PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence (2512.16793v1)
Abstract: Robotic generalization relies on physical intelligence: the ability to reason about state changes, contact-rich interactions, and long-horizon planning under egocentric perception and action. However, most VLMs are trained primarily on third-person data, creating a fundamental viewpoint mismatch for humanoid robots. Scaling robot egocentric data collection remains impractical due to high cost and limited diversity, whereas large-scale human egocentric videos offer a scalable alternative that naturally capture rich interaction context and causal structure. The key challenge is to convert raw egocentric videos into structured and reliable embodiment training supervision. Accordingly, we propose an Egocentric2Embodiment translation pipeline that transforms first-person videos into multi-level, schema-driven VQA supervision with enforced evidence grounding and temporal consistency, enabling the construction of the Egocentric2Embodiment dataset (E2E-3M) at scale. An egocentric-aware embodied brain, termed PhysBrain, is obtained by training on the E2E-3M dataset. PhysBrain exhibits substantially improved egocentric understanding, particularly for planning on EgoThink. It provides an egocentric-aware initialization that enables more sample-efficient VLA fine-tuning and higher SimplerEnv success rates (53.9\%), demonstrating effective transfer from human egocentric supervision to downstream robot control.
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to teach robots to understand and act in the real world by learning from human first-person videos (like GoPro footage). The authors build a “bridge” between Vision-LLMs (VLMs)—AI that understands pictures and words—and physical intelligence—the skill of planning and doing actions with objects. They turn human egocentric (first-person) videos into clear, reliable training data so a model called PhysBrain can learn how to plan and reason from the robot’s own point of view. Then they plug PhysBrain into robot control systems and test if it helps robots do tasks better. It does.
What questions did the researchers ask?
They focused on three simple questions:
- Can we use large amounts of human first-person videos to teach AI the kind of planning and interaction skills robots need?
- How do we turn messy, raw videos into clean, trustworthy training signals that teach “how” and “when” to act—not just “what is in the image”?
- If we train a model this way, will it help robots plan and complete tasks more successfully, even with limited robot-specific data?
How did they do it?
They designed a step-by-step pipeline to translate human egocentric videos into training material for an “embodied brain.” Think of it like turning a collection of diary videos into a study guide that teaches how to do things.
Here’s the approach, explained with everyday analogies:
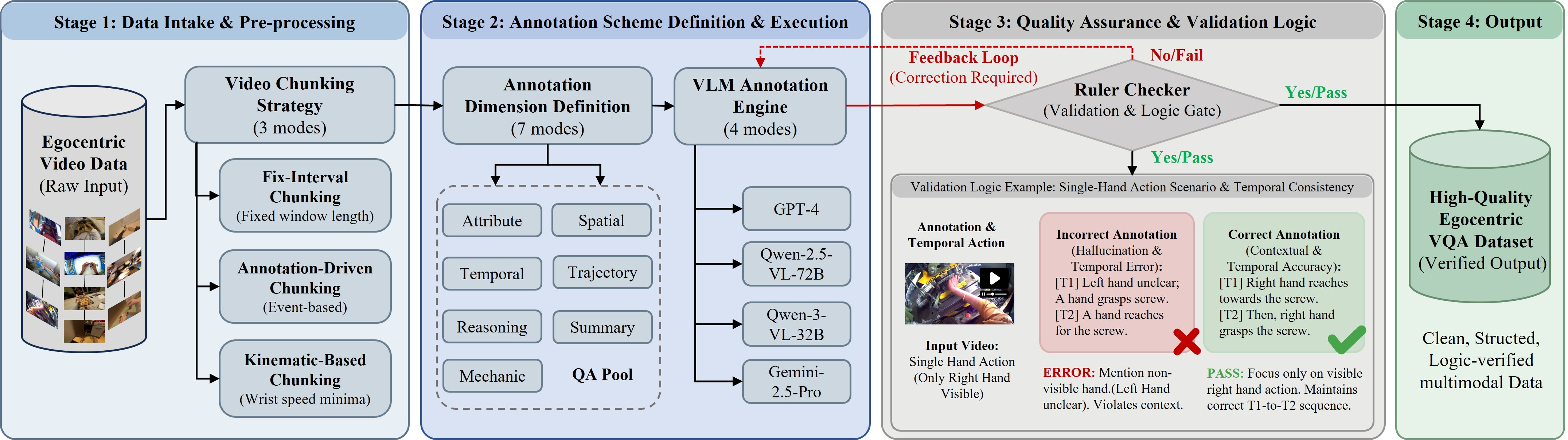
- Breaking videos into short clips:
- Imagine a long vlog chopped into bite-size scenes. Each short clip focuses on one moment that shows what you’re doing with your hands, objects, and timing.
