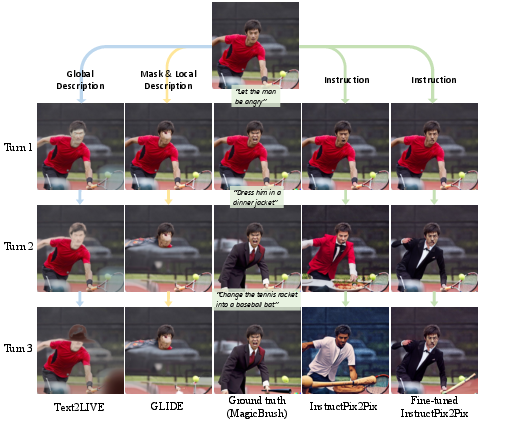
- The paper presents a comprehensive dataset with over 10K manually annotated triplets to advance instruction-guided image editing.
- It outlines a robust crowdsourcing methodology using Amazon Mechanical Turk to ensure diverse and high-quality editing sessions.
- Experiment results show fine-tuned InstructPix2Pix outperforms baselines in both mask-free and mask-provided scenarios with superior metrics.
MagicBrush: A Detailed Exploration of Instruction-Guided Image Editing
Introduction to MagicBrush
MagicBrush is introduced as the first large-scale, manually annotated dataset specifically created for instruction-guided real image editing. It was designed to cover a diverse range of scenarios, including single-turn, multi-turn, mask-provided, and mask-free editing. The dataset comprises over 10,000 manually annotated triplets (source image, instruction, target image) and seeks to overcome the limitations of existing methods, which often rely on zero-shot capabilities or synthetic datasets laden with noise. This new dataset supports the training of large-scale text-guided image editing models and demonstrates superior performance when fine-tuning state-of-the-art models like InstructPix2Pix.

Figure 1: MagicBrush provides 10K manually annotated real image editing triplets (source image, instruction, target image), supporting both single-turn and multi-turn instruction-guided editing.
Dataset Creation and Annotation Workflow
MagicBrush was constructed using a detailed crowdsourcing workflow executed on the Amazon Mechanical Turk platform. Initially, source images were carefully selected from the MS COCO dataset, emphasizing diversity across multiple object classes while mitigating over-representation issues, such as the prevalence of the person category. A three-stage workflow ensures high-quality annotations:
- Worker Selection and Training: Workers were trained rigorously, passing several qualifying rounds including quizzes and manual grading.
- Interactive Image Editing: Workers provided edit instructions and engaged interactively with the DALL-E 2 image editing platform. The process involved iterative trials with varied prompts and hyperparameters to achieve desired image outputs.
- Quality Control: Generated images underwent manual spot-checks for consistency and naturalness. Improperly edited sessions were eliminated to maintain dataset integrity.
The dataset comprises 5,313 sessions and 10,388 editing turns, supporting various scenarios. Furthermore, the inclusion of instructions in natural language allows for flexible interactions, such as iterative image edits.
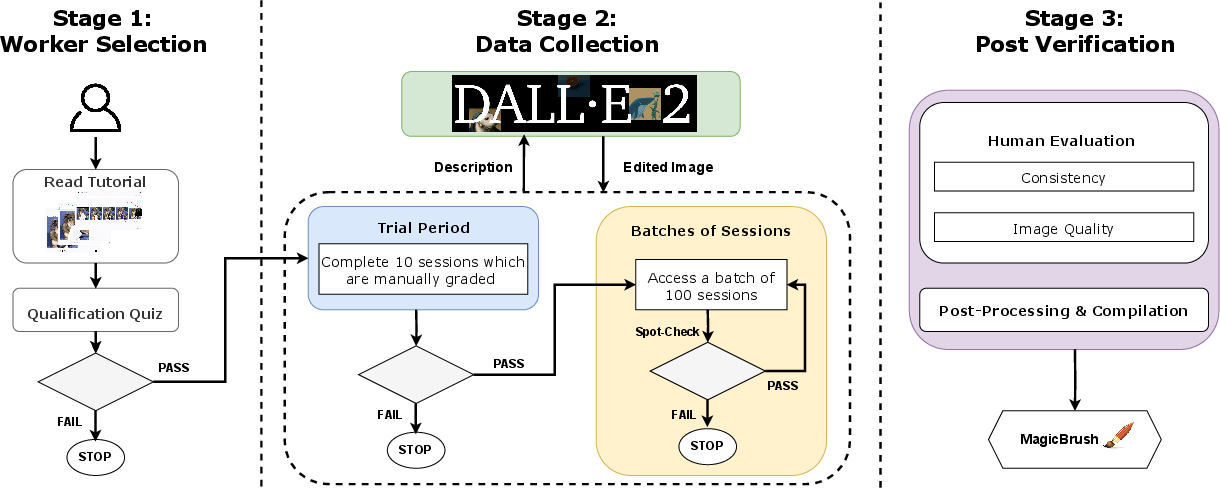
Figure 2: The three-stage crowdsourcing workflow designed for dataset construction.
