- The paper introduces a two-stage MGSD framework that combines supervised fine-tuning with on-policy self-distillation using a symbolic teacher.
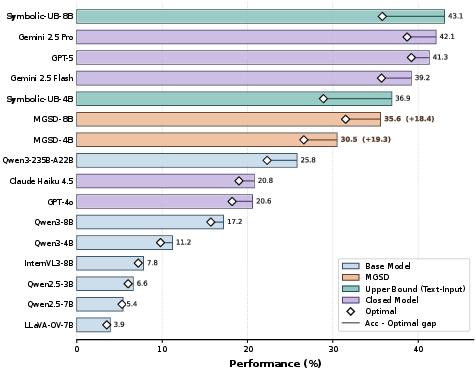
- MGSD achieves significant improvements, with planning accuracy gains of +19.3% on Qwen3-VL-4B and narrowing the gap to symbolic-input oracles by 6-7 points.
- Ablation studies confirm that both perception-oriented fine-tuning and symbolic guidance are essential to effectively bridge the visual-symbolic modality gap.
Modality-Gap-Aware Self-Distillation for Visual Spatial Planning
Introduction
The paper "Learning Visual Spatial Planning from Symbolic State via Modality-Gap-Aware Self-Distillation" (2606.06076) targets the intrinsic discrepancy between visual and symbolic planning — the perception–reasoning modality gap. This gap arises because models must not only accurately recover latent state representations from pixel-based visual observations but also perform multi-step reasoning over these recovered states to generate valid action sequences. Unlike symbolic planners, which operate over explicit and structured states, vision-LLMs (VLMs) must bootstrap both perception and reasoning, leading to compounded performance bottlenecks. The paper introduces Modality-Gap-Aware Self-Distillation (MGSD), a two-stage framework designed to iteratively bridge this gap using privileged symbolic supervision strictly during training.
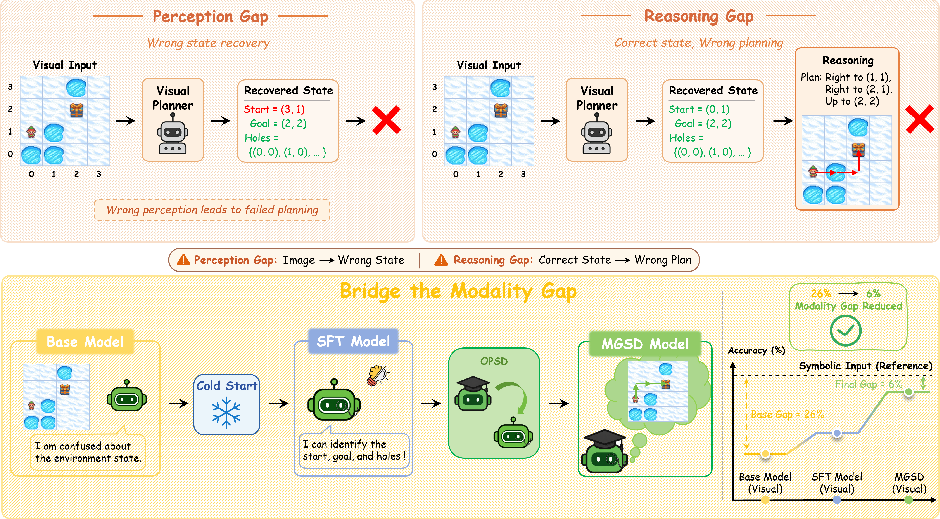
Figure 1: The modality gap in visual spatial planning, and the MGSD pipeline sequentially bridging perception and reasoning bottlenecks to approach symbolic upper bounds.
MGSD Framework
MGSD decomposes the interface mismatch into two training phases. The first, perception-oriented supervised fine-tuning (SFT), aligns the visual model with planning-relevant symbolic states, driving robust extraction of spatial relations and object properties. The second, symbolic-guided on-policy self-distillation (OPSD), leverages a text-only teacher that has access to the privileged symbolic state and reference plan. The visual student samples rollouts via image-conditioned prompts, and token-level feedback from the teacher supervises the student's own trajectories, directly localizing and correcting errors along the joint perception-reasoning axis.
