- The paper introduces a unified Embodied Foundation Model that integrates cognition, planning, and action correction for robust physical intelligence.
- It employs a hybrid System-2/ System-1 architecture, large-scale multi-task reinforcement, and tailored data pipelines to achieve SOTA across 24 benchmarks.
- The model demonstrates zero-shot real-robot autonomy with effective closed-loop error recovery and high performance on diverse embodied tasks.
Embodied-R1.5: A Unified Framework for Physical Intelligence in Embodied AI
Overview and Motivation
The proliferation of large multimodal LLMs (MLLMs) has led to advanced embodied agents, yet models capable of unifying embodied cognition, planning, correction, and low-level action grounding in a single scalable and efficient system remain rare. "Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models" (2606.11324) introduces a unified Embodied Foundation Model (EFM) that integrates these core embodied reasoning capabilities, establishing a new baseline for physical intelligence in vision-language-action tasks.
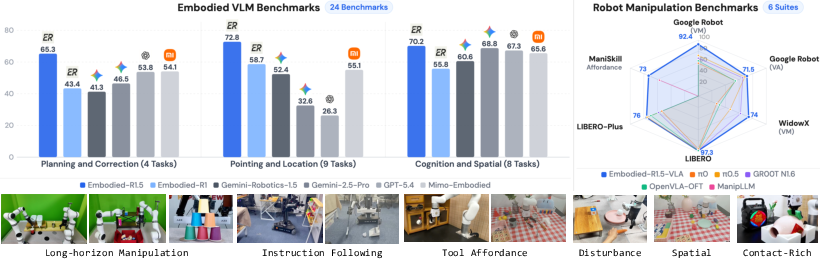
Figure 1: Performance overview of Embodied-R1.5: SOTA across 24 benchmarks and diverse zero-shot real-robot evaluations.
Unified Embodied Capabilities: Model Architecture
Embodied-R1.5 formalizes embodied intelligence along three principal capability dimensions: (1) embodied cognition and spatial reasoning (semantic and spatial structure comprehension), (2) embodied task planning and correction (long-horizon decomposition, runtime monitoring, fault recovery), and (3) embodied pointing and localization (referential and functional grounding across 2D/3D).
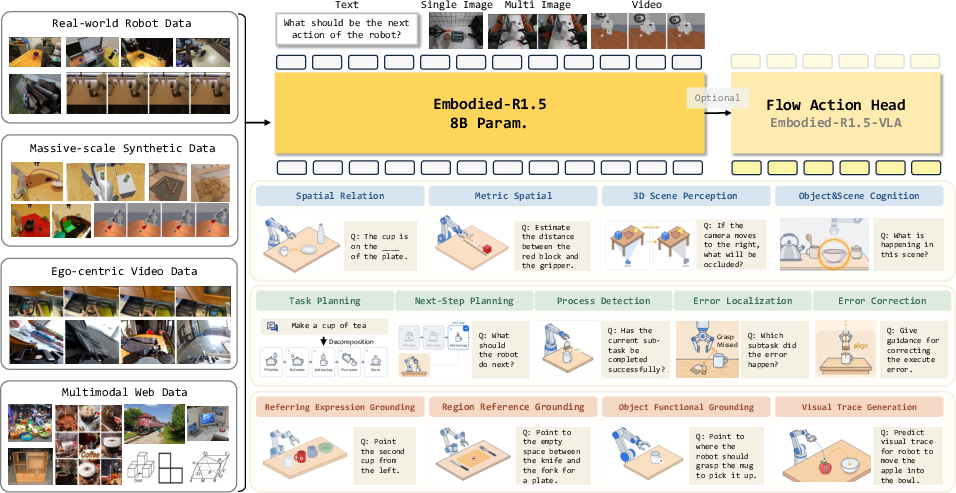
Figure 2: Embodied-R1.5 architecture and capability taxonomy. Top: EFM extensible to direct action via lightweight flow-matching expert. Bottom: Three unified embodied reasoning dimensions with tailored data pipelines.
Embodied-R1.5 is instantiated as an 8B-parameter vision-LLM (VLM), designed for stable open-vocabulary coordinate prediction via plain-text numeric output, supporting both reasoning and spatial anchoring throughout multi-step inference. Action policy extension is achieved via a lightweight DiT-based flow-matching expert, forming a hybrid System-2 (reasoning) + System-1 (action generation) architecture that eliminates the requirement for large-scale action pretraining.
Data Construction: Scalable, Balanced Multi-Task Pipelines
Achieving comprehensive capability internalization required a 15B-token training corpus. The pipeline integrates and restructures 34 datasets, complemented by three automated construction modules:
- 3D Scene Annotation for Spatial Reasoning: Automated pipeline leverages robot scene images to produce metric-scale 3D semantic graphs via MoGe-2 depth, Grounded-SAM open-vocabulary segmentation, and RANSAC-based world alignment, followed by QA generation for spatial metrics and relations.