- Asking structured questions (VQA: Video Question Answering):
- Instead of vague descriptions, the system uses a set of “question styles” (like “Where is the cup?”, “What happens next?”, “Which hand is picking up the spoon?”).
- Each clip gets a carefully worded question and a detailed answer. This teaches the model about space (where things are), time (what happened before/after), mechanics (hand-object contact), and planning (steps to reach a goal).
- Strict rule-checking for quality:
- Like a referee checking the replay, a rule checker rejects any answer that mentions things not visible (like a hand you can’t see), gets the order wrong (before vs after), or is unclear.
- If it fails, it regenerates a better Q&A until it passes the rules. This keeps the training clean and trustworthy.
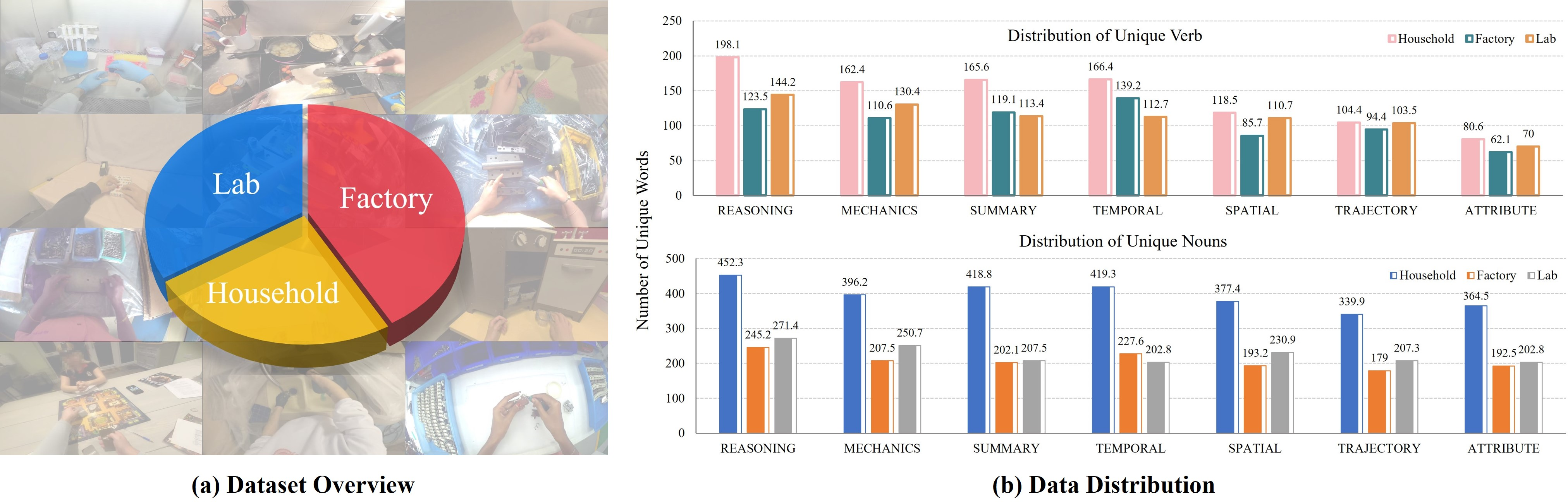
- Building a large, diverse dataset:
- They apply this process to three big sources of human first-person videos:
- Household scenes (Ego4D): cooking, cleaning, everyday activities.
- Factory tasks (BuildAI): tools, parts, repeated procedures.
- Lab work (EgoDex): precise actions with equipment and samples.
- The result is E2E-3M: about 3 million verified Q&A pairs that teach egocentric planning and interactions across many environments.
- Training the model (PhysBrain):
- They fine-tune existing VLMs (for example, Qwen2.5-VL-7B) on a mix of the new egocentric dataset and general vision-language data. This creates PhysBrain, a first-person-aware “brain” that better understands what to do from the robot’s viewpoint.
