- The paper introduces DailyReport as a benchmark that deconstructs real-world search tasks into 3,546 expert-curated rubrics spanning 10 domains, focusing on instruction following, factuality, and rationality.
- It employs a cascade rubric methodology that measures agents’ performance with metrics such as instruction compliance above 0.96, while revealing significant challenges in factual accuracy.
- Empirical evaluation shows that even state-of-the-art agents fall short in user satisfaction, highlighting the need for improved evidence integration, source reliability, and domain-specific adaptations.
DailyReport: A Comprehensive Benchmark for Real-World Search Agent Evaluation
Benchmark Motivation and Design
The DailyReport benchmark addresses critical deficiencies in prior Search Agent (SA) benchmark design by grounding evaluation in authentic, rapidly evolving, real-world user demands. Unlike existing benchmarks that primarily target artificially constructed, domain-specific research tasks, DailyReport curates 150 open-ended search tasks from trending topics on major Western and Chinese social platforms, encompassing user-centered concerns such as education, public policy, consumption, and entertainment.
Each task is meticulously decomposed into multiple subtasks, annotated by human experts and hybrid LLM-based refinement, resulting in 3,546 rubrics that span 10 high-level domains and 35 fine-grained categories.
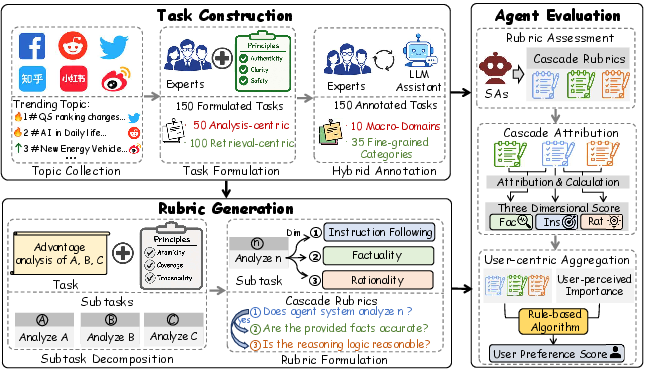
Figure 1: The DailyReport structure combines authentic daily search tasks and cascade rubrics for SA evaluation.
This design ensures coverage across both retrieval-centric (objective information extraction and synthesis) and analysis-centric (subjective analysis and reasoned argumentation) use cases, aligning benchmark focus with predominant, real-world user activity.

Figure 2: DailyReport covers 150 expert-curated tasks and 3,546 rubric items, spanning 10 domains—systematically reflecting genuine user demand.
Cascade Rubric and User-Centric Aggregation
DailyReport operationalizes evaluation via a three-dimensional, cascade rubric architecture:
- Instruction Following quantifies the agent's ability to parse and rigorously fulfill explicit user directives.
- Factuality is computed conditional on successful instruction following, measuring the accuracy of objective claims via external web validation, not parametric model knowledge.
- Rationality assesses the logical coherence and analytical soundness of agent responses, focusing on endogenous report structure and analysis, decoupled from factuality.
User-centric aggregation offers additional interpretability and real-world relevance by weighting subtasks according to user-perceived importance; final outputs include both granular dimensional scores and a scalar user preference rating reflecting overall perceived utility.
Empirical Evaluation of State-of-the-Art Agents
The paper delivers a large-scale evaluation—using the DailyReport benchmark—of 17 agentic systems, spanning deep research agents (DRAs), search-augmented LLMs, and LLMs orchestrated through frameworks like Claude Code.
Key findings:
- Instruction Following is robust across all leading agents: all systems exceed 0.96 on this metric.
- Factuality is the primary bottleneck. Even top models underperform, indicating persistent susceptibility to hallucination and unreliable claim-evidence alignment.
- User Preference scores remain sub-threshold: even the best-performing GPT-5.4 configuration achieves only 2.89/4, falling short of the "acceptable" level defined as 3. This result holds across all system types, strongly indicating open challenges in securing practical, consistently satisfactory user outcomes.
- Additionally, subtask pass rates (full rubric satisfaction) are low, and performance disparities amplify when agents miss critical, high-importance subtasks, further suppressing user preference scores.
Task-Type and Domain Effects
Performance breakdown by task-type reveals nuanced findings:
- Retrieval-centric tasks drive higher factuality scores, exploiting the relatively objective nature and verifiability of such information needs.
- Analysis-centric tasks yield improved instruction following and rationality, leveraging LLM endogenous strengths in discourse and explanatory synthesis, but expose factuality weaknesses due to scattered, heterogeneous evidence and higher potential for unsupported assertions.
