MiMo-Embodied: X-Embodied Foundation Model Technical Report
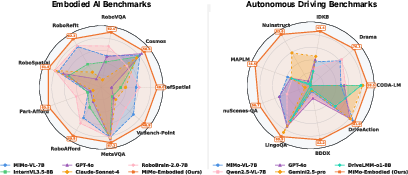
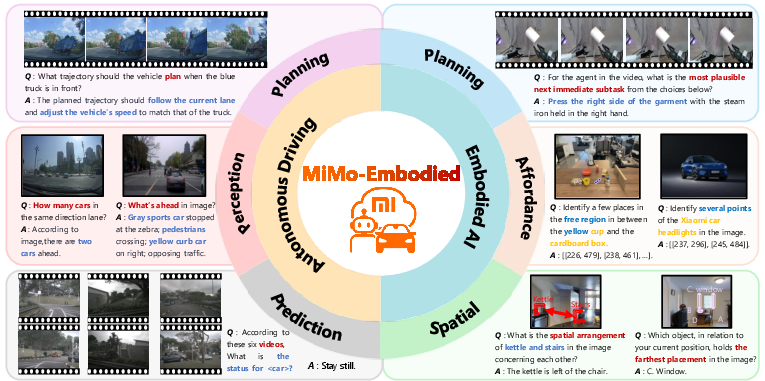
Abstract: We open-source MiMo-Embodied, the first cross-embodied foundation model to successfully integrate and achieve state-of-the-art performance in both Autonomous Driving and Embodied AI. MiMo-Embodied sets new records across 17 embodied AI benchmarks in Task Planning, Affordance Prediction and Spatial Understanding, while also excelling in 12 autonomous driving benchmarks across Environmental Perception, Status Prediction, and Driving Planning. Across these tasks, MiMo-Embodied significantly outperforms existing open-source, closed-source, and specialized baselines. Our results indicate that through multi-stage learning, curated data construction, and CoT/RL fine-tuning, these two domains exhibit strong positive transfer and mutually reinforce one another. We provide a detailed analysis of our model design and training methodologies to facilitate further research. Code and models are available at https://github.com/XiaomiMiMo/MiMo-Embodied.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “MiMo-Embodied: X-Embodied Foundation Model”
Overview
This paper introduces MiMo-Embodied, a single AI system that is good at both:
- Embodied AI (robots understanding and acting in the physical world), and
- Autonomous driving (cars that can understand the road and make safe decisions).
Instead of building separate AIs for robots and cars, MiMo-Embodied combines both into one model. The authors show that learning skills in one area helps the other, and their model reaches top scores on many tests across both fields. They also share their code and models so others can build on their work.
Goals
The paper has two main goals:
- Build one unified AI model that can handle tasks from both embodied AI (like a household robot) and autonomous driving (like a self-driving car).
- Test this “cross-embodiment” model thoroughly to see how well it understands, reasons, and plans across indoor (robot) and outdoor (driving) situations.
Put simply: they want one smart system that sees and thinks about the world like a helpful robot and a cautious driver—and they want to prove it works.
How the Model Works and How They Trained It
Think of MiMo-Embodied like a team with three parts:
- Vision Transformer (the “eyes”): It looks at images and videos and notices important details.
- Projector (the “adapter”): It takes what the eyes saw and converts it into a format the “brain” understands.
- LLM (the “brain”): It reads text, reasons, and explains decisions.
It can handle single pictures, multiple pictures, and videos. The “projector” is like a translator that turns visual features into tokens (small pieces of information), so the LLM can think about them.
To make the model strong and well-rounded, the researchers used a four-stage training process. You can think of it like training for a sport with drills, strategy, and feedback:
- Stage 1: Learn general visual-language skills plus robot-focused skills.
- This builds basics like “What is this object?”, “Where is it?”, “What can I do with it?”, and “How are things arranged in space?”
- Stage 2: Add driving-specific knowledge.
- This includes understanding traffic scenes, predicting what other cars and people might do, and planning safe actions.
- Stage 3: Chain-of-Thought fine-tuning (show your work).
- The model practices writing out its reasoning step by step, like “I see a stop sign on the right, cars ahead are slowing down, so the safe action is to brake.”
