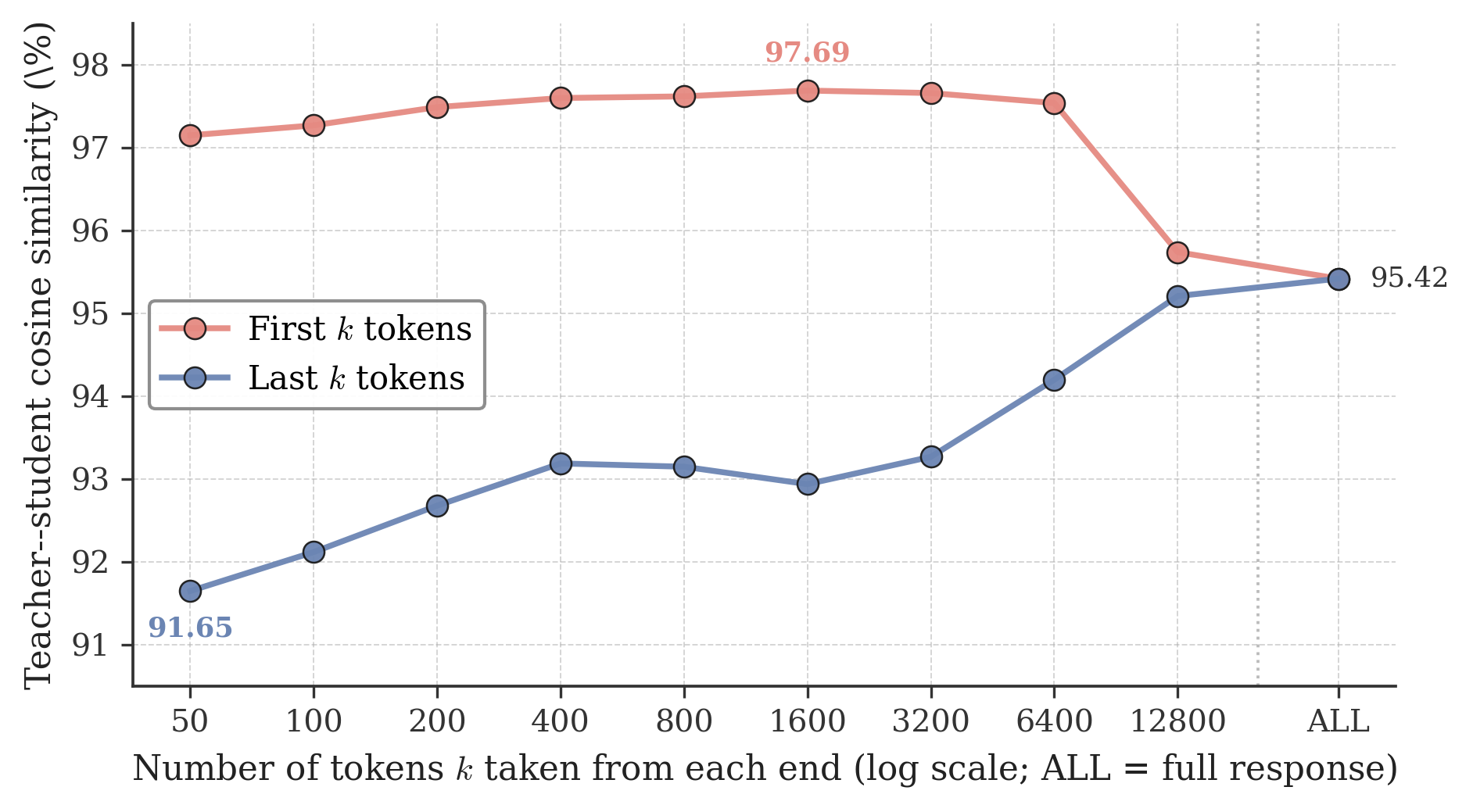
- The paper presents OPRD, a method that supervises intermediate hidden states to eliminate high-variance gradient issues inherent in output-space distillation.
- It leverages richer, deterministic scalar supervision from multiple layers to close the performance gap between student and teacher models.
- Empirical results demonstrate that OPRD enhances accuracy, reduces computational cost, and produces more concise, precise policy behaviors.
OPRD: On-Policy Representation Distillation
Motivation and Limitations of Output-Space OPD
On-policy distillation (OPD) has become standard in LLM post-training by adaptively fitting a student to a teacher on student-generated rollouts, thereby avoiding exposure bias. However, all existing OPD variants—sampled-token, full-vocabulary, and top-k—are restricted to the output space, enforcing alignment only on next-token probability distributions. The paper identifies two fundamental limitations of this paradigm:
- High-variance gradient estimation: Sampled-token and top-k OPD use REINFORCE-style estimators whose variance remains high throughout training because each token's KL divergence is Monte Carlo-estimated from a very large vocabulary. As the student converges to the teacher, signal-to-noise ratio of the gradient collapses, resulting in stagnating or oscillatory student performance well below the teacher.
- Information bottleneck: By supervising only on post-LM-head outputs, current OPD variants ignore the stack of teacher hidden states, discarding structural information (e.g., attention patterns and geometric structure) available in intermediate representations. The LM-head projection compresses these features into a highly ill-conditioned subspace, leaving many directions in hidden-state space unsupervised.
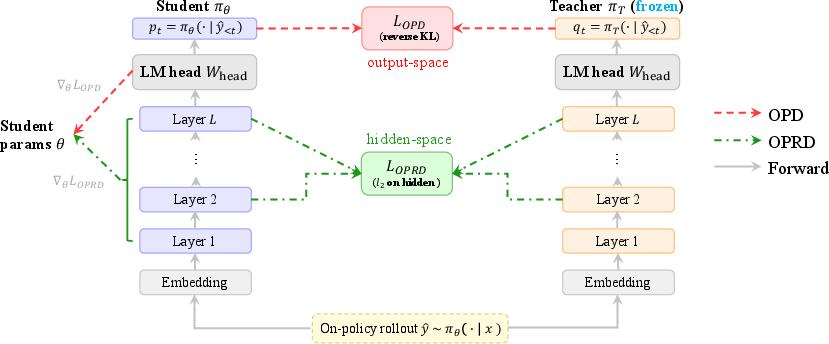
Figure 1: OPRD aligns student and teacher in intermediate hidden-state space as opposed to standard OPD which supervises only after the LM head, revealing the orthogonal channels of supervision.