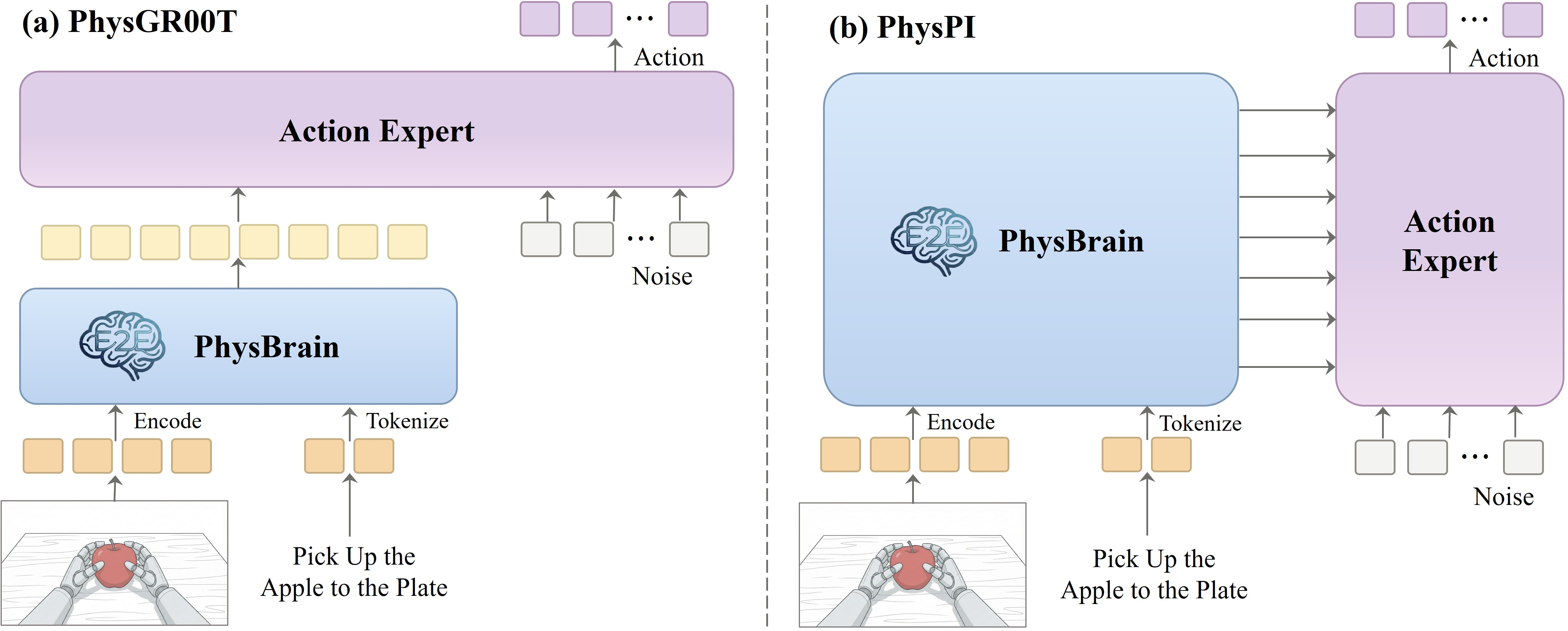
- Plugging PhysBrain into robot control (VLA: Vision-Language-Action):
- Think of the robot system as two parts: the “brain” that understands, and the “muscles” that move.
- PhysBrain is the brain. The “muscles” are an action generator that turns understanding into motion.
- They test two common setups:
- PhysGR00T: uses the brain’s final “thoughts” (last-layer features) as guidance for the action generator.
- PhysPI: lets the action generator “listen in” to multiple layers of the brain’s thoughts while planning motions, which can be more detailed.
- The action generator uses a diffusion method: it starts with a rough, noisy idea of actions and gradually “sculpts” them into the right movements—like whittling a block of wood into a useful tool.
What did they find, and why does it matter?
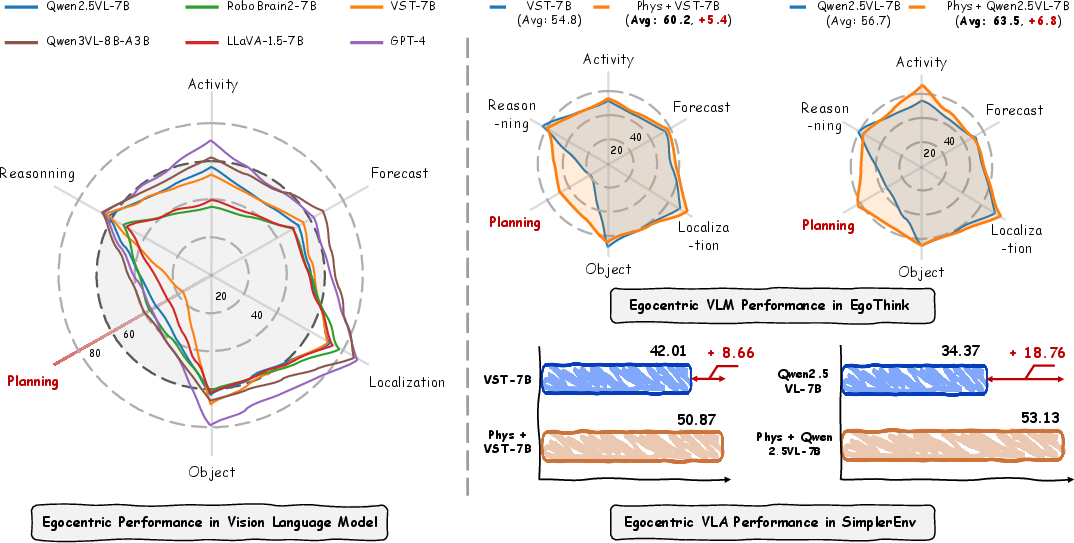
- Better first-person planning and reasoning:
- On the EgoThink benchmark (tests for egocentric understanding), PhysBrain improves a lot—especially in planning—compared to similar models. Planning means turning “what you see” into a step-by-step way to achieve a goal.
