- The paper introduces a graph-based RL framework that transforms sparse end-rewards into dense, step-level supervision by merging semantically equivalent states.
- It employs a dual-group advantage estimator to reduce variance and favor efficient, accurate reasoning paths during policy optimization.
- Experimental results demonstrate that GraphPO outperforms chain and tree-based rollouts with higher accuracy and improved exploration efficiency across various LLMs.
GraphPO: Graph-based Policy Optimization for Reasoning Models
Motivation and Empirical Analysis
Reinforcement Learning with Verifiable Rewards (RLVR) has become the standard for refining Large Reasoning Models (LRMs) on advanced reasoning tasks, such as mathematical and agentic benchmarks. The classical RLVR paradigm, which samples independent response trajectories and assigns reward based only on final answers, exhibits two critical limitations: (1) sparse outcome rewards impede credit assignment to intermediate reasoning steps, and (2) independent rollouts repeatedly explore semantically similar states, causing substantial redundancy and limiting exploration diversity.
Conventional approaches attempt to densify reward signals using Process Reward Models (PRMs) or through tree-structured rollouts, allowing prefix sharing and branch-level comparisons. However, trees treat diverged branches as independent, preventing information sharing among semantically equivalent states reached via different paths. This results in persistent redundant exploration even in tree-based rollouts.
An empirical study quantifies semantic redundancy across rollout strategies, demonstrating that both chain and tree sampling produce highly similar intermediate reasoning states: semantic similarity remains high (>0.9) across diverse prefixes (Figure 1). Tree-based rollouts reduce early-stage redundancy by prefix sharing but cannot merge equivalent descendants. Exploration efficiency measurements show that graph-based sampling substantially outperforms chain and tree approaches by reallocating computation toward novel frontier states, thus maximizing reasoning diversity under fixed token budgets.
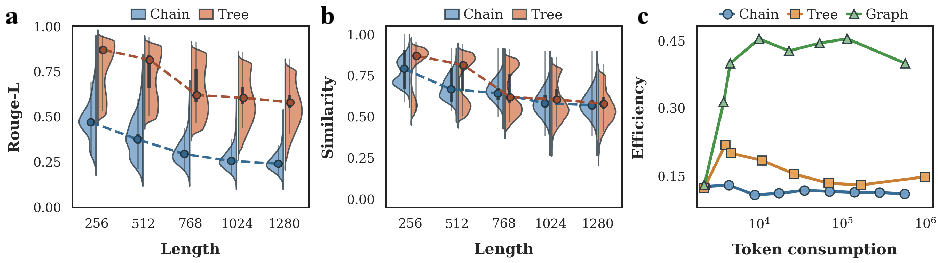
Figure 1: Empirical study reveals pronounced semantic redundancy in chain and tree rollouts and highlights superior exploration efficiency achieved by graph-based sampling.
GraphPO Framework
GraphPO introduces a graph-based RL framework where rollouts are represented as a directed acyclic graph (DAG): nodes denote intermediate semantic states summarized from reasoning prefixes, and edges correspond to generation steps. Graph construction proceeds by detecting semantic equivalences between non-causal nodes (via embedding similarity), merging them into equivalence classes, and reallocating budget away from redundant expansions to states with higher exploration value.
Within the graph, downstream suffixes from merged equivalent nodes are shared, converting sparse outcome rewards to dense step-level edge rewards. The policy model summarizes state embeddings and merges nodes when cosine similarity exceeds a threshold κ. All equivalent nodes retain direct context but also inherit suffixes from class members, enhancing both exploitation and exploration efficiency.
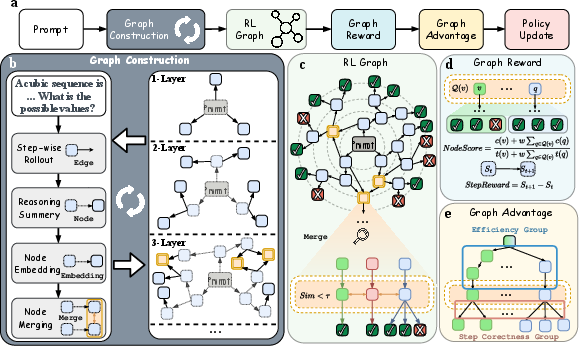
Figure 2: Architectural overview of GraphPO, from graph construction via step-level expansion to dual-group advantage assignment and reward derivation.
Dual-Group Advantage Estimation
GraphPO employs a dual-group advantage estimator:
- Correctness Group: Compares outgoing edges at each node, pooling rewards from direct and shared continuations to produce a lower-variance step-level correctness advantage.
- Efficiency Group: Compares incoming paths towards equivalence classes, assigning higher advantage to shorter paths that reach the same merged state; this promotes inference efficiency by favoring concise correct reasoning.
The combined dual-group advantage signal stabilizes policy updates and systematically drives the policy toward both higher accuracy and lower computation.
Training Objective and Theoretical Guarantees
GraphPO optimizes a PPO-style objective, leveraging the dual-group advantage for each token on an edge. The theoretical analysis demonstrates:
- Variance Reduction: Shared suffixes in equivalence classes reduce estimator variance compared to tree-based rollouts, with a tunable bias controlled by merging threshold κ.