OPRD: Representation-Level On-Policy Distillation
Objective and Mechanism
OPRD addresses both critical limitations by shifting the distillation target from next-token distributions to intermediate hidden states. For a student πθ and teacher πT sharing the same transformer architecture, OPRD directly supervises the student's representations hθ,t(l) to match the teacher's hT,t(l) across selected layers and response positions on student-generated trajectories. The objective is a normalized MSE loss:
LOPRD(θ)=Ex,y^[∣Llayer∣1l∑∑tmt1t∑mtd1∥hθ,t(l)−sg(hT,t(l))∥22]
This objective is inherently deterministic for sampled rollouts. Hence, OPRD provides a zero-variance gradient estimator, in contrast to the persistent sampling variance in OPD.
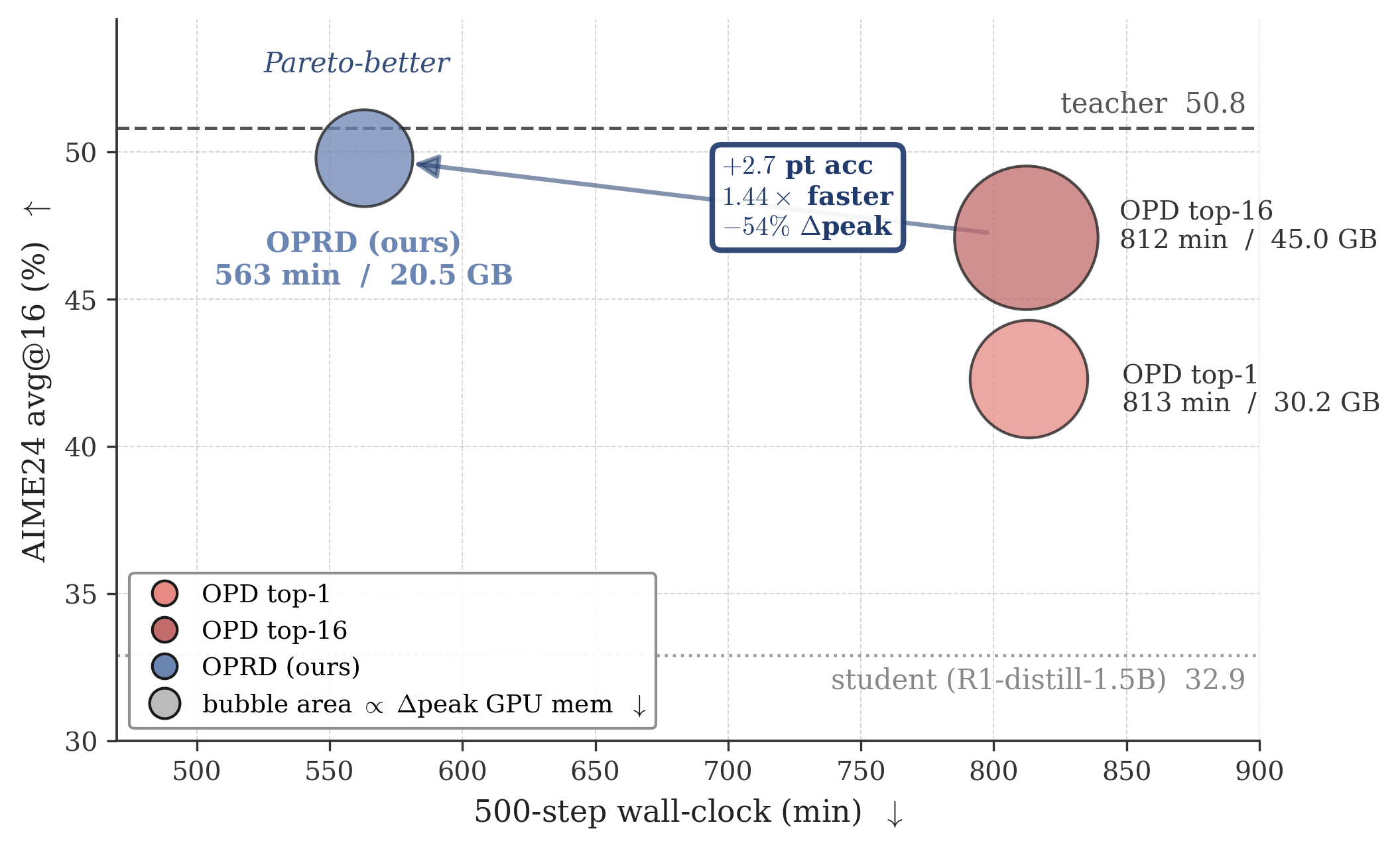
Figure 2: OPRD achieves strictly Pareto-dominant accuracy, training time, and GPU resource usage compared to strongest output-space OPD baselines (bubble area: actor-update memory).
Theoretical Guarantees
- Zero-gradient variance: OPRD's gradient is conditionally deterministic, removing late-stage optimization noise and enabling continuous improvement even as the student approaches the teacher.
- Richer supervision: OPRD exposes orders of magnitude more scalar supervision per sample (layers × positions × hidden_dim), providing alignment on richer internal structures that LM-head compressed losses discard.
OPD, by contrast, leaves entire affine subspaces (the "null space" of the LM head) unregularized and cannot penalize discrepancies outside the range of the output projection, as formalized by the spectral gap theorems in the appendix.
Empirical Evaluation
Mathematical Reasoning Benchmarks
The empirical evaluation targets advanced mathematical reasoning (AIME 2024, AIME 2025, AIMO) using a fixed teacher (JustRL-1.5B) and a student (R1-distill-1.5B) with identical architecture and head. Training configurations are strictly controlled: all compared methods use identical rollouts, the same single teacher forward pass, and equivalent optimization budgets.
- OPD Top-1: Reverse-KL on sampled tokens.
- OPD Top-16: Reverse-KL averaged over top-16 student tokens.
- OPRD: Full 28-layer, last-2000-token hidden-state supervision.