- Stage 4: Reinforcement Learning (practice with feedback).
- The model tries answers, gets reward signals for being correct, precise, and well-formatted, and improves. It uses a method called GRPO, which compares several answers and boosts the best ones.
What They Found
The model was tested on many benchmarks (standard tests used by researchers):
- In embodied AI, it excelled at:
- Affordance prediction (figuring out what actions are possible with objects, like “You can pull this handle” or “Place the cup here safely”),
- Task planning (turning a goal into steps),
- Spatial understanding (knowing directions, distances, and where things are).
- In autonomous driving, it did great at:
- Environmental perception (seeing and understanding the road, signs, lanes, and important objects),
- Status prediction (guessing what other cars or pedestrians will do next),
- Driving planning (choosing safe, rule-following maneuvers and explaining why).
It set new records across 17 robot-related benchmarks and 12 driving-related benchmarks, beating both open-source models and many closed/proprietary systems.
A key finding: training the model on both robots and driving made it better at each. Skills learned in indoor robot tasks helped outdoor driving tasks, and vice versa. This “positive transfer” means one model can learn more effectively by practicing in multiple real-world settings.
Why It Matters
- Smarter, safer systems: A unified model that can see, reason, and plan in different environments can lead to more reliable robots and safer autonomous cars.
- Better generalization: Understanding both indoor and outdoor worlds helps the AI handle new, complex situations more confidently.
- Clearer explanations: By practicing chain-of-thought, the model can explain its decisions, which builds trust—important for safety-critical tasks like driving.
- Faster progress for the research community: Because it’s open-source, others can test, improve, and adapt it for new applications.
In simple terms: MiMo-Embodied shows that one AI can learn to be a careful driver and a capable helper robot at the same time. This could push forward how we build intelligent machines that understand and act safely in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Cross-domain transfer mechanism remains unquantified: the paper asserts strong positive transfer between autonomous driving and embodied AI but does not isolate, measure, or explain which skills transfer, when, and under what data/task mixtures (no ablations contrasting single-domain vs. joint training).
