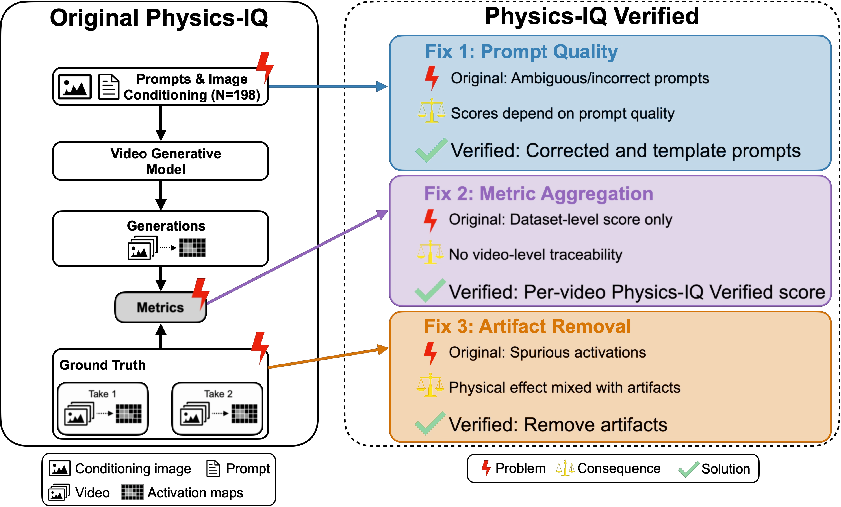
Physics-IQ Verified
Abstract: Video generative models ( VGMs) have become a new frontier that can be used not just for video generation but for a multitude of downstream tasks, including world modeling. To advance these tasks, a good video model must understand the physical reality of the world. Evaluating this understanding is an emerging field and has led to the Physics-IQ benchmark, which quantifies this explicitly by comparing model-generated videos to real-world videos of physical experiments. In this work, we present a systematic audit of the Physics-IQ benchmark, expose shortcomings and propose three solutions that sharpen how we can measure physical understanding of VGMs. Specifically, we improve prompt and ground-truth quality to reduce the influence of confounding factors and further introduce a sample-level scoring system that weights each sample and metric equally. Our resulting benchmark, Physics-IQ Verified, refines 57.6\% of all samples and improves over 34.8\% of prompts. In a comparison study using six image-to-video generative models, we observe moderate but meaningful ranking changes (Kendall's $τ= 0.46$). We hope Physics-IQ Verified advances the community by providing a more reliable signal toward physically accurate VGMs. The code for the benchmark can be accessed at https://github.com/google-deepmind/physics-iq-benchmark



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about testing whether AI video generators truly understand basic physics, not just how to make videos that look realistic. The authors review and improve a popular test called Physics-IQ, which compares AI‑made videos to real videos of simple science experiments (like dominoes falling or balls rolling). Their upgraded version is called Physics-IQ Verified, and it’s designed to measure “real physics understanding” more fairly and clearly.
What questions were the researchers asking?
The team focused on three simple questions:
- Are the instructions (prompts) given to video models clear enough to test physics, not guesswork?
- Is the scoring system fair, so each video and each metric counts equally?
- Are there “artifacts” (random camera shakes, reflections, or extra motions) in the real videos that accidentally boost or hurt scores and distract from the actual physics?
How did they do it?
First, here’s how the original Physics-IQ test works (in everyday terms):
- There are 66 real experiments, filmed from different angles and done twice. Each clip shows a setup, then something physical happens.
- A model gets a short “starter” part of the video (about 3 seconds) plus a text description (the prompt), then must generate the next 5 seconds.
- The AI’s video is compared to the real continuation using four measures:
- Spatial IoU: where does action happen?
- Spatiotemporal IoU: where and when does it happen?
- Weighted Spatial IoU: where and how strong is the action?
- MSE (mean squared error): how close are the actual pixels?
Think of IoU like asking, “Did the motion show up in the right spots and at the right times?” and MSE like, “Do the frames look the same, pixel by pixel?”
