RLCSD: Reinforcement Learning with Contrastive On-Policy Self-Distillation
Abstract: On-policy self-distillation (OPSD) provides dense, token-level supervision for reasoning models by aligning a model's own distribution with the distribution it produces under privileged context, typically a verified solution. However, we show that the learning signal drawn from this distributional gap concentrates on style tokens rather than task-bearing ones, as the hinted model tends to produce more direct, shorter outputs. We term this pathology \emph{privilege-induced style drift}, which destabilizes training or causes response length to shrink. To address this, we propose \textbf{RLCSD} (Reinforcement Learning with Contrastive on-policy Self-Distillation), which mitigates this drift by contrasting the teacher-student gap under a correct hint against that under a wrong hint, suppressing the style shift that conditioning on a hint tends to induce regardless of correctness, and yielding a signal that is more concentrated on task-bearing tokens. Experiments on Qwen3 (1.7B/4B/8B) and Olmo-3-7B-Think across mathematical and logical reasoning show that RLCSD consistently outperforms GRPO and prior OPSD methods. We further show that the contrastive principle is general: it plugs into existing OPSD methods to improve them, and its underlying insight extends to the broader cross-model on-policy distillation setting.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces a new way to train “thinking” AI models (the kind that write out their steps when solving math or logic problems). The method is called RLCSD, which stands for Reinforcement Learning with Contrastive On-Policy Self-Distillation. In simple terms, it helps a model teach itself better by comparing how it behaves when it’s shown a correct solution versus when it’s shown a wrong one—and using the differences to learn what truly matters for getting the right answer.
The problem the authors noticed
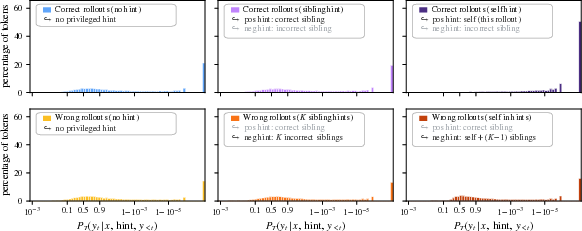
Many training methods let a model peek at a “hint” (like a correct worked solution) and learn to imitate its behavior, word by word. This sounds great, but the authors found a hidden problem: when the model sees a hint, it tends to change its writing style more than its actual reasoning. For example, it becomes more confident, uses shorter sentences, and picks certain “style” words like “Therefore” or “Thus,” even when those don’t help solve the problem.
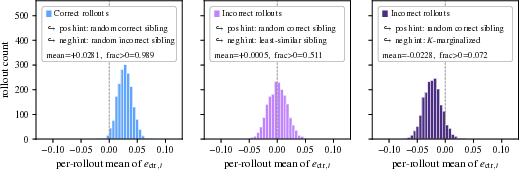
The authors call this issue privilege-induced style drift. “Privilege” means the teacher sees a special hint the student doesn’t. “Style drift” means the model’s tone and formatting change, even if the hint is wrong. This distracts the model from learning the important parts—the tokens (words/symbols) that actually carry the math or logic needed to be correct.
Goals and key questions
The paper aims to answer these questions in an easy-to-understand way:
- How can we give the model detailed, word-by-word feedback that focuses on real problem-solving, not just fancy phrasing?
- Can comparing a correct hint with a wrong hint remove the “style” noise and highlight the truly useful parts?
- Can this idea make training more stable (no weird behavior like super-long or super-short answers) and improve results across math and logic tasks?
How the method works (with simple analogies)
Think of training the model like training a student to solve math problems:
- Old approach: Show the student a correct worked solution (the hint) and make them match their writing to it, word by word. The problem is the student might copy the “style” (short, confident) rather than the math thinking.
- RLCSD’s idea: Play “spot the difference” with two hints—one correct and one wrong—both shown in the same template. Because both hints are wrapped the same way, any shared style (shortness, confident phrasing) cancels out. What’s left are the differences tied to correctness—like the numbers, operations, and key steps that actually decide the answer.
