- The paper presents a unified approach that integrates a conditional drift field with critic-driven value maximization to improve offline RL performance.
- It employs kernel mean-shift for attraction toward dataset actions and repulsion among candidate actions, maintaining multimodal diversity.
- Empirical evaluations on D4RL and OGBench demonstrate superior robustness and single-pass inference efficiency compared to diffusion and flow-based methods.
Drift Q-Learning: A Unified, Efficient Approach to Offline Policy Improvement
Motivation and Technical Framework
Offline RL demands robust policy learning from static datasets, relying on behavior regularization to prevent exploitation of OOD actions for which value estimates are unreliable. Traditional deterministic actors (e.g., TD3+BC) enforce behavioral fidelity but lack multi-modal expressivity. Recent diffusion and flow-based generative policies remedy this by modeling the behavior distribution and facilitating value-guided improvement, yet those approaches suffer from inference inefficiency (iterative denoising, solver overhead) and increased implementation complexity (auxiliary networks, distillation).
Drift Q-Learning (\ourMethod) marries the expressive regularization of generative models with the efficiency of deterministic methods by leveraging a conditional drift field based on kernel mean-shift, implemented as a single unifying actor network. The method employs a one-step generative mapping from state and noise to action, regularized via an attraction-repulsion drift: attraction toward the dataset action (a+) and repulsion among generated actions, with the critic Q-gradient providing value-driven improvement. This construction prioritizes occupancy of high-value regions within the data support while maintaining stochastic diversity and avoiding collapse onto a single mode.
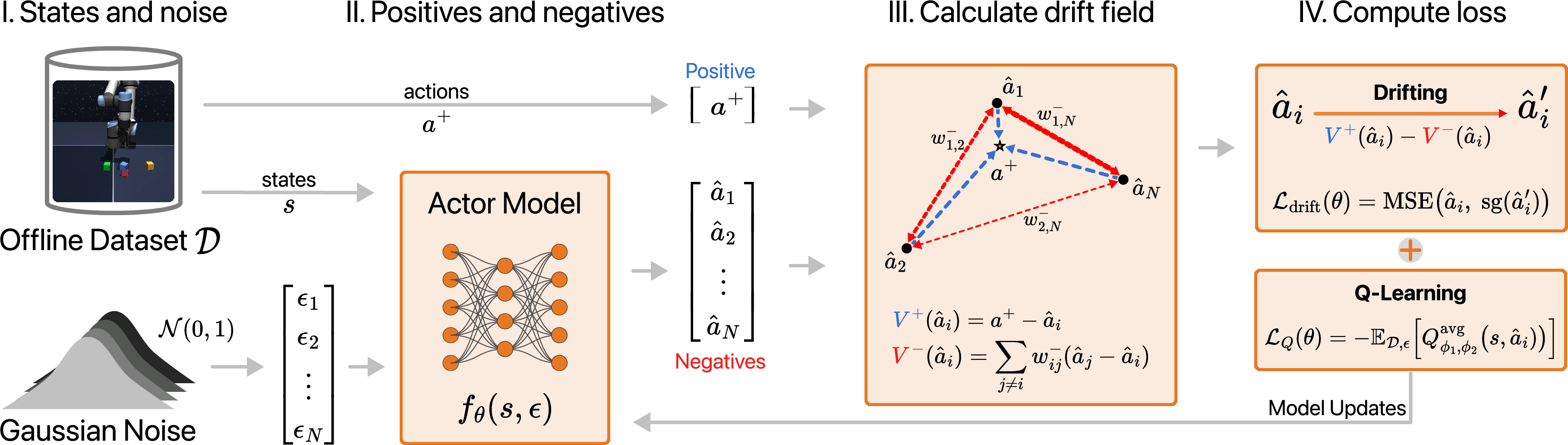
Figure 1: Overview of Drift Q-Learning: state-conditioned candidate actions are generated, subjected to attraction (toward data action) and repulsion (among candidates) via the drift field, and updated by drift and value losses.
Drift Field Construction and Training Objective
The drift field, V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i), is computed per state as follows:
- Attraction: Single-positive mean-shift toward the dataset action, emphasizing behavioral fidelity.