- Absence of stage-wise ablations: the contributions of Stage 1–4 (embodied SFT, driving SFT, CoT, RL) to final performance are not disentangled, and the marginal gains, trade-offs, and potential interference or forgetting are not reported.
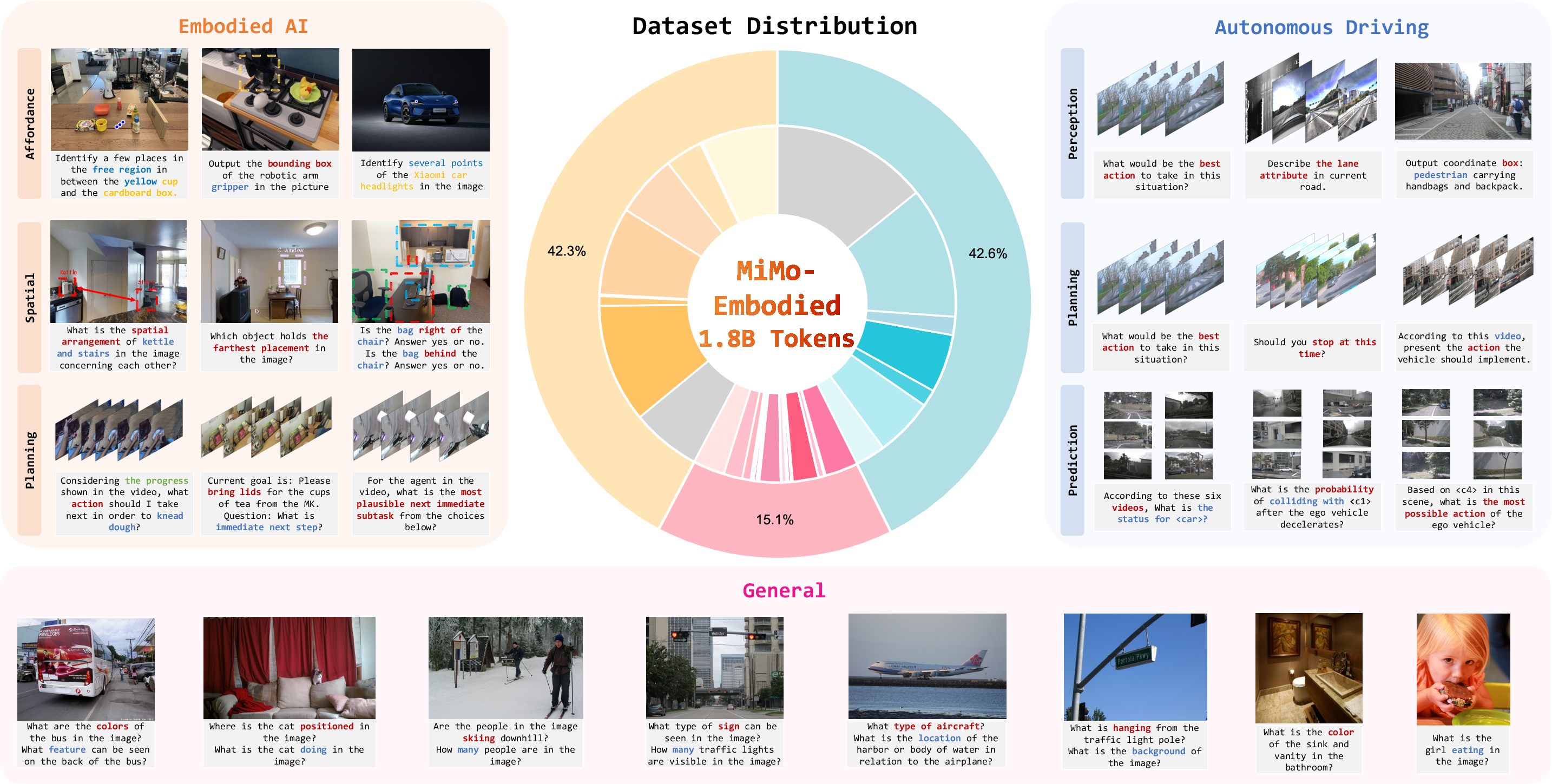
- Data mixture and sampling strategy are unspecified: the proportions, curriculum schedules, and sampling policies across general, embodied, and driving datasets are not detailed, leaving reproducibility and optimization of cross-domain mixtures unclear.
- Potential data contamination is unaddressed: given overlap with widely used benchmarks (e.g., nuScenes-derived datasets, RoboVQA, Cosmos-Reason1, RefSpatial), the paper does not audit training-test leakage or describe deduplication/hold-out safeguards.
- Benchmark comparability and statistical rigor are limited: “SOTA” claims lack statistical significance tests, variance/confidence intervals, and standardized prompt settings, and many results were computed with the authors’ own evaluation framework without detailing its procedures.
- Evaluation is open-loop and offline-only: there is no closed-loop testing in simulators (e.g., CARLA) or on real vehicles/robots to validate planning quality, safety, and control integration under execution.
- Lack of low-level control integration: the model’s outputs (e.g., plans, decisions, reasoning) are not connected to downstream controllers, actuation policies, or safety-verified planners; end-to-end system performance (collision rate, interventions, task success) is not measured.
- Sensor modality limits: the system appears vision-language centric (RGB images/videos); there is no integration of LiDAR, radar, maps, HD lanes, or GPS/IMU, and the impact of lacking these modalities on driving safety is not studied.
- Multi-view/multi-camera fusion is under-specified: the approach to camera calibration (intrinsics/extrinsics), time synchronization, BEV/3D representation, and inter-view attention or memory is not described or evaluated.
- Monocular 3D understanding reliability is unclear: the paper mentions 3D QA and monocular 3D grounding but does not report 3D localization accuracy, failure cases (scale/depth errors), or robustness under occlusion and clutter.
- Temporal reasoning limits: there is no quantitative assessment of long-horizon temporal consistency in videos (e.g., object permanence, track fragmentation, causal dependencies), nor sensitivity to clip length and frame rate.