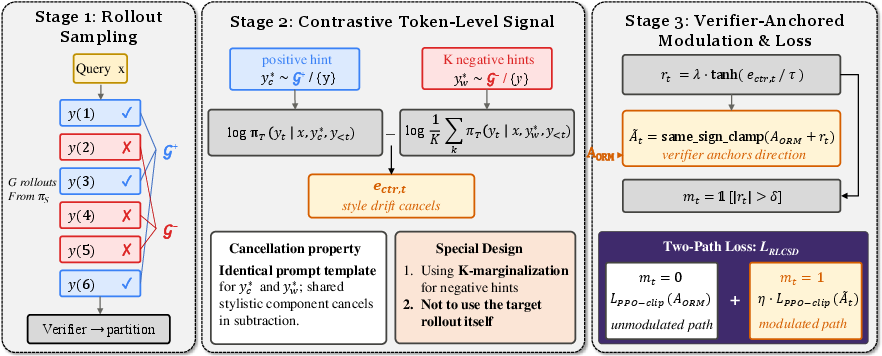
Here’s the approach in three simple stages:
- Sample answers from the model itself: For each question, the model produces several answers. A checker (verifier) marks each one as correct or incorrect.
- Build a contrast signal:
- Pick one correct hint and a few wrong hints from these model answers.
- Show each hint to the “teacher version” of the model using the exact same prompt format.
- Compare how much the teacher supports each word in the student’s current answer when using the correct hint versus the wrong hint.
- Subtract the two. This subtraction removes shared “style” and keeps the correctness-focused signal.
- Combine with outcome feedback:
- Keep using a simple score for whether the whole final answer is right or wrong (this keeps the model pointed in the right direction).
- Use the contrast signal to gently boost or reduce the learning strength on specific words that matter, without flipping the overall direction of learning.
Everyday analogy:
- Imagine you’re learning to solve a puzzle. If you only copy a polished solution, you might learn to write neat answers rather than how to solve it.
- If you compare a good explanation with a bad one that looks the same on the surface, you can notice which specific steps actually lead to the right result. That’s what the model learns to focus on.
Important design choices explained simply:
- Multiple wrong hints: Using several wrong hints averages out random mistakes, making the comparison more reliable.
- Don’t let the model “hint” itself with its own answer: That would make the teacher too confident and less informative.
- Keep the final answer score in charge: The “right or wrong” outcome still decides the overall direction. The word-level contrast only adjusts how strongly to update on certain words.
What they found and why it matters
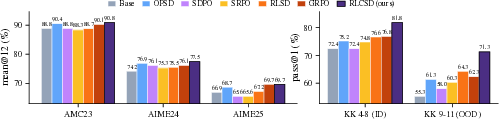
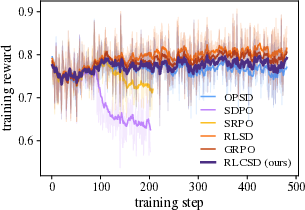
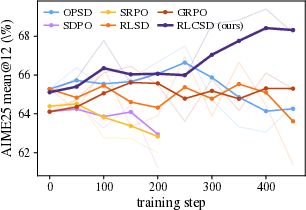
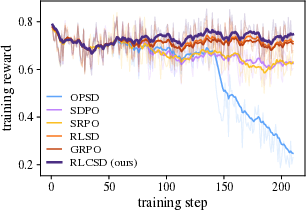
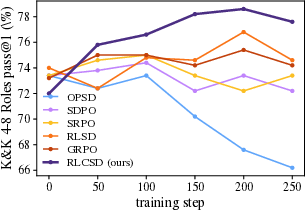
Main results across multiple models and tasks:
- The method was tested on math contests (like AMC and AIME) and a logic puzzle set (Knights and Knaves).
- It consistently beat standard reinforcement learning methods (like GRPO) and several popular self-distillation methods.
