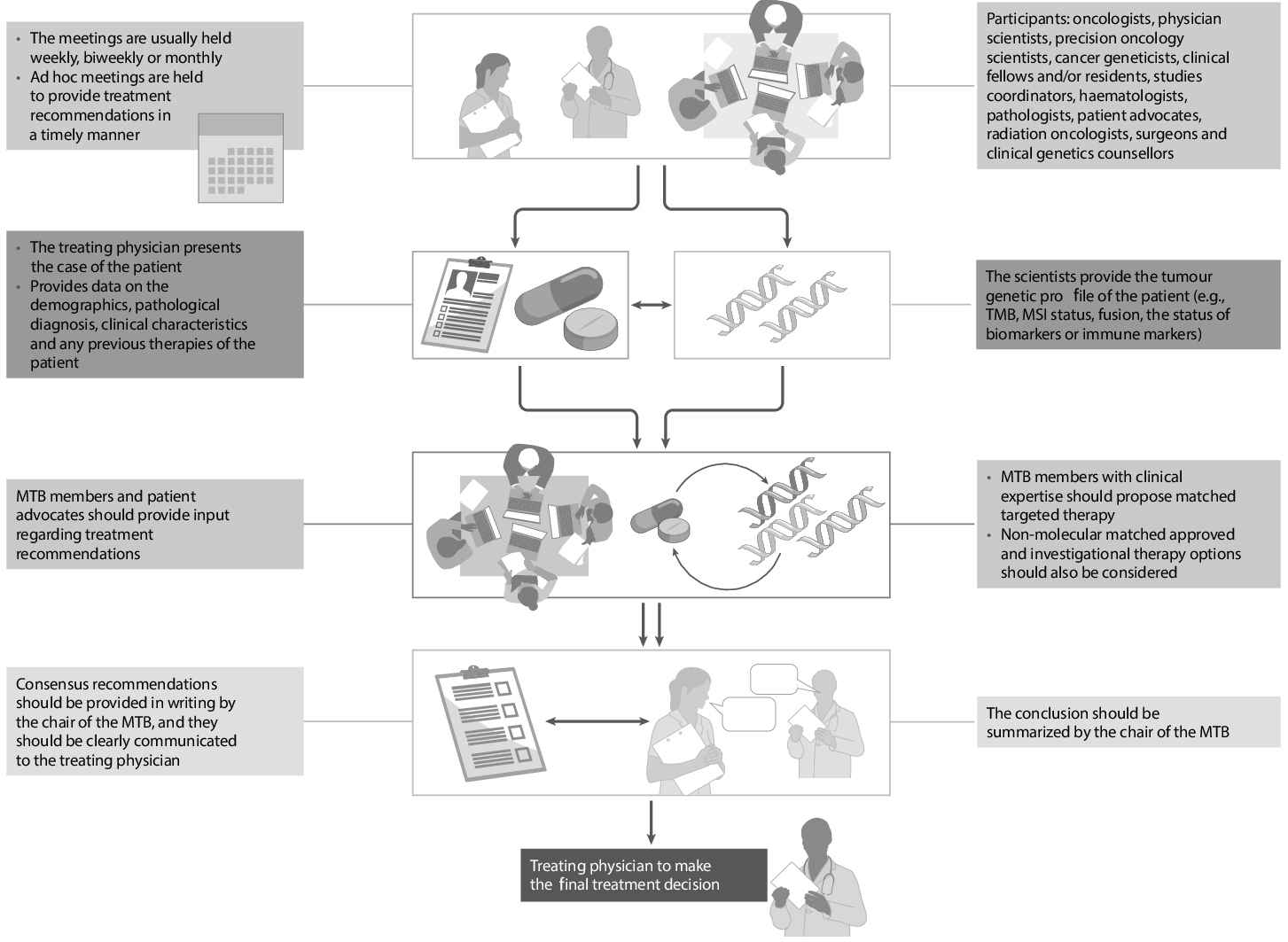
- The paper introduces a novel benchmark that replicates Molecular Tumor Board workflows using multimodal, longitudinal clinical data.