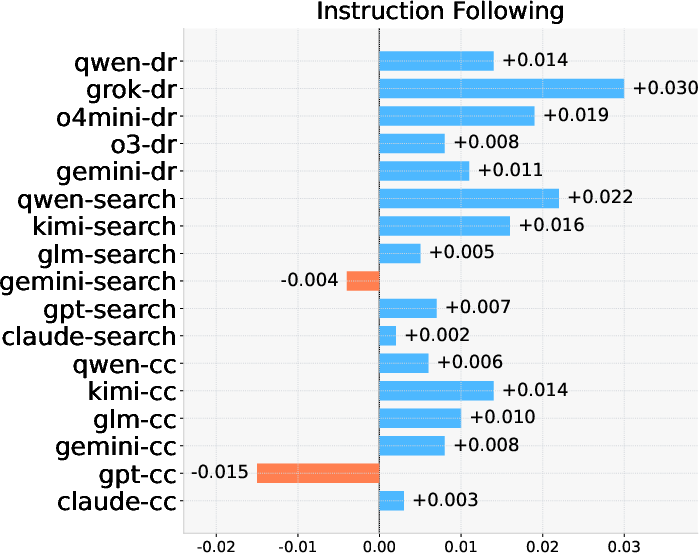
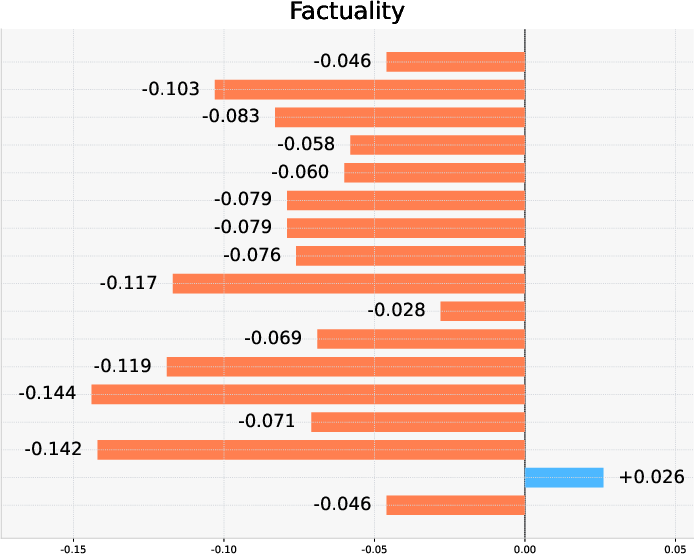
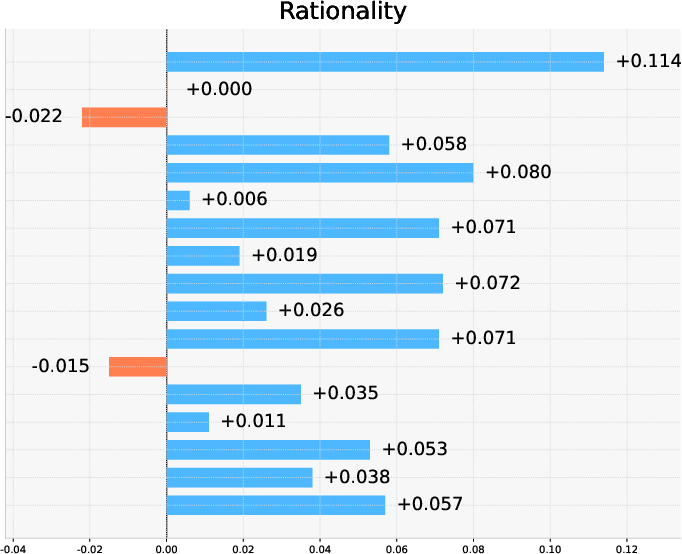
Figure 3: Differential model performance in instruction following, factuality, and rationality by task type, revealing distinct error surfaces.
Domain heatmaps emphasize the variability of agent capability. Systems perform best on structured domains with accessible authoritative sources (e.g., Politics & Law, Industrial Economy), but deteriorate substantially on dynamic or subjective topics (e.g., Sports, Entertainment) due to both the instability of available evidence and increased subjectivity.