- It avoided two common training problems seen in other methods:
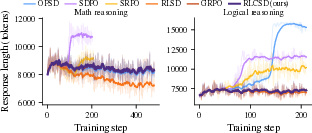
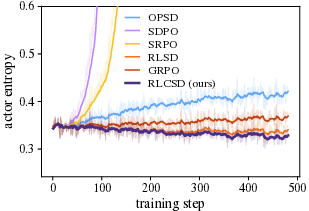
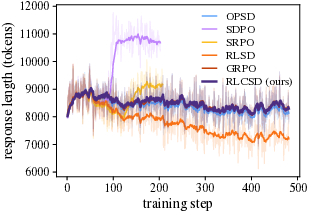
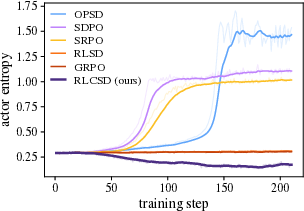
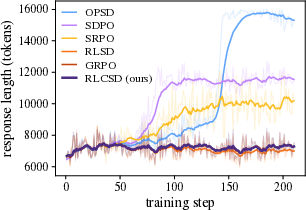
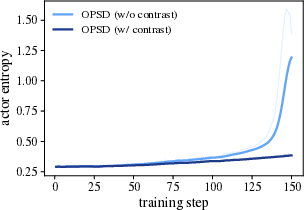
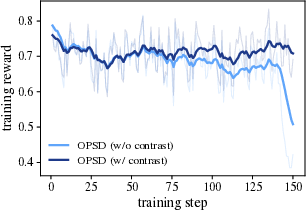
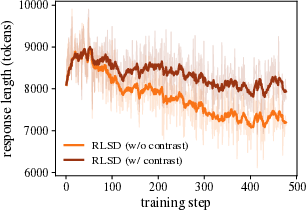
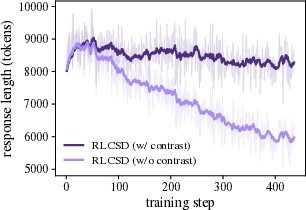
- Training instability and “entropy explosion” (the model becomes chaotic and outputs very long, messy answers).
- Premature answer shortening (the model learns to write too little, too soon, and loses problem-solving richness).
Why this is important:
- Better focus: The model learns to pay attention to the parts that decide correctness (numbers, math operations, logical steps), not filler words.
- More stable training: It keeps a healthy answer length and doesn’t collapse or go off the rails.
- Practical and efficient: It doesn’t need a separate, bigger “teacher” model. The model teaches itself using its own correct and wrong attempts, which saves memory and time.
- Generalizable: The contrast idea can also improve other self-distillation methods. It’s a plug-in principle, not just a single algorithm.
What this could change going forward
- Stronger reasoning AIs: Models can learn real problem-solving skills instead of just copying a confident style.
- Cheaper training pipelines: Because the same model acts as both student and teacher, it’s easier to scale without expensive external teachers.
- Better generalization: The method improves performance even on harder, out-of-distribution logic puzzles, suggesting it learns deeper thinking patterns.
- Broad usefulness: The “contrast” trick—comparing correct and wrong hints—could help in many learning systems where style and content get mixed up.
In short
RLCSD helps AI models learn to think by comparing how helpful correct and wrong hints are, canceling out superficial style, and zeroing in on the words and steps that really lead to correct answers. It trains more stably, works across math and logic, and can make future reasoning models both smarter and easier to train.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that are either missing, uncertain, or left unexplored in the paper. Each item is phrased to enable concrete follow-up work.
- Theoretical guarantees for contrastive cancellation:
- No formal analysis of when identical prompt templates guarantee suppression of “privilege-induced style drift,” nor sufficient conditions on hint distributions for to concentrate on correctness-bearing tokens.
- Absence of bias–variance analysis of the contrastive gradient estimator and its convergence properties when combined with group-normalized advantages.
- Sensitivity to prompt-template design:
- The method assumes that byte-for-byte identical templates cancel style; the robustness to small formatting changes, different instruction styles, or multilingual templates is not assessed.