The authors found three problems and fixed them:
1) Clearer, better-structured prompts
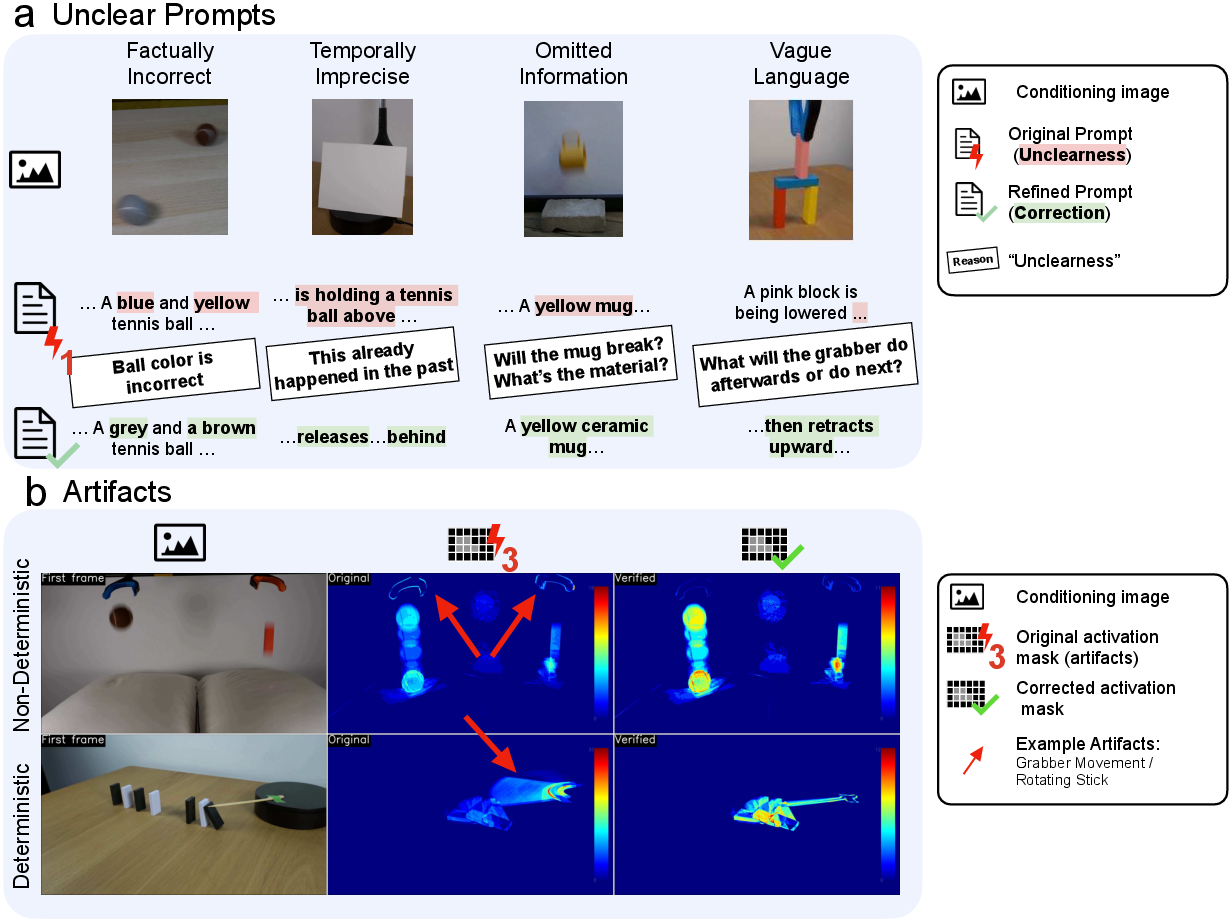
- Problem: Some original prompts were unclear, missing key info, too vague, or even factually wrong. That makes it hard for any model (or person) to predict the right outcome.
- Fix: They rewrote prompts to be like good exam questions—clear about the setup and what sets the action in motion, but without spoiling exactly how it unfolds.
- They also organized each prompt into six fields that match how different models prefer to be instructed: SETUP, SCENE, ACTION, CAM (camera), STYLE (e.g., “realistic scientific demo”), and SCOPE (stay within the described scene, don’t add random stuff). They avoided tricky negatives (“don’t do X”), which models often misread.
- Why this helps: Better prompts mean the model is tested on physics, not on guessing vague instructions.
2) Cleaning “artifacts” from real videos
- Problem: The metrics detect motion by looking at changes between frames. But sometimes motion comes from things that aren’t the phenomenon being tested—like a platform that’s always spinning (deterministic) or accidental stuff like glare, people moving off-camera, or camera wobble (non-deterministic).
- Fix: They marked when the main physical effect ends and masked regions with irrelevant motion, so the metrics focus on the real phenomenon (e.g., the ball and dominoes), not distractions.
- Why this helps: It prevents unrelated motion from inflating or confusing the scores.
3) A fairer, sample-level scoring system
- Problem: The original final score mixed everything across the whole dataset in a way that could overweight some videos and underweight others, and it made it hard to see which specific experiments caused problems.