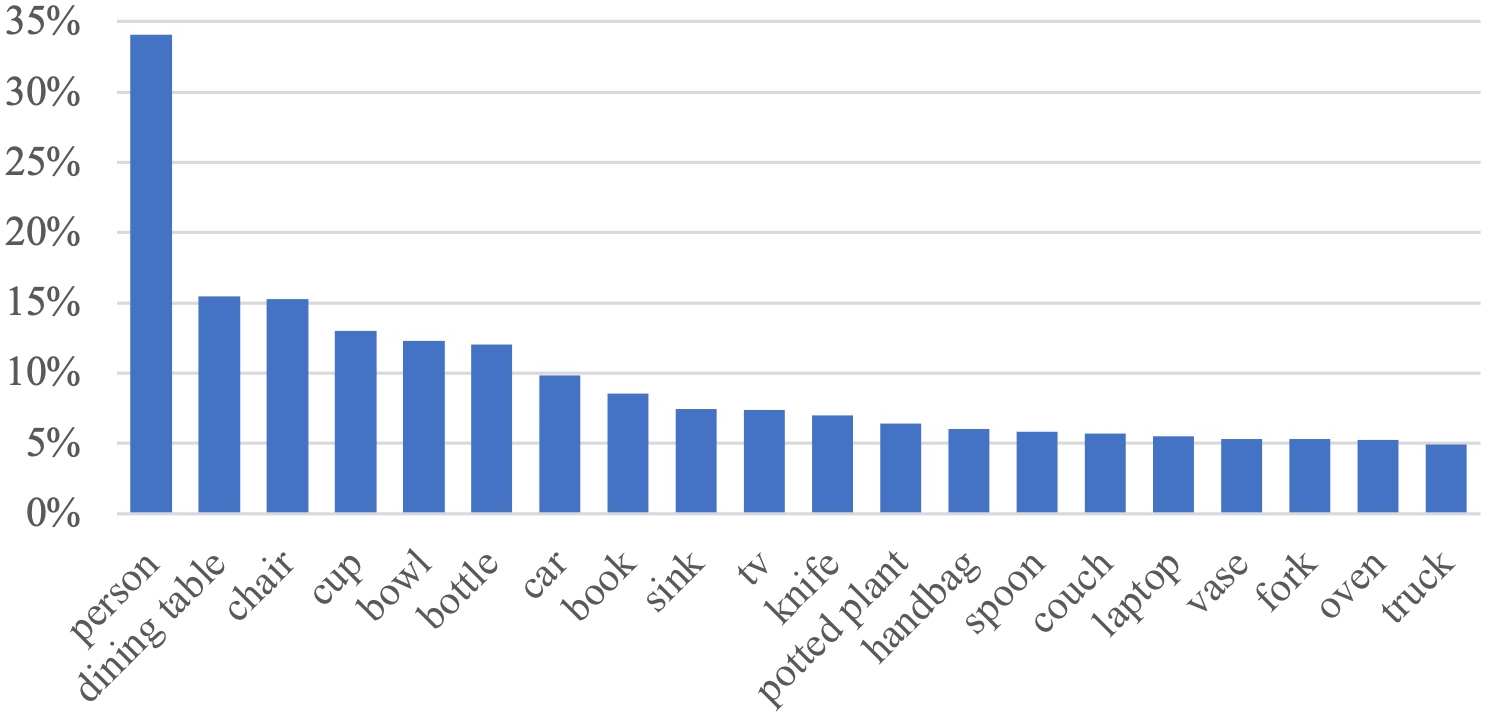
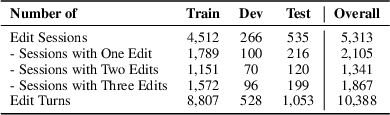
Figure 3: Top 20 object class distribution.
Evaluation and Experiments
MagicBrush's effectiveness was validated through extensive quantitative, qualitative, and human evaluations.
Quantitative Analysis
Several baselines, including Open-Edit, VQGAN-CLIP, and SD-SDEdit, were evaluated. Two main scenarios were considered—mask-free and mask-provided editing, further divided into single-turn and multi-turn settings:
Human Evaluation
Human evaluators assessed edited images through multi-choice comparisons, one-on-one comparisons, and individual evaluations based on a 5-point Likert scale.
- Multi-choice Comparison: Fine-tuned InstructPix2Pix achieved superior performance across both consistency and image quality aspects.
- One-on-One Comparison: Consistent results showed InstructPix2Pix, fine-tuned on MagicBrush, outclassed both strong baselines and the original model.
- Individual Evaluation: The 5-point scale further confirmed the superior performance of the fine-tuned model.
Implications and Future Directions
MagicBrush establishes a new benchmark for instruction-guided image editing, facilitating the development of more refined models that cater to real-world needs. The dataset helps bridge the gap between current methods and user expectations by enhancing image-editing models' precision, consistency, and overall quality of output. Future endeavors should focus on developing advanced models and evaluation metrics that align even better with human preferences.
The MagicBrush dataset is a critical advancement towards sophisticated, user-friendly image editing solutions in real-world applications, opening new avenues for development in instruction-following AI systems.