- The paper presents a rigorous benchmark that isolates agent harness design from underlying LLM capabilities by integrating cost metrics into coding agent evaluations.
- It demonstrates that proper adapter design boosts Pass@1 from 19.1% to 73.4% while reducing patch application failures to below 1.5%.
- The framework uses a standardized Docker-based adapter protocol to enable fair, scalable comparisons across diverse models and multilingual coding tasks.
Introduction and Motivation
Claw-SWE-Bench introduces a rigorous, harness- and cost-aware framework for evaluating agentic coding systems on realistic software engineering tasks. The benchmark addresses a major confound in existing SWE-bench-style evaluations: entanglement of underlying LLM capabilities, harness implementations, and task content. Prevailing benchmarks report aggregate performance metrics (e.g., Pass@1) from monolithic systems, obscuring how harness design, model variation, and evaluation resource usage affect observable agent competence. Claw-SWE-Bench systematically isolates the harness—termed "claw"—as a controlled experimental dimension. It further integrates cost metrics directly into agent evaluation, bridging the gap between methodological rigor and practical deployability.
Protocol Architecture and Adapter Abstraction
The Claw-SWE-Bench methodology is structured around a two-layer separation of concerns. The lower layer introduces a standardized adapter protocol that serves as a contract between individual harnesses—whether purpose-built or general agents, such as OpenClaw—and the benchmarking lifecycle. This protocol consists of a set of lifecycle methods (e.g., create_agent, send_task, backup_session, delete_agent, get_docker_args), allowing arbitrary harnesses to interface with shared orchestration infrastructure in a Docker-based, task-isolated environment.