- Fix: They now score each video individually (so each sample and each metric counts equally), then average those. They also flip MSE into a “higher is better” form so all four metrics are aligned.
- Why this helps: It’s easier to understand and fairer—every experiment gets the same say.
What did they find?
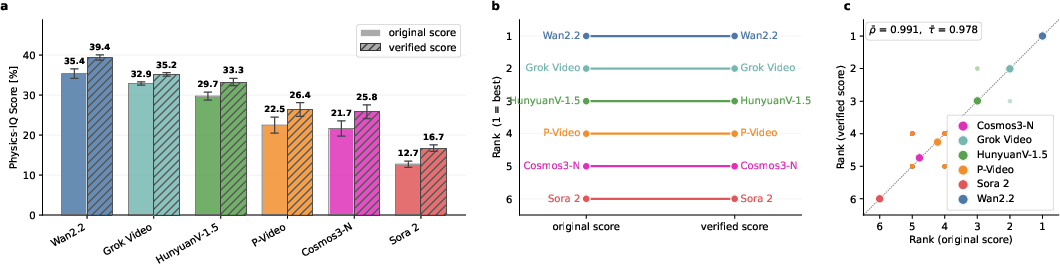
- Large cleanup: They refined 57.6% of samples and improved 34.8% of prompts. Many videos had artifacts that could confuse the metrics, and many prompts were ambiguous.
- Rankings changed: When they tested six image‑to‑video models with both the original and the verified setup, the order of who “did best” changed moderately but meaningfully (in stats terms, Kendall’s ). In plain terms: the improved test makes some models look better and others worse, depending on how well they truly handle physics.
- Clear prompts usually boost scores: With better prompts, most models did better, because they were responding to clearer, more precise instructions. One model (Wan 2.2) did not benefit as much, and even dropped in some cases.
- Cleaning artifacts usually lowers scores: Once you remove irrelevant motion from the real videos, some models’ previous high scores go down—especially for models that may have been “helped” by those accidental cues.
- New scoring increases clarity: The new per-sample scoring raised overall scores slightly but, more importantly, made it easy to trace which videos and metrics were strong or weak. Rankings from the old vs. new scoring alone stayed similar, showing the biggest changes came from the cleaner prompts and videos.
Why does this matter?
- It tests real physics understanding, not just “good-looking video”: By sharpening prompts, cleaning noisy ground truth, and making the scoring fair, Physics-IQ Verified gives a truer signal of whether AI models understand how the physical world works.
- Better benchmarks lead to better models: Clear, reliable feedback helps researchers improve video generators so they can be used as “world models” for things like robotics, science education, and planning.
- It reduces confusions and shortcuts: Models can no longer benefit from vague instructions or random video artifacts. That nudges progress toward genuine physical reasoning.
In short: Physics-IQ Verified is a cleaner, fairer way to check if video AIs actually “get” physics. It helps the whole community build models that don’t just look right—they behave right. The benchmark and code are available on GitHub so others can use and build on it.
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain after this work; each item is phrased to enable concrete follow-up by future researchers.
- Scope limited to image-to-video (I2V) models: no evaluation of text-to-video (T2V) or video-to-video (V2V) settings, multi-frame conditioning strategies, or how improvements transfer across modalities.
- Coverage and diversity of physical scenarios: only 66 experiments with fixed 3s+5s horizons; unclear representativeness for complex, multi-object, long-horizon, stochastic, or chaotic phenomena (e.g., turbulent fluids, deformables, frictional heterogeneity).
- Generalization tests not probed: no interventions on initial conditions (masses, friction, angles), geometry, or apparatus to assess counterfactual/causal physical reasoning and extrapolation.
- Camera and cinematography constraints: evaluation assumes static, locked-off cameras; robustness to camera motion, zoom, rolling shutter, or varying frame rates remains untested.
- Human validation of prompt clarity missing: no user study confirming that revised prompts enable humans to predict outcomes reliably (as intended “exam questions”), nor measurement of inter-rater agreement.
- Fairness and comparability of model-specific templating: per-model prompt templaters may advantage some models; no controlled ablation comparing (a) best-practice per-model prompts vs (b) a single standardized prompt to quantify fairness–performance trade-offs.
- Potential leakage of outcome via prompt fields: STYLE/SCOPE and more explicit CAM descriptions could inadvertently constrain the output space toward one “correct” rendering style; no audit of whether these cues leak ground-truth specifics or reduce legitimate variation.
- Stability across prompt styles: ranking sensitivity to alternative yet reasonable prompt phrasings/templates (within best-practice guidance) is not analyzed.