- Stronger robot task performance:
- In the SimplerEnv simulation (with a WidowX robot), PhysBrain-based systems reach an average success rate of about 53.9% across tasks like placing items and stacking blocks. That’s higher than several popular baselines, even though it used less robot-specific training data.
- Translation: the model learned valuable skills from human videos and reused them to help a robot act more reliably.
- Targeted gains in egocentric spatial understanding:
- When fine-tuned on the E2E dataset, models greatly improve at recognizing and reasoning about movement from a first-person view (for example, “Egocentric Movement” jumps from 26.09 to 91.30). This shows the dataset teaches exactly the kind of knowledge robots need when seeing through their own cameras.
- Scalability and practicality:
- Collecting huge robot datasets is expensive and slow (hardware, safety, people). Human first-person videos are much easier to gather and cover everyday interactions naturally. This makes the approach more scalable.
What’s the big impact?
This work suggests a practical path to smarter robots:
- Use plentiful human first-person videos to teach models how to plan and interact from the robot’s own viewpoint.
- Turn those videos into structured, reliable Q&A lessons, so models learn “what to do next,” not just “what is in the frame.”
- Start robot training from a strong egocentric-aware brain (PhysBrain), then fine-tune with a smaller amount of robot data. This saves time, cost, and improves performance.
- Human egocentric data and robot data complement each other: the human videos build general skills and planning; robot data adds exact control and physical details. Together, they can push robots closer to robust, real-world abilities.
In short, the paper shows that teaching robots to think like they see—using human first-person experiences—can make them better at planning and doing tasks, while keeping training scalable and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper, with concrete directions for future work:
- Real-world deployment: The study evaluates only in simulation (SimplerEnv with WidowX) and lacks results on physical robots. It remains unknown how PhysBrain transfers to real hardware under contact-rich, long-horizon, and safety-critical conditions, including sim-to-real gaps, latency, and robustness to sensor noise.
- Architectural coverage: The PhysPI variant is minimally explored. There is no systematic comparison between PhysGR00T and PhysPI (e.g., number of VLM layers used for conditioning, cross-attention configurations, fusion strategies, or alternative action experts like autoregressive policies or world-model-backed policies).
- Ablation depth: Missing ablations on key design choices, including clip segmentation strategy, VQA mode definitions, template design, evidence-grounding rules, annotation engine types, and mixing ratios between egocentric and general vision–language data. It is unclear which components drive planning improvements and sample efficiency gains.
- Annotation reliability: The pipeline relies on VLM-generated annotations with a deterministic rule checker, but no human-in-the-loop auditing is reported. There is no quantitative error analysis (false positives/negatives in evidence grounding, temporal ordering failures, hand-reference mistakes) or inter-annotator agreement/spot-check protocols to estimate supervision quality.
- Evidence grounding mechanism: The paper does not specify the algorithms used to verify “evidence grounding” (e.g., object/hand detectors, tracking, pose estimation) and provides no metrics for the validator’s coverage and failure modes. It is unclear whether validation is independent of the generation model or susceptible to correlated errors.
- Temporal segmentation effects: Scenario-aware chunking (fixed-interval, event-driven, kinematic-aware) is introduced but not evaluated. There is no study of how clip length, segmentation granularity, or event boundary accuracy affect planning/generalization performance.
- VQA schema sufficiency: The seven VQA modes (temporal, spatial, attribute, mechanics, reasoning, summary, trajectory) omit tactile/force cues, affordances, uncertainty, failure recovery, and constraints under occlusion. It is an open question whether augmenting the schema with force/3D contact states or uncertainty annotations yields better embodied planning.