This design resolves the contract mismatch between agentic tool usage and SWE-bench’s patch-based scoring regime. By constraining agent actions to file-level modifications within a containerized repository and extracting solution patches directly from the resulting repository state, the protocol ensures agent outputs are unambiguously scorable and comparable (Figure 1).
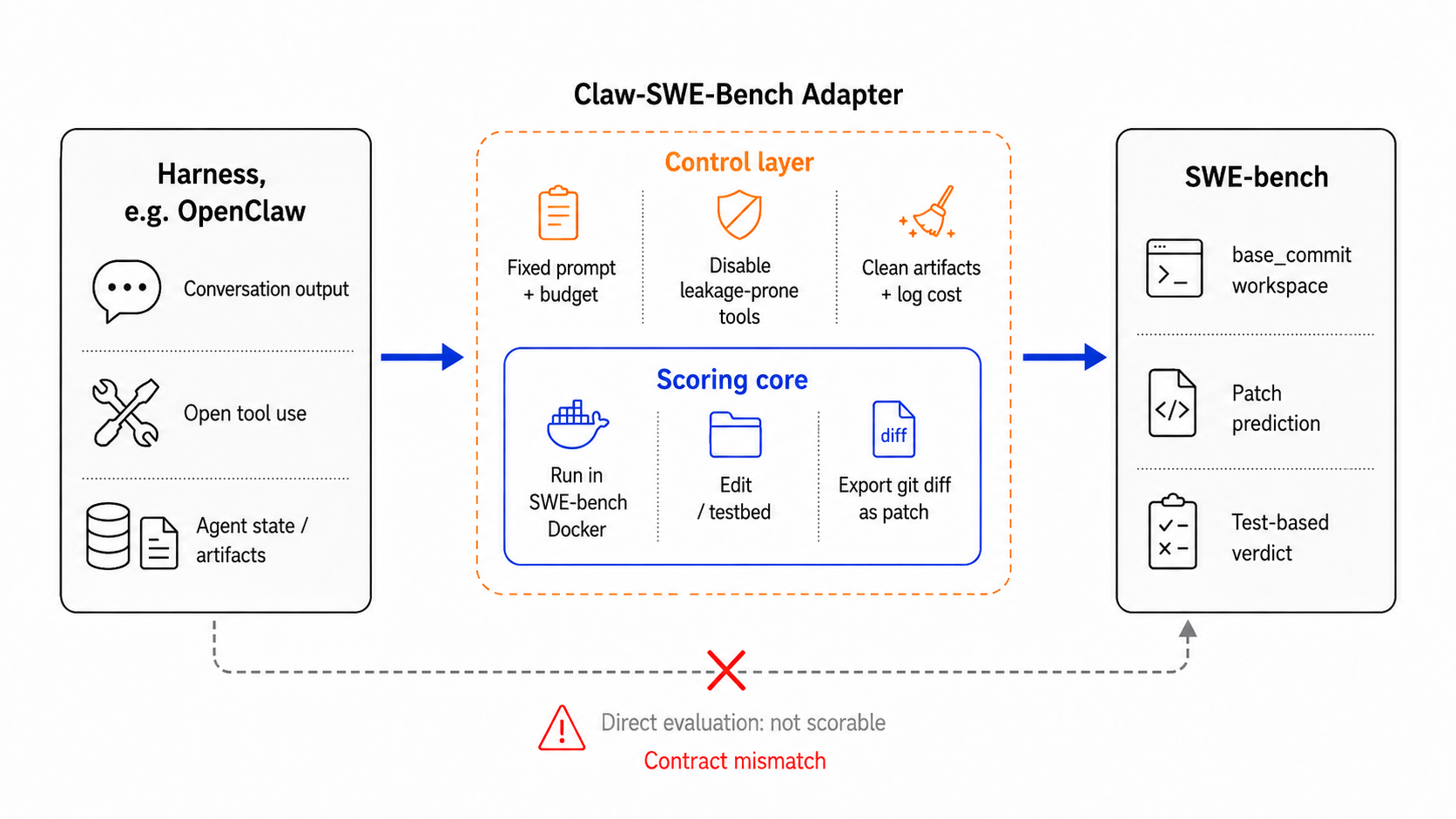
Figure 1: Contract mismatch between OpenClaw-style harnesses and SWE-bench. The adapter converts a general agent interaction into a SWE-bench-scored patch prediction, while outer controls ensure fairness, comparability, and traceable cost.
Benchmark Construction and Replicability
Claw-SWE-Bench assembles a diverse, multilingual workload consisting of 350 unique GitHub issue-resolution tasks, spanning 8 programming languages and 43 repositories. The dataset unifies 300 cross-language tasks from SWE-bench-Multilingual with 50 human-validated Python instances from SWE-bench-Verified-Mini, yielding broad coverage for repository-level coding evaluation.
To facilitate rapid experimentation under resource constraints, Claw-SWE-Bench Lite provides a cost- and rank-calibrated 80-instance subset. The Lite selection process is formulated as a binary optimization over resolve-rate parity, stability of pairwise rankings, and resource cost, calibrated across 17 columns of (model, harness) combinations to ensure robust cross-system, cross-language comparability. The resulting Lite-80 subset maintains within 0.4 percentage points of full-suite Pass@1 over all calibration axes, while reducing end-to-end evaluation cost by ~77% (Figure 2).
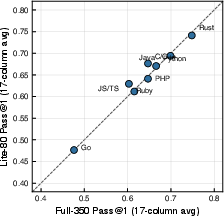
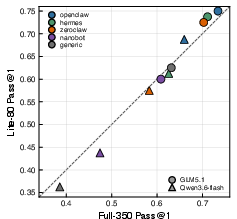
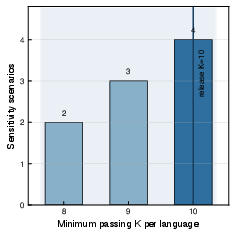
Figure 2: Lite-80 parity with full-350. (a) Per-language comparison between full-350 and Lite-80 Pass@1, averaged uniformly over 17 calibration columns. (b) Cross-claw Pass@1 comparison between full-350 and Lite-80 over 5 claws × 2 shared models. (c) K-sweep sensitivity envelope; the minimum acceptable K falls in [8,10] across scenarios, and the release uses the conservative stable point K=10.
