Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
Abstract: Expressive continuous control policies, such as diffusion and flow models, form the backbone of recent advances in scaling imitation learning for simulated and real robot control. While they are known to scale stably in the supervised imitation learning setting, incorporating them into reinforcement learning (RL) pipelines for policy improvement has proven more difficult. It often requires specialized training objectives or backpropagating through denoising processes, which cause well-known issues with stability and affect scalability. In this paper we study the question of whether simple policy improvement schemes at test time alone, leaving stable supervised policy training intact, can be a competitive alternative which sidesteps these issues. To this end, we propose QGF (Q-Guided Flow), an RL algorithm that performs policy optimization entirely at test time. QGF works by pre-training both a reference flow policy (via a standard behavioral cloning objective) and a value function critic and, at test time, using the value gradient to guide the reference policy to generate higher-value actions without any additional policy learning. Empirically, QGF outperforms prior test-time RL methods on single-task and goal-conditioned offline RL benchmarks with high-dimensional action spaces, and is competitive with state-of-the-art training-time algorithms while being much cheaper to run. Moreover, it exhibits favorable scaling with model size by avoiding the instability of actor-critic training, offering a practical and effective alternative RL algorithm with expressive policies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to make robot and game-playing AI choose better actions without making training complicated or unstable. The method is called QGF (Q‑Guided Flow). It keeps training simple and safe, then uses a smart “nudge” at the moment of action (test time) to get higher rewards.
What problem does it try to solve?
Modern AI for control (like robots) often uses powerful “flow” or “diffusion” models to pick actions. These models are great at copying what they see in data (imitation), but they’re hard to combine with reinforcement learning (RL) because RL training can get unstable and expensive. The paper asks: can we leave training simple and only do the reward‑seeking part at test time, when the robot is actually choosing what to do?
Key questions in simple terms
- Can we train a policy (how the AI picks actions) by just copying a dataset, and train a separate judge (a value function, also called a critic) to score actions?
- Then, at test time, can we use the critic’s advice to gently steer the policy’s action toward better ones, without retraining the policy?
- Can this be done in a way that’s cheap, stable, and works well even on hard tasks?
How the method works
First, a few plain-language ideas:
- Policy: the AI’s way to choose actions from a state (like a recipe for what to do).
- Critic (Q-function): a judge that scores how good an action is in a state (higher is better).
- Flow/Diffusion policy: a model that creates actions step by step, like cleaning up a blurry image until it’s clear. Each “denoising” step brings you closer to a final action.
- Gradient: a direction that tells you how to change something to make a score go up.
The usual problems:
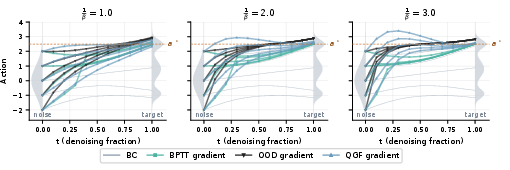
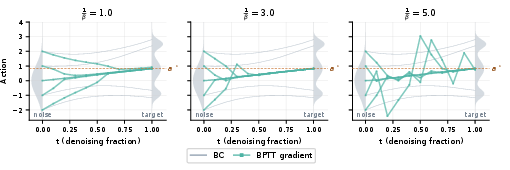
- Taking the critic’s gradient in the middle of the denoising steps is unreliable (the critic was trained on clean, final actions, not half-finished “noisy” ones).
- Backpropagating through all denoising steps to reach the final action is slow and unstable.
QGF’s simple test-time trick:
- During training:
- Train the policy by imitation only (behavioral cloning), so it copies actions from the dataset. This is stable and scales well.
- Train a critic separately to score actions.
- At test time (when choosing an action):
- The flow policy starts producing an action in small steps (denoising).
- QGF pretends to jump to a nearly finished action in one quick “big step” (a first-order/Euler step). Think of it like fast-forwarding to see what the final action would look like.
- Ask the critic for the gradient at this almost-finished action: “Which way should I nudge to get a higher score?”
- Add that gentle nudge to the policy’s next denoising step.
- Repeat for the remaining steps until you get the final action.
