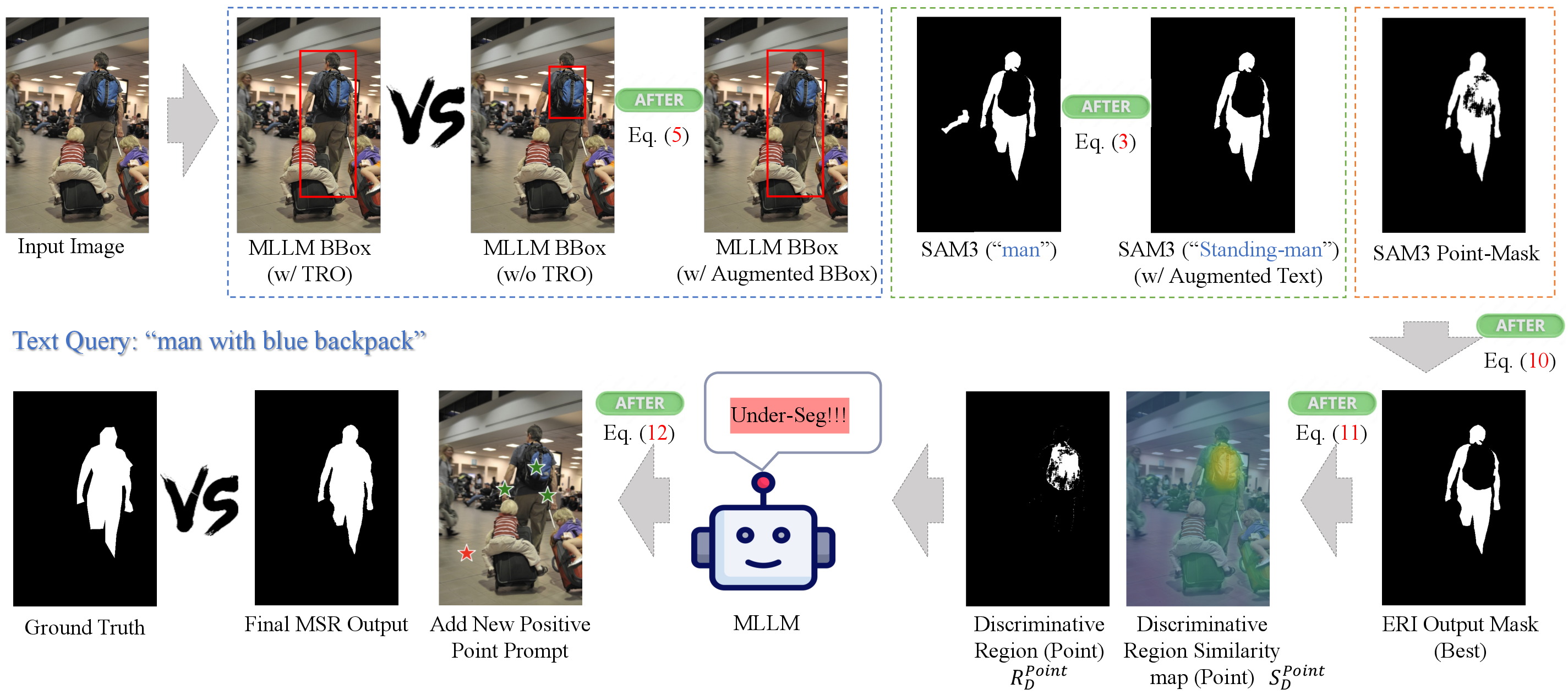
- The paper introduces a training-free framework that combines MLLM reasoning with DINOv3-driven mask refinement to address both explicit and implicit referring expression segmentation.
- It demonstrates state-of-the-art performance with 75.5 gIoU on RefCOCO and strong generalization across open-world scenarios, outperforming previous baselines.
- Component ablation confirms that the ERI and MSR modules are critical for enhancing segmentation accuracy and scalability without relying on annotated training data.