- The practice of labeling both correct and incorrect references as “Correct final answer” is untested for side effects (e.g., learned brittleness, truthfulness degradation).
- Dependence on group composition and data efficiency:
- Groups with only correct or only incorrect rollouts are discarded; the proportion of discarded groups and its impact on sample efficiency, especially in early (low-accuracy) or late (high-accuracy) training, is unreported.
- No strategy is provided for regimes where positives (or negatives) are scarce (e.g., curriculum design, cross-batch hint pooling, or synthetic negatives).
- Compute and throughput overhead:
- Contrastive training requires multiple teacher forward passes per token (positive + K negatives); the added wall-clock cost, memory footprint, and throughput versus GRPO and other OPSD baselines are not quantified or equalized.
- Lack of compute-normalized comparisons (e.g., matching FLOPs or time) leaves unclear how much of the gains stem from additional compute.
- Aggregation over negatives:
- The choice to use log of the arithmetic mean of negative probabilities, i.e., , lacks theoretical justification versus alternatives (e.g., average of log-probs, log-sum-exp with temperature, median, or importance weighting).
- Sensitivity to K (number of negatives) and the trade-off between stability and compute cost is not explored.
- Hyperparameter robustness:
- No systematic sensitivity analysis for , , , , K, group size G, or teacher refresh frequency; it is unknown how brittle performance and stability are to these choices across tasks and scales.
- Masking strategy and gradient allocation:
- The fixed threshold gates 70–80% of tokens; the impact on credit assignment, potential gradient starvation for unmasked tokens, and whether adaptive or learned thresholds perform better are untested.
- Independent normalization of modulated/unmodulated paths may bias gradient magnitudes; no analysis quantifies this effect or compares to alternative weighting schemes.
- Interaction with outcome-level advantage:
- The sign-preserving clamp prevents from reversing , but this may be suboptimal when the verifier is noisy or group-normalization assigns counterintuitive signs; no study on failure cases or alternative arbitration rules.
- Generalization beyond math and synthetic logic:
- Applicability to coding, scientific QA, long-form reasoning, multi-hop retrieval, or dialogue planning is untested.
- No evaluation on multilingual tasks, despite tokenization and style-drifts likely differing by language.
- Verifier assumptions and non-binary rewards:
- The method assumes noise-free binary verifiers; robustness to imperfect verifiers, partial credit, or continuous/structured rewards remains open.
- Extension to stepwise/segment-level verifiers (credit assignment at intermediate steps) is not investigated.
- Stability and exploration dynamics:
- While curves show improved entropy/length behavior, there is no quantitative analysis of exploration–exploitation trade-offs or long-horizon credit propagation beyond the reported tasks.
- Negative-hint source and diversity:
- Negatives come only from in-group student errors; this may narrow the contrast to the model’s current error modes, risking myopic improvements. Using external or adversarial negatives is unexplored.
- Potential benefits of reusing historical negatives (replay) or cross-query negatives are untested.
- Teacher snapshot cadence:
- The impact of the teacher refresh interval (every 10 steps) on stability and performance, and its interaction with non-stationarity, is not ablated.
- Comparison with dense-logit contrastive variants:
- The paper adopts sampled-token signals; whether a dense-logit contrastive OPSD (and its compute/performance trade-offs) performs better is not studied.
- Cross-model applicability:
- The claim that the contrastive principle extends to broader cross-model OPD is not empirically demonstrated; performance when teacher and student differ in architecture, vocabulary, or size remains unknown.
- Safety, truthfulness, and style effects at inference:
- Training exposes the model to wrong answers framed as “correct”; potential downstream effects on assertiveness, hedging, and hallucination rates at inference are not measured.
- No human or automatic evaluations of explanation faithfulness or calibration are reported.
- Token “style vs task” analysis generality:
- The vocabulary partition used to diagnose style drift is math-specific and handcrafted; general, task-agnostic measures (e.g., mutual information with correctness, learned token influence) are not provided.