- Safety, robustness, and uncertainty are not quantified: no adversarial, weather/nighttime, geographic, or long-tail corner-case stress tests; no calibration/uncertainty metrics; no risk-aware decision thresholds or fail-safe behavior analyses.
- Domain generalization across regions and rules is untested: the model encodes traffic knowledge (IDKB), but performance across countries with different signage, right-of-way rules, and cultural driving norms remains unknown.
- Reward design limitations in RL: the paper focuses on deterministic and template-checkable tasks (classification, grounding IoU), leaving open how to design rewards for continuous control, stochastic settings, multi-objective safety-efficiency trade-offs, or reasoning quality beyond format compliance.
- CoT quality and provenance are not audited: CoT traces generated by external models (e.g., DeepSeek-R1) may be noisy or biased; there is no filtering strategy, quality scoring, or analysis of whether CoT improves correctness vs. merely verbosity.
- Latency, throughput, and resource footprint are missing: inference speed on multi-image/video inputs, memory usage with 32k tokens, hardware requirements, and feasibility for real-time on embedded platforms (cars/robots) are not reported.
- Scaling laws and model size effects remain unexplored: the impact of scaling (beyond the 7B backbone), dataset size vs. performance, and whether larger or smaller models yield different cross-embodiment benefits is not studied.
- Failure analysis is absent: the paper does not present qualitative/quantitative breakdowns of common errors, corner-case failures, or misreasoning patterns in driving planning, intent prediction, or spatial grounding.
- Fairness and ethical considerations are missing: potential demographic, geographic, and environmental biases, privacy concerns (web data), and societal risk in safety-critical deployment are not assessed.
- Reproducibility gaps: exact dataset counts, preprocessing, prompt templates, negative answer mining strategies (e.g., EgoPlan-IT), and evaluation scripts are not fully specified for independent replication.
- Generalization to new embodiments is unknown: applicability to drones, mobile manipulators, or industrial arms, and the ease of adapting to novel embodiments or tasks beyond those curated is not evaluated.
- Interpretability beyond CoT is limited: there is no analysis of whether model internals (attention maps, token-level attribution, visual grounding consistency) align with CoT narratives or support trust in safety-critical settings.
- Integration with maps and routing is absent: how the model would incorporate HD maps, route planning, and constraints (speed limits, lane rules) to produce compliant high-level driving plans is not demonstrated.
- Consistency of reasoning with control constraints is unverified: the logical justifications in driving reasoning are not checked against kinematic feasibility, legal constraints, or real-world maneuver executability.
- License and usage constraints of aggregated datasets are not discussed: mixing multiple sources (web images, academic sets, proprietary annotations) raises licensing, redistribution, and IP concerns that remain unaddressed.
Practical Applications
Below is an overview of practical, real-world applications that follow directly from the model’s findings, methods, and innovations. Each item is specific, actionable where possible, and linked to sectors, potential tools/workflows, and feasibility assumptions.
Immediate Applications
These applications can be piloted or deployed now with human oversight and appropriate integration.