Why this is clever:
- It avoids asking the critic about messy, halfway actions it wasn’t trained on.
- It avoids expensive backpropagation through many steps.
- It uses a simple, low-variance gradient signal that’s more reliable in practice.
In short: train simply, and at test time, steer each step a bit toward what the critic likes.
What did they find?
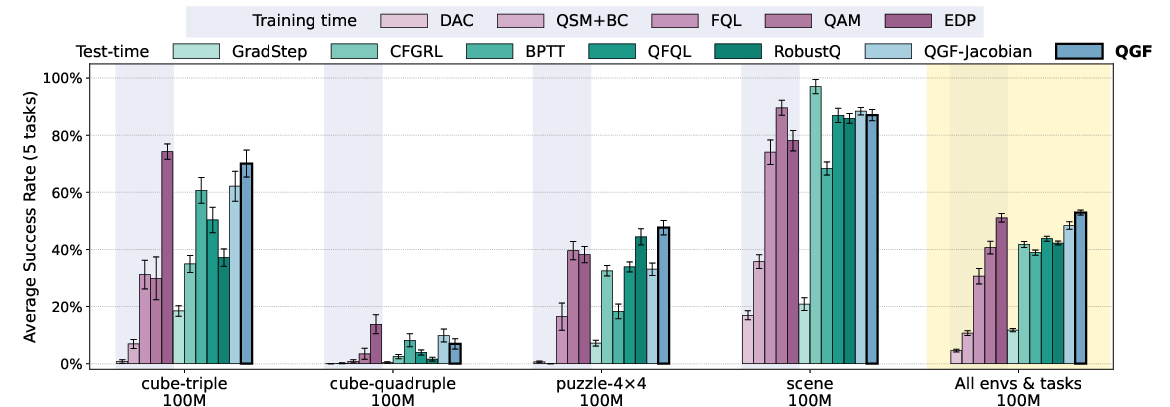
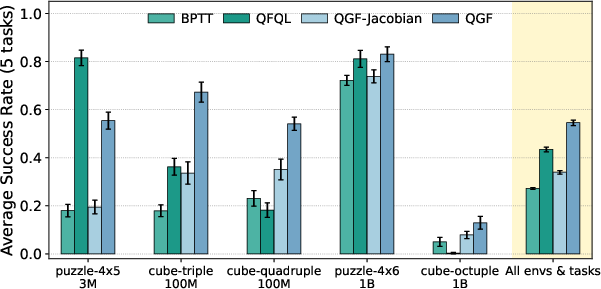
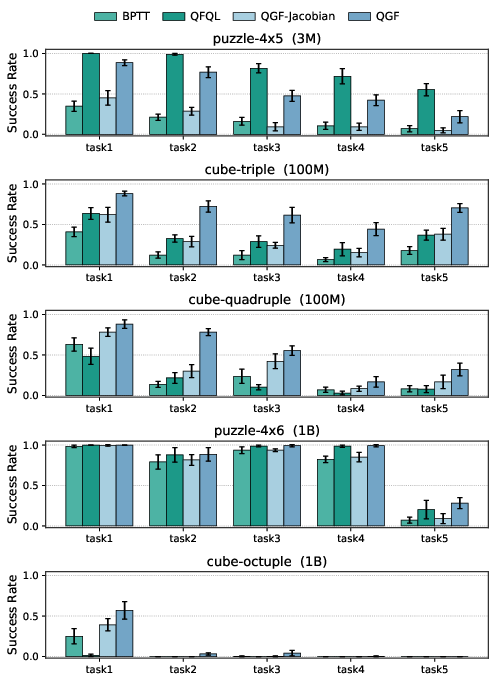
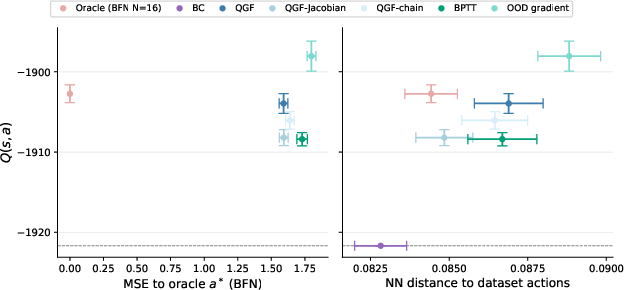
- QGF beats other test-time methods:
- It outperforms methods that either sample many actions and pick the best (best-of-N), or that try to nudge only at the very end, or that use noisy mid-step gradients.
