measurable performance gains, providing a scalable recipe for post-training reasoning enhancement in modern LLMs (2606.23104).