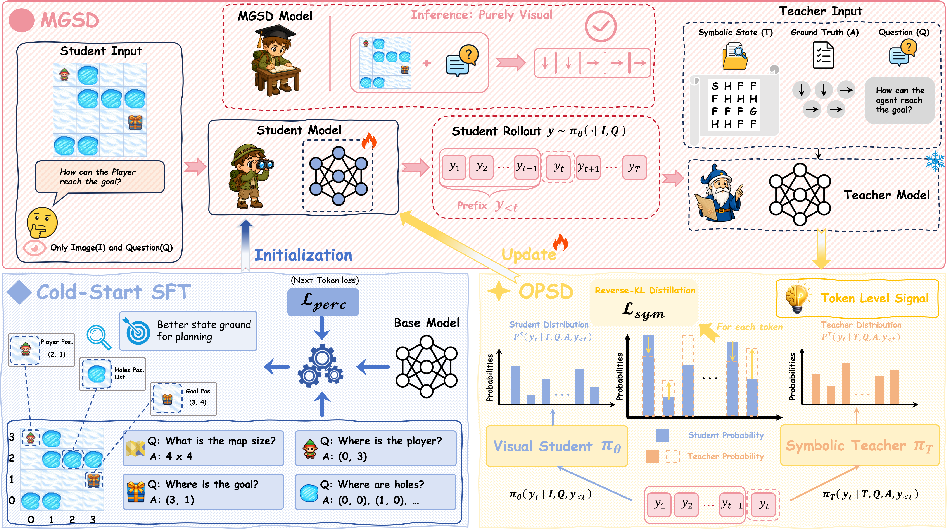
Figure 2: MGSD training: cold-start SFT for visual state grounding, followed by symbolic-guided OPSD where a symbolic teacher supervises visual student rollouts; inference is purely visual.
This dual-stage approach makes the distillation process explicitly modality-gap-aware: teacher and student do not operate over identical information, forcing knowledge to be transferred across representational boundaries, rather than merely imitated within the visual modality.
Experimental Results
MGSD is evaluated on three diagnostic environments: FrozenLake (safe grid navigation), Maze (topology-aware path finding), and MiniBehaviour (embodied decision-making with object interaction). Visual and symbolic ground-truths are comprehensively paired, allowing systematic ablation and diagnostic studies. The framework is instantiated on Qwen3-VL 4B and 8B backbones.
MGSD yields the following results:
Ablation experiments confirm both stages are indispensable: omission of cold-start SFT or privileged reference plans in the teacher sharply degrades performance. Swapping the frozen symbolic teacher for an exponentially moving (EMA) variant yields further degradation, supporting the hypothesis regarding stable distillation targets across modalities.
Diagnostic Decomposition
The paper introduces a rigorous diagnostic protocol, decoupling visual planning errors into perception (state recovery) and reasoning (planning on ground-truth symbolic states). The analysis reveals that simply maximizing perception fidelity (State F1) is insufficient; many base and SFT-only models, although recovering more accurate symbolic states, still underperform in optimal-path planning due to weak reasoning priors. MGSD uniquely attains competitive symbolic state recovery while simultaneously achieving the highest symbolic planning fidelity, producing the best end-to-end accuracy frontier.
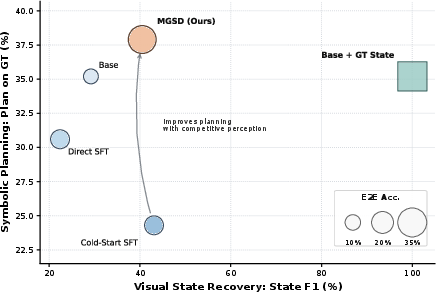
Figure 4: Bubble diagnostic: MGSD uniquely combines competitive perception (x-axis) and state-of-the-art symbolic planning (y-axis), maximizing overall end-to-end planning accuracy (bubble size).
Discussion and Implications
MGSD demonstrates that privileged symbolic annotation, used for dense, on-policy supervision during training, is an especially effective mechanism for narrowing the perception–reasoning modality gap in visual spatial planning. Unlike recent prior works that operate exclusively within the visual or latent domain, or that attempt to perform reward-driven RL with sparse signals, MGSD efficiently exploits a reliable symbolic teacher — but confines its use to the training regime, preserving practical deployment constraints.
Theoretically, MGSD decouples learning signals for perception and reasoning, leveraging the alignment induced by structured SFT to stabilize and localize subsequent on-policy distillation. Empirically, this protocol yields strong absolute and relative gains, even when compared to models with much larger parameter budgets.
Practically, the proposed diagnostic decomposition provides valuable granularity, guiding targeted improvements to both visual abstraction modules and downstream reasoning architectures. The primary limitation is the dependence on paired visual-symbolic training data, naturally suited to structured or simulated environments, but less readily available in unstructured or open-world domains.
Future Directions
Key open directions include:
- Extension to continuous control and partially observable settings;
- Relaxing the need for perfect symbolic training annotation, e.g., by utilizing noisy or pseudo-symbolic guidance;
- Scaling to real-world, long-horizon manipulation tasks with nontrivial perception ambiguity and distribution shift;
- Modular integration of state abstraction and relational reasoning, combined with advanced verification and intermediate supervision protocols.
Conclusion
MGSD establishes a concrete methodology for bridging the visual–symbolic planning gap by modulating dense symbolic supervision across the two core learning bottlenecks: perception and reasoning. The results robustly demonstrate that modality-gap-aware self-distillation is a scalable and effective approach for end-to-end visual planning. The framework delivers state-of-the-art performance on abstract grid and embodied spatial tasks, providing a foundation for future research in vision-grounded sequential decision making.