- QGF is competitive with strong “training-time” RL methods:
- Even compared to methods that optimize the policy for rewards during training, QGF performs similarly or better, while being simpler and cheaper to run.
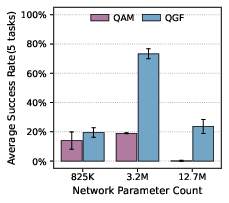
- It scales well:
- As model size grows, QGF improves more than some training-time baselines, because training remains stable (pure imitation), and the guiding happens only at test time.
- It handles harder, long-horizon tasks:
- On challenging goal-reaching tasks with long sequences of actions, QGF often performs best, showing its guidance is robust.
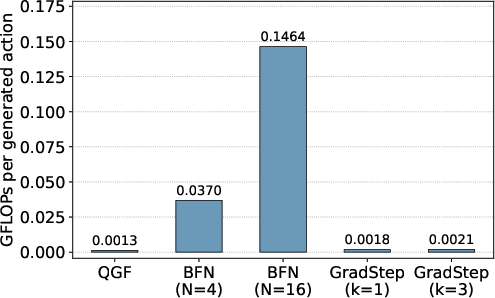
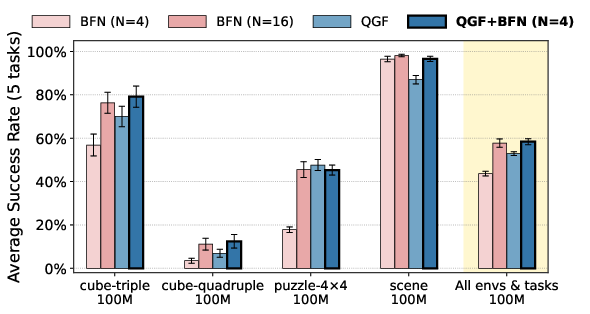
- It’s efficient:
- Best-of-N can be very expensive (you must generate many full actions to pick one). QGF often does better with much less compute. If you do have extra compute, combining QGF with a small amount of best-of-N can give even better results.
- It’s flexible:
- QGF works with different kinds of critics. If you improve the critic, QGF gets better too.
Why this matters
- Simpler, safer training: You can train big, expressive policies with stable imitation learning, no tricky RL loops.
- Strong performance with low fuss: You get the benefits of RL by doing the “smart steering” at test time, which is cheaper and easier to control.
- Practical for robots and complex control: Works well in high‑dimensional action spaces and long tasks, where sampling many actions is too slow.
- Scales with model size and compute: As models and datasets grow, this approach stays stable and gets stronger.
In a sentence: QGF shows that you can keep training simple and stable, then use a lightweight, smart test-time nudge from a critic to get high-reward behavior—often matching or beating more complicated RL training methods.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to help guide future investigations:
- Lack of theoretical guarantees: no analysis of convergence, monotonic policy improvement, or bounds on bias induced by using a first-order Euler clean-action approximation with an identity Jacobian.
- Justification of identity Jacobian: dropping the Jacobian is empirically effective but theoretically unmotivated; it remains unclear when this approximation preserves descent directions and when it fails (e.g., under high curvature or nonlinearity in ).
- Conditions for Euler-step validity: the paper does not characterize when a single large Euler step reliably approximates the denoised action, how the error scales with , or how the choice of solver/step size affects guidance quality and stability.