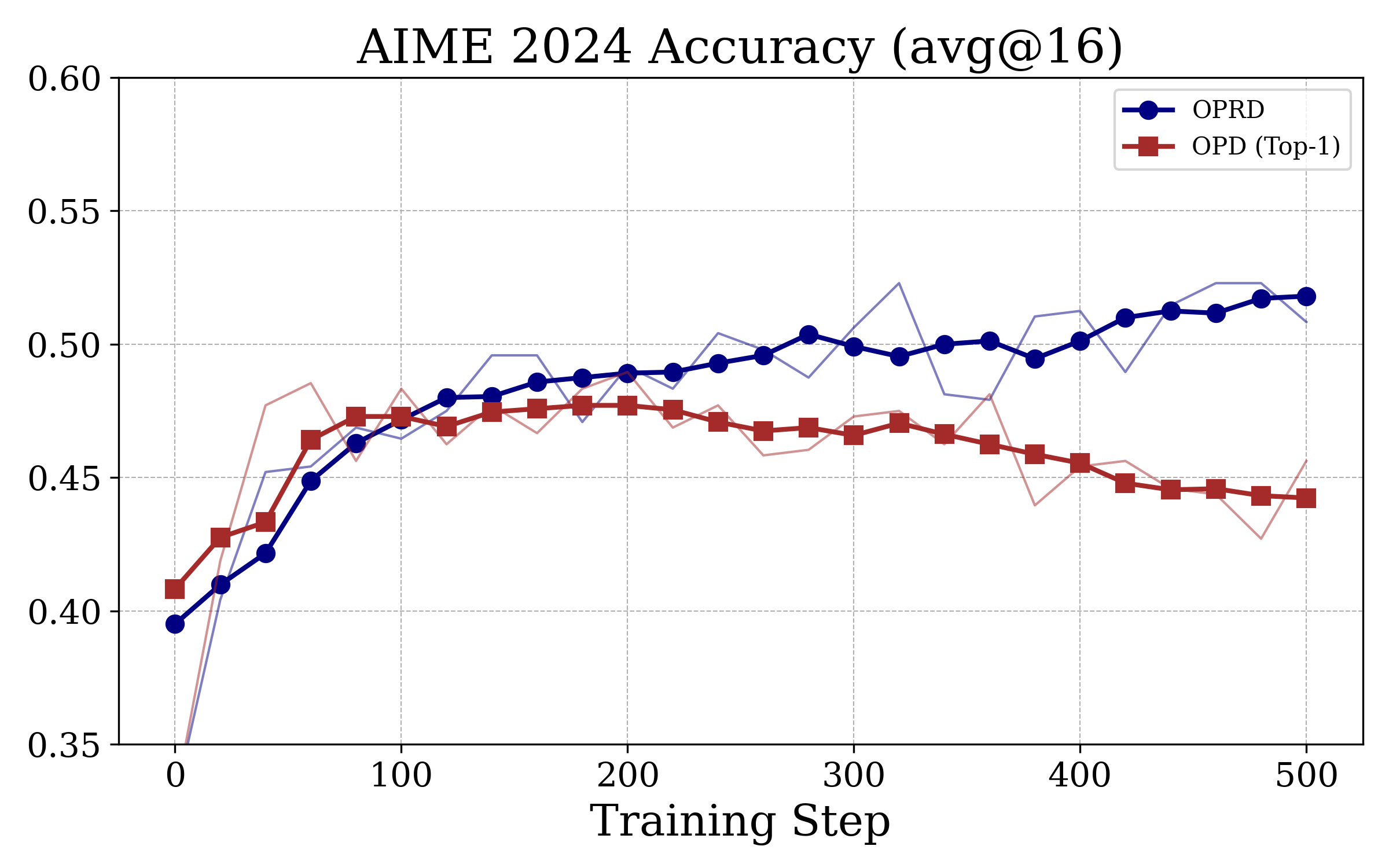
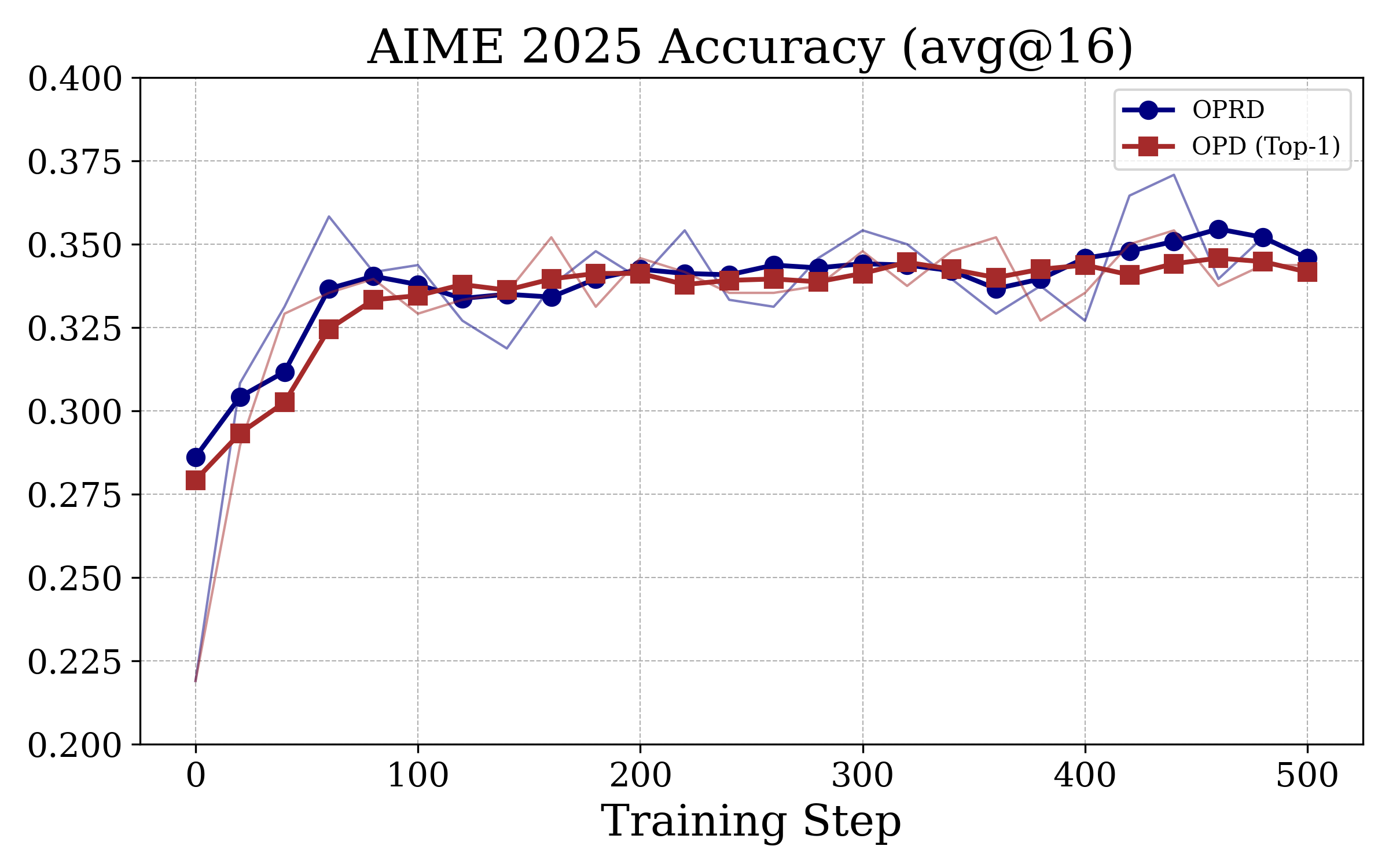
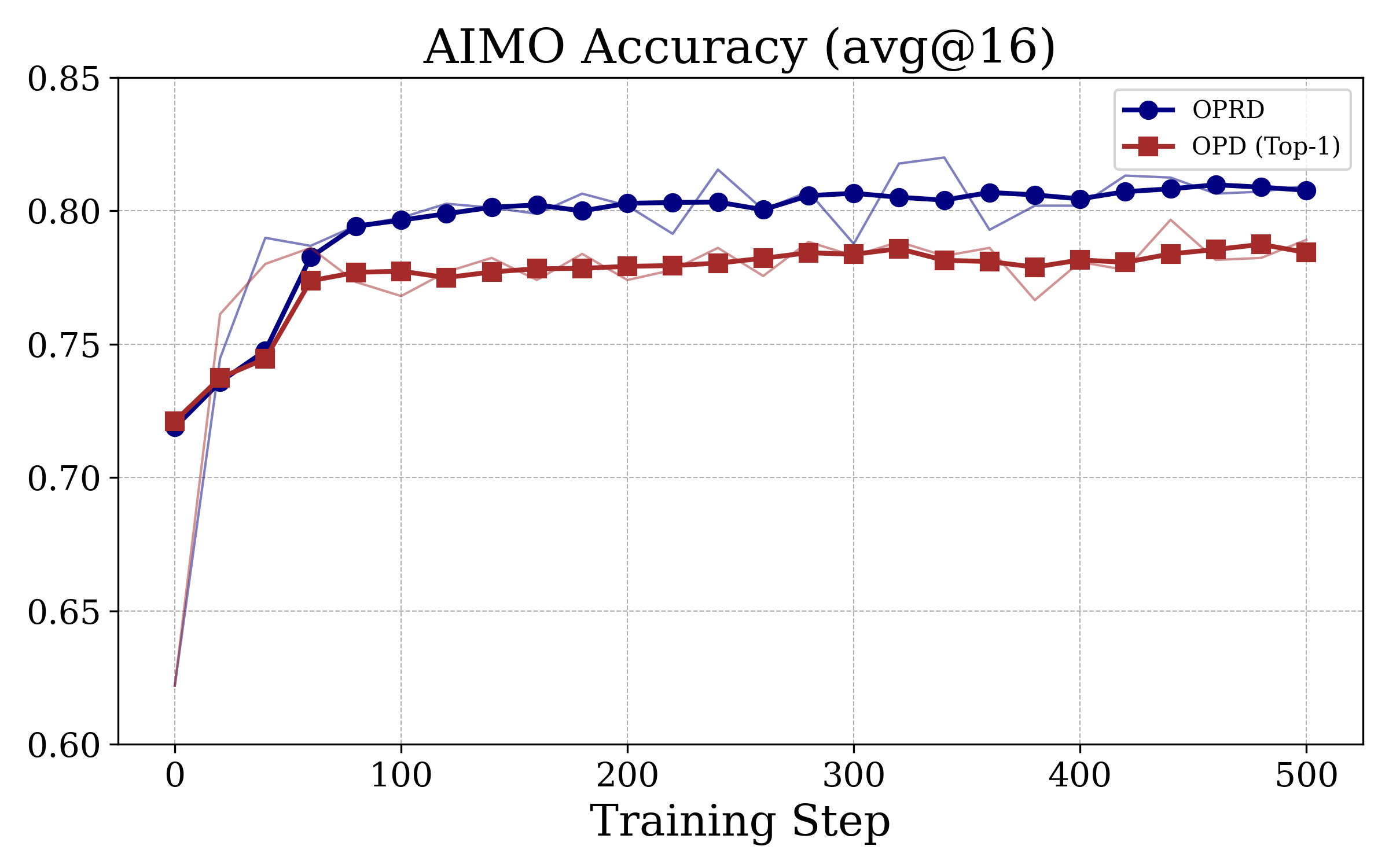
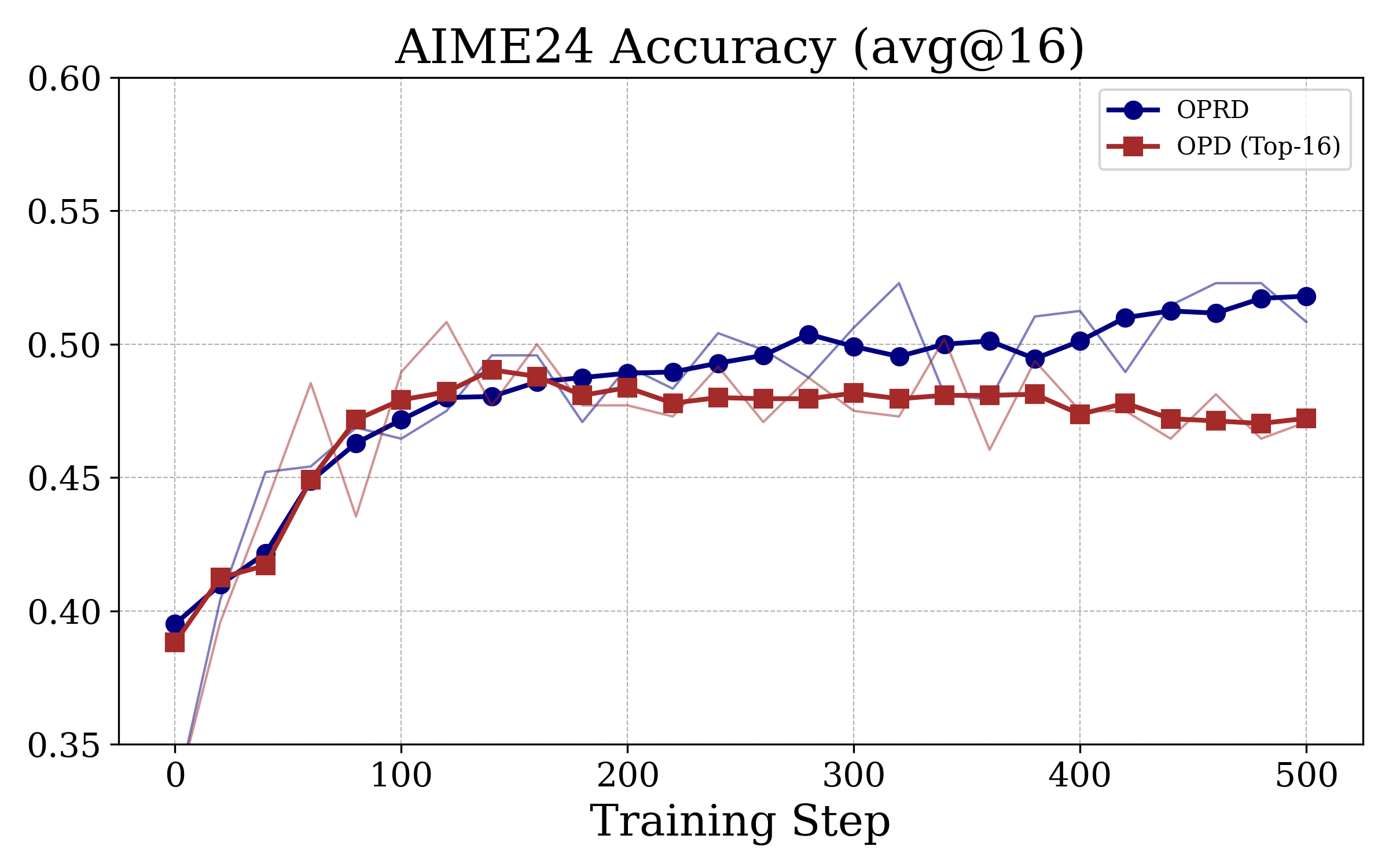
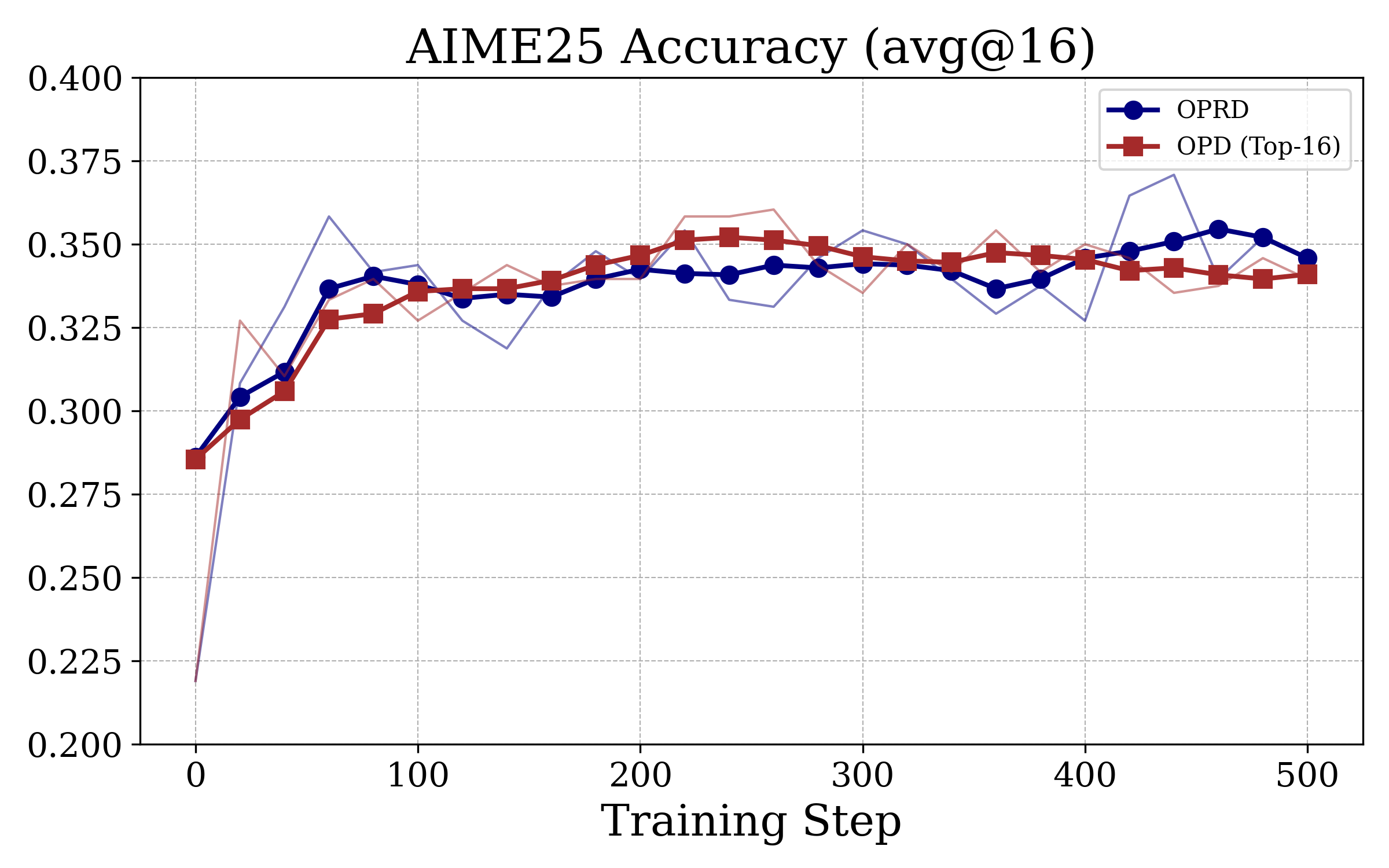
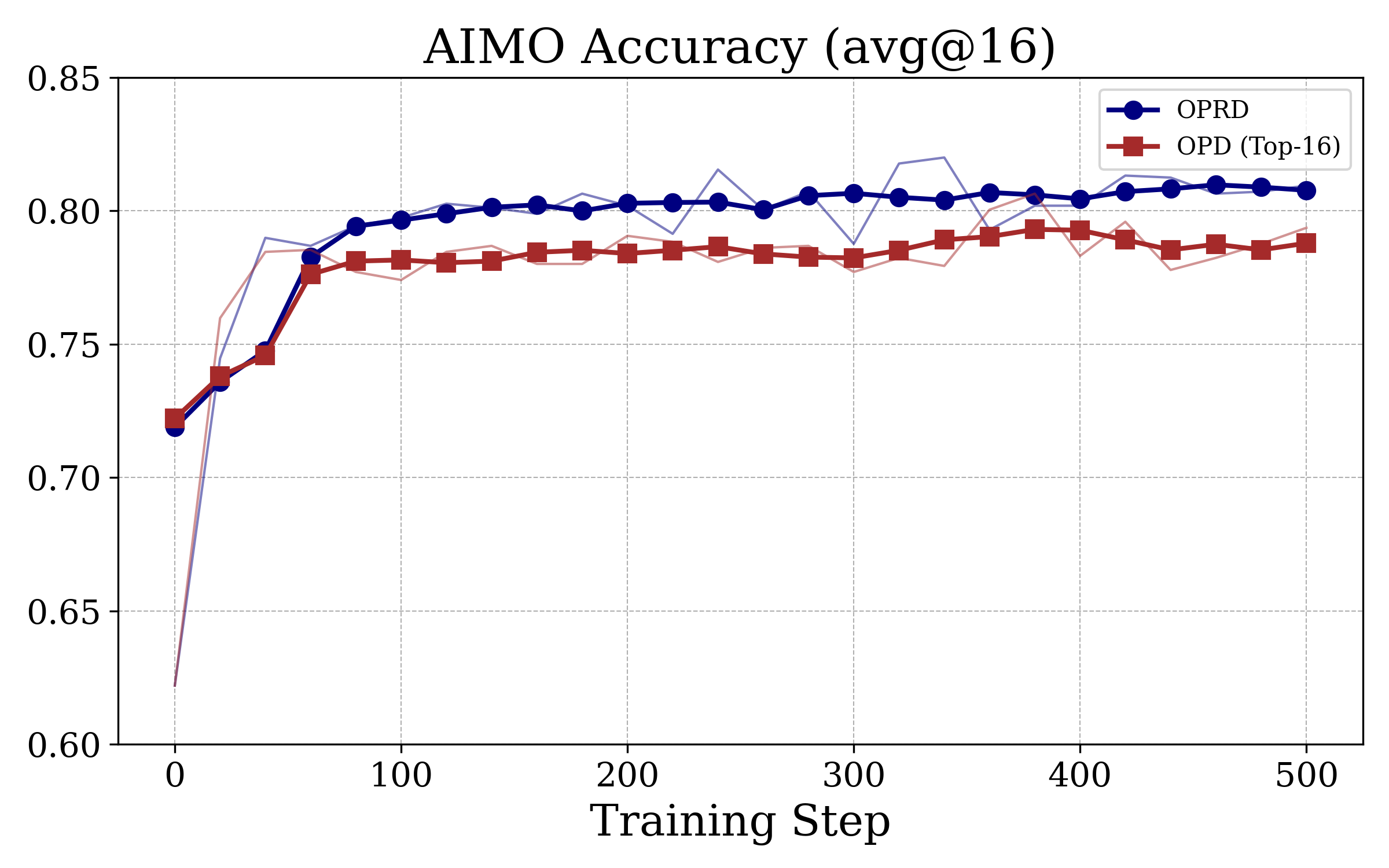
Figure 3: OPRD achieves monotonic, teacher-level accuracy improvement on AIME24/25/AIMO, unlike OPD baselines which plateau several points below the teacher.
Key Numerical Results (Avg@16, %):
| Method |
AIME24 |
AIME25 |
AIMO |
| Teacher |
50.8 |
35.6 |
79.5 |
| Student (unmodified) |
32.9 |
21.9 |
62.2 |
| OPD Top-1 |
42.3 |
33.5 |
77.0 |
| OPD Top-16 |
47.1 |
34.0 |
76.5 |
| OPRD |
49.8 |
34.6 |
79.1 |
OPRD matches or essentially closes the student–teacher gap on all three datasets, outperforming output-space OPD baselines by 0.6–2.7 points at strictly lower computation and memory cost.
Training Dynamics and Behavioral Effects
OPRD's learning curve is monotonically increasing and does not exhibit the plateau/oscillation typical of output-space OPD, validating the theoretical signal-to-noise analysis.
Additionally, OPRD guides the student towards more concise policy behavior, consistently yielding shorter but higher-accuracy responses compared to OPD.
