Tree-OPO: Off-policy Monte Carlo Tree-Guided Advantage Optimization for Multistep Reasoning
Published 11 Sep 2025 in cs.AI, cs.CL, and cs.LG | (2509.09284v1)
Abstract: Recent advances in reasoning with LLMs have shown the effectiveness of Monte Carlo Tree Search (MCTS) for generating high-quality intermediate trajectories, particularly in math and symbolic domains. Inspired by this, we explore how MCTS-derived trajectories, traditionally used for training value or reward models, can be repurposed to improve policy optimization in preference-based reinforcement learning (RL). Specifically, we focus on Group Relative Policy Optimization (GRPO), a recent algorithm that enables preference-consistent policy learning without value networks. We propose a staged GRPO training paradigm where completions are derived from partially revealed MCTS rollouts, introducing a novel tree-structured setting for advantage estimation. This leads to a rich class of prefix-conditioned reward signals, which we analyze theoretically and empirically. Our initial results indicate that while structured advantage estimation can stabilize updates and better reflect compositional reasoning quality, challenges such as advantage saturation and reward signal collapse remain. We propose heuristic and statistical solutions to mitigate these issues and discuss open challenges for learning under staged or tree-like reward structures.
The paper introduces Tree-OPO, a framework that uses MCTS-based prefix trees to structure reinforcement learning for improved multi-step reasoning.
It employs staged advantage estimation with hierarchical, prefix-conditioned baselines, reducing variance and yielding more stable policy updates.
Experimental results on benchmarks like GSM8K demonstrate that Tree-OPO enhances accuracy and sample efficiency over traditional flat approaches.
Tree-OPO: Off-policy Monte Carlo Tree-Guided Advantage Optimization for Multistep Reasoning
Introduction and Motivation
Tree-OPO introduces a novel framework for preference-based reinforcement learning (RL) in LLMs that leverages the structure of Monte Carlo Tree Search (MCTS) rollouts to improve multi-step reasoning. The method is motivated by the observation that MCTS, when used as a teacher, generates a tree of partial solution prefixes, each representing a subproblem of varying difficulty. Traditional RL approaches such as Group Relative Policy Optimization (GRPO) treat all completions as flat, ignoring the hierarchical relationships between prefixes. Tree-OPO addresses this by introducing staged advantage estimation (SAE), which computes advantages in a manner consistent with the tree structure, enabling more informative and stable policy updates.
Methodology
MCTS-Derived Prefix Trees and Reverse Curriculum
Tree-OPO operates in a setting where an expert teacher (typically a stronger LLM) generates MCTS rollouts offline, producing a tree of reasoning prefixes. Each node in this tree corresponds to a partial solution, and deeper nodes represent easier subproblems due to increased context. The student policy is trained by sampling prefixes from this tree and generating continuations, receiving binary rewards based on task success.
This setup induces a reverse curriculum: the student is exposed to a spectrum of subproblem difficulties, from shallow (hard) to deep (easy) prefixes, facilitating more efficient exploration and learning.
Figure 1: A group of staged prompts, each representing a different reasoning prefix sampled from the MCTS tree.
Staged Advantage Estimation (SAE)
The core innovation of Tree-OPO is SAE, which formulates advantage estimation as a constrained quadratic program. Unlike standard GRPO, which uses a single baseline for all completions, SAE computes prefix-conditioned baselines, ensuring that advantages are comparable only among completions sharing similar context and expected return. The constraints enforce:
Parent-child consistency: If a child prefix leads to success and its parent does not, the child's advantage must be higher.
Sibling triplet consistency: Among siblings, advantages are ordered based on observed future success in their subtrees.
where r is the vector of observed rewards, and Corder encodes the tree-structural constraints.