- Manual artifact removal subjectivity: freeze_areas and end_effect_frames rely on human annotations; no protocol details on annotator training, inter-annotator agreement, or objective criteria; potential for inconsistent or biased cleaning.
- Risk of over-cleaning: removal may also excise subtle, legitimate physical signals (e.g., secondary effects after “end”); no quantitative verification that cleaning preserves all relevant phenomena.
- Consistency of cleaning across physical-variation baselines: it is unclear whether artifacts were removed identically from both takes (GT1, GT2); mismatched cleaning can distort per-sample normalization by physical variation.
- No automated artifact detection: absence of algorithmic or model-based artifact detection/stabilization (e.g., background subtraction, camera-stabilization, motion segmentation) to scale and standardize cleaning.
- Metric design limitations persist: IoU on frame-difference activations and pixel MSE remain sensitive to lighting flicker, minor camera jitter, shadows, occlusion, and texture; lack of object-level or physics-aware metrics (e.g., tracked trajectories, conservation constraints, contact timing).
- Validation against human judgments of “physical correctness”: no side-by-side human evaluation to calibrate metric scores with perceived physical plausibility and correctness, or to weight metrics by human relevance.
- Per-sample physical variation estimation is noisy: normalization uses only two takes (GT1/GT2), offering no confidence intervals; no assessment of how variance in rM affects per-sample or aggregate uncertainty and rankings.
- Equal metric weighting unvalidated: the 1/4 uniform weighting and clipping choices lack empirical or theoretical justification; no sensitivity analysis to alternate weights, orderings, or non-linear aggregations.
- Effects of clipping not analyzed: the [0,1] clipping may mask extreme errors or inflate near-perfect cases; no sensitivity study on clipping thresholds or alternative bounded transforms.
- Ranking robustness by physics category: no analysis of per-domain stability (e.g., solids vs fluids vs optics) or which domains drive ranking changes after verification steps.
- Version drift and reproducibility with closed-source APIs: results depend on evolving proprietary models (e.g., Sora version changes); no protocol for pinning model versions, auditing updates, or archiving outputs to ensure long-term comparability.
- Limited statistical power: only four runs per model and 198 videos evaluated; unclear if this is sufficient for stable rank ordering given model stochasticity and prompt sensitivity.
- Training data contamination not audited: public release of benchmark videos/prompts could leak into model training; no contamination checks or blinded holdouts to ensure evaluations are out-of-training-distribution.
- Goodharting risk remains: models might learn to game activation-based IoU metrics (e.g., adding structured motion) rather than learning physical rules; no adversarial or metric-robustness tests.
- No downstream correlation: it remains unknown whether improvements on Physics-IQ Verified predict gains on real downstream tasks (robotics control, planning, model-based RL).
- Limited temporal horizon: only 5-second continuations are tested; effects on long-horizon prediction, delayed interactions, cumulative errors, and long-term conservation are unexplored.
- Angle/view generalization underexplored: although multiple viewpoints exist, the study does not analyze cross-view robustness, multiview consistency, or performance aggregation across viewpoints.
- No detailed failure-mode taxonomy: the paper reports ranking changes but lacks a granular, per-sample or per-phenomenon breakdown linking specific physical failures to model architectures or training regimes.
- Dataset licensing and access constraints: reliance on closed-source models and potential usage restrictions may limit full reproducibility; clarity on licensing and long-term hosting of cleaned annotations is needed.
- Benchmark extensibility: procedures for adding new experiments, maintaining annotation quality at scale, and governing community contributions are not specified.
- Automatic quality gates: no proposal for pre-flight checks (e.g., camera stabilization, lighting normalization) to systematically reduce spurious activations before metric computation.
Practical Applications
Immediate Applications
Below are practical, deployable-now uses that leverage the paper’s refined benchmark, methods, and tools. Each item names the sector(s), summarizes the application, suggests potential tools/workflows/products, and notes key dependencies/assumptions.
- Industry (AI/Software), MLOps/QA: Pre‑release physics QA for video generative models (VGMs)
- What: Integrate Physics-IQ Verified (artifact-cleaned ground truth, sample-level scoring, equal per-metric/sample weights) into continuous evaluation to detect regressions and trace failure modes to individual samples.
- Tools/workflows/products: CI job using the Physics-IQ Verified codebase; “per-sample score explorer” dashboards; automatic alerts on large drops in SP/ST/WS IoU or per-sample MSE-ratio.
- Dependencies/assumptions: Access to the benchmark repo and videos; stable model API versions (model drift affects reproducibility); compute budget.