- It evaluates model performance across both multimodal and sequential tasks, demonstrating enhanced diagnostic accuracy with targeted tool integration.
- The study underscores the importance of foundation model augmentation in improving clinical decision-making in oncology.
MTBBench: A Multimodal Sequential Clinical Decision-Making Benchmark in Oncology
Introduction and Motivation
The development of Multimodal LLMs (MLLMs) and their integration into clinical AI research have highlighted the gap between existing QA benchmarks and the realities of clinical workflows, particularly those exemplified by Molecular Tumor Boards (MTBs). MTBs require agents to integrate heterogeneous and temporally distributed multimodal data—including pathology slides, IHC images, genomics, and longitudinal clinical events—to support high-stakes diagnosis, prognosis, and therapeutic decision-making. Traditional medical AI benchmarks fail to adequately capture this complexity, generally restricting evaluation to unimodal, static, and context-deprived queries.
The "MTBBench: A Multimodal Sequential Clinical Decision-Making Benchmark in Oncology" (2511.20490) directly addresses these shortcomings by introducing a new agentic benchmarking framework closely mirroring MTB-style workflows. The benchmark is designed to simulate realistic, multi-agent, and temporally evolving oncology decision-making, tightly coupled with expert clinical validation and tool-augmented agent architectures.
Benchmark Construction and Clinical Realism