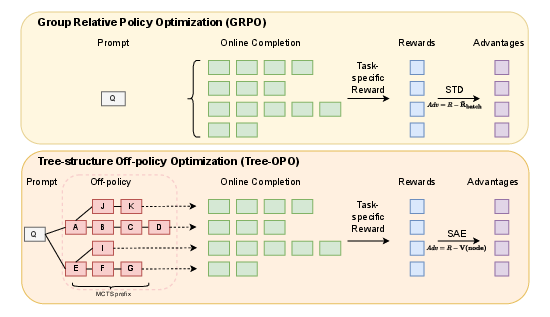
Figure 2: Tree-OPO (bottom) replaces flat standardization (top, GRPO) with hierarchical advantage ordering, yielding more discriminative advantages for structured generation.
Heuristic Baselines
To avoid the computational cost of solving the full quadratic program, Tree-OPO introduces heuristic baselines for V(p), the expected return from prefix p:
Optimistic: Indicator if any successful rollout exists in the subtree, VO(p).
Pessimistic: Indicator if all rollouts are successful, VP(p).
Empirical baselines provide the best trade-off between variance reduction and reward alignment, while optimistic/pessimistic variants are useful in settings with sparse rewards or when exploration/conservativeness is desired.
where Ak=rk−αV(pk), and V(pk) is the chosen baseline. Theoretical analysis shows that using the expectation baseline minimizes variance and aligns the gradient with the true reward structure.
Theoretical Analysis
Tree-OPO's SAE projection is shown to:
Reduce or preserve variance of the advantage signal compared to flat baselines.
Enforce prefix-consistent ranking of advantages, embedding inductive bias for structured reasoning.
Improve sample efficiency: Lower variance in the gradient estimator directly translates to fewer SGD iterations required for convergence.
These properties are formalized through a series of lemmas and theorems, establishing that the structured projection acts as a variance-reducing filter and sharpens the discriminative power of the advantage signal.
Experimental Results
Setup
Experiments are conducted on GSM8K, GSM-Symbolic, and MATH benchmarks. The student (Qwen2.5-1.5B) is trained using MCTS-derived prefix trees generated by a teacher (Qwen2.5-7B). Three advantage estimation structures are compared: flat (vanilla), trace (single rollouts), and tree (full MCTS hierarchy).
Main Findings
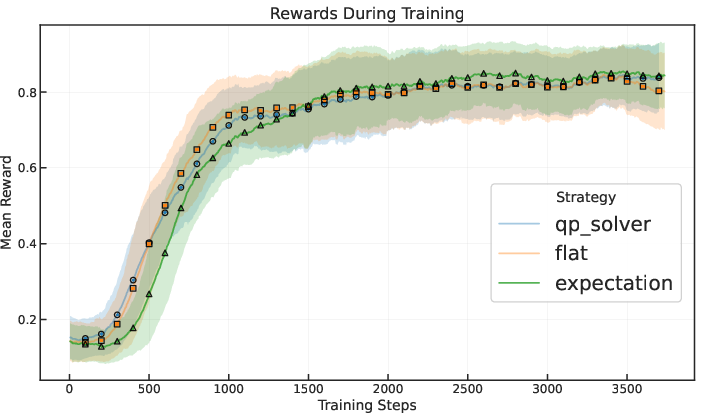
Tree-structured advantage estimation (expectation baseline) achieves 77.63% accuracy on GSM8K, outperforming both flat and trace-based baselines.