- Industry (AI/Software), Prompt Engineering: Model-specific prompt templating in evaluation and production
- What: Use the six-field templater (SETUP, SCENE, ACTION, CAM, STYLE, SCOPE) to align prompts to provider best practices and reduce confounding from ambiguous/lax prompts.
- Tools/workflows/products: “Physics Prompt Templater” library that formats prompts per model (e.g., Sora-like, Wan-like); prompt linting in CI; internal prompt catalogs for physics-heavy tasks.
- Dependencies/assumptions: Up-to-date provider guidelines; team buy-in to change prompts; observance that negations perform poorly (avoid “don’t…”).
- Robotics, Autonomy R&D: Model selection and reward shaping using per-sample physics scores
- What: Use the Verified benchmark to pick I2V/V2V components for world models, and to shape inference-time or training-time rewards (e.g., penalize spatiotemporal IoU deviations from ground truth) in robotics pipelines.
- Tools/workflows/products: Evaluation hooks that log SP/ST/WS IoU against curated experiments (e.g., collisions, falling, rolling); reward terms derived from sample-level metrics; scenario subsets aligned to target robot domains.
- Dependencies/assumptions: Transfer from consumer VGMs to control-relevant prediction; domain adaptation may be needed.
- Media, Games, VFX: Physics-consistent previsualization and content quality checks
- What: Screen candidate VGMs for realism in motion and interactions; apply CAM/STYLE/SCOPE guidance to suppress unwanted camera motion or stylized renderings when realism is required.
- Tools/workflows/products: Previz “physics fidelity gate” using Verified scores; prompt templates that enforce “static locked-off” camera for realism; automated pass/fail thresholds per scene type.
- Dependencies/assumptions: Benchmark covers phenomena relevant to studio needs; tolerance for real-world variance.
- Academia (ML/AI evaluation): Benchmark auditing and replication studies
- What: Adopt sample-level scores and artifact-cleaning methodology to re-evaluate past claims about “physical understanding vs. perceptual realism”; run cross-benchmark comparisons.
- Tools/workflows/products: Analysis scripts using Verified metrics; bootstrap ranking comparisons; ablation studies on prompt clarity or artifact presence.
- Dependencies/assumptions: Availability of model checkpoints/APIs used in prior work; licenses for datasets.
- Benchmarking community, Dataset curation: Artifact-removal protocols for video benchmarks
- What: Reuse end_effect_frames and freeze_areas annotations to clean spurious activations in other physical video datasets.
- Tools/workflows/products: “Activation Inspector” GUI for annotators; SOPs for deterministic vs. non-deterministic artifact removal; inter-annotator agreement pipelines.
- Dependencies/assumptions: Human annotation capacity; clear definitions of phenomena vs. apparatus artifacts; QA budgets.
- Product/Procurement, AI Governance: Vendor RFP and compliance checklists for “physics-aware” claims
- What: Require Physics-IQ Verified scores (with per-sample breakdowns) in procurement; stipulate thresholds on SP/ST/WS IoU or MSE ratios for physics-heavy use cases.
- Tools/workflows/products: Standardized reporting template; audit-ready scorecards; spot checks using the Verified dataset.
- Dependencies/assumptions: Alignment of internal risk policy; legal/contractual acceptance of third-party benchmarks; recognition that scores vary with prompt quality.
- Education (STEM/Physics), EdTech: Lab modules comparing human and VGM predictions
- What: Use clear, exam-like prompts and “static camera” guidance to let students hypothesize outcomes, then compare to VGM continuations and ground truth.
- Tools/workflows/products: Classroom kits with selected scenarios; guided worksheets emphasizing when/where/how-much metrics; discussion of physical variance vs. model variance.
- Dependencies/assumptions: Classroom-safe access to model APIs; didactic framing that avoids teaching to a benchmark.
- Open Source, Community contributions: Extending scenarios and annotations
- What: Contribute new real-world experiments, prompts in six-field structure, and artifact annotations to broaden coverage (solids, fluids, optics, etc.).
- Tools/workflows/products: Contribution guides; annotation drives using the Activation Inspector; validation leaderboards for new sets.
- Dependencies/assumptions: Data licensing, safety and reproducibility of physical experiments; community moderation.
- Tooling vendors (AIOps/Observability): Physics-focused evaluation plug-ins
- What: Offer off-the-shelf plug-ins that compute Physics-IQ Verified metrics and visualize per-sample failures in enterprise model observability suites.
- Tools/workflows/products: Metric calculators, model adapters (T2V/I2V/V2V), report generators, comparison against physical variation per sample.
- Dependencies/assumptions: Compatibility with customers’ evaluation stacks; maintenance of provider-specific prompt templates as models evolve.