- Diversity metrics clarity: The object/verb diversity formulas appear syntactically incorrect and lack rigorous definitions (e.g., tokenization, lemmatization, normalization). Future work should formalize diversity measures, report confidence intervals, and analyze long-tail distributions and cross-domain balance.
- Dataset balance and coverage: E2E-3M aggregates household, factory, and lab videos, but the domain/task distribution, long-horizon activity coverage, and bimanual/mobile manipulation prevalence are not quantified. It is unclear how domain imbalance or repetitive patterns (e.g., factory workflows) influence generalization.
- Cross-benchmark generalization: Evaluation is limited to EgoThink. PhysBrain’s performance on other egocentric benchmarks (EgoPlan-Bench, QaEgo4Dv2, EgoM2P) and zero-shot transfer to out-of-domain tasks remains untested.
- Benchmark leakage controls: While Ego4D was excluded when training for EgoThink, the paper does not detail de-duplication across general-purpose instruction data or potential near-duplicate clips from other sources. Stronger duplicate detection and data lineage audits are needed to rule out inadvertent leakage.
- Evaluation methodology robustness: EgoThink scoring uses a GPT-4o judge without reporting inter-judge consistency, human agreement, or statistical significance. Objective, reproducible metrics and confidence intervals (e.g., multiple-choice, targeted probes, human ratings) would strengthen claims.
- Sample efficiency characterization: The claim that egocentric supervision improves sample efficiency is not backed by learning curves. A systematic study relating robot-data budgets to performance with and without human egocentric pretraining is needed (scaling laws, data ablation).
- VLA fine-tuning data scope: Fine-tuning uses only Bridge and Fractal subsets of OXE. It is unclear how performance scales across different robot datasets, tasks, and embodiments, and how the mixing ratio of robot vs human egocentric supervision affects outcomes.
- Action space alignment: The work deliberately avoids explicit alignment between human and robot action spaces but does not investigate methods to bridge embodiment gaps (e.g., cross-view action mapping, 3D hand/body pose as intermediates, affordance-to-action translation).
- Long-horizon planning: The improvements on EgoThink Planning are promising, yet the system is not evaluated on extended multi-step tasks (e.g., partial progress, recovery after failure, subgoal discovery), nor on planning with delayed rewards or constraints (e.g., time windows, resource limits).
- Occlusions and egomotion robustness: Egocentric-specific challenges (hand–object occlusion, motion blur, rapid viewpoint changes) are cited as motivation but not rigorously stress-tested. Robustness benchmarks and controlled perturbation studies are needed.
- Multimodal signals: The dataset and supervision are video-text only. Audio, depth, IMU, and tactile proxies—highly relevant for physical reasoning—are not exploited. It remains open whether integrating these modalities improves grounding and policy transfer.
- Multilingual and cultural bias: The paper does not report language coverage or geographic/cultural diversity, which may bias object/action distributions. Multilingual supervision and fairness audits are needed to ensure global applicability.
- Safety and privacy: The use of large-scale human egocentric videos raises privacy, consent, and ethical considerations. The paper does not detail data governance, redaction of sensitive content, or privacy-preserving annotation protocols.
- Interpretability and debugging: The system’s internal planning representations (e.g., step decompositions, causal chains) are not analyzed. Tools to inspect layer-wise contributions, attention maps, and failure explanations would aid reliability and downstream integration.
- Chain-of-thought in control: Although related works explore reasoning integration, PhysBrain-based VLAs do not test CoT-style planning scaffolds or policy-time deliberation (e.g., think-then-act). The impact of structured reasoning on manipulation remains unquantified.
- Real-world task breadth: SimplerEnv covers four tabletop tasks. Broader task suites (stacking, insertion, tool use, deformables, bimanual, mobile/base navigation) would better probe physical intelligence and embodiment transfer.
- Compute and deployment constraints: Training costs, memory footprint, and inference latency are underreported. It remains unclear whether PhysBrain can run on-device or resource-constrained platforms typical for mobile and home robots.
- Release completeness: The paper links a project page but does not detail the availability of code, full pipeline components (annotation engines, validators), data schemas, or pretrained weights. Reproducibility and community adoption depend on clear licensing and comprehensive releases.