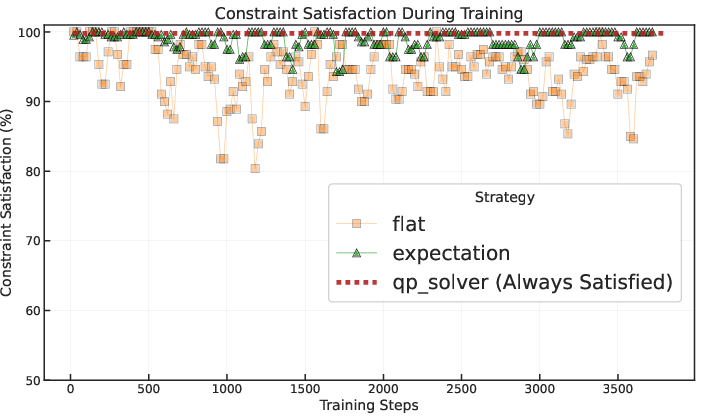
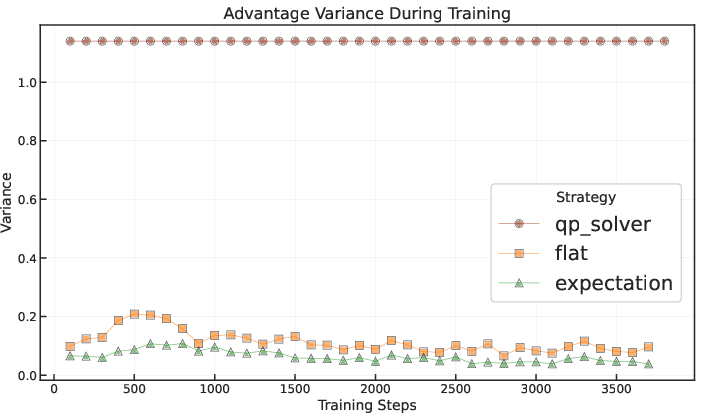
The expectation baseline yields the highest constraint satisfaction and lowest advantage variance, correlating with improved stability and performance.
The QP Solver (hard constraints) achieves perfect constraint satisfaction but introduces high variance, degrading performance.
Optimistic and pessimistic baselines underperform due to their inability to capture fine-grained differences in subtree success rates.
Figure 3: Constraint satisfaction rates for different advantage estimation strategies, demonstrating the superiority of the expectation-based tree-structured approach.
Cross-Dataset Robustness
Tree-OPO demonstrates robust performance across multiple math reasoning benchmarks, with the expectation-based variant consistently outperforming others. GRPO remains a strong baseline, particularly when its global advantages naturally satisfy tree-consistency constraints.
Policy Optimization Strategy Comparison
An ablation study compares Tree-OPO to KL-distillation and actor-critic methods. Tree-OPO achieves the highest accuracy (77.63%) with the lowest memory and supervision requirements, highlighting the efficiency of structured, reward-driven advantage estimation over hybrid or distillation-based objectives.
Practical Implementation Considerations
Data Preparation: Requires offline MCTS rollouts from a strong teacher to construct the prefix tree. This can be parallelized and reused across experiments.
Advantage Computation: Heuristic baselines are computationally efficient and sufficient for most practical purposes. The full QP solver is only necessary for ablation or when strict constraint satisfaction is required.
Batching and Curriculum: Sampling prefixes uniformly from the tree ensures exposure to a range of subproblem difficulties, implementing an implicit reverse curriculum.
Resource Requirements: Tree-OPO is more sample-efficient than on-policy RL methods and does not require value networks or online teacher rollouts, reducing both compute and memory overhead.
Deployment: The method is compatible with any autoregressive LLM and can be integrated into existing RLHF or preference-based training pipelines.
Implications and Future Directions
Tree-OPO demonstrates that leveraging the hierarchical structure of MCTS rollouts for advantage estimation yields measurable improvements in multi-step reasoning tasks. The approach bridges the gap between structured search-based supervision and lightweight policy optimization, offering a scalable alternative to value-based or distillation-heavy methods.
Theoretically, Tree-OPO opens new questions regarding optimal curriculum design, the interplay between tree structure and policy learning, and the extension to more complex or deeper reasoning domains. Practically, the method suggests that future RLHF pipelines for LLMs should incorporate structured trajectory information, not just flat preference signals, to better align model updates with compositional reasoning quality.
Conclusion
Tree-OPO introduces a principled framework for off-policy, tree-structured advantage optimization in LLMs, grounded in both theoretical analysis and empirical validation. By exploiting the compositional structure of MCTS rollouts, the method achieves improved stability, sample efficiency, and accuracy in multi-step reasoning tasks. The results suggest that structured advantage estimation, informed by the underlying reasoning tree, is a promising direction for advancing the reasoning capabilities of LLMs in both research and applied settings.