- The paper introduces the black benchmark, rigorously evaluating IIE models through 16 dimensions and a diverse dataset of over 2,000 images and 6,700 instructions.
- It assesses both single-round and multi-round editing, revealing key challenges like error accumulation and semantic drift in iterative workflows.
- The study demonstrates strong alignment with human judgment using multimodal LLMs, offering actionable insights for model selection and future improvements.
Comprehensive Evaluation of Instruction-based Image Editing: The black Benchmark
Introduction
The paper "An Extensive Benchmark for Single-round and Multi-round Instruction-based Image Editing" (2606.15570) introduces black, a rigorous benchmarking suite designed to address the significant gap in evaluation methodologies for instruction-based image editing (IIE) models. As the field moves beyond traditional prompt-based image manipulation to text-instruction-driven protocols, the complexity, diversity, and semantic richness of editing tasks have outpaced existing benchmarks and evaluation metrics. black stands out for its simultaneous evaluation of both precision and robustness in single-round and multi-round editing scenarios, alignment with human judgment across 16 granular dimensions, and extensivity in both dataset size and annotation diversity. The benchmark quantitatively and qualitatively assesses eight contemporary IIE models, offering detailed comparative insights and strategic guidance for the research community.
Benchmark Design and Methodological Innovations
black encompasses a dataset of over 2,000 images sourced from diverse public datasets and annotated with more than 6,700 instructions spanning both single-round and multi-round editing scenarios. This dataset reflects a broad combinatorial coverage of editing tasks, ensuring representativity. The benchmark is structured to evaluate:
- Single-round and Multi-round Editing: Multi-round editing, often neglected in prior benchmarks, exposes instability and error accumulation in iterative IIE workflows. For this, black provides dedicated evaluation metrics for tracking fidelity and robustness across sequential instruction chains.
- Comprehensive Dimensionality: Sixteen evaluation axes are defined, split between high-level (semantic/object-centric) and low-level (pixel-level restoration/enhancement) dimensions. High-level metrics are assessed using advanced multimodal LLMs (e.g., GPT-4V), while pixel-level modifications are measured via established perceptual metrics such as SSIM and CLIP similarity.
- Instruction Diversity: To counteract annotation bias and limited linguistic scope, original instructions are systematically rewritten into paraphrased variants using ChatGPT, increasing the linguistic complexity and requiring models to demonstrate instruction robustness.
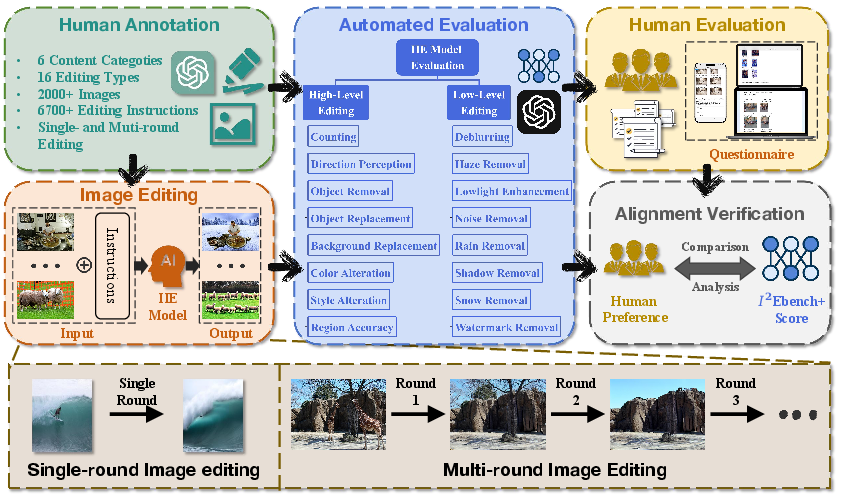
Figure 1: black systematically evaluates IIE models using a curated multi-domain dataset, diverse instructions, and automated/human scoring.
- Alignment with Human Judgment: black scores are empirically validated, showing strong positive correlation (Spearman's ρ) with systematic human evaluation across all metrics, confirming the benchmark’s perceptual reliability.
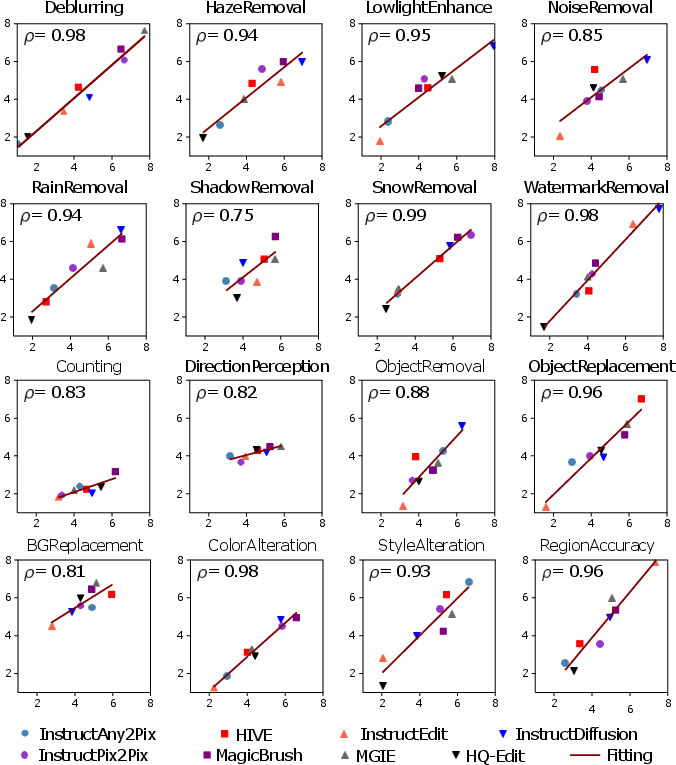
Figure 2: Strong linear and rank-order correlations between black scores and human assessment validate the perceptual alignment of the benchmark.