- Fleet incident triage and explainability for autonomous driving
- Sector: automotive, logistics, insurance
- Tools/Products/Workflows: “AD Scene QA API” to ingest dashcam/multi-camera video; automatic identification of hazardous objects/events; chain-of-thought (CoT) reasoning reports that justify maneuvers and rule adherence; event timelines for near-miss analysis
- Assumptions/Dependencies: high-quality synchronized camera feeds; integration into post-drive analytics; human review for policy/legal use; model is not a driving controller
- Driver training companion and safety coaching
- Sector: education, transportation, consumer apps
- Tools/Products/Workflows: mobile app that analyzes recorded trips and surfaces mistakes (e.g., missed pedestrian, unsafe gap) with CoT explanations; scenario playlists from benchmarks for practice
- Assumptions/Dependencies: privacy safeguards; device or cloud compute; regional traffic rule knowledge adaptation
- Autonomous driving dataset auto-labeling and QA augmentation
- Sector: software/AI, data operations
- Tools/Products/Workflows: “Autonomous Driving Auto-Labeler” that pre-annotates regional objects, intent labels, and reasoning justifications; triages corner cases; template-based validation via RL rewards (IoU, format compliance)
- Assumptions/Dependencies: annotation guidelines; calibration metadata; human-in-the-loop verification
- In-vehicle vision-language co-pilot (advisory, non-control)
- Sector: automotive, consumer electronics
- Tools/Products/Workflows: real-time hazard callouts, signal/road-marking interpretation, rule reminders with concise rationales; safe/unsafe meta-action advisories (e.g., “wait before changing lanes”)
- Assumptions/Dependencies: edge inference latency; robust multi-camera support; clarity that system is advisory-only
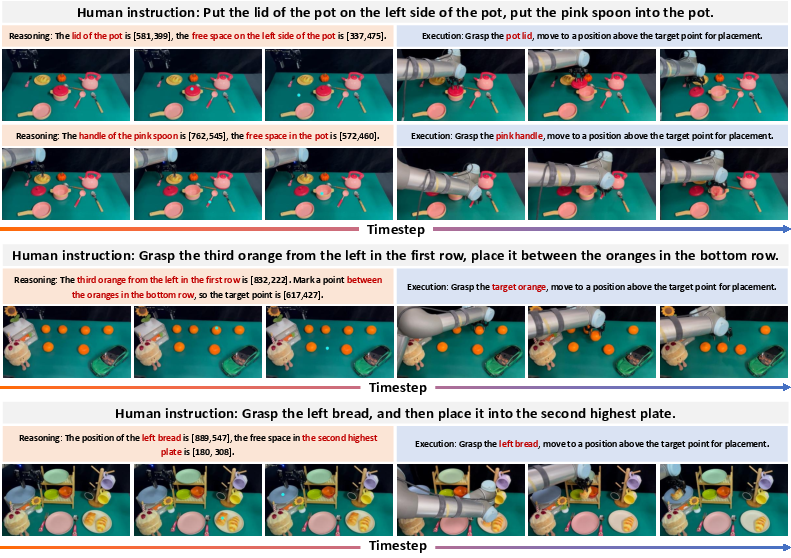
- Warehouse and fulfillment robotics: pick-point and placement assistance
- Sector: robotics, manufacturing, e-commerce logistics
- Tools/Products/Workflows: “Affordance Server” for grasp points and “Where2Place” free-space detection; natural-language-to-action sequence planning for pick-and-place; task-level CoT explanations for operators
- Assumptions/Dependencies: camera pose and gripper calibration; closed-loop control handled by robot stack; safety interlocks and stop conditions
- Home service robots: instruction grounding and task planning
- Sector: consumer robotics, smart home
- Tools/Products/Workflows: “Embodied Task Planner” that converts user instructions into executable steps; referential resolution in clutter (RoboRefIt-like); spatial reasoning for navigation and object finding
- Assumptions/Dependencies: platform integration (ROS/robot APIs); physical safety rules; domain adaptation to household layouts and objects
- AR spatial guidance for procedures and maintenance
- Sector: AR/VR, education, field service
- Tools/Products/Workflows: “Spatial Guidance SDK” to overlay directions, distances, and placements on live camera feeds; multi-step task plans sourced from Cosmos/EgoPlan-like data
- Assumptions/Dependencies: device pose tracking; acceptable mobile inference latency; calibrated cameras for 3D cues
- Egocentric procedure compliance analysis
- Sector: industrial QA, operations
- Tools/Products/Workflows: analyze first-person videos against SOPs; identify missing steps, unsafe actions, and suggest next actions; store CoT rationales for audits
- Assumptions/Dependencies: SOP mapping; domain adaptation to specific workflows; privacy and worker consent controls
- 3D spatial understanding for digital twins and site monitoring
- Sector: AEC (architecture/engineering/construction), smart cities
- Tools/Products/Workflows: “Spatial Understanding API” for monocular 3D box regression, object relationship QA, and navigational hints; route-checking for indoor/outdoor movement
- Assumptions/Dependencies: camera calibration and metadata; target accuracy thresholds; handling of occlusions and clutter
- Academic baselines, methods replication, and cross-domain evaluation
- Sector: academia, R&D labs
- Tools/Products/Workflows: open-source code/models for 4-stage training (embodied + driving SFT, CoT, RL); reproducible benchmarks across 17 embodied and 12 driving tasks; ablation templates for positive transfer studies
- Assumptions/Dependencies: compute resources; dataset licensing; responsible release practices for derived datasets
- Policy and compliance reporting for driving incidents
- Sector: public policy, regulatory, legal
- Tools/Products/Workflows: “Compliance Auditor” to generate transparent, step-by-step reasoning alongside scene perception; rule citation and defensive driving rationale; standardized incident summaries
- Assumptions/Dependencies: non-binding analyses requiring expert review; jurisdiction-specific rules; audit trails and provenance
- Accessibility and novice support for road interpretation
- Sector: education, daily life
- Tools/Products/Workflows: consumer app that explains complex scenes (e.g., “why did the car slow down?”); highlights attention targets (pedestrians, signals) and rationales
- Assumptions/Dependencies: clear UX, privacy-first design; localization to languages and traffic norms
Long-Term Applications
These applications will require further research, scaling, integration, certification, and/or new hardware/software capabilities.
