- The paper introduces FiRe-OPD, a dual-step method that filters weak trajectories and reweights tokens to enhance supervision quality.
- It demonstrates significant empirical gains in math reasoning and code generation across multiple teacher-student setups.
- The framework balances hard trajectory filtering with soft token modulation, improving optimization stability and knowledge transfer.
Filter, Then Reweight: Revisiting Granularity in On-Policy Distillation
Introduction
This essay analyzes the proposal and empirical evaluation of FiRe-OPD (Filter, then Reweight) (2606.02684), a new optimization framework for On-Policy Distillation (OPD) in LLMs. FiRe-OPD systematically addresses issues of unreliable and suboptimal supervision signals by integrating trajectory-level filtering with soft, token-level importance weighting, producing a new paradigm for selective, fine-grained optimization in OPD. The work substantially advances the state-of-the-art by demonstrating consistent and robust empirical improvements across strong-to-weak, single-teacher, and multi-teacher distillation scenarios for both math reasoning and code-generation.
Traditional OPD performs dense KL-based supervision across all student-generated trajectories and tokens, assuming homogeneous signal quality. Recent research shows, however, that optimization signals in OPD suffer from granularity isolation and hard selection rigidity: (1) Most prior approaches apply selection mechanisms either at the trajectory or token level, neglecting joint modeling, and (2) Use of hard filtering discards potentially usable supervision, which often degrades optimization stability and expressivity.
Among recent advancements, EOPD leverages entropy-aware KL adjustments; TIP and REOPOLD focus on token-level filtering using either teacher or student entropy; ExOPD and Uni-OPD employ reward scaling and outcome-based trajectory selection. These, however, optimize in one dimension, lacking a systematic framework for dual-granularity adaptive weighting. FiRe-OPD is introduced as a unified solution to these deficiencies.
Method: FiRe-OPD Framework
FiRe-OPD deploys a two-stage process:
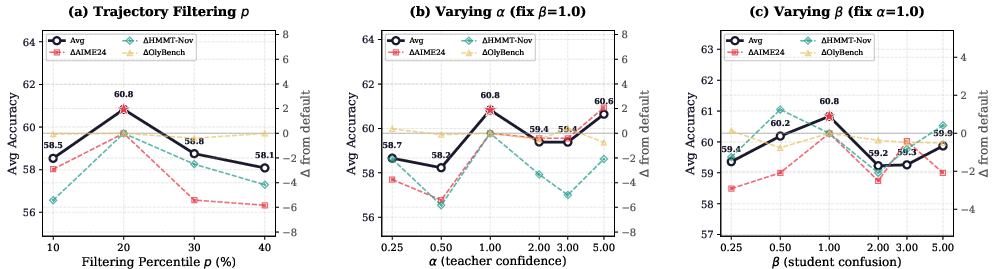
- Trajectory-Level Filtering: For each batch, FiRe-OPD computes the normalized teacher log-probability for every student-generated rollout. It removes the bottom p% (default p=20) of trajectories where the teacher’s likelihood is lowest, thereby eliminating off-distribution samples where teacher supervision is unreliable.
- Token-Level Importance Weighting: On the retained trajectories, per-token weights are computed as the multiplicative product of teacher confidence (1 minus normalized entropy) and student confusion (normalized entropy), soft-adjusted via scaling hyperparameters α and β. The weights are normalized across the trajectory to maintain stable gradient magnitude. Rather than removing tokens (hard selection), this mechanism amplifies updates in “teachable” positions (teacher is certain, student is unsure) while down-weighting saturated or irrelevant positions.
Figure 1: Schematic of FiRe-OPD's dual-stage selectivity: trajectory-level filtering culls poor rollouts, and token-level weights focus learning on critical tokens.
Empirical ablations validate this architectural decoupling: trajectory filtering is optimal as a hard (binary) step, while token weighting is optimal as a soft (continuous) modulation.
Experimental Results
Benchmarks and Evaluation
Experiments utilize:
- Strong-to-Weak: Qwen3-30B-A3B-Instruct → Qwen3-4B (large-to-small transfer)
- Single-Teacher: Qwen3-4B-Non-Thinking → Qwen3-4B (minimal gap, architecture match)
- Multi-Teacher: Joint supervision from math- and code-specialized Qwen3-4B models.