- Risk & Compliance (cross-sector): Audit claims about physics simulation in marketing and documentation
- What: Use ranking shifts between original and Verified evaluations to spot over-claiming based on confounded benchmarks.
- Tools/workflows/products: Audit checklists; side-by-side ranking reports; sensitivity analyses to prompt/ground-truth changes.
- Dependencies/assumptions: Access to reproducible runs and seeds; traceability from marketing claims to evaluation artifacts.
Long-Term Applications
These uses require further research, scaling, or ecosystem development to realize broader impact.
- Standards & Certification (Policy/Regulation): “Physics Consistency” certification for generative video
- What: Develop an industry standard (potentially ISO-like) using sample-level upper bounds and artifact-cleaned ground truths; issue certifications for physics-critical deployments.
- Potential products: Third-party audit services; compliance badges; standardized scenario suites per sector (e.g., robotics, AR/VR).
- Dependencies/assumptions: Multi-stakeholder consensus; governance around dataset updates; mitigation of Goodhart’s Law.
- Safety-critical autonomy (Robotics, Mobility): Regulatory test suites for world models
- What: Regulators mandate passing physics consistency thresholds for components used in planning, simulation, or predictive perception.
- Potential products: Compliance test harnesses; scenario packs emulating edge cases (slips, bounces, occlusion dynamics); per-sample safety KPIs.
- Dependencies/assumptions: Demonstrated correlation between Verified metrics and downstream safety; domain shift strategies.
- Digital Twins and Engineering (Energy, Manufacturing, AEC): Physics-aware surrogate generators
- What: Use VGMs screened by Verified metrics as inexpensive surrogates for early-stage visualization or hypothesis generation before high-fidelity simulation.
- Potential products: Twin pre-visualizers; “physics plausibility” gates in CAD/CAE workflows.
- Dependencies/assumptions: Careful delineation between plausibility and numerical accuracy; sector-specific validation.
- Healthcare (Training/Communication): Verified VGMs for medical education and patient communication
- What: Employ physics-consistent generative video for anatomical/biomechanical demonstrations where motion realism matters (e.g., joint mechanics), vetted by analogous benchmarks.
- Potential products: Educational content pipelines; approval workflows referencing Verified-like metrics adapted to biophysical domains.
- Dependencies/assumptions: Domain expansion beyond current 66 physics experiments; medical oversight; privacy/compliance.
- Platform Policy (Consumer/Creator Tools): Runtime “physics sanity checks”
- What: Integrate lightweight detectors (trained on activation maps or downstream proxies) to flag implausible motion in generated content and suggest re-prompting with CAM/STYLE/SCOPE constraints.
- Potential products: Editor plug-ins; “regenerate with physics guardrails” buttons; post-gen validators.
- Dependencies/assumptions: Fast approximations of Verified metrics; acceptable latency; UX acceptance.
- Expanded Benchmarks (Research): From 2D video to multi-view/3D and contact-rich phenomena
- What: Extend metrics beyond IoU/MSE to event- and force-aware measures; include tactile/contact proxies and multi-view consistency.
- Potential products: 3D activation metrics; temporal causal probes; datasets with synchronized sensor streams.
- Dependencies/assumptions: New data collection; agreement on ground-truth definitions; scalable artifact removal.
- Semi-automated artifact handling (Data Ops): ML-assisted annotation for artifacts
- What: Train detectors to propose freeze_areas and end_effect_frames, reducing human load in large-scale dataset maintenance.
- Potential products: Assisted labeling tools; uncertainty-driven review queues; continuous data quality pipelines.
- Dependencies/assumptions: Seed sets for training; human-in-the-loop validation; drift monitoring.
- Contracting & SLAs (Enterprise): Performance-based agreements around physics fidelity
- What: Define service levels in creative or simulation services that guarantee minimum Verified scores for chosen scenario classes.
- Potential products: SLA templates; automated compliance reporting; penalty/bonus mechanisms tied to physics KPIs.
- Dependencies/assumptions: Stable scoring across model updates; agreed-upon scenario relevance.
- Education at scale (EdTech): Virtual lab assistants and curriculum integration
- What: Use templated prompts and verified evaluations to power interactive physics labs that adaptively challenge students and explain failures.
- Potential products: Adaptive tutoring systems; scenario libraries mapped to learning objectives; teacher dashboards.
- Dependencies/assumptions: Robustness across devices; curricular alignment; assessment validity research.
- Marketplace transparency (Platforms): Physics-consistency labeling for model catalogs
- What: App stores or model hubs display Physics-IQ Verified badges and per-sample summaries, aiding customer selection for physics-sensitive tasks.
