- The paper introduces Q-VGM, a novel RL method that leverages critic gradients as velocity corrections to improve fine-tuning of flow-matching VLA policies.
- It employs an ensemble Cal-QL critic with look-forward clean-action estimation and adaptive selection to refine actions during the denoising process.
- Empirical evaluations on LIBERO, RoboTwin 2.0, and real-world tasks show significant improvements in success rates over traditional fine-tuning methods.
Q-Guided Value-Gradient Matching for Flow-Matching Vision-Language-Action Policies
Motivation and Problem Statement
Recent advances in vision-language-action (VLA) models have substantially increased the generality and expressivity of robot control policy architectures, in particular by leveraging flow-matching models that can handle multimodal and long-horizon action distributions. However, fine-tuning such policies with reinforcement learning (RL) poses significant algorithmic challenges. In contrast to conventional actor-critic or policy-gradient RL, flow-matching policies lack analytically tractable action likelihoods and their iterative denoising process introduces instability in value-backpropagation, especially at large VLA model scales.
Existing value-based and Q-guided RL strategies for flow models either (1) suffer from instabilities by directly backpropagating rewards through the generation chain, (2) only utilize critics at test time without online policy update, or (3) distill critic-improved actions via terminal action labels, thus ignoring intermediate velocity supervision in the flow trajectory. These limitations impede both efficient exploitation of first-order critic information and practical, high-dimensional fine-tuning.
Q-VGM Methodology
Q-Guided Value-Gradient Matching (Q-VGM) introduces a new off-policy RL approach that sidesteps the fundamental limitations of both policy-gradient and naïve value-based fine-tuning for flow-matching VLAs. Q-VGM leverages a value-gradient (VGG-Flow) perspective to translate the critic's action-space gradients into denoising-time velocity field corrections, which are directly learnable by the flow policy.
This procedure involves several architectural and algorithmic innovations:
- Action-Sensitive Critic: The Q-function is an ensemble Cal-QL architecture trained on chunked offline rollouts using compact RLT features for state encoding, augmented by per-layer repeated action injection. This ensures strong sensitivity to local action changes and accurate computation of ∇AQ(s,A).
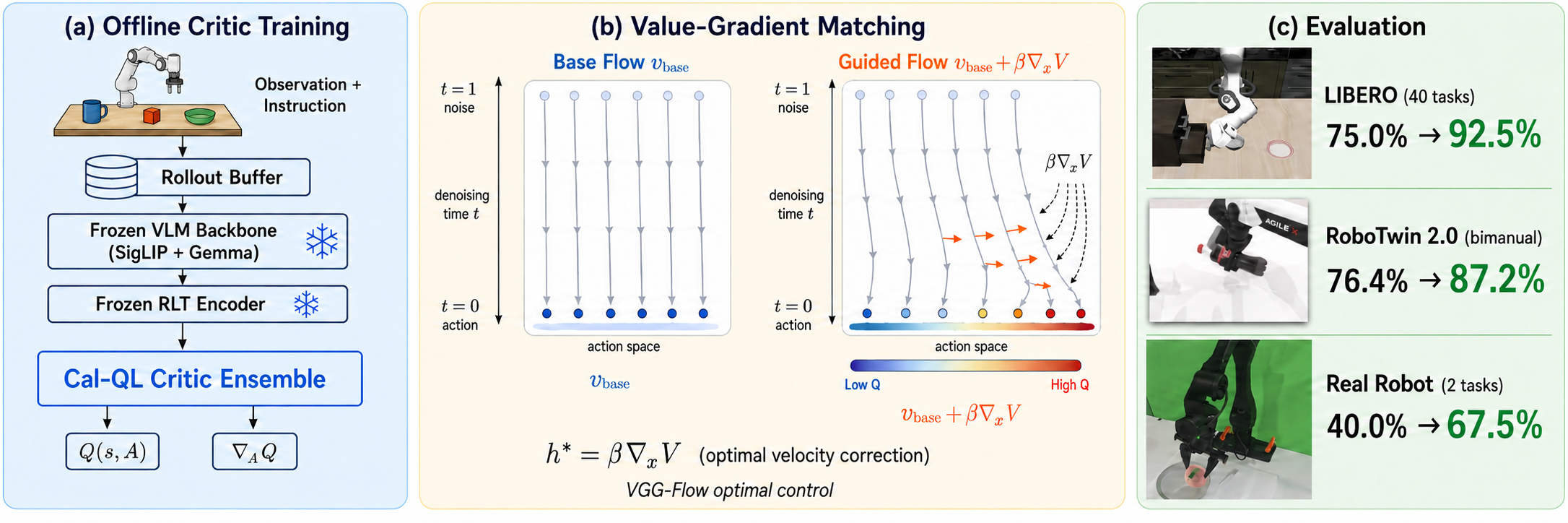
Figure 1: Q-Guided Value-Gradient Matching (Q-VGM). (a) The Cal-QL critic is trained offline using frozen VLM and RLT features; (b) Critic gradients yield denoising-time velocity corrections; (c) Q-VGM fine-tunes a pretrained policy from few-shot SFT.