- Handling extremely long contexts:
- The memory and stability implications of contrastive hints in very long sequences (e.g., multi-document contexts) are unreported.
- Statistical reliability:
- Results are shown without confidence intervals or multi-seed variance; reproducibility and statistical significance of improvements are not established.
- Late-training regimes:
- When accuracy is high and negatives are rare, how to maintain learning signal and avoid plateauing is not addressed.
- Integration with other RL algorithms:
- The approach is evaluated only with GRPO; performance with critic-based PPO, value baselines, or off-policy methods remains open.
- Deployment-time implications:
- While training-time length stability is shown, inference-time latency, response lengths, and throughput under production constraints are not analyzed.
- Data and domain coverage:
- The logic benchmark is synthetic (Knights and Knaves); transfer to more naturalistic logical reasoning tasks (e.g., natural language inference, planning benchmarks) is not tested.
- Potential for positive–negative hint collisions:
- Cases where the negative hint is superficially similar to the positive (near-miss errors) or where both hints share the same stylistic artifacts may weaken contrast; strategies to detect or mitigate this are not described.
Practical Applications
Overview
The paper introduces RLCSD, a training algorithm that combines reinforcement learning with verifiable rewards (e.g., GRPO) and a contrastive on‑policy self‑distillation signal. By contrasting a model’s token‑level behavior when conditioned on a correct versus an incorrect hint under identical templates, RLCSD suppresses “privilege‑induced style drift” and shifts credit assignment toward task‑bearing tokens. Empirically, it improves reasoning accuracy and training stability (avoiding entropy/length explosions or premature shortening) on math and logic benchmarks across 1.7B–8B models.
Below are practical applications and workflows that leverage these findings.
Immediate Applications
- [Model Training Infrastructure | Software/AI] Plug‑and‑play upgrade for RLVR/GRPO post‑training of reasoning LLMs
- What: Integrate RLCSD into existing PPO/GRPO pipelines to get denser, cleaner token‑level credit assignment without a separate teacher model.
- Workflow/product: “RLCSD trainer” module for PPO—implements contrastive hint construction, token‑level modulation (
tanhscaling, masking, sign‑preserving clamp), and two‑path clipped loss; uses a periodically refreshed teacher snapshot of the student. - Assumptions/dependencies: Availability of a verifier (binary or graded) for target tasks; ability to sample groups with both correct and incorrect rollouts; identical prompt templates for positive/negative hints; extra forward passes for K negative hints.
- [Software Engineering] Code assistant training with unit tests as verifiers
- What: Fine‑tune coding LLMs using passing tests as positive hints and failing tests as negative hints to improve synthesis, refactoring, and bug‑fix reasoning.
- Workflow/product: CI‑integrated training loop—sample candidate patches/solutions, execute tests to partition correct/incorrect, build contrastive prompts, train with RLCSD.
- Assumptions/dependencies: Reliable, fast test suites; deterministic or stabilized evaluations to avoid flakiness.
- [Education] Math/logic tutoring systems with stable, step‑by‑step reasoning
- What: Improve small to mid‑size models’ chain‑of‑thought quality and maintain appropriate explanation length in math problem solving and logic puzzles.
- Workflow/product: Tutor models trained on math datasets with automatic answer verifiers; deploy on-device or in classrooms for worked examples and practice.
- Assumptions/dependencies: Accurate verifiers (answer extraction/equivalence check); careful prompt templates to avoid stylistic confounds.
- [Finance & Accounting] Spreadsheet formula synthesis and reconciliation
- What: Train models to generate formulas, validate totals, or reconcile ledgers using verifiable checks as rewards; contrast passing vs failing solutions to focus on numeric/logical steps instead of formatting.
- Workflow/product: “Finance‑LLM trainer” with rule‑based validators (e.g., checksum, balance constraints).
- Assumptions/dependencies: High‑coverage validators; guardrails for data privacy.
- [Data Extraction/ETL] Structured extraction with schema validators
- What: Enhance adherence to schemas (JSON/XML, regex, type constraints) by contrasting outputs that pass vs fail validation.