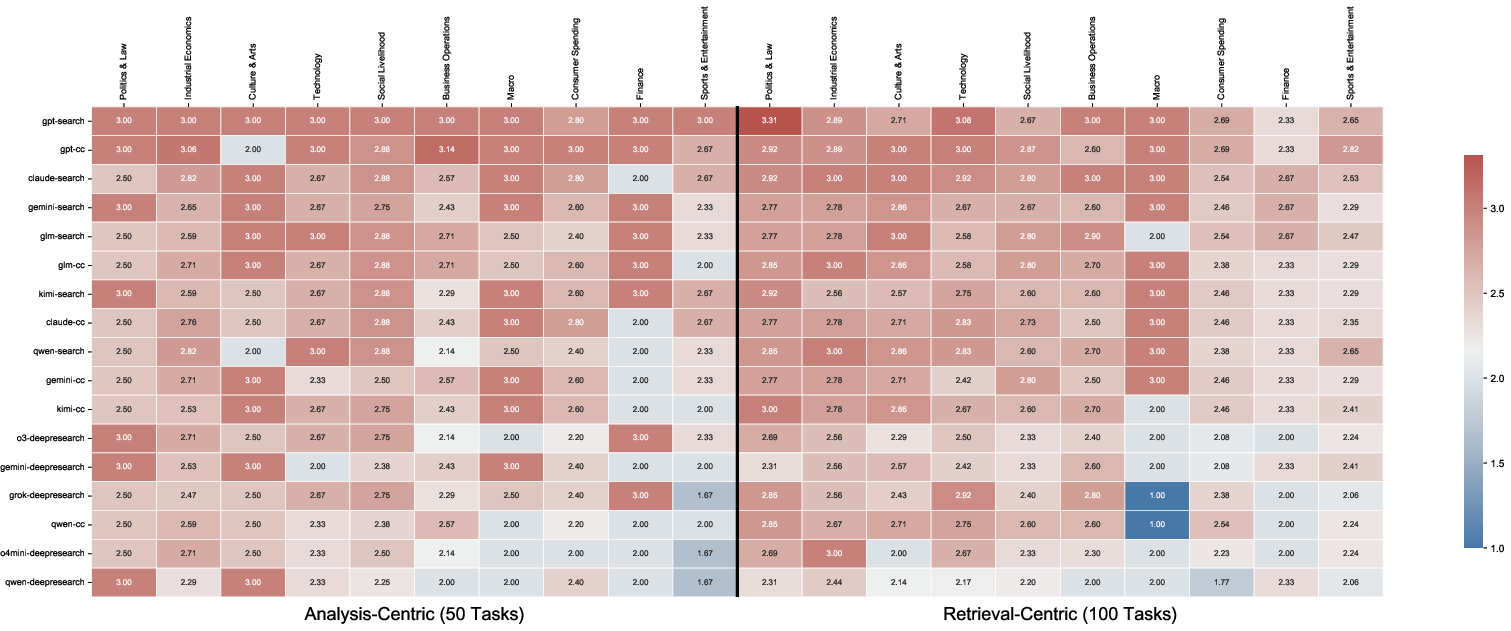
Figure 4: User preference scores across domains show highest satisfaction in structured, authoritative fields and consistent underperformance in rapidly-evolving or subjective areas.
Diagnostic Trace Analysis and Robustness
Solving-trace dissection demonstrates that higher quality is strongly associated with more extensive, sophisticated tool-call usage—especially iterative retrieval and evidence gathering. However, even when explicit references are provided, reference-claim consistency and reference accuracy remain weak links. Citation does not guarantee validity or proper claim grounding, highlighting a key vulnerability in current agent architectures.
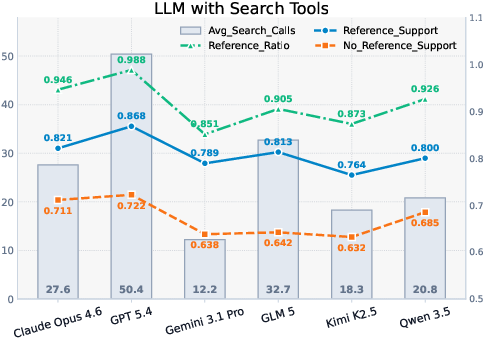
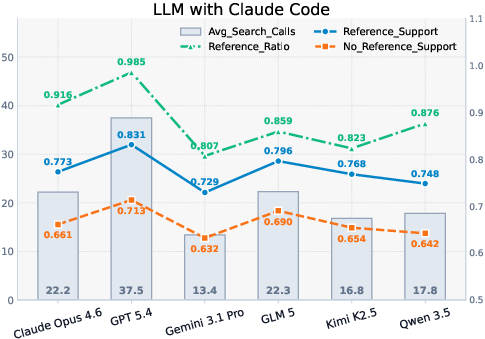
Figure 5: Analysis of search calls, citation rates, and claim/reference factual support, quantifying model weaknesses in evidence reliability and citation alignment.
Notably, evaluation stability analyses confirm that DailyReport yields highly reproducible results: repeated trials across representative models exhibit minimal score variance, supporting its value as a robust research asset.
Judge model ablation establishes Gemini-3-Flash as an accurate, cost-effective evaluator, outperforming GPT-5.2 and Gemini-2.5-Pro for alignment with human ground truth.
Implications and Recommendations
The DailyReport benchmark systematically demonstrates that while SAs can reliably execute explicit instructions, fundamental limitations persist in claim grounding, evidence alignment, and nuanced, user-centered synthesis—particularly in open-ended or subjective domains. Results underscore the need for future SA development to prioritize:
- Integration of active, multi-angle verification and cross-source validation within agent pipelines.
- Enhanced citation-consistency checking and source reliability assessment.
- Improved modularity for hybrid architectures (incorporating specialized module orchestration without code-oriented overhead).
- Domain-specific adaptation to account for evidence stability and source heterogeneity.
The practical implication is clear: agentic systems cannot yet be trusted to autonomously satisfy the majority of authentic daily information needs without significant risk of misalignment, inaccuracy, or user dissatisfaction.
Conclusion
DailyReport establishes a new standard for evaluating web-powered SAs by aligning tasks with real-world user demands, rigorously disentangling evaluation dimensions, and centering evaluation on user experience and interpretability. Reliable empirical benchmarking of frontier SAs reveals robust instruction compliance but persistent deficits in factual accuracy and real-world user alignment. This work concretely diagnoses the technical and methodological frontiers for next-generation research agents, incentivizing further advances in search-intensive, user-aligned agentic reasoning and evaluation.