- Failure-Aware Correction Data: Systematic perturbation of sub-task plans (step deletion, swap, object/action error), truncation/inconsistency synthesis in demonstrations, and physical perturbation in simulation construct 800K failure diagnosis and correction QA examples, partitioned by detection/localization/correction and planning/execution failure.
- Functional Affordance & Trajectory Data Generation: Simulation assets (ManiSkill-PartNet, PRISM) and large-scale human-robot interaction data are processed for functional part and affordance annotation, as well as visual trace extraction (object-centric and end-effector-centric, 2D and 3D), supporting rich referential and manipulation labels.
Training Strategy: Multi-Task Reinforcement and Curriculum Design
Training features a two-stage approach: supervised fine-tuning (SFT) on the full multi-capability dataset for foundational alignment, followed by multi-task balanced reinforcement learning (RFT) with difficulty-aware sample filtering, dynamic degenerate group masking, and global batch reward normalization. The RL stage utilizes five tailored reward functions—exact match, IoU, point distance, trajectory RMSE, and reward model-based semantic similarity—for dense and aligned gradient signal propagation across heterogeneous embodied objectives.
The Planner-Grounder-Corrector (PGC) Closed-Loop System
Autonomy is validated with the PGC framework, in which a single Embodied-R1.5 instance asynchronously orchestrates (1) high-level planning/decomposition, (2) low-level spatial grounding, and (3) closed-loop process correction using a minimal FIFO memory buffer. This closed-loop design eliminates multi-model cascading, allowing direct context sharing for instruction, spatial, and fault reasoning, and rewiring control flow solely at the orchestration harness without explicit heuristic logic.
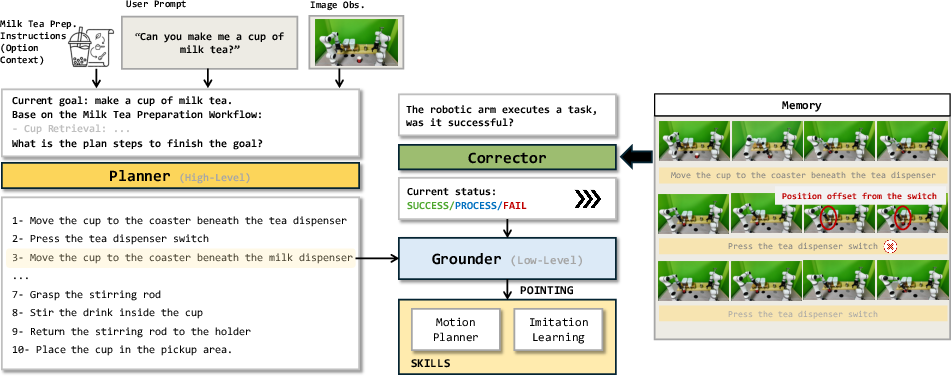
Figure 3: The PGC closed-loop autonomy stack. The example demonstrates adaptive long-horizon task decomposition, spatial grounding, and error-triggered replanning.
Evaluation Framework
To address the embodied evaluation gap, the EmbodiedEvalKit system is presented, standardizing over 25 benchmarks and 20+ models in a unified four-layer codebase supporting structured parsing, format normalization, and official embodied metrics.
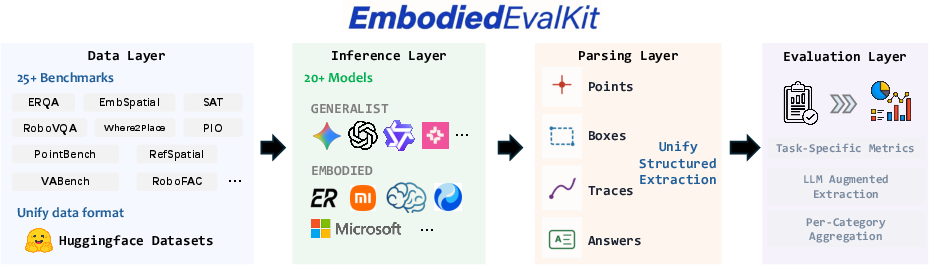
Figure 4: EmbodiedEvalKit: Modular, scalable evaluation over the full embodied benchmark suite.
Experimental Results
Comprehensive evaluation spans 24 benchmarks covering planning/correction, cognition/spatial reasoning, and pointing/location. Embodied-R1.5 attains state-of-the-art on 16/24, with an average main-benchmark score of 70.4% (outperforming Gemini-Robotics-ER-1.5 by +17.0pp and GPT-5.4 by +21.7pp). The most substantial margin is observed on open-vocabulary and functional affordance pointing tasks due to targeted data construction and architecture.