- Workflow/product: RLCSD pipeline for structured extraction agents; integrate with existing validation engines.
- Assumptions/dependencies: Strong validators; mechanisms to generate and cache failed samples for negative hints.
- [Operations & Scheduling] Constraint‑aware schedule/plan generation
- What: Use constraint checkers (e.g., staffing rules, temporal constraints) to verify outputs; contrast satisfying vs violating plans to emphasize constraint‑bearing tokens.
- Workflow/product: Planning assistant trained in‑silico with a constraint solver or MILP checker as the verifier.
- Assumptions/dependencies: Efficient checkers; representative simulation scenarios to produce both success and failure cases.
- [MLOps/Compute Efficiency] Teacher‑free distillation for smaller orgs
- What: Improve reasoning models without serving a larger external teacher (saving memory/latency), using the model itself with privileged context.
- Workflow/product: Drop‑in replacement for OPD when teacher logits/vocab aren’t available; compatible across open‑source model families.
- Assumptions/dependencies: Verifiable reward; periodic teacher snapshot; some added compute from multiple hint passes.
- [Safety/UX Quality] Mitigation of style‑induced over‑assertiveness and length collapse
- What: Maintain healthy entropy/response length and reduce optimization toward writing style tokens (e.g., boilerplate, hedges).
- Workflow/product: Training guard module that monitors style‑token concentration and length dynamics; applies RLCSD to keep updates task‑focused.
- Assumptions/dependencies: Token categorization pipelines (optional for monitoring); stable training hyperparameters.
- [Research/Interpretability] Token‑level diagnostics and dataset design
- What: Use contrastive signal magnitudes to identify task‑bearing tokens and analyze where supervision is landing; design datasets/prompts to minimize style drift.
- Workflow/product: Visualization tool that reports the proportion of modulated tokens and their categories (task vs style), per dataset/model.
- Assumptions/dependencies: Access to logits for analysis (training already computes them); a vocabulary tagging heuristic.
Long‑Term Applications
- [Healthcare] Verifier‑anchored clinical reasoning (e.g., dosage calculations, order sets)
- What: Train models where portions of the task are verifiable (dose ranges, drug interactions) and contrast success/failure to focus on clinical logic rather than report style.
- Potential products: Clinical calculators, protocol adherence assistants.
- Assumptions/dependencies: High‑fidelity medical verifiers and knowledge bases; rigorous evaluation; regulatory compliance and risk management.
- [Legal & Compliance] Contract clause checking and policy conformance
- What: Combine formalized policy/contract rules with automated verifiers (or SAT/SMT solvers) to assess compliance; contrast compliant vs non‑compliant drafts.
- Potential products: Contract review copilots, compliance auditors.
- Assumptions/dependencies: Mature rule formalization; reliable verifiers; confidentiality guarantees.
- [Robotics & Autonomous Agents] Plan synthesis with simulator‑based reward
- What: Train task planners by contrasting successful vs failed executions in simulators; better token‑level attribution to action‑relevant steps.
- Potential products: Household or warehouse planning agents; task decomposition modules.
- Assumptions/dependencies: Fast, realistic simulators; stable sim2real transfer; robust success/failure labeling.
- [Multi‑Tool Agentic Systems] Long‑horizon tool use with verifiable subgoals
- What: Use tool‑return codes/validators for each substep and construct contrastive hints from successful vs failed tool runs to improve credit assignment across long chains.
- Potential products: Enterprise workflow agents (data pipelines, report generation).
- Assumptions/dependencies: Tool ecosystem with reliable status codes and checks; orchestration to sample groups per query.
- [Cross‑Model Distillation] Contrastive OPD with black‑box or closed‑source teachers
- What: Extend the contrastive principle to reduce style confounds when distilling from a teacher with limited access (e.g., logits unavailable) by crafting symmetric prompts and comparing outcomes.
- Potential products: Distillation frameworks that use API‑only teachers with contrastive calls.