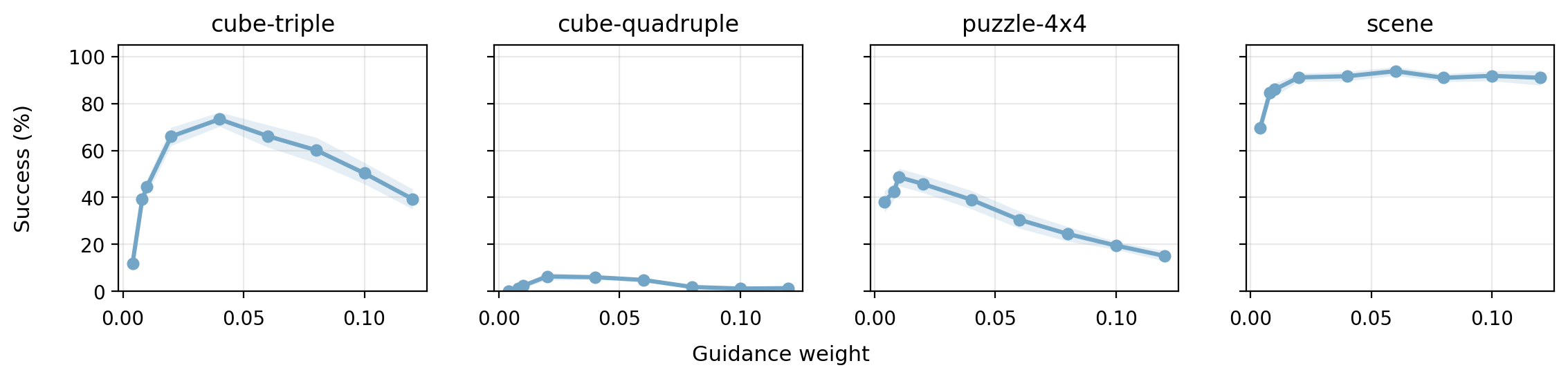
- Guidance weight scheduling: the effect of varying across denoising time (e.g., early vs. late guidance, annealing) is not examined; there is no principled method to adapt to avoid over-optimization or Q-exploitation.
- Sensitivity and robustness to critic errors: while QGF avoids the worst OOD gradients, it still relies on at approximate clean actions; the failure modes when is miscalibrated, biased, or overestimates values in low-density regions are not systematically analyzed.
- Uncertainty-aware guidance: the method does not incorporate critic uncertainty (e.g., ensembles, conservative penalties, Lipschitz constraints) into the guidance rule to reduce exploitation of spurious Q-gradients.
- Interaction with behavioral constraints: QGF does not explicitly enforce a KL or behavior-regularization term during test-time optimization; how to ensure safe closeness to the dataset policy beyond tuning remains open.
- Stability over long denoising chains: cumulative effects of repeatedly using gradients computed at approximate clean actions (vs. exact clean actions) across many steps are not analyzed; error accumulation and stability conditions are unstudied.
- Gradient scaling/normalization: the paper does not explore normalizing or regularizing the Q-gradient (e.g., clipping, rescaling by velocity magnitude, line search), which could affect stability and performance across tasks.
- Alternative gradient estimators: beyond identity-Jacobian and BPTT, low-rank, diagonal, or learned surrogate Jacobians (or finite-difference approximations) are not evaluated, leaving a gap between exact and identity approximations.
- Score-based interpretation gap: the derivation assumes access to (or correspondence with) the policy score , yet the implemented guidance only uses the flow velocity and Q-gradient; implications of this mismatch for sampling correctness are not addressed.
- Choice of denoising ODE/SDE and solver: only the ODE with simple Euler integration is tested; whether higher-order solvers, adaptive step sizes, or stochastic denoising (SDE) improve guidance quality is unexplored.
- Generality across policy classes: results focus on flow policies; it remains open how well QGF transfers to diffusion models with explicit noise schedules or to other generative policy families (e.g., normalizing flows with exact likelihoods).
- Applicability to discrete or mixed action spaces: QGF requires differentiability w.r.t. actions; extensions to discrete or hybrid action spaces (e.g., via Gumbel-softmax, implicit relaxation) are not discussed.
- Online RL setting: the method is evaluated offline; it is unknown how QGF behaves with environment interaction (e.g., critic bootstrap bias, distribution shift, nonstationarity) or whether adaptive test-time guidance can accelerate online learning.
- Safety and constraints: the method does not handle action/state constraints or safety requirements; how to enforce constraints during test-time guidance (e.g., via projected gradients or constrained ) remains an open question.