- Exploration Efficiency: Budget reallocation away from detected redundant states increases expected coverage of distinct reasoning paths.
- Self-Emergent Process Supervision: Edge rewards derived from outcome-only signals provide effective process-level supervision comparable to oracle PRM surrogates, but without annotated step labels.
- Inference Efficiency: The efficiency advantage term ensures shorter correct reasoning paths are systematically favored.
Experimental Results
GraphPO is evaluated across four LLMs (Qwen2.5-7B-Instruct, Qwen2.5-7B-Math, Qwen3-8B-Base, Deepseek-R1-Distill-Qwen-7B) and multiple reasoning and agentic benchmarks. Experimental highlights include:
- Accuracy Gains: GraphPO consistently achieves higher accuracy across all datasets and models than both outcome-only and tree-based RL baselines (e.g., 91.6% vs. 88.1% on MATH500 for Qwen2.5-7B-Math).
- Exploration Preservation: Entropy measurements show GraphPO maintains broader exploration during training, avoiding the premature collapse of diversity observed in tree-based methods.
- Trajectory Efficiency: Response length analysis indicates GraphPO produces shorter, efficient responses by merging redundant states and emphasizing path efficiency.
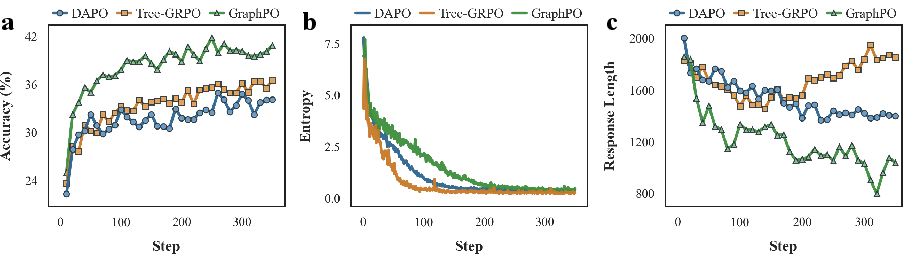
Figure 3: Training trajectory analysis for Qwen2.5-7B-Math, showing accuracy, entropy, and response length dynamics.
- Agentic RL: On deep search and agent benchmarks (General AI Assistant, WebWalkerQA, BrowseComp, XBench), GraphPO outperforms ReAct, GRPO, DAPO, and Tree-GRPO, validating the framework's applicability to sequential decision tasks.
- Resource Utilization: Ablation studies reveal optimal merging thresholds (κ ≈ 0.92) and pooling coefficients (w ≈ 0.7) strike the best bias-variance trade-off, and GraphPO maintains trajectory generation efficiency comparable to tree-based models.
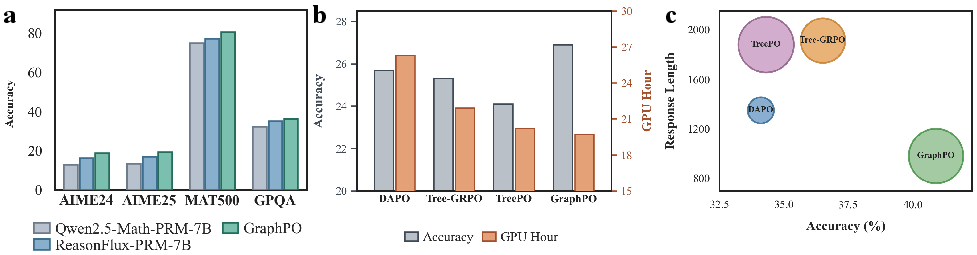
Figure 4: Comparative performance and efficiency—GraphPO outperforms PRM models without additional annotations, achieves accelerated training, and matches trajectory generation efficiency of tree-based baselines.
Practical and Theoretical Implications
GraphPO demonstrates that DAG-based rollout structures yield profound improvements in RL for reasoning models, leveraging semantic equivalence detection to maximize exploration and exploit redundancy for efficient credit assignment. By obviating the need for costly step-level annotations, the method enables scalable RLVR across diverse tasks. Practically, GraphPO enhances rollout utilization, reduces compute requirements, and supports RL in agentic workflows.
Theoretically, the approach provides a framework for variance reduction, improved exploration coverage, and self-supervised process reward derivation from outcome signals—opening avenues for further research in multimodal, long-horizon, and dynamic environments. Optimal settings for semantic merging and reward pooling are empirically robust, and false negatives degrade gracefully to tree-level estimators, while false positives are bounded by the merging threshold.
Conclusion
GraphPO advances RL for reasoning models by representing rollouts as graphs, merging semantically equivalent states to optimize exploration and exploitation under outcome-only supervision, and employing dual-group graph advantage estimation to drive inference efficiency and accuracy. Empirical results confirm that GraphPO outperforms canonical chain and tree-based baselines on both reasoning and agentic tasks with matched resource budgets, achieving denser process-level supervision and efficient trajectory generation. The framework’s robust, efficient design is poised to guide future developments in RL for advanced reasoning systems.