Glossary
- ActionVAE: A variational autoencoder used to compress robot actions into a continuous latent space for alignment and learning. "compresses actions into a continuous latent space via ActionVAE"
- Catastrophic forgetting: The loss of previously learned capabilities (e.g., language) when fine-tuning on new tasks (e.g., actions). "attempt to address the catastrophic forgetting of language capabilities during VLA training"
- Chain-of-thought reasoning: An approach that explicitly models step-by-step reasoning to improve planning and decision quality. "explore incorporating chain-of-thought reasoning into the VLA inference process"
- Cross-attention: A mechanism where one sequence (e.g., actions) attends to another (e.g., VLM features) to condition generation. "inject them layer-wise into the DiT through cross-attention"
- Cross-embodiment: Training across different physical platforms or agents (human/robot) to improve generalization of action policies. "large-scale cross-embodiment and multi-task pretraining"
- Diffusion transformer (DiT): A transformer architecture tailored for diffusion models that denoise latent trajectories. "implemented as a diffusion transformer~(DiT)"
- Egocentric consistency: Validation rules ensuring hand references and body mentions align with the first-person viewpoint. "Egocentric consistency enforces the correct hand references and prohibits mentions of unseen limbs or contradictory assignments."
- Egomotion: The motion of the camera wearer (agent) that induces viewpoint changes in first-person videos. "missing egocentric cues such as hand manipulation, egomotion, and partial observability"
- Embodied brain: A representation/model that integrates perception, reasoning, and action generation for an agent. "Vision-Language-Action (VLA) systems rely on a reliable embodied brain that integrates scenario understanding and action generation."
- Embodiment gaps: Differences between human and robot bodies and capabilities that complicate direct demonstration transfer. "which is inherently constrained by embodiment gaps between humans and robots."
- Evidence grounding: Ensuring that generated annotations or answers are supported by visible frames and interactions. "Evidence grounding requires that all mentioned actions, hands, and contact states are supported by the clip frames."
- Flow-Matching (FM): A training/objective framework for diffusion-like models that learns velocity fields to transport noise to data. "a Flow-Matching (FM) action expert"
- Kinematic-aware strategies: Segmentation approaches that respect motion dynamics (e.g., hand/object movement) when chunking videos. "including fixed-interval, event-driven, and kinematic-aware strategies."
- Long-horizon planning: Planning that spans extended temporal sequences with multiple dependent steps and state changes. "long-horizon planning under egocentric perception and action."
- Partial observability: Situations where the agent lacks full state information (e.g., occlusions) in first-person perception. "missing egocentric cues such as hand manipulation, egomotion, and partial observability"
- Proprioceptive state: Internal state variables (e.g., joint angles) that describe the agent’s own body configuration. "optional proprioceptive state "
- Rectified-flow parameterization: A formulation for training flow/diffusion models via velocity fields that map noise to data. "Under the rectified-flow parameterization"
- Schema-driven annotation space: A constrained design of question/answer templates to standardize and validate supervision signals. "we define a finite, schema-driven annotation space."
- Spatial Aptitude Training (SAT): An evaluation/training protocol for assessing and improving spatial reasoning capabilities. "we evaluate Spatial Aptitude Training (SAT) by performing supervised fine-tuning (SFT) on VST using only E2E data"
- Tele-operation: Remote control of a robot by a human operator, typically used to collect high-quality demonstrations. "reliance on expert tele-operation"
- Temporal grounding: Linking language or events to specific time spans in video for sequence-aware understanding. "first-person retrieval, recognition, and temporal grounding."
- Visual Question Answering (VQA): A task where models answer questions about visual inputs, often used for structured supervision. "multi-level, schema-driven VQA supervision"
- Vision-Language-Action (VLA): Models that map vision and language inputs to actionable robot policies in an end-to-end framework. "Vision-Language-Action (VLA) models represent a recent paradigm shift in robotic manipulation"
- World models: Generative/dynamic models that predict future observations or dynamics to aid planning and action. "attempt to incorporate video generation models or world models into VLA action prediction"
Practical Applications
Immediate Applications
The following applications can be deployed with current tools and the assets described in the paper (Egocentric2Embodiment pipeline, E2E-3M dataset, PhysBrain checkpoints, and the PhysGR00T/PhysPI VLA recipes).
- Egocentric VLM initialization for robotics fine-tuning [Robotics, Software]
- What: Use PhysBrain as a plug-in VLM backbone to improve sample efficiency and success rates when fine-tuning Vision-Language-Action (VLA) policies on limited robot data (e.g., Open X-Embodiment subsets), replicating the reported 53.9% average success on SimplerEnv.
- How/tools: Adopt the PhysGR00T or PhysPI integration templates; use the provided flow-matching diffusion action expert; initialize from Qwen2.5-VL-7B+PhysBrain or VST-7B+PhysBrain; training workflow via starVLA-style configs.