The paper reports that no evaluated model achieves uniformly strong results across all editing dimensions; instead, performance is highly task-dependent. For pixel-level editing, InstructDiffusion achieves leading scores in deblurring, noise removal, and watermark removal. In high-level semantic manipulations, MagicBrush and InstructAny2Pix demonstrate strong performance in object replacement and color alteration, but falter in multi-round stability. Critically, models utilizing state-of-the-art multimodal LLMs (e.g., Qwen-image, FLUX Kontext) consistently perform well in instruction-following and semantic compositionality, exhibiting robustness to linguistic paraphrasing and outperforming mask-based or handcrafted-instruction models in complex multi-round workflows.

Figure 3: Comparative visualization of single- and multi-round edits across 16 evaluation dimensions for major IIE models.
Moreover, multi-round editing tasks reveal significant degradation relative to single-round performance—particularly for iterative object replacement and counting. This reflects the compounding effect of error propagation and the requirement for persistent state tracking.
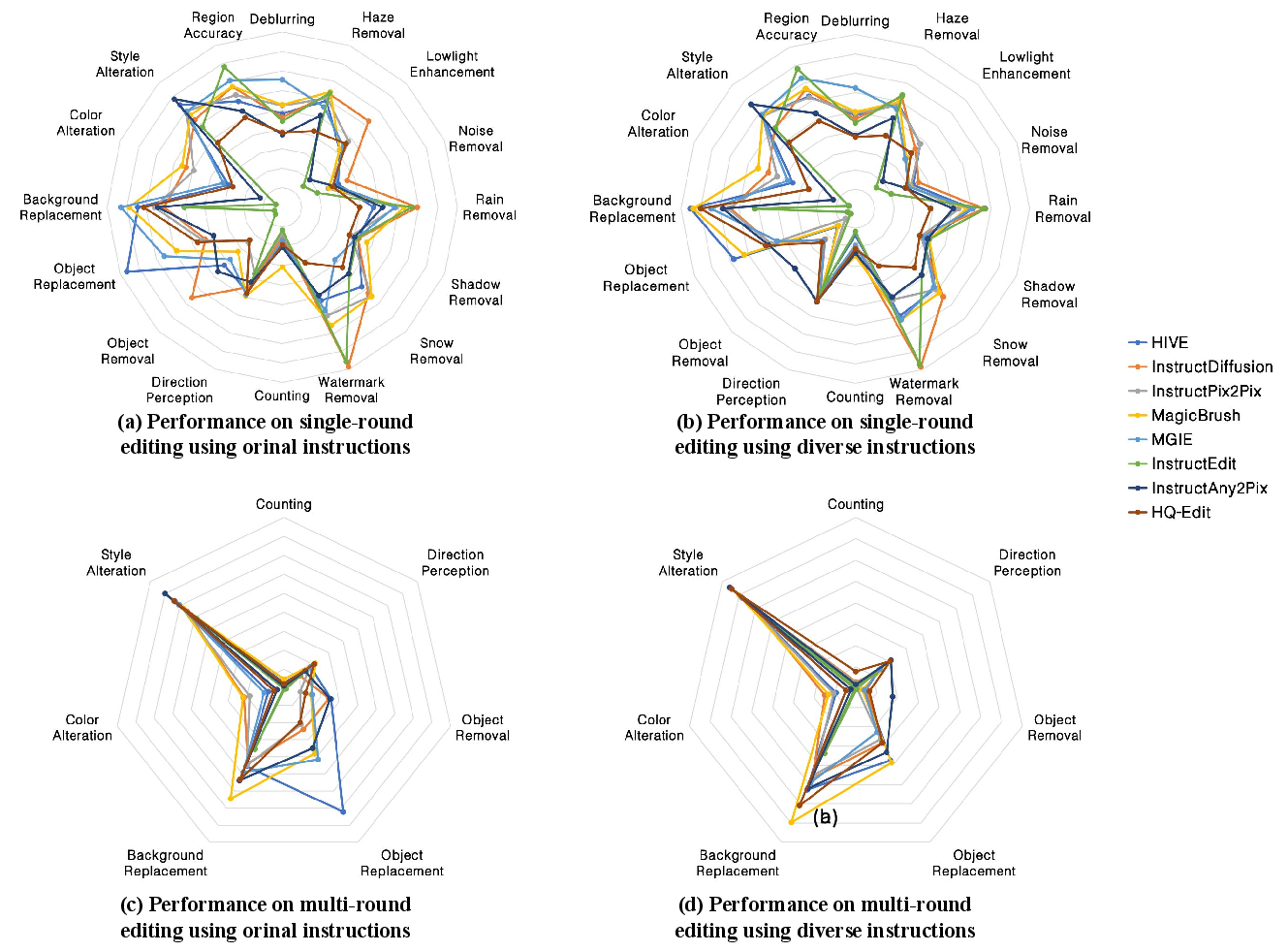
Figure 4: Radar chart comparison of black scores for original/diverse instructions; multi-round scores consistently drop, especially in semantic tasks.