Tarot-SAM3: Training-Free SAM3 for Any Referring Expression Segmentation
Referring Expression Segmentation (RES) is a core vision-language task that aims to segment regions in images specified by natural language expressions. Traditional RES systems are heavily reliant on large annotated datasets and specialize either in explicit (direct object identification) or implicit (contextual, relational, or commonsense-based) expressions, impeding their scalability to open-world scenarios. Recent advances like Segment Anything Model 3 (SAM3) offer robust promptable concept segmentation but suffer when deployed directly for RES due to limited capacity for complex expressions and naive MLLM-SAM3 coupling, which over-relies on MLLM outputs and ignores mask refinement.
Tarot-SAM3 addresses these bottlenecks by proposing a training-free framework—jointly leveraging the reasoning capabilities of MLLM and object-aware feature coherence from DINOv3—to enable accurate segmentation for any referring expression, explicit or implicit.
Tarot-SAM3 Framework: System Design
Tarot-SAM3 employs a two-phase strategy:
1. Expression Reasoning Interpreter (ERI) Phase:
ERI decomposes the input expression into structured prompt types via reasoning-assisted options and evaluation-aware rephrasing. ERI stabilizes MLLM responses, extracting target object names, refer-object sets, and generates heterogeneous prompts for SAM3, including explicit text prompts, bounding boxes, and evaluation-guided rephrasings.
2. Mask Self-Refining (MSR) Phase:
MSR selects the optimal masks across prompt types and refines them via DINOv3-driven feature relationships. Discriminative regions are analyzed for over- or under-segmentation, and segmentation correction is performed through targeted modification of prompt anchors.
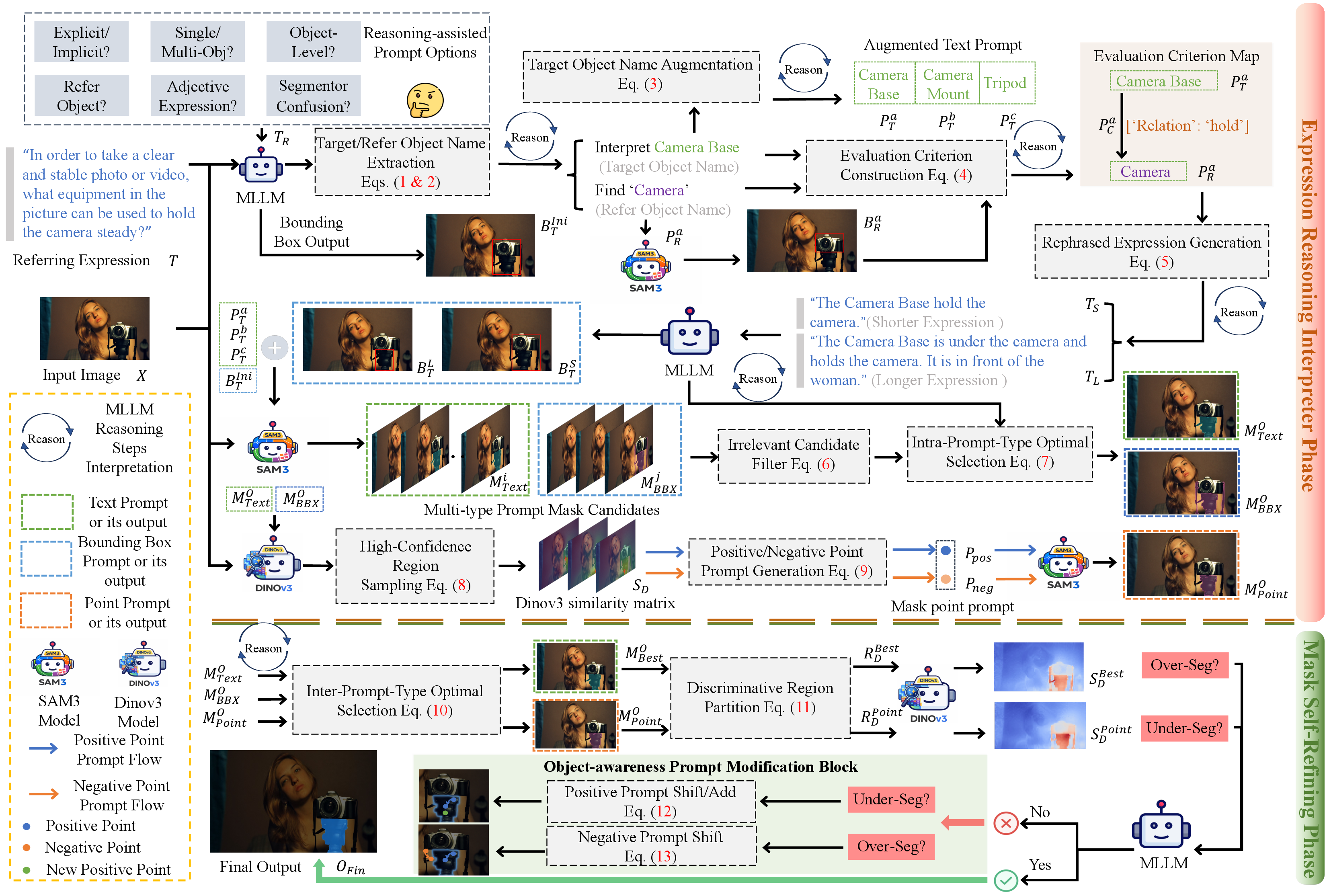
Figure 1: Overview of the Tarot-SAM3 framework, illustrating the ERI and MSR pipeline for training-free robust RES.