- Unified cross-embodied generalist agent for vehicles and robots
- Sector: robotics, automotive
- Tools/Products/Workflows: “Embodied Agent OS” spanning indoor manipulation and outdoor navigation; shared reasoning modules; continuous learning across domains
- Assumptions/Dependencies: robust closed-loop control stack; safety certification; extensive sim-to-real adaptation
- Interpretable planning core for higher levels of autonomy (L3–L4)
- Sector: automotive
- Tools/Products/Workflows: on-vehicle foundation model that fuses cameras, LiDAR, radar with MiMo-style reasoning; transparent justifications for trajectory and policy decisions
- Assumptions/Dependencies: sensor fusion beyond RGB; real-time constraints; strict validation and regulatory approval
- City-scale traffic reasoning and multi-agent intent prediction
- Sector: smart cities, transport policy
- Tools/Products/Workflows: “City Traffic Reasoning Platform” for proactive congestion management and incident prevention; multi-camera roadside feeds with CoT explanations
- Assumptions/Dependencies: access to infrastructure video; privacy and governance; compute at edge or centralized
- Coordinated emergency response among autonomous vehicles and robots
- Sector: public safety, defense
- Tools/Products/Workflows: shared situational awareness and spatial reasoning; task allocation with interpretable rationales for responders and autonomous agents
- Assumptions/Dependencies: communication reliability; adversarial robustness; fail-safe designs and human oversight
- Elder care and assistive home robotics with advanced spatial/task reasoning
- Sector: healthcare, consumer robotics
- Tools/Products/Workflows: “Care Companion Planner” for medication fetching, tidying, and guided navigation; safety-aware task plans and interaction explanations
- Assumptions/Dependencies: stringent safety constraints; ethical use; personalization to user routines and environments
- Generalizable industrial automation from egocentric demonstrations
- Sector: manufacturing, logistics
- Tools/Products/Workflows: leverage long-horizon reasoning to convert demonstrations into executable programs; minimal task-specific coding
- Assumptions/Dependencies: high-fidelity perception-control loops; adaptation to varied tools/materials; formal verification for critical steps
- Embodied education platforms for physics, traffic logic, and spatial reasoning
- Sector: education technology
- Tools/Products/Workflows: interactive curricula using real-world videos; students inspect CoT; sandbox scenarios to explore cause-effect in physical tasks and driving
- Assumptions/Dependencies: curricular alignment; assessment design; content moderation
- Energy-efficient operations via planning-aware routing for fleets and EVs
- Sector: energy, transportation analytics
- Tools/Products/Workflows: use status prediction and planning rationales to minimize stop-and-go, optimize charging and route timing
- Assumptions/Dependencies: telematics integration; weather/traffic feeds; business rules
- Insurance and finance risk products based on interpretable video analytics
- Sector: finance/insurance
- Tools/Products/Workflows: claim triage and risk scoring with explicit reasoning; anomaly detection and fairness audits
- Assumptions/Dependencies: regulatory permissions; bias mitigation; standardized reporting
- Standards and certification for VLM-based interpretable autonomy
- Sector: policy, standards bodies
- Tools/Products/Workflows: benchmark suites that combine perception, prediction, and planning with CoT; protocols for incident reconstruction and accountability
- Assumptions/Dependencies: multi-stakeholder consensus; transparent datasets; long-term governance
Notes on feasibility across applications:
- The model processes single/multi-image and video inputs and has strong offline reasoning; safety-critical real-time control requires additional verification and integration.