- Generalization and OOD states: while QGF reduces gradient OOD issues at noisy actions, its behavior under state distribution shift (e.g., test states unseen in the dataset) is not studied.
- Hyperparameter sensitivity: there is limited analysis of sensitivity to , number of denoising steps, time discretization, and action chunk size; guidelines for robust tuning are not provided.
- Task and domain breadth: experiments are concentrated on OGBench manipulation with chunked high-dimensional actions; performance in other domains (e.g., locomotion, non-manipulation control, real-robot settings) remains untested.
- Real-time constraints: although FLOPs are compared, latency and wall-clock impact of per-step Q-gradients in real-time control (and potential amortization/parallelization strategies) are not evaluated.
- Data quality dependence: the paper does not analyze how QGF performance varies with dataset quality/diversity (e.g., highly suboptimal or narrow datasets), nor how guidance interacts with severe covariate shift.
- Interaction with better critics: while QGF benefits from a stronger (QAM-based) critic, there is no systematic study of how critic architecture, expectile parameter , regularization, or training regimen affect guidance quality.
- Multi-step test-time compute tradeoffs: beyond small BFN comparisons, the frontier between BFN and gradient guidance (e.g., hybrid strategies, N vs. gradient steps) is not thoroughly mapped for different compute budgets.
- Failure mode diagnostics: tools to detect and mitigate over-optimization on (e.g., monitoring Q-value increases vs. task success, trust-region thresholds, discrepancy metrics to the behavior policy) are not proposed.
- Extensions to hierarchical/goal-conditioned settings: while goal-conditioned results are included, combining QGF with hierarchical policies, latent variable policies, or planning (e.g., at subgoal or skill level) is left unexplored.
Practical Applications
Overview
This paper introduces QGF (Q-Guided Flow), a test-time reinforcement learning (RL) method that improves actions from a pre-trained flow/diffusion policy by adding a value-function (critic) gradient during each denoising step. Key innovations include:
- A low-variance, low-cost gradient estimator that evaluates the critic at an approximated clean action via a single-step Euler integration and omits the Jacobian.
- Avoiding backpropagation through the full denoising chain and avoiding gradients at out-of-distribution (noisy) actions.
- Strong performance in offline RL with high-dimensional action spaces, favorable scaling with model size, and compatibility with multiple critics (e.g., IQL, QAM).
- Test-time compute that can be tuned (and combined with best-of-N sampling) without retraining the policy.
Below are actionable applications grouped by immediacy, with sector links, candidate tools/workflows, and feasibility notes.
Immediate Applications
- Robotics (industrial automation, warehousing, assembly)
- Use case: Improve reliability and success rates of pick-and-place, bin packing, stacking, assembly and long-horizon manipulation using large offline datasets. Train a behavior-cloned flow policy and a critic offline; run QGF at deployment to steer actions toward higher-value behaviors without unstable actor-critic training.
- Tools/workflows:
- QGF inference module integrated into existing diffusion/flow-based controllers.
- Runtime “guidance weight” β as a knob to trade optimality vs. conservatism.
- Optional light best-of-N (e.g., N=4) on top of QGF when latency allows.
- Dependencies/assumptions:
- Sufficient offline data coverage for states/actions and a reasonably accurate critic.
- Real-time compute budget for flow denoising plus critic gradient per step.
- Continuous action spaces and a deployed flow/diffusion policy.
- Simulation-to-Real transfer for manipulators
- Use case: Train policies and critics in simulation on large logged datasets; at deployment, use QGF to bias toward robust, higher-value actions (e.g., higher success or safety margins) without re-training the actor.
- Tools/workflows:
- Offline IQL/QAM critics calibrated with a small amount of real data.
- QGF-based runtime adapter with safety filters (limits, collision checks).
- Dependencies/assumptions:
- Domain gap manageable via critic calibration/regularization.
- Verified safety constraints layered over Q-guided actions.
- Game AI and e-sports analytics
- Use case: Learn from large gameplay logs to create bots that are safe-by-default (behavioral) yet performance-boosted via QGF during execution.
- Tools/workflows:
- Training: BC flow policy on logs + IQL critic on the same logs.