Aesthetic quality, measured via CLIP-based MLP scoring, further declines with increased editing rounds, signifying the practical difficulty of maintaining perceptual fidelity under sequential edits.
Benchmark Robustness and Judge Consistency
A notable strength of the study is the rigorous judge consistency analysis. By deploying three independent multimodal LLMs (GPT-4V, Qwen3VL-8B, LLaVA-1.5-7B) as evaluation arbiters, the authors show that model ranking and relative performance trends are largely invariant to the choice of scoring LLM. This mitigates concerns about potential protocol bias and demonstrates that black’s conclusions are robust and scientifically transferable.
Insights, Limitations, and Future Directions
The paper systematically identifies current limitations in IIE models:
- Multi-round Instability: There is substantial evidence of error accumulation and semantic drift when performing sequential edits, particularly when instructions depend on prior outputs.
- Instruction Robustness: Paraphrased instructions degrade performance for models lacking strong language-image alignment, highlighting a need for more adaptive or linguistically-aware architectures.
- Category Bias: Global and scenery-oriented edits outperform animal/human/object-centric manipulations, suggesting easier localization and less ambiguity.
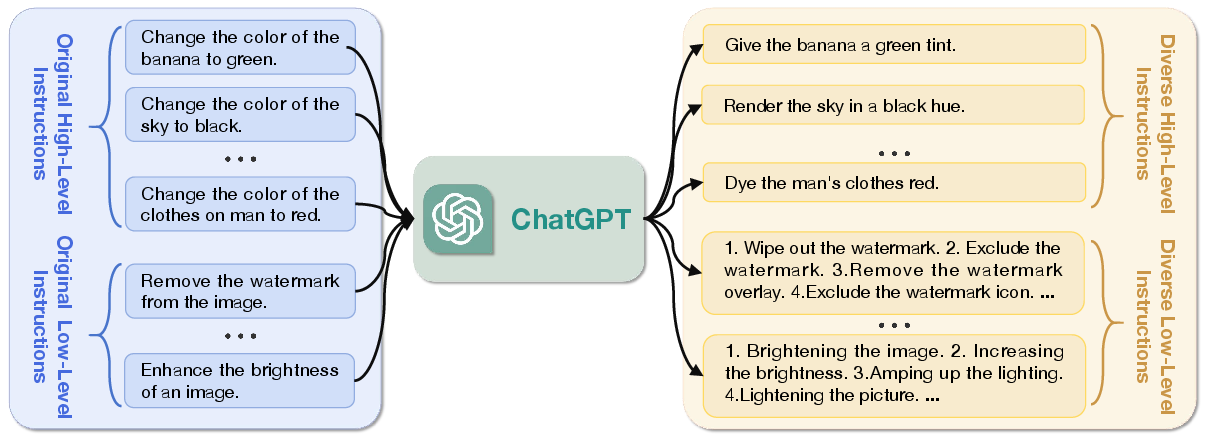
Figure 5: ChatGPT-generated diverse instructions amplify linguistic variability and stress-test instruction robustness.

Figure 6: Word cloud visualizations illustrate the linguistic breadth of single- and multi-round editing instructions.
The benchmark discussion emphasizes areas for future extension: robust handling of ambiguous/infeasible instructions, increased benchmark size for statistical power, diversity evaluation (for multi-modal or open-ended edits), and atomic-to-compositional transition in task complexity.
Practical and Theoretical Implications
Empirically, black provides actionable guidance for model selection by elucidating domain-specific strengths of contemporary IIE approaches. Practically, the benchmark is extensible, publicly available, and offers reproducible protocols for large-scale comparative assessments. Theoretically, black establishes a new standard for multi-dimensional, perceptually-aligned benchmarking in vision-language research, pushing the field toward more robust, generalizable, and human-compliant IIE systems. The consistent correlation between automated and human scores substantiates the use of advanced MLLMs as reliable proxies for model grading.
Conclusion
black is a comprehensive, technically rigorous benchmark that advances the state of evaluation in instruction-based image editing by systematically covering both single-round and multi-round editing, a wide span of semantic and low-level tasks, instruction diversity, and alignment with human perceptual judgment. By exposing existing weaknesses—particularly in multi-round robustness and instruction-following—and validating cross-model and cross-judge consistency, the benchmark sets a standard for transparent and reproducible assessment of future IIE models and architectures. It is expected to play a central role in fostering methodological innovation and accelerating the development of instruction-compliant visual editing systems.