- Multi-camera benefits depend on calibration and synchronization; performance may vary across domains not well-represented in training data.
- Many deployments should start as advisory systems with human-in-the-loop oversight.
- Hardware acceleration (edge GPUs/NPUs) and optimized inference are necessary for low-latency scenarios.
- Legal, privacy, and ethical considerations (data retention, consent, bias) must be addressed before production use.
Glossary
- 2D coordinate predictions: predicting precise x–y positions in the image plane for localization tasks; "requiring precise 2D coordinate predictions."
- 3D bounding box localization: identifying and localizing 3D boxes of objects within a scene; "To advance this paradigm, we introduce 3D bounding box localization."
- 3D Question Answering (3D-QA): answering questions that require holistic understanding of a 3D scene; "for 3D Question Answering (3D-QA), a task requiring holistic 3D scene understanding from textual questions."
- Action Decision: predicting high-level meta actions for the ego vehicle in dynamic scenarios; "Action Decision The task's primary goal is to predict the ego vehicleâs meta actions in dynamic driving scenarios."
- Affordance Prediction: inferring possible interactions that objects or scenes afford; "Affordance Prediction: inferring actionable interaction possibilities from visual scenes to enable effective interactions;"
- Autonomous Driving: the domain of self-driving vehicle perception, prediction, and planning; "both Autonomous Driving and Embodied AI."
- Camera coordinate system: a 3D reference frame tied to the camera used for spatial reasoning; "requiring the model to regress 3D boxes in a camera coordinate system."
- Chain-of-Thought (CoT): explicit, step-by-step reasoning used for training and inference; "Stage 3: Chain-of-Thought Fine-tuning enhances complex reasoning by incorporating generated rationales."
- Driving Planning: generating safe, rule-compliant driving maneuvers with justifications; "Driving Planning: generating safe driving maneuvers with explainable justifications based on traffic logic, ensuring compliance with road rules while optimizing safety and efficiency."
- Driving Reasoning: producing driving decisions together with the underlying reasoning process; "Driving Reasoning Different from action decision, driving reasoning is to predict the ego vehicleâs driving decisions while explicitly outputting the corresponding reasoning process."
- Egocentric perspective: first-person viewpoint crucial for embodied task execution; "develop robust spatial understanding from an egocentric perspective, which is essential for embodied task execution."
- Egocentric video: video captured from a first-person viewpoint used for embodied and navigation tasks; "each sample combining egocentric video inputs with questions about 3D object relations and navigational actions."
- Ego vehicle: the self-driving vehicle whose behavior and decisions are being modeled; "then provide the ego vehicle with optimal driving suggestions while implicitly embedding the reasoning logic in the advice."
- Embodied AI: AI systems that perceive, reason, and act within physical environments; "specialized embodied VLMs have emerged in domains such as autonomous driving and embodied AI"
- Environmental Perception: understanding the driving scene, including semantics and geometry; "Environmental Perception: understanding traffic scenes through semantic and geometric analysis to scene comprehension, region-level interpretation and potential hazards detection;"
- Group Relative Policy Optimization (GRPO): a reinforcement learning algorithm using group-wise normalization of advantages; "We implement the Group Relative Policy Optimization (GRPO)~\cite{guo2025deepseek} algorithm, which samples multiple responses for each query and computes advantages through group-wise normalization."
- Intent Prediction: forecasting future behaviors of traffic participants; "Intent Prediction A core task in autonomous driving perception and planning, its primary goal is to forecast the future driving behaviors of surrounding traffic elements in dynamic driving scenarios."
- Intersection over Union (IoU): an overlap metric for evaluating predicted vs. ground-truth regions; "it is assessed via IoU between predicted and ground-truth boxes or point in mask."
- Kinematic relationships: motion-related relationships among entities in a scene; "reason about the kinematic relationships among vehicles, pedestrians, and infrastructure elements."