- Deployment: QGF-guided action generation; optional per-situation β scheduling.
- Dependencies/assumptions:
- Stationarity or slow drift in game meta; critic must generalize to test play.
- Animation and motion synthesis (graphics/VR)
- Use case: Generate motion sequences with diffusion policies that balance style and physically/plausibly “good” motions using a learned value (e.g., task completion, energy, comfort).
- Tools/workflows:
- Plug-in QGF guidance into motion diffusion samplers; expose β as a user control.
- Dependencies/assumptions:
- A learned critic aligned with aesthetic/physical objectives and trained on representative data.
- Building energy/HVAC control (model-based simulation or logged-data control)
- Use case: From historical BMS logs, train a flow policy and a critic predicting energy cost/comfort; at runtime, apply QGF to improve efficiency subject to comfort constraints.
- Tools/workflows:
- Offline critic training (IQL or bootstrapped) with cost signals.
- QGF in the building controller; β adjusted by time-of-day or demand response events.
- Dependencies/assumptions:
- Adequate offline data and a critic robust to seasonal/weather variation.
- Control loop latency tolerance for diffusion/flow policy inference.
- Academic RL and control research
- Use case: A stable, low-variance, compute-efficient policy improvement mechanism for flow/diffusion policies in offline RL benchmarks and ablation studies.
- Tools/workflows:
- Direct use of the released codebase to benchmark against training-time RL.
- Systematic sweeps over β and test-time compute; integration with OGBench, DQC.
- Dependencies/assumptions:
- Access to flow/diffusion policy baselines; GPU for inference experiments.
- MLOps for offline RL deployments
- Use case: Operationalize “train BC + value function” pipelines where deployment-time performance is tuned purely by β and optional best-of-N, without retraining models.
- Tools/workflows:
- CI pipelines that train BC flows and critics, then evaluate QGF with different β on held-out logs/sims.
- Monitoring Q-value distributions, critic drift checks, and guardrails.
- Dependencies/assumptions:
- Monitoring infrastructure for critic reliability and behavior deviation.
- Consumer/home robotics
- Use case: Improve success of household manipulation (e.g., tidying, organizing) learned from offline demos; QGF improves reliability without high compute overhead.
- Tools/workflows:
- On-device QGF with small β for safety; occasional cloud-assisted runs with QGF+BFN for difficult tasks.
- Dependencies/assumptions:
- Embedded compute sufficient for flow inference and gradients.
- Safety constraints and user-defined limits enforced.
Long-Term Applications
- Autonomous driving and advanced ADAS
- Use case: Test-time guidance of trajectory policies using a learned value function that encodes safety, comfort, and efficiency; QGF could refine candidate trajectories without re-training the actor.
- Tools/workflows:
- Perception-to-trajectory diffusion policies; critic predicting composite costs.
- QGF with strict safety layers and verifiable constraints.
- Dependencies/assumptions:
- High-assurance critics robust to edge cases and distribution shift.
- Regulatory approvals; deterministic latency guarantees.
- Clinical decision support and robotic surgery
- Use case: Offline treatment or surgical action sequence planning; QGF steers BC policies toward better outcome predictions.
- Tools/workflows:
- Retrospective EHR/surgical logs to train critics/policies; simulation-in-the-loop validation.
- Conservative β and additional causal/robustness validation.
- Dependencies/assumptions:
- Regulatory compliance, clinician-in-the-loop oversight.
- Robustness to confounding, non-stationarity, and sparse outcomes.
- Algorithmic trading and portfolio management
- Use case: QGF-guided action sequences (orders, allocations) learned from historical data, aiming to improve return/risk trade-offs at execution.
- Tools/workflows:
- Offline critic capturing market impact and risk; runtime β scheduling by volatility regime.
- Dependencies/assumptions:
- Non-stationarity handling, tight risk controls; rigorous backtesting and live A/B safeguards.
- Multi-robot and multi-agent coordination
- Use case: Joint action generation with per-agent flow policies and centralized or decentralized critics; QGF to coordinate efficiently at runtime.
- Tools/workflows:
- Critics that model joint returns; communication-aware QGF scheduling.