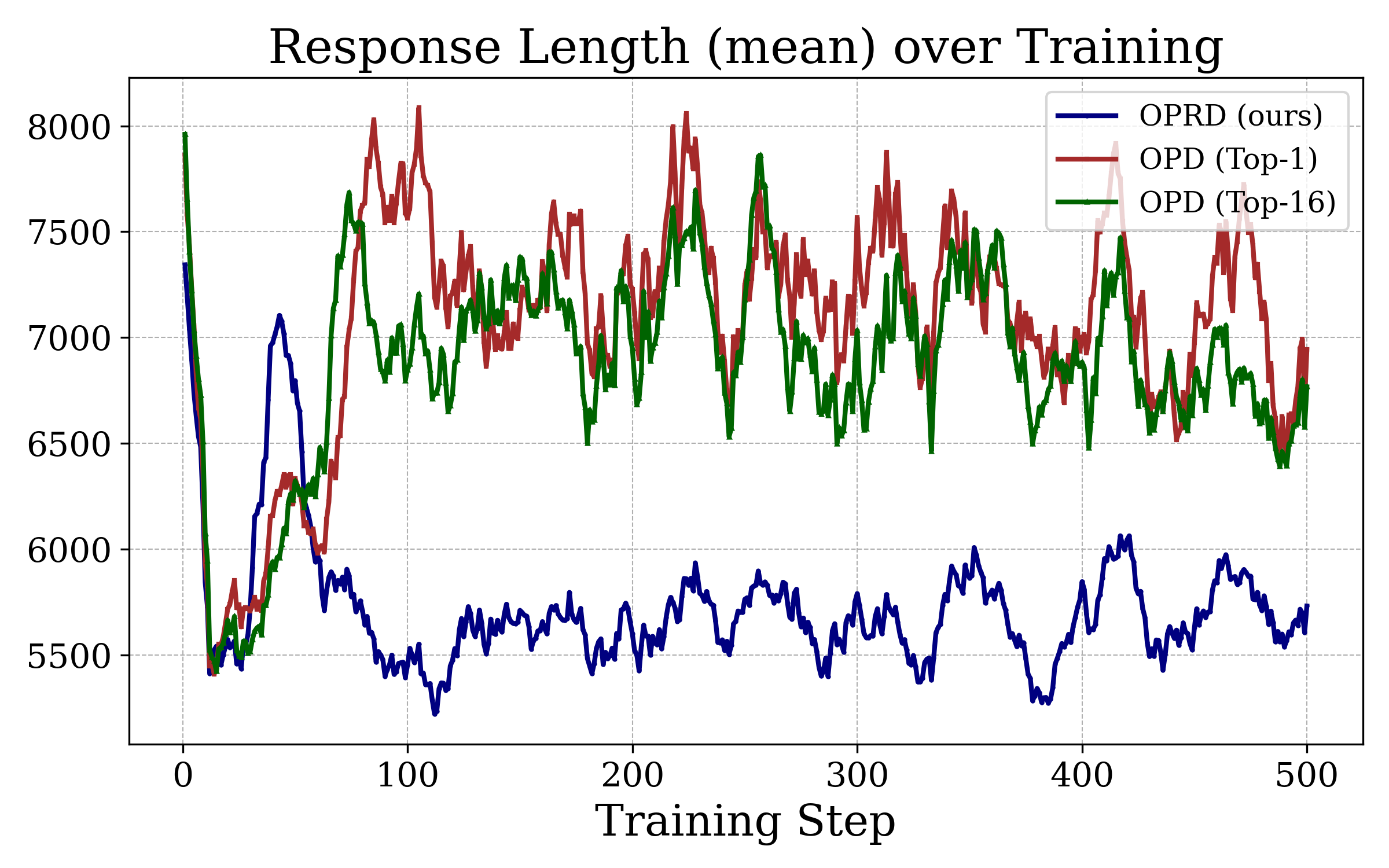
Figure 4: OPRD students generate substantially shorter reasoning chains—by ∼20%—at higher accuracy than OPD-trained counterparts.
Mechanistic Insights
Further ablation studies show:
Efficiency
OPRD reduces actor-update transient memory by 32–54% and cuts wall-clock training time by 1.44× compared to OPD Top-16. The reduced cost is a direct consequence of avoiding the O(BT∣V∣) logits tensor.
Theoretical and Practical Implications
The main theoretical implication is that output-space distillation's inability to supervise hidden directions orthogonal to the LM-head results in unaddressed student–teacher discrepancies that block downstream performance improvement, especially as models approach capacity ceiling. OPRD circumvents this bottleneck and enables more robust post-training convergence.
Practically, OPRD provides significant cost savings and unlocks representation-level supervision for RL pipelines and on-policy self-distillation settings. However, OPRD is architecture-matched—student and teacher must have compatible internal representations; cross-architecture generalization remains an open problem.
OPRD is also highly compatible as an add-on to existing pipelines, requiring minimal change to rollout or teacher evaluation infrastructure.
Conclusions
OPRD establishes representation-level on-policy supervision as a strictly stronger channel for post-training distillation in LLMs relative to all prior output-space methods. It eliminates gradient variance, exposes the full structural signal computed by the teacher, and achieves both faster and more accurate convergence at lower compute/memory cost.
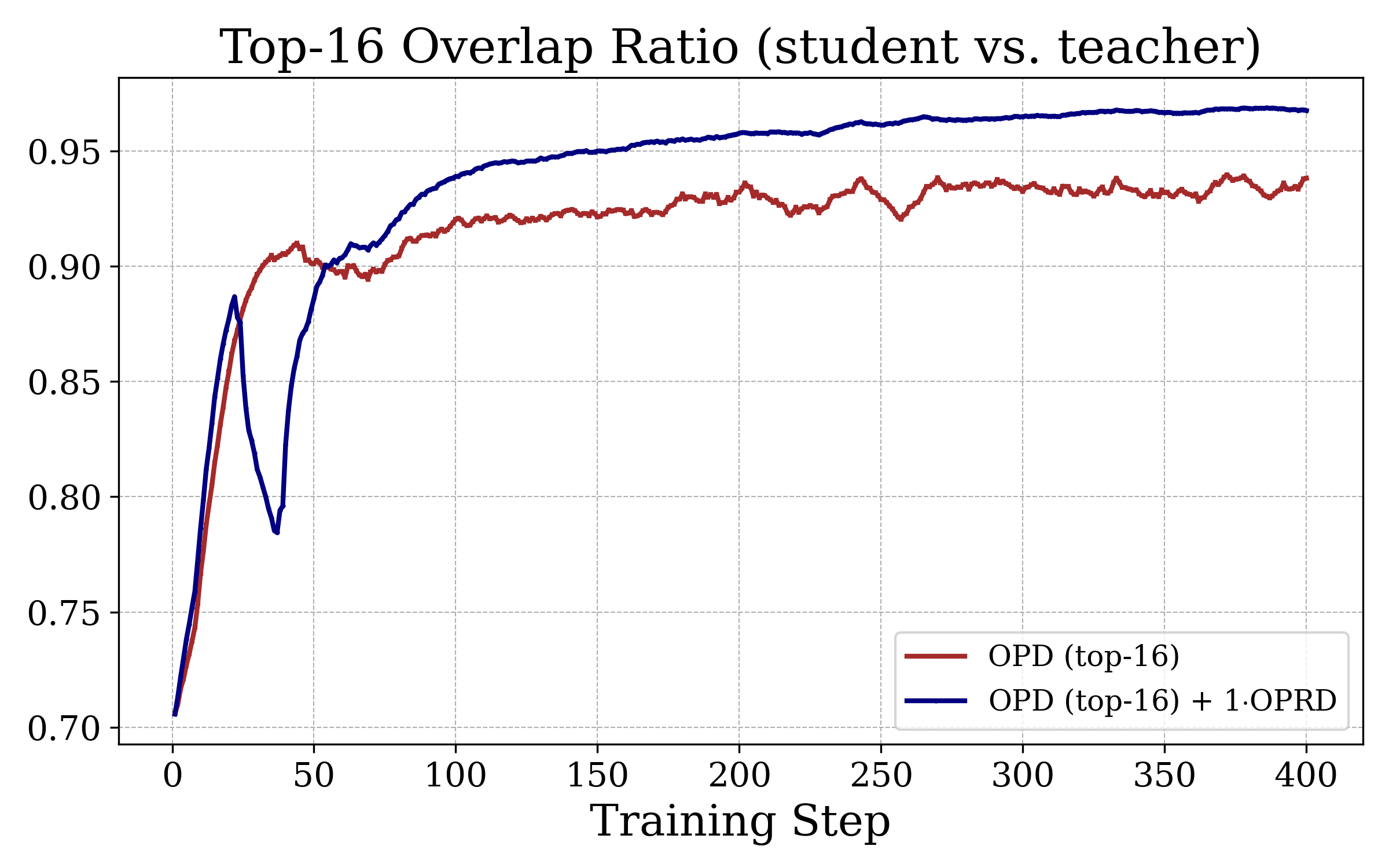
Figure 6: OPRD consistently increases student–teacher top-k next-token set overlap during training, enhancing the quality of output alignment.