- Assumptions/dependencies: Transfer from sim to real requires additional robot data and calibration; availability of GPUs; access to PhysBrain weights and licensing; safety review for physical deployment.
- Large-scale egocentric data curation and conversion into training signals [Software, Academia, Enterprise Video Analytics]
- What: Convert existing first-person video archives (e.g., manufacturing, lab, retail training footage) into structured, validated VQA supervision to bootstrap domain-specific egocentric brains.
- How/tools: Deploy the Egocentric2Embodiment Translation Pipeline (schema-driven VQA generation, seven modes, deterministic rule checker), then SFT a VLM on the generated corpus.
- Assumptions/dependencies: Video rights and consent; compute for VLM-driven annotation; domain customization of templates/rules to reduce false positives; storage and data governance.
- Factory and lab “video-to-work-instructions” generator [Manufacturing, Pharma/Biotech Labs, Education/Training]
- What: Automatically convert head-mounted recordings of procedures into step-wise, egocentric, evidence-grounded instructions and checklists for training, quality control, and compliance documentation.
- How/tools: Apply the pipeline’s temporal, mechanics, and reasoning modes; generate multi-level VQA supervision and compile procedure summaries; deliver via a workflow tool (e.g., LMS integration).
- Assumptions/dependencies: Accurate temporal segmentation in repetitive workflows; domain vocabulary/verb templates; validation rules extended to sector-specific hazards; privacy controls for personnel and IP.
- AR/VR instructional overlays from egocentric context [Wearables, Field Service, Education]
- What: Provide step-by-step guidance and error checks for assembly, device maintenance, or lab tasks using first-person view from smart glasses or body cams.
- How/tools: Run PhysBrain for egocentric planning and forecasting; connect to a small action library; deliver overlays via AR SDKs; use the pipeline to bootstrap domain-specific training data from internal videos.
- Assumptions/dependencies: On-device or edge inference constraints (may require model distillation); latency and battery limitations; safety review for hands-busy workflows; robust hand/object occlusion handling.
- Safety and compliance auditing from first-person recordings [Manufacturing, EHS, Insurance]
- What: Detect missed steps, improper contact/handling, or out-of-order actions in SOPs; generate evidence-grounded incident timelines.
- How/tools: Use mode-specific temporal logic checks and mechanics/trajectory templates; run periodic audits on recorded sessions; flag violations with grounded frames.
- Assumptions/dependencies: Policy alignment on surveillance and consent; low false-positive rates; sector regulations (e.g., OSHA, GMP); secure storage and audit trails.
- Research benchmarking and curriculum building for egocentric cognition [Academia]
- What: Study scaling laws, viewpoint gaps, long-horizon planning, and contact reasoning using E2E-3M; build new tasks on top of EgoThink/EgoPlan with the pipeline’s validated QA schemas.
- How/tools: Train baselines with/without E2E-3M; ablate VQA modes; compare PhysGR00T vs. PhysPI coupling; share reproducible validation logs.
- Assumptions/dependencies: Dataset access/licensing; standardized judging protocols; compute resources for multi-run comparisons.
- Hallucination-resistant annotation for egocentric datasets [Software Tooling, Data Vendors]
- What: Reduce annotation errors via evidence grounding and rule-based consistency checks (hand visibility, order, and contact states) before training or releasing datasets.
- How/tools: Integrate the paper’s deterministic rule checker as a QA gate into existing annotation workflows; log regeneration errors to improve templates.
- Assumptions/dependencies: Coverage of rules for new domains; adaptation to non-English data; careful balance between recall and precision to avoid over-rejection.
- Egocentric planning boosters for general VLMs [Software, Developer Tools]
- What: Fine-tune existing open VLMs with E2E-3M to improve first-person planning, forecasting, and localization without compromising general vision-language skills.
- How/tools: Mixed SFT on E2E-3M + general-purpose instruction data; evaluate with EgoThink; publish task-specific checkpoints.
- Assumptions/dependencies: Compute cost; licensing constraints on base models/datasets; need for domain-specific validation to prevent regressions outside egocentric tasks.
Long-Term Applications
These applications require further research, scaling, or real-world integration (e.g., sim-to-real transfer, broader datasets, regulatory alignment).
- Wearable task copilots for home and workplace [Consumer, Enterprise, Assistive Tech]
- What: Always-available assistants that plan and verify multi-step tasks from first-person video (cooking, DIY, equipment setup), with proactive warnings for missing prerequisites and unsafe states.
- How/tools: PhysBrain-style pretraining on diverse egocentric corpora; on-device inference and privacy-preserving training; integration with AR glasses and speech interfaces.