- Assumptions/dependencies: Methods to estimate token‑level signals from black‑box models (e.g., sampling‑based estimators); cost control for multiple API calls.
- [Creative/Subjective Tasks] Surrogate verifiers and preference‑contrastive training
- What: For tasks lacking objective verifiers (summarization, tutoring feedback), use preference models or rubric‑based graders to create positive/negative hints and apply contrastive cancellation of stylistic artifacts.
- Potential products: Safer RLHF variants that avoid optimizing for superficial style cues.
- Assumptions/dependencies: High‑quality preference models; careful template symmetry; noise‑robust training.
- [Energy/Logistics Planning] Optimization‑in‑the‑loop reasoning
- What: Train reasoning models with digital twins/optimizers (power flow, routing) as verifiers; contrast feasible/optimal vs infeasible/suboptimal proposals.
- Potential products: Grid operation assistants, fleet routing copilots.
- Assumptions/dependencies: Scalable, accurate digital twins; clear feasibility/optimality checks.
- [Standards & Governance] Training audit practices to detect and mitigate style drift
- What: Develop guidelines requiring contrastive controls in RL post‑training to ensure improvements are tied to task correctness rather than stylistic biases.
- Potential products: Audit checklists, compliance tooling for LLM training.
- Assumptions/dependencies: Community consensus on metrics (e.g., style‑vs‑task token ratios), reproducible reporting.
Cross‑Cutting Notes on Feasibility
- Best suited to tasks with verifiable outcomes (binary or graded). For open‑ended tasks, surrogate verifiers (preference models, rubric graders) add noise and require further research.
- Requires constructing symmetric prompt templates for positive/negative hints; deviations reduce style cancellation.
- Needs both correct and incorrect samples per group; very easy/hard tasks may yield uniform outcomes—consider curriculum or adaptive sampling to ensure both.
- Compute trade‑offs: Although no separate teacher is required, each step evaluates 1 positive + K negative hints; batching and teacher snapshotting mitigate costs.
- The contrastive principle can “plug into” other on‑policy self‑distillation or OPD methods, but hyperparameters (K, τ, λ, δ, η) need tuning for each domain.
Glossary
- Advantage: In reinforcement learning, a measure of how much better an action (or token) is compared to a baseline; used to weight policy updates. Example: "The outcome-level advantage is then computed by group-relative normalization:"
- Black-box access: Using a model through its inputs/outputs without access to internal parameters or logits. Example: "OPD under black-box access to the teacher"
- Chain-of-Thought (CoT) solution: A step-by-step reasoning trace used as privileged or training context. Example: "the privileged context consists of the CoT solution together with the answer."
- Contrastive estimate: A signal formed by comparing two conditions (e.g., correct vs. incorrect hints) to cancel shared confounds and highlight informative differences. Example: "we form a contrastive estimate"
- Contrastive signal: The token-level supervision obtained by contrasting teacher signals under different hints. Example: "their difference yields the contrastive signal "
- Credit assignment: The problem of attributing outcome rewards to the specific intermediate decisions (tokens) that caused them. Example: "fine-grained credit assignment"
- Dense distillation: Matching the full token-level distributions between teacher and student across an entire rollout. Example: "performs dense distillation"
- Entropy explosion: A failure mode where output distribution entropy grows uncontrollably, destabilizing training. Example: "Failure Mode 1: Entropy explosion and training instability."
- Exposure bias: The mismatch from training on ground-truth prefixes while testing on model-generated prefixes, leading to compounding errors. Example: "the on-policy formulation mitigates the exposure bias inherent in standard supervised fine-tuning"
- Forward-KL: The Kullback–Leibler divergence measured as KL(teacher || student), encouraging mode coverage. Example: "forward-KL offers stronger mode coverage"
- GRPO: Group Relative Policy Optimization; a verifier-grounded RL method that normalizes rewards across a group of rollouts. Example: "exemplified by GRPO"
- Group-relative normalization: Scaling advantages by statistics computed over a group of rollouts from the same query. Example: "by group-relative normalization:"
- Importance ratio: The ratio of current-policy to old-policy probabilities for a taken action (token), used in PPO-style objectives. Example: "denote the per-token importance ratio."