- Dependencies/assumptions:
- Scalability of joint critics; stability under partial observability and delays.
- LLM-based agents and program synthesis with diffusion/flow decoders
- Use case: Extend QGF-like guidance to sequence generation (e.g., code, plans) by guiding diffusion-style token policies with a learned reward/value model.
- Tools/workflows:
- Reward models or Q-like critics over token sequences; gradient-based guidance in latent/token spaces.
- Dependencies/assumptions:
- Adaptation of the method to discrete/latent token flows; reliable value models for language tasks.
- Embedded and low-power deployments
- Use case: Bring QGF to devices with tight compute/latency budgets by single-step distillation of the denoising process or hardware-accelerated gradients.
- Tools/workflows:
- Distill multi-step flows to single-step flows compatible with QGF-like guidance; custom kernels for critic gradients.
- Dependencies/assumptions:
- Acceptable performance loss from distillation; hardware support.
- Governance, standards, and policy for test-time RL
- Use case: Establish guardrails for critic-guided policies (e.g., acceptable β ranges, stress tests, transparency on test-time compute).
- Tools/workflows:
- Standardized evaluation suites for critic robustness and guidance stability; logging/reporting norms.
- Dependencies/assumptions:
- Cross-industry consensus on metrics and risk thresholds.
Cross-Cutting Assumptions and Dependencies
- Data and critic quality: Success hinges on high-quality offline datasets and reliable critics. Poor critics can be exploited even by QGF; monitoring and guardrails are necessary.
- Action model class: The approach assumes a flow/diffusion policy (iterative denoising); other policy classes require adaptation.
- Latency/compute: QGF is far cheaper than best-of-N sampling but still requires per-step gradients; ensure real-time constraints are met.
- Safety and constraints: In safety-critical settings, integrate hard constraints, verified safety filters, or conservative β to bound deviation from behavior.
- Distribution shift: For non-stationary environments (finance, driving), maintain critic recalibration and drift detection; consider robust or risk-sensitive critics.
- Tunable optimality: β is a deployment-time knob; establishing procedures for selecting β per context is important for feasibility and safety.
These applications leverage the core strengths of QGF—stability, test-time tunability, and compatibility with expressive flow/diffusion policies—offering practical pathways for deployment today and clear directions for future, safety-critical, or more complex scenarios.
Glossary
- Action chunking: Executing sequences of multiple low-level actions as a single higher-dimensional action output. "We follow the action chunking setting~\citep{li2025reinforcement} with a chunk size of ."
- Actor-critic: A class of RL methods that train a policy (actor) alongside a value estimator (critic), which can be unstable in practice. "avoiding the instability of actor-critic training"
- Adjoint matching: A training technique that replaces backpropagating through a denoising process by matching adjoint dynamics, used to optimize policies against a critic. "QAM~\citep{li2026q} uses adjoint matching to replace back propagating through the denoising process;"
- Advantage (values): A measure of how much better an action is compared to the baseline value in a state; used as conditioning signal in guided sampling. "CFGRL~\citep{frans2025diffusion}, which trains a policy by conditioning it on advantage values and samples with classifier free guidance at test time;"
- Backpropagation through time (BPTT): Computing gradients through a multi-step process (e.g., denoising or temporal unrolling), which can be costly and unstable. "performing expensive, high-variance backpropagation through time,"
- Best-of-N (BFN) sampling: A test-time strategy that samples N candidate actions and selects the one with the highest critic value. "best-of-N (BFN) sampling strategy"
- Behavior policy: The data-collecting policy whose state-action distribution defines the offline dataset. "a behavior policy ."
- Behavioral cloning (BC): Supervised imitation of behavior policy actions to train a policy, often used to pre-train expressive policies. "standard supervised learning via behavioral cloning (BC)."
- Classifier free guidance: A sampling technique that guides a generative model without an external classifier by interpolating between conditioned and unconditioned predictions. "samples with classifier free guidance at test time;"
- Classifier guidance: Guiding a generative model’s sampling trajectory using gradients from an external classifier. "This is analogous to performing classifier guidance \citep{dhariwal2021diffusion} with a learned Q function replacing the classifier."