Experimental Results
Adapter Effectiveness and Harness Impact
A central experimental result is the quantification of the adapter’s influence on agent scorable performance. A bare OpenClaw adapter that simply emits a unified diff in its output achieves only 19.1% Pass@1, with a 69% patch application failure rate due to format fragility. In contrast, the full adapter, which applies edits in-context and extracts patches from actual repository state, achieves 73.4% Pass@1 with <1.5% application failures, confirming the necessity of proper adapter design for realistic SWE-bench evaluation.
Cross-Axis Variation: Models, Harnesses, and Accuracy-Cost Trade-offs
Claw-SWE-Bench enables precise separation of model and harness effects. On a fixed OpenClaw harness across nine competitive LLMs, Pass@1 spans 48.6% (Seed 2.0-mini) to 78.0% (GPT 5.5), with total evaluation cost differing by over two orders of magnitude—e.g., $8.2 for DeepSeek-V4 Flash vs.$1,399 for GPT 5.5. This demonstrates that cost and model accuracy are only weakly coupled and must be reported jointly.
Variation across harnesses is equally pronounced when model is held constant. For GLM 5.1, the five analyzed claws yield a Pass@1 spread of 12.5 percentage points (73.4% to 60.9%). For Qwen 3.6-flash, the spread is even larger at 27.4 points (66.0% to 38.6%). Variation in cache utilization, tool management, session logic, and output formatting substantially affect both resolved rate and cost (Figure 3).
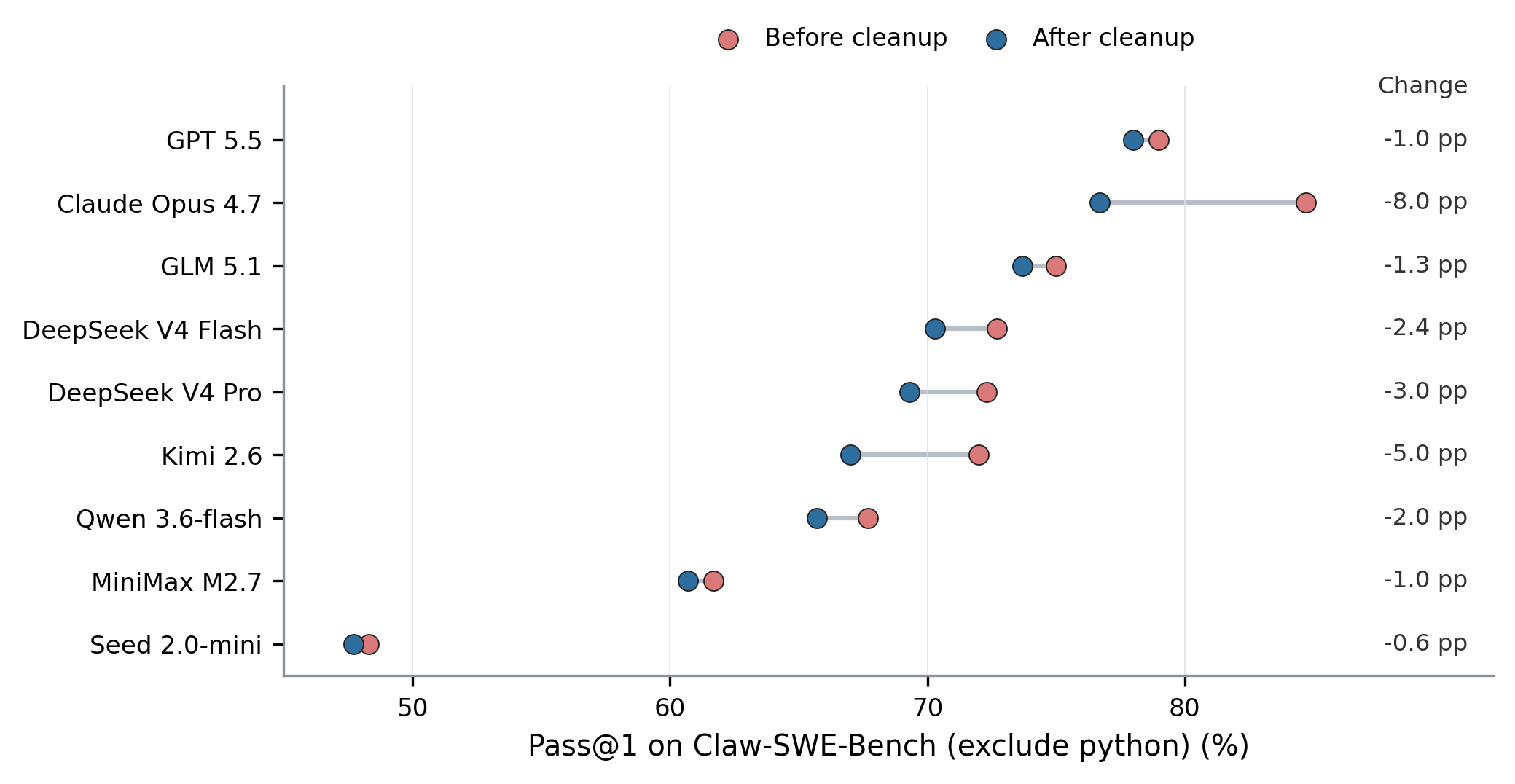
Figure 3: Effect of future-commit cleanup on the OpenClaw model sweep. After cleanup, Pass@1 does not increase for any of the nine models; drops range from 0.6 to 8.0 percentage points.
Critically, the accuracy-cost Pareto frontier exhibits non-trivial structure (Figure below): higher Pass@1 does not necessarily require exponential cost increase, and certain claw–model pairs dominate both axes.
(Figure 4)
Figure 4: Resolve-rate–cost Pareto frontier for five claws × two models sweep; points indicate unique claw–model pairs. The black line marks the non-dominated Pareto frontier.
Fairness and Robustness Measures