- LLM: a large neural LLM used for textual understanding and reasoning; "aligned with a LLM; and (3) the LLM itself for textual understanding and reasoning."
- Latent space: a representation space into which inputs are projected for alignment with the LLM; "a projector that maps visual encodings to a latent space aligned with a LLM"
- Monocular 3D understanding: inferring 3D structure from a single RGB image; "provides crucial supervision for monocular 3D understanding and domain generalization."
- Multi-layer perceptron (MLP): a feedforward neural network used as the projector; "The projector is implemented using a multi-layer perceptron (MLP), which maps visual tokens to the LLM's input space."
- Multi-view spatial reasoning: reasoning across multiple camera views for consistent scene understanding; "including multi-view spatial reasoning, temporal consistency across video sequences, and complex traffic scenario analysis."
- Object permanence: maintaining awareness of objects’ existence across time/frames; "maintain object permanence across frames"
- Optical Character Recognition (OCR): extracting text content from images; "facilitating robust OCR capability"
- Projector: a module that maps visual features into the LLM-compatible latent space; "a projector that transforms these visual encodings into a latent space compatible with the LLM."
- Reinforcement Learning Fine-tuning: optimizing model behavior using reward signals after supervised training; "Stage 4: Reinforcement Learning Fine-tuning further refines task-specific performance via GRPO~\cite{guo2025deepseek} optimization."
- RGB-D: visual modality combining color (RGB) and depth data; "The dataset features multi-modal RGB-D inputs paired with textual instructions requiring precise 2D coordinate predictions."
- Referring Expression Comprehension (REC): locating or identifying targets based on natural-language referring expressions; "supporting tasks such as referring expression comprehension (REC) and segmentation (RES)."
- Regional Object Localization: localizing critical objects that influence driving decisions; "Regional Object Localization A object-level positioning task, its core objective is to achieve accurate target detection for critical objects that influence driving decisions in driving scenarios, rather than detecting all objects without distinction."
- Regional Object Understanding: detailed analysis of localized objects’ attributes, states, and impacts; "Regional Object Understanding As a object-level perception task, its core objective is to enable fine-grained QA interactions for specific target objects within driving scenarios, focusing on detailed recognition, attribute analysis, and behavioral impact interpretation of localized objects."
- Self-attention mechanism: an attention mechanism relating tokens to each other to extract features; "This component employs a self-attention mechanism to extract significant features from the input data, allowing the model to discern complex patterns and relationships."
- Spatial Affordance Localization: identifying feasible regions for placing or manipulating objects; "Spatial Affordance Localization: identifying suitable placement regions in free space or on supporting surfaces to facilitate object manipulation."
- Spatial Understanding: reasoning about directions, distances, layouts, and spatial relations; "Spatial Understanding: reasoning about spatial relationships, including directions, distances, and layouts, to facilitate navigation and interaction within the environment."
- Status Prediction: predicting behaviors or states of agents and their interactions; "Status Prediction: forecasting the behaviors of agents and multi-agent interactions to facilitate proactive decision-making;"
- Temporal reasoning: reasoning over time in video to understand events and dynamics; "Video Understanding materials enable temporal reasoning through dense event captioning and dynamic scene analysis"
- Vision Transformer (ViT): a transformer-based encoder for visual inputs; "a Vision Transformer (ViT) for encoding visual inputs;"
- Vision-LLM (VLM): a model jointly processing visual and textual modalities; "Vision-LLMs (VLMs)~\cite{gpt4o, team2025gemini, bai2025qwen2, wang2025internvl3, seed15, chen2025nanovla} demonstrate significant promise in advancing multimodal perception, understanding, and reasoning capabilities."
- Visual Grounding: aligning text phrases with specific regions or objects in images; "Visual Grounding data cultivates fine-grained object-level localization and cross-modal alignment across diverse scenes, enabling precise region-reference understanding and object attribute recognition."
- Visual tokens: discrete embeddings representing visual features for downstream processing; "The visual tokens generated through this process are formatted for seamless integration with the subsequent stages of the architecture."
Collections
Sign up for free to add this paper to one or more collections.