- Critic gradient: The gradient of the learned value function with respect to the action, used to steer action generation toward higher values. "with critic gradient at test time."
- Decoupled Q-learning (DQC): A value-learning approach used in long-horizon settings to improve stability and performance of learned critics. "we train IQL value functions with DQC~\citep{li2025decoupled} since the tasks have a very long horizon."
- Denoising process: The iterative procedure that maps noise to clean samples (actions) in diffusion/flow policies. "actions are generated by an iterative denoising process."
- Diffusion models: Generative models that learn to transform noise into data via iterative denoising steps, often learning the score function. "diffusion models learn a score function directly."
- Euler integration: A first-order numerical method for approximating ODE integration steps, used here to approximate denoising in a single step. "a single, large, Euler integration step"
- Expectile regression: A regression technique targeting asymmetric expectiles; used to fit value functions by emphasizing upper tails of Q-values. "expectile regression loss "
- Flow matching: A generative modeling framework that learns a time-dependent velocity field transporting noise to data by matching linear interpolants. "Flow matching~\citep{lipman2022flow} generative models are parameterized by a time-dependent velocity field "
- Flow policy: A policy parameterized by a flow model whose samples are obtained by integrating a learned velocity field. "during sampling from flow policies."
- Goal-conditioned RL: RL where the policy is conditioned on a desired goal to handle different target outcomes within the same environment. "single-task and goal-conditioned offline RL benchmarks"
- Implicit Q-learning (IQL): An offline RL algorithm that learns Q and V without policy sampling by regressing V to an upper expectile of Q. "we instead rely on Implicit Q-learning (IQL)~\citep{kostrikov2021offline}"
- Jacobian: The matrix of partial derivatives relating changes in noisy actions to changes in approximated clean actions during guidance. "the Jacobian of the denoised action with respect to the noisy action, ."
- KL-regularized RL objective: An RL objective that trades off reward maximization with KL divergence to a behavior policy to avoid distributional shift. "we consider the KL-regularized RL objective with respect to the behavior policy "
- Markov Decision Process (MDP): A formal framework for sequential decision-making defined by states, actions, transitions, rewards, and discount factor. "We consider a Markov Decision Process (MDP)~\citep{sutton1998reinforcement}"
- ODE (Ordinary Differential Equation): A differential equation describing continuous-time dynamics; used to define flow-based policy sampling. "via an ODE:"
- Offline RL: Learning policies solely from a fixed dataset without environment interaction, requiring safeguards against distributional extrapolation. "Offline RL studies how to learn a reward-maximizing policy solely from a fixed dataset without any interactions and environment feedback."
- Out-of-distribution (OOD): Data or inputs outside the distribution seen during training; using Q on such inputs can bias guidance. "can exploit out-of-distribution -values"
- Policy extraction: Deriving a usable policy from learned value estimates, often under behavioral constraints in offline RL. "policy extraction techniques"
- Policy gradient methods: RL approaches that directly optimize expected return by ascending the gradient of performance with respect to policy parameters. "policy gradient methods"
- Q bootstrapping: Training a Q-function using targets that depend on Q evaluated at actions sampled from a policy. "using actions sampled from the policy via bootstrapping"
- Q-function: The expected discounted return starting from a state-action pair when following a policy thereafter. "The -function approximates the expected discounted return from state after taking action and following the policy "
- Reparameterization trick: A gradient estimation method that moves stochasticity outside the network to enable low-variance backpropagation. "the reparameterization trick~\citep{haarnoja2018soft}"
- Score function: The gradient of the log-density with respect to inputs; diffusion models often learn this directly. "diffusion models learn a score function directly."
- Temporal-difference (TD) learning: A value-learning approach using bootstrapped targets based on immediate rewards plus discounted value estimates. "temporal-difference (TD) learning methods."
- Value function: A function estimating expected return from a state (or state-action), used to guide or evaluate policies. "a value function critic"
- Velocity field: The time-dependent vector field that drives the transport from noise to data in flow matching models. "a time-dependent velocity field "
Collections
Sign up for free to add this paper to one or more collections.

