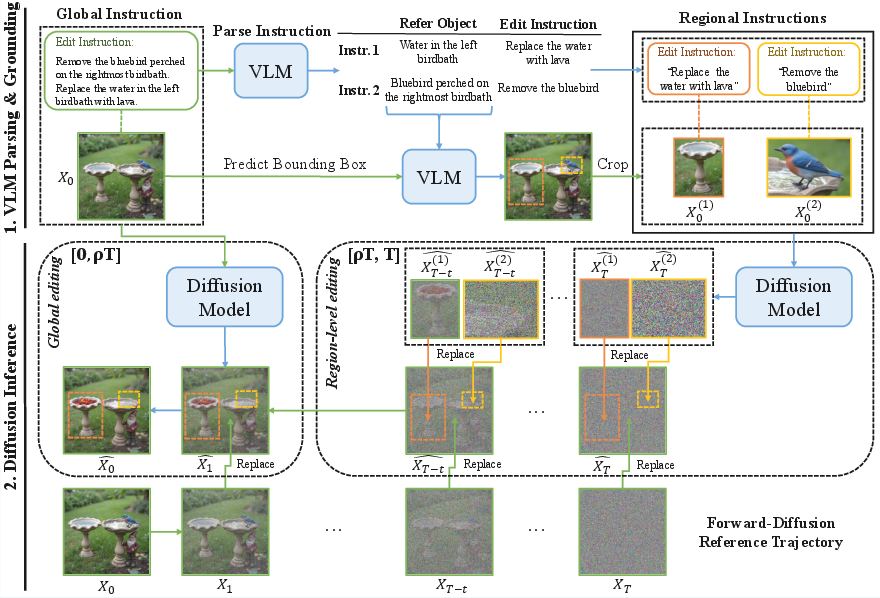
- The paper introduces MIRAGE, a training-free approach that decomposes global edit instructions into precise, region-specific subproblems to improve multi-instance editing.
- It presents MIRA-Bench, a novel benchmark designed to evaluate compositional editing with clear referential instructions and rigorous spatial and perceptual metrics.
- Empirical studies demonstrate significant gains in prompt following and consistency, highlighting MIRAGE's potential for robust, fine-grained image editing applications.
MIRAGE: A Framework and Benchmark for Multi-Instance Image Editing
Introduction and Motivation
Instruction-driven image editing with diffusion models has made substantial advancements, yet multi-instance and compositional scenarios remain an unresolved challenge. Existing state-of-the-art (SOTA) approaches, such as FLUX.2 and Qwen-Image-Edit, exhibit significant over-editing and spatial misalignment when given instructions that require fine-grained, instance-specific modifications in scenes containing multiple similar objects. This paper systematically analyzes these deficits and establishes rigorous evaluation procedures and baselines for this setting.
To address the scarcity of diagnostic benchmarks targeting fine-grained multi-instance editing, the authors introduce MIRA-Bench, a carefully constructed dataset that emphasizes referential clarity, compositional instruction complexity, and coverage of three or more similar instances per scene. Building upon the diagnosis provided by this benchmark, the authors present the MIRAGE framework—a training-free inference approach for multi-instance regional alignment via guided editing. MIRAGE decomposes global edit instructions into region-specific subproblems using vision-LLMs (VLMs) and orchestrates a multi-branch, parallel denoising strategy, with region-localization and latent fusion to enforce background integrity. Extensive comparative and ablation studies on both MIRA-Bench and RefEdit-Bench demonstrate consistent and significant improvements over current SOTA methods in prompt following, local consistency, and artifact suppression.
Benchmark Construction: MIRA-Bench
A core contribution is the MIRA-Bench dataset, specifically designed to stress-test the capacity of editing models in multi-instance, compositional setups. Dataset creation relies on an automated but carefully validated pipeline:
- Image Sourcing: Image prompts are generated to enforce 3-5 referable, visually distinct but semantically similar instances (e.g., five red apples on a table), using Qwen3-14B-Instruct for diversity and uniqueness checks across samples.
- Image Generation: Reference images are synthesized by FLUX.2 [Dev], followed by human curation for semantic clarity and visual quality.
- Instruction Generation and Localization: For each image, Qwen3-VL-8B produces precisely five edit instructions, spatially aligned to explicit regions or instances, with one-to-one mapping and referential clarity. The referring expression for each instruction is also extracted for target region localization.
- Instance Masks: Bounding boxes predicted by VLMs are refined into pixel-accurate masks using SAM2, supporting subsequent fine-grained evaluation.
- Evaluation Protocol: Editing models must perform all compositional instructions in a single forward pass. The resulting images are evaluated on instance-specific prompt following, background consistency, and perceptual quality.

Figure 1: MIRA-Bench generation pipeline using text-to-image synthesis, VLM-based instruction extraction, and segmentation models for target mask acquisition.

Figure 2: Example images and complex compositional instructions illustrating the challenge of instance-level multi-edit tasks present in MIRA-Bench.

Figure 3: MIRA-Bench sample triplets: original image, GT masks for target regions, and compositional edit instructions.
MIRAGE Methodology
MIRAGE is a training-free, modular framework that can be applied atop existing denoising-based image editing backbones. Its operation comprises the following components:
Empirical Evaluation
MIRAGE is extensively benchmarked against recent SOTA models—including FLUX.2, Qwen-Image-Edit, GPT-Image-1.5, and MagicBrush—on both MIRA-Bench and RefEdit-Bench.
Quantitative Results
MIRAGE consistently improves both Prompt Following (PF) and Consistency (Cons) metrics as measured by the EditScore framework:
Qualitative Analysis
MIRAGE systematically corrects failure modes where baselines either:
- Edit non-target instances due to ambiguous binding between referring expressions and image regions.
- Distort background structure or introduce visual artifacts through uncontrolled global modifications.
- Accumulate errors under sequential application of compositional edits, resulting in significant artifact propagation.