- Look-Forward Clean-Action Estimation: To bridge the gap between noisy denoising states and critic-evaluable clean actions, each intermediate state along the denoising chain is projected to a clean-action estimate via a single Euler look-forward step on the frozen base flow policy.
- Iterative Q-Gradient Ascent and Keep-Best Selection: Projected clean-action estimates undergo several steps of Q-gradient ascent, searching for improved actions in the critic landscape. An adaptive keep-best mechanism chooses, per-sample, either the original or improved action, effectively inducing an adaptive per-sample trust region.
- Value-Gradient Velocity Correction: The change along the denoising chain from the base action to the (potentially) improved action is converted into a scaled velocity correction at each denoising step (gated by a schedule s(t)), respecting the temporal reliability of the critic signal.
- Residual Velocity Matching: The policy is trained (with frozen backbone) to match these velocity corrections at residual level, thus injecting critic guidance into the flow field directly, rather than only at trajectory endpoints.
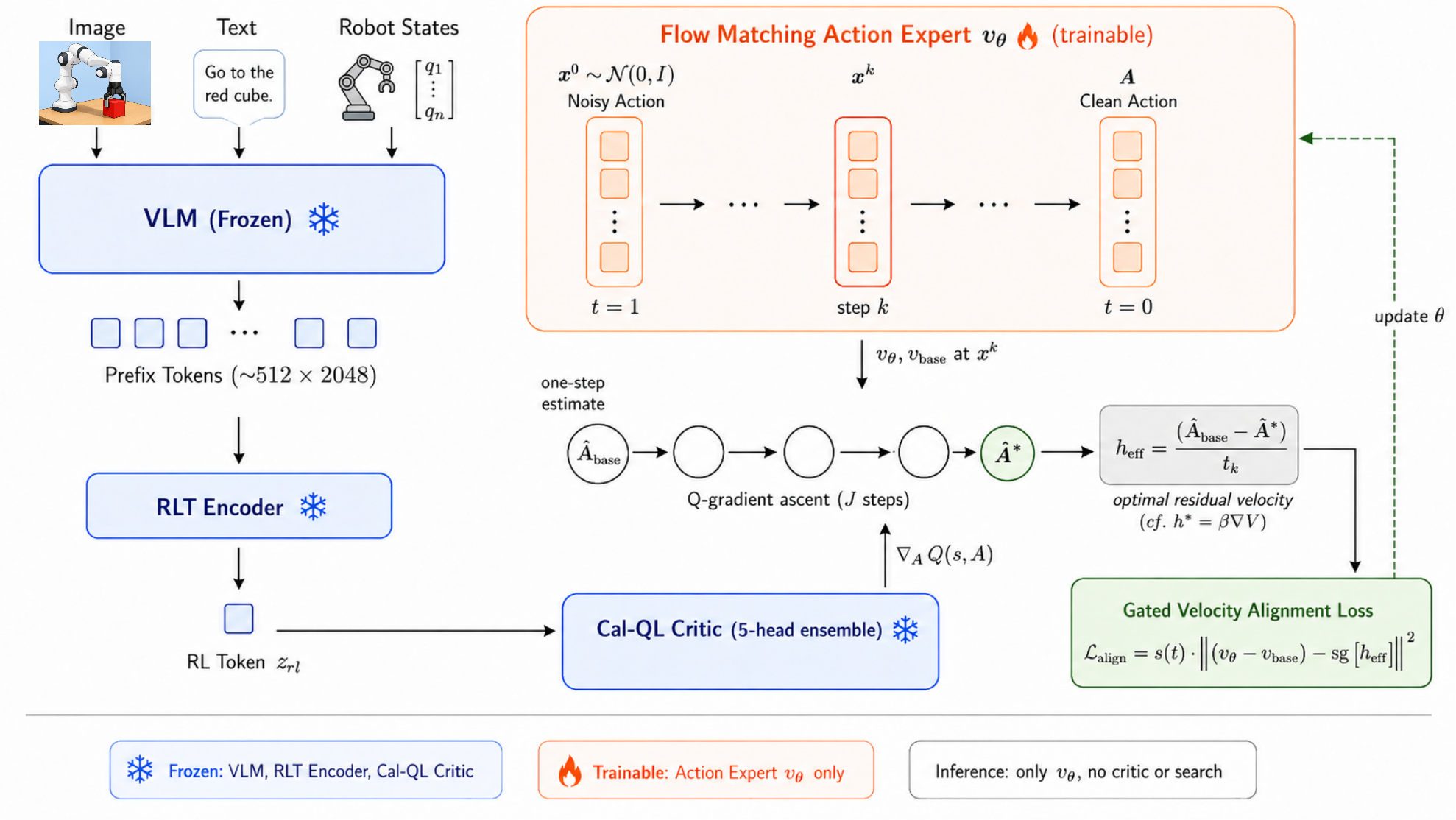
Figure 2: Overview of Q-Guided Value-Gradient Matching (Q-VGM).