The evaluation endpoint strictly enforces workspace boundary, patch extraction procedure, and future-commit cleanup to prevent test set leakage and enable fair, auditable comparison. After applying future-commit cleanup, Pass@1 drops for all models, with maximum decreases up to 8 percentage points (e.g., for Claude Opus 4.7), highlighting the necessity of strict workspace sanitization.
Practical and Theoretical Implications
Claw-SWE-Bench demonstrates that agentic coding-system evaluation must treat harness design, resource cost, and evaluation protocol as first-class, orthogonally controlled variables. Harnesses are not mere wrappers around LLMs; their implementation details (e.g., tool interface, session management, patch extraction) can shift observed performance by as much as the underlying model tier. As evaluation cost varies widely with both harness and cache policy, future agent benchmarking must report cost, Pass@1, and cache hit rate together, and standardize protocol interfaces for meaningful scientific attribution.
The provision of Lite-80 enables frequent, high-fidelity regression testing and rapid model/harness experiments within practical cost and time constraints—critical for researchers and small teams operating under limited resources.
For the broader agentic evaluation ecosystem, Claw-SWE-Bench’s layered architecture and open protocol provide a template for disentangling evaluation axes in domains beyond coding: general web agents, productivity tools, and interactive assistants all require analogous abstractions for fair, reproducible benchmarking.
Conclusion
Claw-SWE-Bench provides a comprehensive, protocol- and cost-aware benchmark for evaluating OpenClaw-style and heterogeneous agent harnesses on challenging, multilingual coding tasks. By isolating harness architecture as a controlled experimental dimension and integrating cost metrics into evaluation, this work establishes new methodological foundations for reproducible, comparable, and cost-transparent agentic coding system research. Future work should extend these protocols to deeper model–harness interaction studies, multi-seed replication for variance estimation, and broader domains of agentic autonomy.