- Potential products: Badging pipelines; comparison widgets; API metadata schemas.
- Dependencies/assumptions: Broad vendor participation; periodic re-testing; governance to prevent benchmark gaming.
Notes on feasibility and assumptions common across applications:
- Generalization: The 66 real-world experiments are strong but finite; domain transfer to new tasks may require additional scenarios.
- Metric validity: IoU/MSE-based metrics capture many, but not all, aspects of physical understanding; future metrics should address causality, force, and contact.
- Model drift: Closed-source VGMs evolve; archived versions or version-pinned APIs are needed for reproducibility.
- Human effort: Artifact removal and prompt refinement may require sustained annotation and expert review.
- Goodhart risks: As the benchmark gains influence, anti-gaming safeguards, periodic refreshes, and diversified metrics are advisable.
Glossary
- Activation maps: Frame-wise signals indicating where motion/activity occurs, derived from differences between consecutive frames for metric computation. "All three IoU-based metrics used in Physics-IQ operate on activation maps\citep[Algo. 2]{motamed2026generative} that are derived from the visual differences of neighboring video frames, for both ground truth videos and generated videos."
- Artifacts: Spurious metric activations caused by visual events unrelated to the intended physical phenomenon, which bias evaluations. "Many videos contain ``spurious metric activations'' or artifacts that are not caused by the physical phenomena."
- Binary activations: Thresholded activation signals indicating presence/absence of motion, used by IoU metrics. "Artifacts influence the binary activations, here visualized as a temporally aggregated heatmap, arising from visual events not stemming from the physical phenomena to be observed which we categorize into non-deterministic and deterministic."
- Bootstrap analysis: A resampling-based method to estimate variability and confidence in rankings or metrics. "Additionally we perform bootstrap analysis where 500 complete sets of videos of size 198 are generated by drawing for each video id the corresponding video from one of the four original sets."
- Cinematographic language: Explicit, standardized camera and shot descriptors used to guide generation consistently. "The CAM field is changed to use descriptive cinematographic language describing the expected video in detail to ensure that it is sufficiently clear: ``Static locked-off single-shot with fixed frame throughout, filmed at constant framerate in real-time.''."
- Clipping operation: A function that bounds values within a specified interval to prevent out-of-range scores. "The clipping operation ensures the final score remains within ."
- Conditioning frame: A single starting image provided to a generative model to condition the subsequent video continuation. "A well-designed prompt for assessing VGMs' ability to model physics is a text description, accompanied by a conditioning frame or video, that clearly specifies the full experimental setup and the catalyst of the physical phenomenon, without revealing how that phenomenon unfolds."
- Conditioning input: The set of initial frames or a clip used to condition image-to-video or video-to-video models before generation begins. "These switch frames, alongside previous video frames, can also be used as conditioning input for image-to-video or video-to-video models."
- Deterministic artifacts: Predictable, setup-induced spurious signals (e.g., from apparatus motion) that confound metrics. "Deterministic artifacts stem from events that are specifiable from the prompt or experimental setup (e.g., a rotating apparatus)."
- Distributional metrics: Measures comparing statistics of sets of generated vs. real videos without one-to-one matching, e.g., FVD. "Earlier benchmarking efforts addressed this question using distributional metrics that compare unmatched sets of generated and real-world videos, such as Frechet Video Distance~\citep{unterthiner2019fvd} or Frechet Video Motion Distance~ \citep{liu2024fr}."
- end_effect_frames: Annotations marking when the target physical phenomenon ends, used to exclude post-effect artifacts. "First, we use end_effect_frames to indicate when the physical phenomenon ends, removing any artifacts that occur afterwards."
- freeze_areas: Spatiotemporal masks identifying regions and times to suppress artifact-induced activations during the effect. "Second, we use freeze_areas to pinpoint the spatial location and timing of artifacts occurring during the physical phenomenon."
- Frechet Video Distance (FVD): A distributional metric comparing statistical features of generated and real videos to assess realism. "such as Frechet Video Distance~\citep{unterthiner2019fvd} or Frechet Video Motion Distance~ \citep{liu2024fr}."
- Frechet Video Motion Distance: A metric focused on comparing motion consistency between sets of generated and real videos. "such as Frechet Video Distance~\citep{unterthiner2019fvd} or Frechet Video Motion Distance~ \citep{liu2024fr}."
- Ground truth: The real recorded continuation of an experiment used as the reference target for evaluation. "These 8 second videos are then split into a 3 second conditioning part, and a 5 second ``ground truth'' video continuation for comparison."