- Assumptions/dependencies: Robustness to egomotion/occlusions in the wild; energy-efficient models; strong privacy guarantees and on-device processing; broad domain generalization.
- Humanoid and mobile manipulators trained primarily from human egocentric supervision [Robotics]
- What: Robots acquire new skills by watching human-worn cameras at scale, then performing limited robot-domain fine-tuning to achieve robust control in households and logistics.
- How/tools: Continuous Egocentric2Embodiment ingestion from fleets of wearables; VLA with stronger coupling (PhysPI-like) and proprioception; world models for long-horizon plans; safety layers.
- Assumptions/dependencies: Demonstrated sim-to-real reliability; standardized robot action spaces; safe learning frameworks; liability and certification pathways for human-robot interaction.
- Real-time safety forecasting in safety-critical environments [Healthcare, Energy, Construction]
- What: Predict near-future risks (e.g., contamination in sterile fields, hot-surface contact, tool misplacement) from surgeon/technician first-person video; issue timely alerts.
- How/tools: Extend forecasting/temporal VQA modes to risk models; integrate with hospital or plant safety systems; closed-loop interventions via wearables or haptics.
- Assumptions/dependencies: High precision/recall thresholds; domain shift mitigation; clinical/industrial validation; stringent privacy and compliance (HIPAA, IEC, ISO).
- Automatic SOP learning and continuous improvement from frontline work [Manufacturing, Logistics]
- What: Infer, version, and optimize standard operating procedures by aggregating thousands of worker egocentric sessions; highlight bottlenecks and error-prone steps.
- How/tools: Aggregate E2E-like supervision across sites; mine temporal graphs of actions/states; link to MES/QMS for change management and training rollouts.
- Assumptions/dependencies: Worker consent; robust anonymization; IT integration; union and policy considerations; clear governance over derived performance metrics.
- Skill transfer marketplaces and “video-to-policy” services [Software, Platforms]
- What: Platforms that turn curated egocentric tutorial libraries into deployable robot policies or training modules for partner robots and simulators.
- How/tools: Standardized schema/templates; API endpoints for policy export; simulation bridges and evaluation suites; tiered verification (human-in-the-loop).
- Assumptions/dependencies: Licensing of source videos; cross-embodiment transfer quality; liability sharing and warranties; standardized evaluation benchmarks.
- Assistive robotics linked to prosthetics and exoskeletons [Healthcare, Rehabilitation]
- What: Use egocentric planning and contact reasoning to drive intent-aware assistive devices that anticipate next steps and provide corrective guidance or motion support.
- How/tools: Fine-tune PhysBrain with clinical egocentric datasets; tight coupling to biomechanical sensors; personalized models.
- Assumptions/dependencies: Clinical trials; patient privacy; device certification; robustness to atypical motion patterns.
- Policy frameworks for egocentric data governance and safe AI use [Policy, Standards]
- What: Develop standards for collection, annotation, storage, and model training on egocentric video, including evidence-grounding requirements and redaction pipelines.
- How/tools: Codify template/rule validation as best-practice; mandate privacy-by-design and data minimization; auditing protocols for annotation accuracy and model behavior.
- Assumptions/dependencies: Multi-stakeholder alignment (industry, labor, patient advocates); evolving privacy laws; feasibility of on-device or federated training.
- Multi-agent learning from shared egocentric experiences [Autonomy, Swarm Robotics]
- What: Cross-embodiment knowledge sharing where many agents learn from heterogeneous human perspectives to coordinate tasks (warehousing, agriculture).
- How/tools: Unified egocentric schemas; representation learning across viewpoints; collective policy distillation; simulation-to-field deployment loops.
- Assumptions/dependencies: Standardized data formats; communication constraints; safety in multi-agent settings; robust out-of-distribution handling.
Cross-cutting dependencies and assumptions
- Privacy and consent: Egocentric recordings often include bystanders, PII, and sensitive locations; robust consent workflows, redaction, on-device processing, and compliance are critical.
- Domain adaptation: Templates and validation rules must be customized to sector vocabulary, safety constraints, and action semantics; rule gaps can cause silent failures.
- Compute and deployment: Training/annotation at scale requires substantial compute; on-device or edge deployment may need compression/distillation.
- Sim-to-real gap: Demonstrated gains in simulation must be validated on real hardware with safety interlocks; robot data remains necessary for grounding.
- Licensing and IP: Use of datasets like Ego4D/BuildAI/EgoDex and enterprise recordings must respect licensing; derived datasets (E2E-like) need clear redistribution terms.
Collections
Sign up for free to add this paper to one or more collections.