MTBBench consists of two primary evaluation tracks: (1) Multimodal and (2) Longitudinal. In both setups, agents interact with patient cases in a staged, multi-turn dialogue, accessing only those files and data corresponding to the current clinical scenario. For the multimodal track, 26 cases with rich H&E, IHC, hematologic, and surgical data are drawn from the Hancock (HC) dataset, with 390 QA pairs representing fine-grained, expert-curated clinical tasks. The longitudinal track utilizes 40 deeply annotated cases from the MSK clinicogenomic cohort, focusing on outcome, recurrence risk, and therapy progression, with 183 expert-validated QA pairs.
A central feature is the dynamic, agentic workflow: agents must actively request information (e.g., slides, labs, timelines), and manage non-persistent, context-limited memory, reflecting the actual constraints and practices of MTB processes.
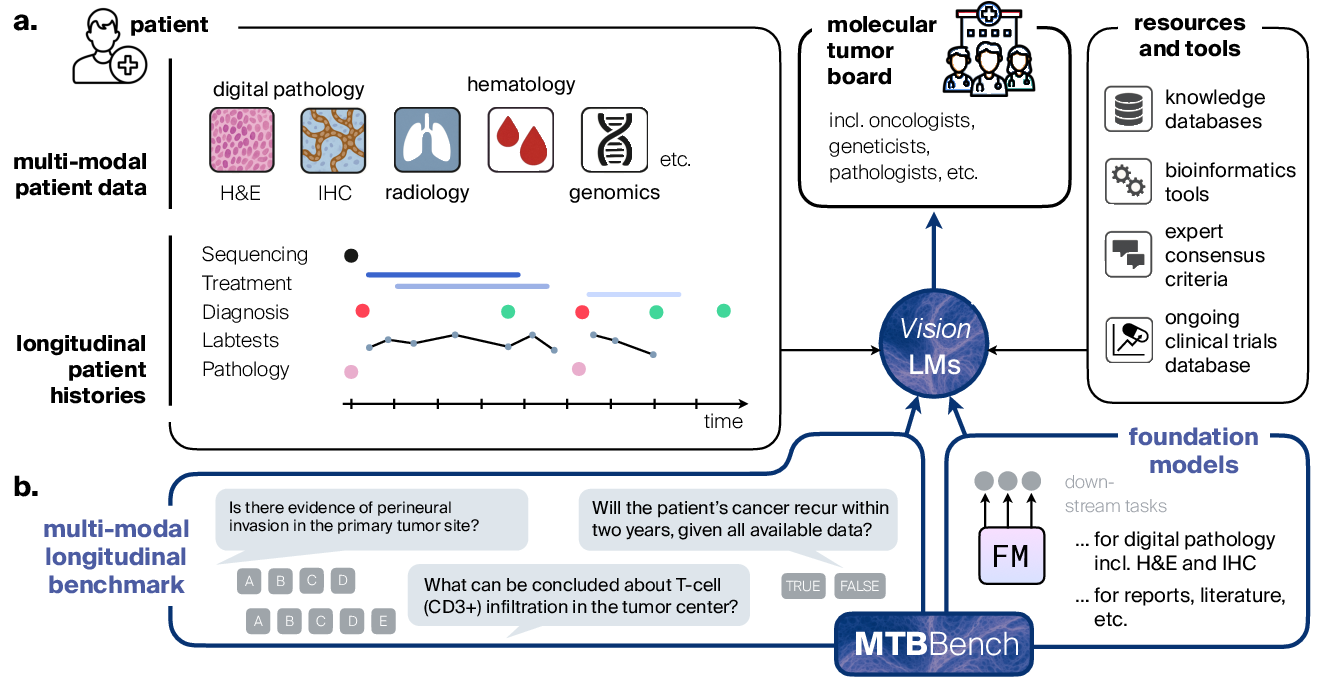
Figure 1: The MTBBench framework simulates MTB workflows, demanding integration of multimodal, longitudinal data, and benchmarking agentic decision-making with realistic file management and tool use.
Expert validation is built into the benchmark through a custom companion application, where clinicians review the exact context, access images and lab files, and provide feedback on each QA item. Inter-rater reliability metrics indicate high agreement and strong question quality, supporting the benchmark’s clinical validity.