This architecture bridges linguistic reasoning and geometric segmentation, improving adaptability and visual consistency without task-specific training.
Explicit RES Benchmarks
Tarot-SAM3 is evaluated on RefCOCO, RefCOCO+, and RefCOCOg datasets. In zero-shot settings, Tarot-SAM3 with Qwen2.5-VL 7B backbone achieves 75.5 gIoU on RefCOCO testA, outperforming previous training-free baselines (e.g., EVOL-SAM3) by +1.8 and SAM3 Agent by +11.2.

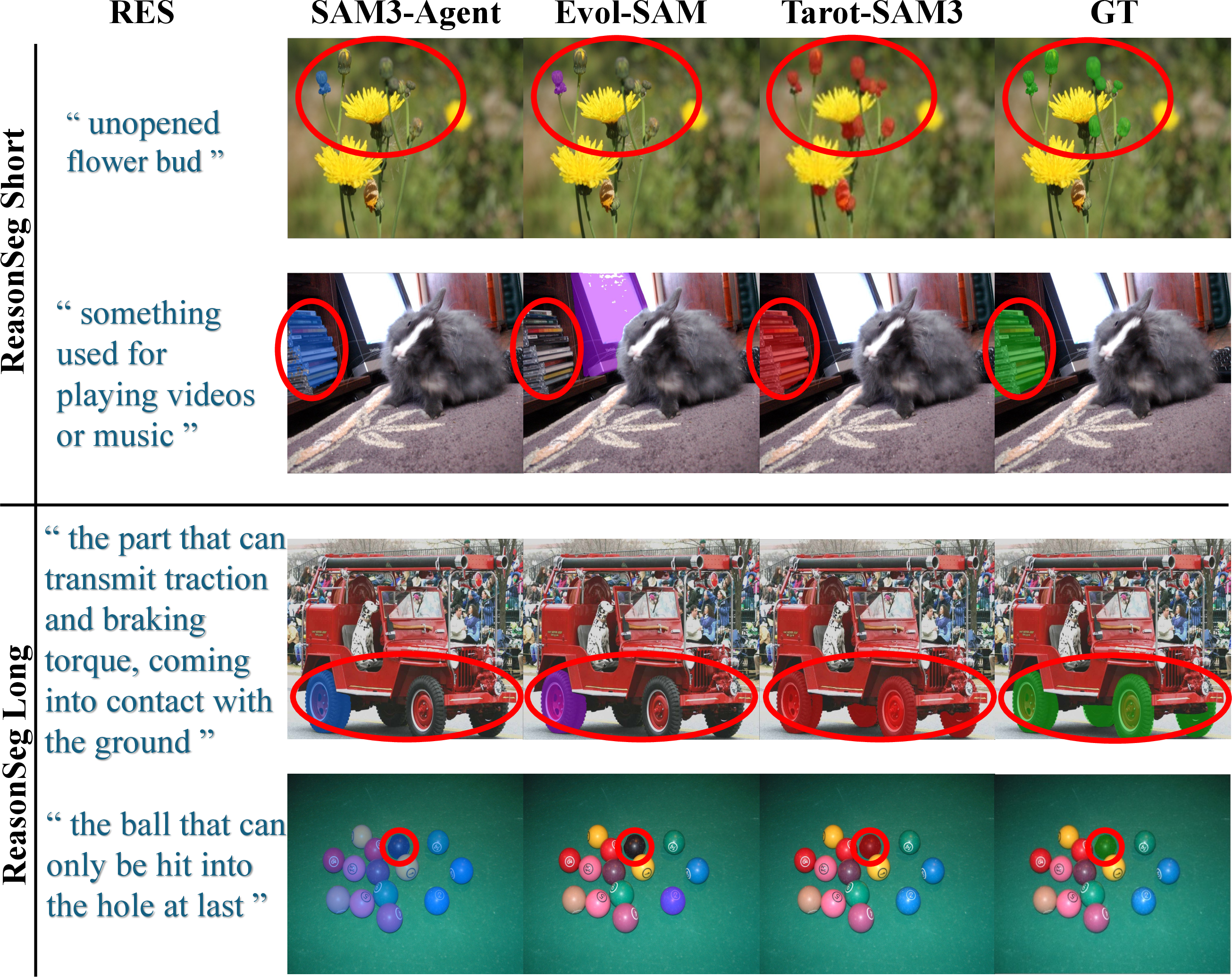
Figure 2: Example visualizations on explicit (left) and implicit (right) RES benchmarks, showing mask quality.
Implicit RES and ReasonSeg
On the ReasonSeg benchmark, Tarot-SAM3 consistently outperforms both dataset-specific fine-tuned and training-free competitors. For Qwen2.5-VL 7B, Tarot-SAM3 achieves 74.3 gIoU and 68.8 cIoU on the ReasonSeg test set—surpassing EVOL-SAM3 (+1.8), SAM3 Agent (+11.3), and even outscoring fine-tuned methods (SAM-Veteran: +11.7 gIoU).
Open-World Generalization
Tarot-SAM3 maintains superior robustness in open-world settings, including domain-shifted images (e.g., anime). This evidences strong generalization and adaptability beyond standard benchmarks.


Figure 3: Open-world visual comparisons and Tarot-SAM3 failure cases; left panel shows robust segmentation under diverse queries, right panel illustrates remaining ambiguity challenges.
Ablation Studies and System Component Contributions
Individual ablations highlight the vital contributions of the ERI and MSR modules:

Figure 5: Ablation visualizations show the impact of text prompt augmentation (left) and rephrased expression generation (right) on mask accuracy.
Practical and Theoretical Implications