Figure 6: Sequential vs joint denoising; MIRAGE’s joint inference avoids accumulative artifacts and misalignment.

Figure 7: MIRAGE delivers improved local control and precise edit placement on additional MIRA-Bench examples.
Ablation Studies
Ablations are conducted on:
- Latent Replacement Interval (ρ): Best trade-off between semantic fidelity and lack of artifacts occurs for ρ in [0.6T,T]; strategy is robust except for extremely narrow or broad range settings.

Figure 8: Effect of ρ on artifact suppression and editing accuracy.
- Target/Background Latent Replacement: Retaining both region and background latent replacement is crucial; disabling either degrades local consistency or produces structural drift in non-edited regions.

Figure 9: Alternative latent replacement strategies and their impact on local/global consistency.
- Instruction Complexity: MIRAGE maintains stable performance as the number of compositional instructions increases, whereas baselines’ performance declines notably in both prompt following and consistency.
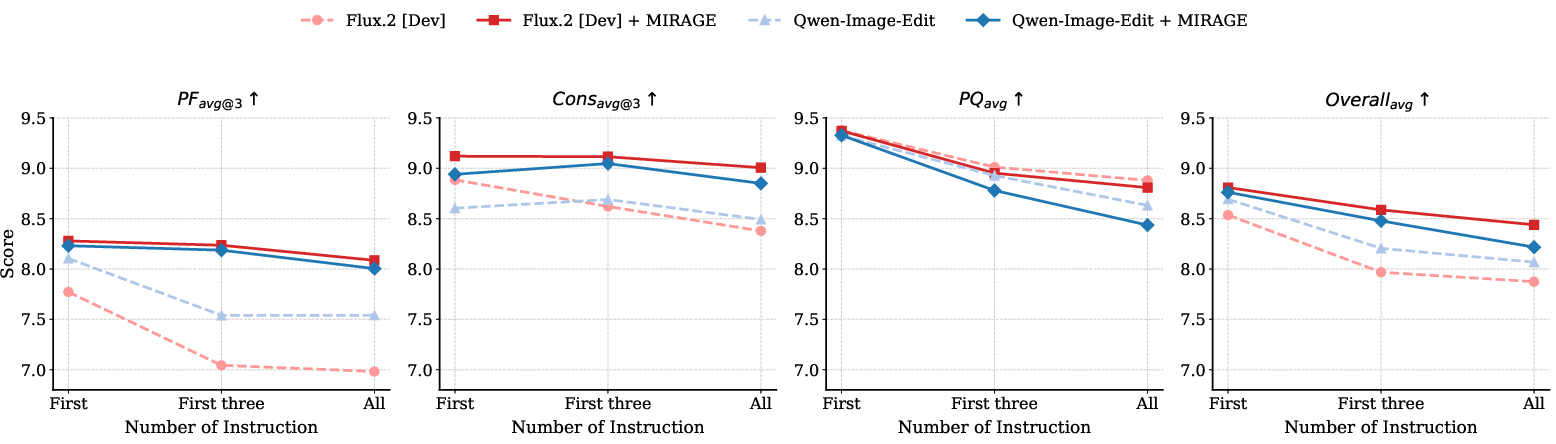
Figure 10: Performance as function of edit instruction complexity.
- VLM Choice Robustness: MIRAGE is robust to VLM selection for region localization, though stronger VLMs yield marginally better instance binding and PF scores.
Runtime and Efficiency
Despite the additional instruction parsing and region detection, the overall execution time of MIRAGE is on par or slightly less than its backbone model due to reduced latent region area during local diffusion. Sequential editing with naïve baselines is an order of magnitude slower and produces inferior results.
Limitations
The performance benefits of MIRAGE presuppose reliable referent extraction and spatial localization by the underlying VLM. Some perceptual degradation is observed on models that forcibly resample image resolution (Qwen-Image-Edit) as local crops may lose detail. Extensions to backbones with flexible input sizes (e.g., FLUX.2) mitigate this issue.

Figure 11: Blurring in MIRAGE outputs due to backbone-imposed image resampling.
Implications and Future Directions
The MIRAGE paradigm establishes that existing text-driven diffusion models are fundamentally under-constrained in fine-grained compositional editing, particularly under multi-instance regimes. The explicit regional alignment and denoising fusion strategy presented here is general, modular, and applicable to a variety of diffusion-based editing pipelines with minimal infrastructure cost.
Practically, this approach enables new classes of interactive visual editing applications which demand strict spatial and referential control even in complex, crowded scenes. Theoretically, decoupling global and regional conditioning via VLM-anchored reasoning advances the potential for precise multimodal control and highlights the utility of external semantic priors in structured image editing tasks.
As VLMs mature in granular object-level reasoning, frameworks such as MIRAGE will likely become the default interface for aligning natural language editing instructions with spatially explicit image regions. The continued expansion of highly compositional and referentially-dense benchmarks in this mold will be critical for driving forward SOTA models’ capabilities in complex scene understanding and manipulation.
Conclusion
This work introduces MIRA-Bench, a systematic benchmark for multi-instance compositional image editing, and MIRAGE, a training-free inference-time framework capable of addressing longstanding over-editing and misalignment errors in diffusion-based editing models. Through explicit regional reasoning, multi-branch denoising, and robust evaluation, the framework establishes new SOTA for instance-level editing accuracy, background consistency, and artifact suppression across complex scenarios. Adoption of MIRAGE sets a new standard for both model assessment and practical system deployment in instruction-guided visual content manipulation.