Figure 5: Embodied-R1.5 demonstrates superior accuracy and task/scene generalization on a diverse evaluation battery.
Robotic Manipulation and Generalization
The VLM backbone's embodied knowledge enables efficient adaptation into action-endowed variants (Embodied-R1.5-VLA) without large-scale action pretraining or demonstration data, substantially outperforming π0.5 and ManipLLM on all four standard manipulation suites (e.g., 92.4% on SimplerEnv Google Robot Visual Matching, 71.5% Variant Aggregation, and 97.3% on LIBERO without pretraining). Distribution shift robustness is validated on LIBERO-Plus (76.0%), and precise zero-shot transfer to RoboTwin bimanual tasks approaches fine-tuned state-of-the-art.
Zero-Shot Real-Robot Autonomy and Robustness
Embodied-R1.5 is deployed zero-shot on multiple real-robot arms, executing instruction following, tool affordance-centric manipulation, spatially indexed grasping, and articulated trajectory tasks without bespoke data or fine-tuning.

Figure 6: Robust zero-shot physical deployment without task-specific tuning: five diverse manipulation categories.
Long-horizon closed-loop experiments verify the autonomous planning and on-the-fly task recovery enabled by the PGC system, including sequential/cyclic tasks and open-vocabulary selection from novel object arrangements.

Figure 7: Long-horizon closed-loop manipulation requiring sequential decomposition, multi-step pointing, and autonomous recovery.
Human-in-the-loop intervention scenarios illustrate the real-time correction and recovery capabilities, with robust task completion after multiple active perturbations.

Figure 8: Embodied-R1.5 recovers from multiple scene disturbances, confirming correction and replanning efficacy.
Ablation and Analysis
Extensive ablation reveals that RFT yields the largest benefit on verifiable, geometry-grounded tasks (e.g., +3.8pp on Pointing), backbone improvements transfer data-efficiency to VLA, and the full multi-task RL recipe is crucial for difficulty-balancing heterogeneous outputs. Vision-to-force handoff experiments (Figure 9) demonstrate synergistic composition for contact-rich tasks.
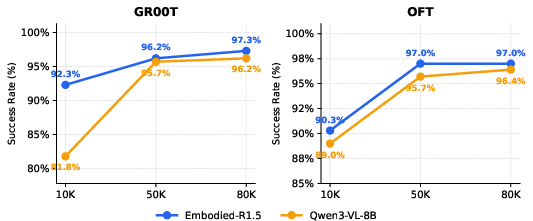
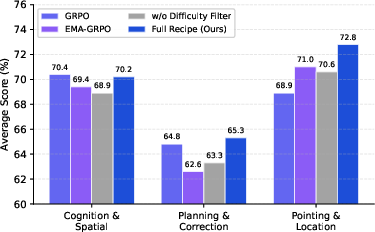
Figure 10: Backbone transfer: Embodied-R1.5 accelerates and magnifies VLA adaptation success rates vs. a standard VLM.

Figure 9: Visual-to-tactile policy handover enables high-precision contact manipulation.
Qualitative Reasoning and Generalization
Visualization sequences illustrate chain-of-thought decomposition, spatial metric inference, 3D scene understanding, robust instance segmentation and functional part localization, confirming robust internalization and transfer (Figures 11–18).
Implications, Limitations, and Future Directions
Embodied-R1.5 demonstrates that unifying embodied reasoning dimensions with tailored data construction and multitask reinforcement yields VLMs that can substitute for explicit action pretraining and scale to long-horizon, closed-loop autonomy. The approach highlights the viability of treating spatial, planning, and manipulation tasks within a single encoder-decoder, leveraging token-symbol grounding for action sequencing.
Notably, operation remains in the 2D image domain; integrating point cloud and explicit 3D inputs may further improve occlusion/geometry grounding. Tighter coupling between reasoning and motor policy modules, direct spatial tokenization, and application to mobile or navigation robots represent promising research avenues. The open-source release of model, data, and evaluation suite provides a foundation for accelerated community advances in unified physical agents.
Conclusion
Embodied-R1.5 delineates a systematic approach for evolving physical intelligence in embodied agents, integrating spatial, planning, and pointing reasoning in a scalable, open-source framework with state-of-the-art performance and robust zero-shot transfer, validated with closed-loop autonomy and correction in real domains. This paradigm evidences that high-capability EFMs can mitigate or even supplant extensive action demonstration requirements, paving the way for more generalizable physical AI systems.