Empirical Evaluation
Q-VGM is empirically validated on established VLA fine-tuning benchmarks, including LIBERO (multi-task 7-DoF manipulation, 40 tasks), RoboTwin 2.0 (14-DoF dual-arm manipulation, 10 tasks), and two real-world robot tasks using a physical 7-DoF arm. In all cases, the experiments follow a few-shot SFT initialization, collection of offline rollouts, offline critic training, and then fully offline Q-VGM fine-tuning. Baselines include test-time value guidance, Q-selection, action distillation, and direct critic backpropagation methods.
Q-VGM achieves the following key results, significantly improving initial SFT policies and outperforming all competitors sharing the same backbone and critic:
- LIBERO: Increases average task success from 75.0% (few-shot SFT) to 92.5%, outperforming next-best Q-guided/diffusion methods by 6–23 percentage points.
- RoboTwin 2.0: Improves average success from 76.4% to 87.2%; excels especially on long-horizon and coordination-sensitive tasks.
- Real-Robot Tasks: Demonstrates substantial gains (from 40.0% to 67.5% on average) with only self-generated offline data and no additional expert supervision.


Figure 3: Real-robot evaluation results on the Pick Peach task.
A rigorous ablation study highlights that the largest contributors to final policy performance include the critic architecture's state encoding (using RLT), per-layer action injection, and the policy-side keep-best mechanism and velocity gating. Replacing any of these with more naïve variants markedly reduces empirical returns.
Theoretical Implications and Limitations
By grounding flow-matching RL policy improvement in the value-gradient field rather than terminal labels or unstable backpropagation, Q-VGM formalizes fine-tuning as a stochastic optimal control problem and amortizes critic-improved actions into local velocity updates along the entire denoising chain. Theoretically, this connects Q-based improvements to the underlying ODE flows induced by policy sampling, offering improved stability and efficiency over prior approaches.
One important limitation of Q-VGM is its dependence on the reliability of ∇AQ(s,A), with the critic being accurate primarily near the support of the collected rollouts. The use of a keep-best mechanism and gradient clipping partially addresses extrapolation risk, but broader generalization and scalability—particularly as tasks diversify and horizons grow—remains a challenge. Integrating model-based planning, tighter pathwise regularization, or trust-region strategies into Q-VGM is a potential research direction.
Future Directions
Potential next steps for this research direction in AI RL with flow-matching policies include:
- Dynamic trust-region regularization to further constrain policy improvement within high-confidence regions of the critic.
- Hybrid model-based/model-free architectures using learned environment models to mitigate horizon scaling and bootstrap value estimation.
- Online variants and continual learning, enabling Q-VGM to operate in semi-supervised or interactive settings.
- Extension to other generative policy architectures, including those without explicit ODE-based sampling (e.g., score-based or stochastic generative models).
Conclusion
Q-VGM systematically resolves critical obstacles in RL fine-tuning of large flow-matching VLA policies. By converting offline Q-function gradients into precise, denoising-time velocity corrections and avoiding instabilities of direct Q-backpropagation, Q-VGM enables efficient and practical few-shot initialization followed by self-improving experience replay. Empirical results across simulated and real-robot regimes indicate marked gains in generalization and robustness without additional expert data, establishing Q-VGM as a robust foundation for scalable, value-aware VLA fine-tuning (2606.08015).