Tarot-SAM3 demonstrates scalable, training-free RES. By integrating structured reasoning with prompt consistency filtering and feature-level refinement, it achieves closed-loop segmentation—mitigating reliance on MLLM interpretation and static SAM3 outputs. This architecture enables:
- Practical deployment for multimodal reasoning, visual dialogue, and embodied navigation tasks without annotated datasets.
- Theoretical advancements in unified processing of explicit/implicit expressions and prompt-adaptive segmentation.
Tarot-SAM3’s modularity enables rapid extension to future, possibly non-image domains such as video-based referring tasks and more complex multi-object reasoning.
Limitations and Prospective Directions
Despite achieving state-of-the-art in training-free segmentation, Tarot-SAM3 has residual limitations:
- Difficulty in spatially ambiguous queries (“far left crate”), resulting in occasional mis-segmentation.
- Challenges in region-level granularity for queries targeting sub-object regions.
Future work should emphasize accelerating inference, optimizing ERI and MSR for greater efficiency and generalization, and extending the framework to temporal and video-centric tasks, such as referring object tracking and sequential reasoning.
Conclusion
Tarot-SAM3 introduces a robust, training-free solution for universal referring expression segmentation, unifying ERI-driven multimodal reasoning with MSR-based mask refinement. Comprehensive experiments validate its superiority on explicit, implicit, and open-world benchmarks. Component-wise ablations confirm each module's effectiveness. This framework sets a new benchmark for scalable, annotation-free RES, with broad implications for future multimodal AI systems.