Prospects for Future Work
Open directions include OPRD across heterogeneous student–teacher architectures (via learned projectors or contrastive geometry), task-adaptive layer/position weighting, phase transition analysis in policy reorganization, alignment of attention-maps in addition to hidden states, and application to broader task domains beyond chain-of-thought-style mathematics.
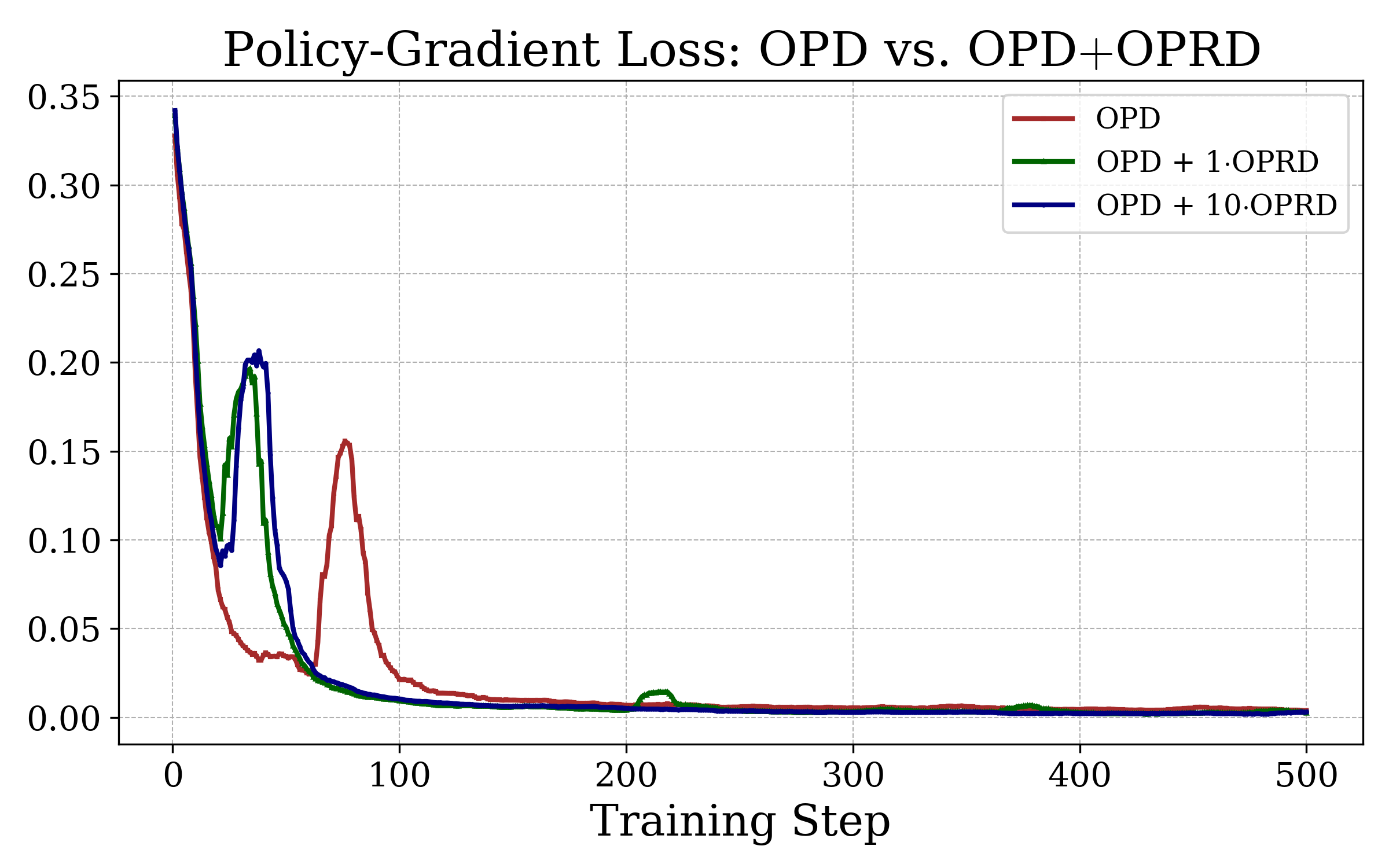
Figure 7: OPRD accelerates the phase transition in the policy-gradient loss, confirming its role in triggering robust policy realignment during distillation.
Summary
On-Policy Representation Distillation (OPRD) expands the scope of LLM distillation beyond probability-level alignment, establishing the practical value and necessity of leveraging all available representational information. This shifts the distillation bottleneck: the student is no longer evaluated solely as a probability prediction device, but as a process that must inhabit—and thus inherit—the full layered computation of its teacher.