- Hallucinated intrusions: Unprompted, spurious objects or interactions erroneously introduced by a generative model. "SCOPE instructs ``only contains the described setup and actions'' to ensure the model is aware that no new actors or interactions enter the scene, suppressing hallucinated intrusions."
- Heatmap: A visualization summarizing activation intensity over space (and time when aggregated) to show where metrics are triggered. "Artifacts influence the binary activations, here visualized as a temporally aggregated heatmap, arising from visual events not stemming from the physical phenomena to be observed which we categorize into non-deterministic and deterministic."
- Image-to-video (I2V): A generative setting where a single image plus text conditions the model to produce a video continuation. "Our evaluation of six \ac{I2V} \acp{VGM} using both the original and verified evaluation finds that models react differently to the improvements in evaluation, which leads to the overall ranking of models changing substantially."
- Intersection over Union (IoU): A similarity metric comparing overlap vs. union of activation regions, used in spatial/motion evaluations. "Three are activation-based\citep[Algo. 2]{motamed2026generative} Intersection over Union (IoU) metrics, and one is a pixel-based Mean Squared Error (MSE) metric:"
- Kendall's tau: A rank correlation coefficient measuring agreement between two orderings. "In a comparison study using six image-to-video generative models, we observe moderate but meaningful ranking changes (Kendall's )."
- Mean Squared Error (MSE): A pixel-wise error metric averaging squared differences between generated and reference frames. "Three are activation-based\citep[Algo. 2]{motamed2026generative} Intersection over Union (IoU) metrics, and one is a pixel-based Mean Squared Error (MSE) metric:"
- Next-frame prediction objective: Training goal of predicting subsequent frames, hypothesized to induce learning of physical causality. "This use is motivated by the assumption that the next-frame prediction objective implicitly teaches the model to encode the causal structure of physical reality"
- Non-deterministic artifacts: Unpredictable recording accidents not specified in prompts, adding irreducible noise to metrics. "Non-deterministic artifacts arise by chance during recording and are absent from any prompt or experimental specification."
- Physical variation: The trial-to-trial variability between two real takes of the same experiment, used to normalize scores. "The physical variation is obtained by computing the mean value for each of these metrics in the same way as for a normal evaluation but using the first and second take for each experiment."
- Physics-IQ Verified: The refined version of the Physics-IQ benchmark with improved prompts, artifact cleaning, and sample-level scoring. "Our resulting benchmark, Physics-IQ Verified, % \footnote{An anonymized version is provided to reviewers} refines 57.6\% of all samples and improves over 34.8\% of prompts."
- Prompt templater: A structured prompt generator that formats fields according to model-specific best practices. "To ensure consistent conditioning, we decompose each prompt into six structured fields. These six fields are used by model-specific templaters, which create the text prompt according to providers' best practices (an example is shown in Figure~\ref{fig:prompt-example})."
- Sample-level scoring system: An evaluation approach computing per-sample scores before averaging, ensuring equal weight per sample and metric. "further introduce a sample-level scoring system that weights each sample and metric equally."
- Spatial IoU: An IoU metric measuring where action occurs spatially in the frames. "1)~Spatial IoU: Where does action happen?"
- Spatiotemporal IoU: An IoU metric measuring where and when action occurs across space and time. "2)~Spatiotemporal IoU: Where {paper_content} when does action happen?"
- Spearman's rho: A rank correlation coefficient quantifying monotonic agreement between rankings. "The resulting rankings are analyzed using Kendall's- \citep{kendall1945treatment} and Spearman's- \citep{spearman1961proof};"
- Switch frame: The exact frame where generation should begin, separating conditioning from prediction. "For the first 198 videos (ID001--198), switch frames mark the exact 3-second point where generation for the video generative model should begin."
- Trial-to-trial variability: Natural differences between repeated real-world trials of the same setup, defining an upper bound on achievable scores. "This variation serves as an upper performance ceiling, representing natural trial-to-trial variability."
- Upper performance ceiling: The maximum attainable benchmark performance given real-world variability between takes. "This variation serves as an upper performance ceiling, representing natural trial-to-trial variability."
- Weighted spatial IoU: A spatial IoU variant that also accounts for the magnitude/intensity of action. "3)~Weighted spatial IoU: Where {paper_content} how much does action happen?"
- World models: Generative models framed as simulators of physical environments, used for prediction and planning. "\Acp{VGM} are increasingly positioned not merely as synthesis tools but as world models \citep{schmidhuber1990making, lecun2022path, bruce2024genie} which simulate the physical world for complex tasks in robotics"
Collections
Sign up for free to add this paper to one or more collections.