A key innovation in MTBBench is its modular agentic framework, permitting integration with foundation model-based tools and structured databases. The benchmark framework exposes foundation models (FMs) for high-resolution digital pathology and IHC analysis as callable tools: agents can invoke CONCH for pathology images, UNI2+ABMIL for IHC quantification, as well as PubMed and DrugBank modules for literature and pharmacological knowledge. This design supports flexible, iterative, and context-aware tool use—an explicit reflection of MTB team dynamics, where specialists sequentially consult different data streams and domain experts.
Empirical analysis confirms that model performance (accuracy) is substantially correlated with active, targeted information access; models which request more data files (i.e., cross-modality integration) attain higher performance.
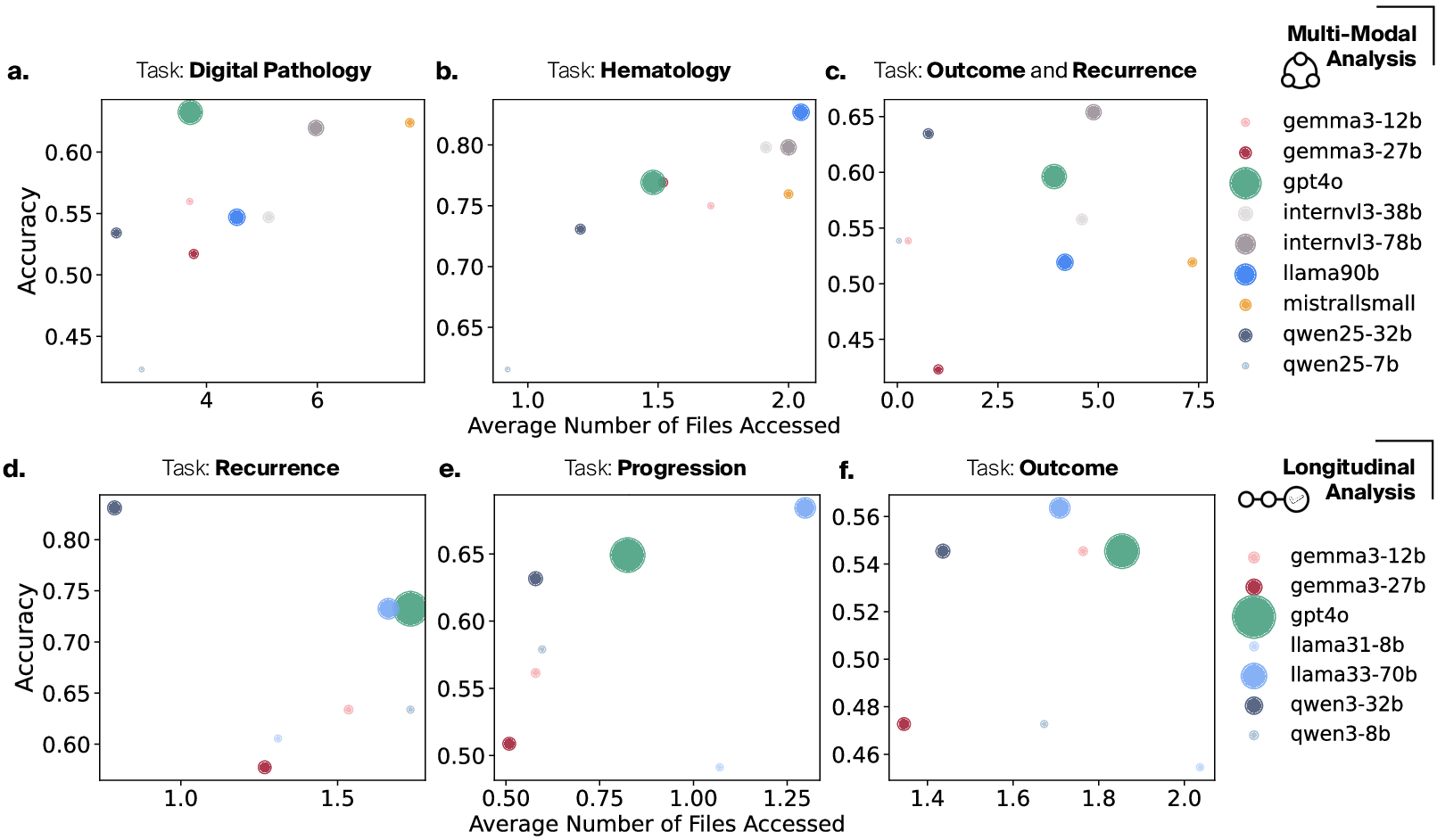
Figure 2: Model accuracy increases strongly with the number of files/modalities accessed per question across both multimodal and longitudinal benchmarks.
Experimental Findings
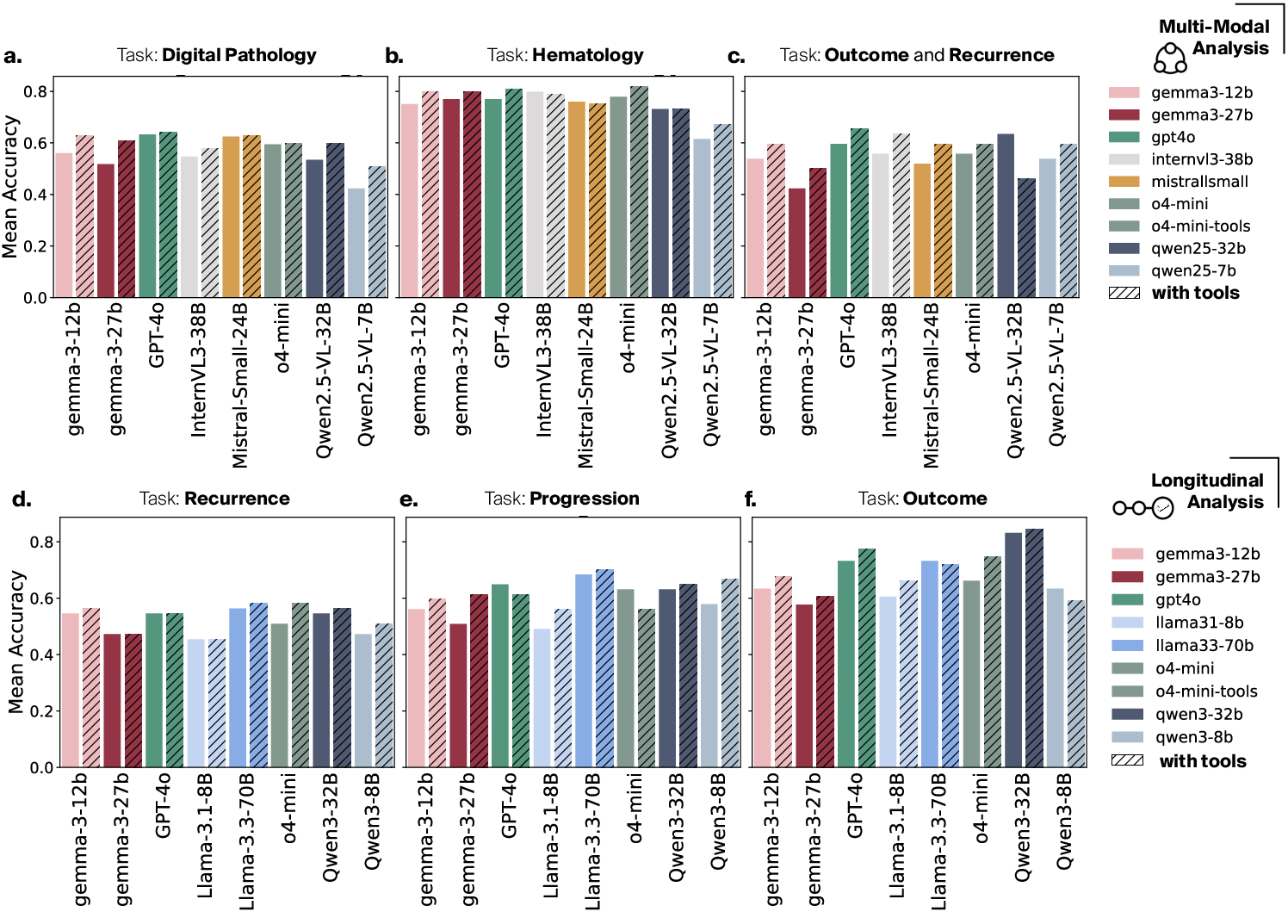
A systematic evaluation of both open and closed-source LLMs/VLMs—including GPT-4o, Gemma, Qwen, InternVL, and others—across both tracks reveals significant, previously unquantified performance gaps:
Qualitative analysis of agent traces demonstrates that correct answers are typically contingent on comprehensive file access and purposeful tool use, with robust grounding in explicit evidence. Models that shortcut information gathering, or fail to leverage cross-modal representations, exhibit high hallucinatory rates and reduced reliability—particularly in scenarios involving ambiguous, evolving, or conflicting clinical evidence.
Implications, Limitations, and Future Directions
The introduction of MTBBench represents a decisive shift from pattern-matching, static QA formulations toward agentic, decision-centric evaluation tailored to real-world MTB processes. This has several implications:
However, some limitations persist. MTBBench remains an offline and controlled testbed—it does not yet address open-ended, ambiguous cases, adaptive clarification, or the full real-time interplay characterizing live MTB deliberations. Most current FMs are not trained for multi-stage or temporally causal clinical inference, and the benchmark presently centers on head and neck oncology cohorts; extension to other organ sites, radiology, or omics modalities would further generalize its scope.
Conclusion
MTBBench (2511.20490) establishes a new standard for realistic, agentic evaluation of clinical AI in precision oncology. Its contribution is two-fold: first, a thoroughly validated, multimodal, and longitudinal benchmark mirroring MTB complexity; second, an extensible agentic framework demonstrating the value and necessity of tool-augmented, foundation model-enabled reasoning. As the field advances toward interactive, autonomously reasoning clinical agents, MTBBench provides a rigorous substrate for both comparative evaluation and the safe, scalable development of future AI collaborators in oncology.