- In-distribution: Data drawn from the same distribution as training, used for evaluating generalization within the trained regime. Example: "both in-distribution and out-of-distribution difficulty"
- Jensen--Shannon divergence: A symmetric divergence between two probability distributions, often used to balance mode seeking and coverage. Example: "Jensen--Shannon divergence"
- Logits: Pre-softmax scores output by a model that define token probability distributions. Example: "white-box access to the teacher's token-level logits"
- Long-horizon: Tasks requiring many sequential steps (tokens), making sparse rewards harder to propagate. Example: "long-horizon reasoning tasks"
- Mass-spreading: A tendency of certain divergence objectives to distribute probability mass broadly across many tokens or modes. Example: "at the cost of mass-spreading"
- Mode coverage: Ensuring the model assigns probability mass to all relevant modes of the target distribution. Example: "stronger mode coverage"
- Mode seeking: Favoring high-probability modes of the target distribution, potentially at the expense of covering all modes. Example: "the trade-off between mode coverage and mode seeking"
- On-policy distillation (OPD): Distilling a teacher into a student along trajectories sampled by the student itself. Example: "On-policy distillation (OPD) addresses this limitation"
- On-policy self-distillation (OPSD): Using the same model as both teacher and student, with the teacher conditioned on privileged context. Example: "On-policy self-distillation (OPSD) has recently emerged"
- Out-of-distribution: Data that differs from the training distribution, used to test robustness and generalization. Example: "out-of-distribution difficulty"
- Per-token modulation: Adjusting the magnitude of an outcome-level advantage at specific tokens based on an auxiliary signal. Example: "as a per-token modulation of $A_{\mathrm{ORM}$"
- PPO-style clipped surrogate objective: A Proximal Policy Optimization objective that clips importance ratios to stabilize updates. Example: "a PPO-style clipped surrogate objective"
- Privileged context: Additional information (e.g., a verified solution) available to the teacher but not the student. Example: "privileged context (such as a verified reference solution)"
- Privilege-induced style drift: A confound where conditioning on privileged context shifts token probabilities toward stylistic rather than task-relevant tokens. Example: "We term this pathology privilege-induced style drift"
- REINFORCE: A classic policy-gradient algorithm using sampled returns to update the policy. Example: "equivalent, in the policy-gradient sense, to REINFORCE"
- Reinforcement learning with verifiable rewards (RLVR): RL where rewards are provided by an external verifier that can check solution correctness. Example: "Reinforcement learning with verifiable rewards (RLVR), exemplified by GRPO"
- Reverse-KL divergence: The Kullback–Leibler divergence measured as KL(student || teacher), often more mode-seeking. Example: "The dominant choice for measuring this gap is the reverse-KL divergence"
- Rollout: A full sampled sequence (trajectory) from the model in response to a query. Example: "at the end of each rollout"
- Sign-preserving clamp: A safeguard that prevents token-level modulations from flipping the sign (direction) of the outcome-level advantage. Example: "Sign-preserving clamp."
- Skew KL: A variant of KL divergence that interpolates between forward and reverse KL to trade off mode coverage and seeking. Example: "skew KL"
- Stop-gradient operator: An operation that prevents gradients from flowing through a tensor (e.g., the teacher distribution). Example: "denotes the stop-gradient operator"
- Top-k truncation: Limiting probability mass to the top-k tokens during approximation or sampling. Example: "top- truncation"
- Trajectory-level reward: A scalar reward applied to the entire generated response rather than individual tokens. Example: "the sparse trajectory-level reward of RLVR"
- Verifier: An external system that checks whether a generated answer is correct and returns a reward. Example: "The reward itself is supplied by an external verifier"
- White-box access: Having internal access to a model’s parameters or token-level outputs (e.g., logits) for training. Example: "require white-box access to the teacher's token-level logits"
Collections
Sign up for free to add this paper to one or more collections.