Evaluation is performed on rigorous mathematical reasoning benchmarks (AIME, MATH-500, AMC, OlympiadBench, HMMT, MinervaMATH) and code generation tasks (HumanEval+, MBPP+, LiveCodeBench).
Results Synthesis
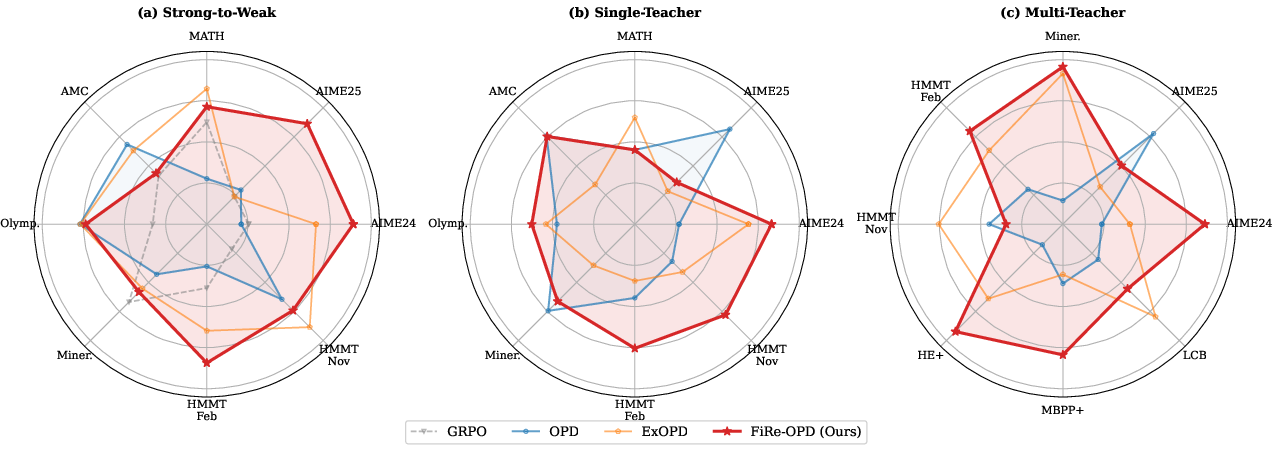
Figure 2: FiRe-OPD outperforms canonical and recent OPD methods by delivering consistently best coverage and balanced gains over strong-to-weak, single-teacher, and multi-teacher scenarios.
- Strong-to-Weak: FiRe-OPD achieves 60.83 Avg@8, an increase of +2.13 over OPD and +0.67 over ExOPD. Gains are pronounced on competition difficulties (e.g., +6.25 AIME24, +4.17 AIME25).
- Single-Teacher: 61.74 avg, +0.53 over OPD; gains materialize even with minimal teacher-student mismatch.
- Multi-Teacher: 51.88 avg on math (+4.84 over OPD), 64.16 avg on code (+4.37), significant improvements in handling heterogeneous teacher signals and facilitating capability integration.
Mechanistic Analysis and Visualization
Ablation studies dissect relative component importance:
Token-level visualizations confirm qualitative insights:

Figure 4: Token-level weights concentrate on reasoning transitions (“Therefore", "implies") and metacognitive cues, not on punctuative or numerical tokens.
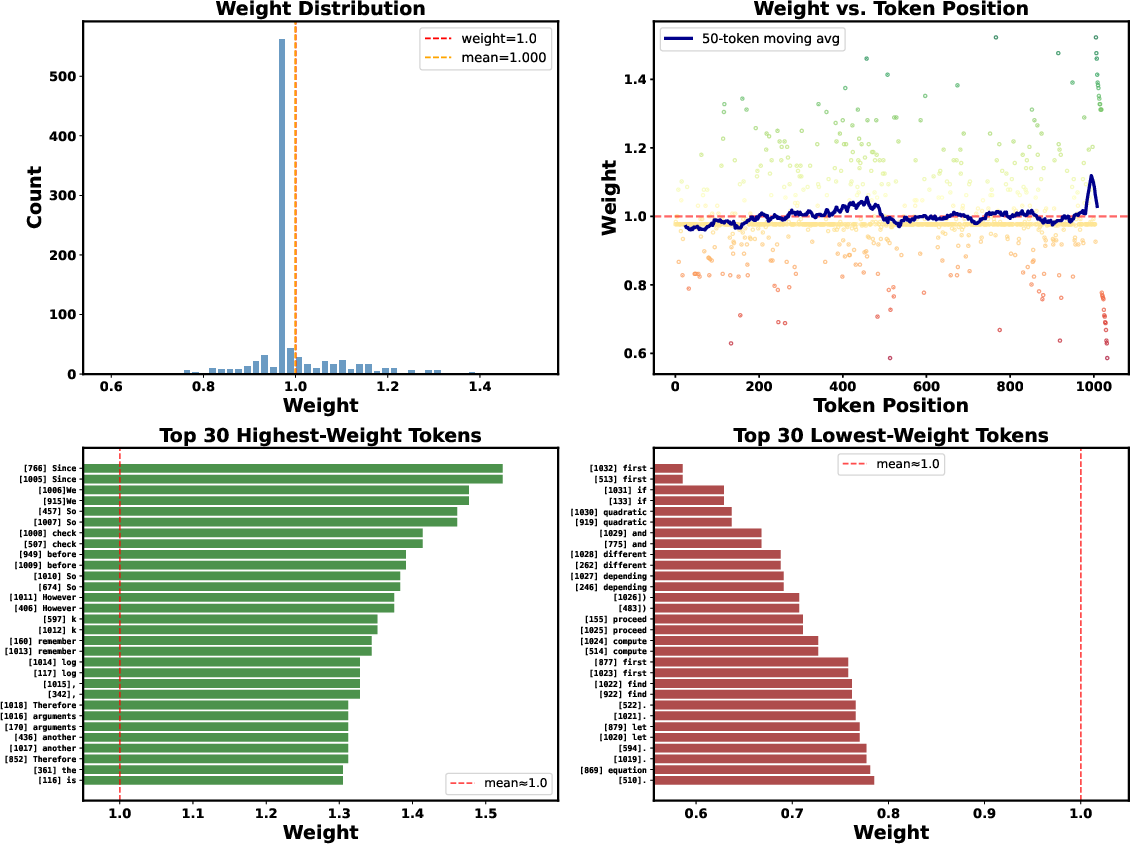
Figure 5: Distributional statistics corroborate selective upweighting of domain-relevant, high-uncertainty tokens and downweighting rote/predictable text.
Theoretical and Practical Implications
Practically, FiRe-OPD delivers immediately applicable improvements to OPD, enhancing reasoning and code-generation outcomes across teacher-student scenarios, and reinforcing the importance of tailored supervision in large model compression and capability transfer. Theoretically, it reconstructs the granularity continuum in distillation: effective optimization demands selective, yet not exclusive, utilization of supervision signals, with the locus of selection (trajectory/token) determined by the underlying dynamics of teacher reliability and student uncertainty.
By eschewing hard token censoring, FiRe-OPD circumvents brittle optimization and maintains stable credit assignment. The dual signals (teacher confidence, student confusion) represent an interpretable, extensible proxy for information-theoretic relevance.
Future Directions
Potential directions include:
- Prefix-aware weighting, where token importances are modulated by the trajectory’s evolving context and error propagation.
- Intermediate granularities, such as step- or span-level weighting, more closely aligning with structured reasoning and chain-of-thought sequences.
- Extending FiRe-OPD to multimodal and agentic settings requiring long-term temporal or cross-modal credit allocation.
Conclusion
FiRe-OPD establishes a robust recipe for on-policy distillation, directly resolving longstanding issues of granularity isolation and hard selection pathologies. By harnessing trajectory-level filtering and adaptive token reweighting, it attains significant improvements on diverse reasoning and code generation benchmarks. These results recommend granular, dynamic, and context-sensitive approaches as the new template for post-training knowledge transfer in LLMs.