- Repulsion: Kernel-weighted mean-shift over co-generated actions to maintain stochastic diversity and provide multimodality.
The kernel temperature τ regulates repulsion sharpness, with row-wise softmax normalization ensuring robust anti-collapse behavior even with a single positive. The actor loss combines drift regularization and value improvement:
Lactor(θ)=αLdrift(θ)+LQ(θ)
where the Q term is the double-ensemble critic value gradient, and α tunes the trade-off.
Notably, the drift field is not solely relied upon for mode concentration; the critic's value gradient supplies an independent signal for optimal policy improvement, obviating the need for score-matching symmetrizations or multi-temperature aggregation found in previous unconditional drifting models (Lai et al., 8 Mar 2026).
Drift Q-Learning is evaluated on D4RL and OGBench—industry-standard continuous control and navigation suites characterized by complex, multi-modal, and sparse data distributions. Against unimodal and expressive baselines (Gaussian, diffusion, flow), \ourMethod delivers superior or competitive results across 78 tasks, with pronounced gains in hard long-horizon navigation and manipulation. For example, on antmaze-large-st and antmaze-giant-st, \ourMethod achieves success rates well above baselines, especially as data quality deteriorates.
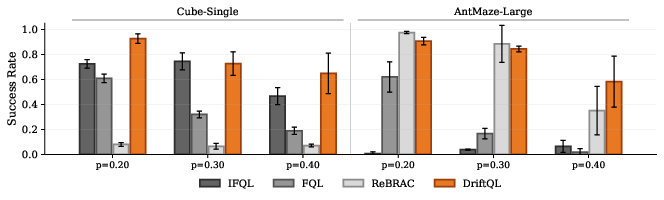
Figure 2: Robustness under random-action corruption: \ourMethod maintains high success rates despite increased random-action fractions, outperforming baselines under severe degradation.
The method further demonstrates resilience to random-action corruption (fraction p replacing dataset actions with uniform noise): the performance remains nearly constant as p increases, unlike diffusion/flow baselines whose scores visibly deteriorate.
Computational Efficiency and Inference Latency
A defining practical benefit of Drift Q-Learning is its inference efficiency. Unlike diffusion models (requiring sequential denoising, K×Nc forward passes) and flow models (ODE integration or distilled networks), Drift Q-Learning produces actions in a single forward pass. Training cost scales as O(N2) with the number of generated samples, but remains comparable to flow-based methods up to N=32. This design enables real-time applicability for high-dimensional tasks, obviating the need for distillation or auxiliary architectures.
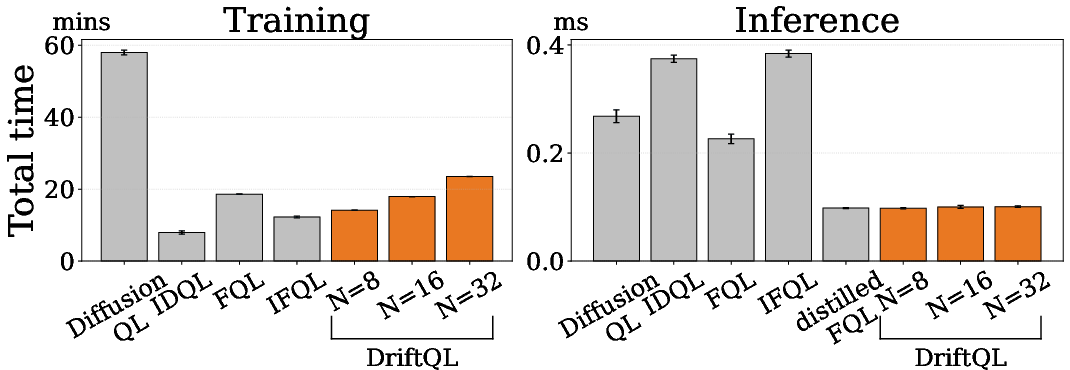
Figure 3: Total training time and inference latency: \ourMethod incurs minimal overhead and achieves single-pass inference irrespective of the number of candidates.
Ablation Analysis: Hyperparameter Sensitivity
A comprehensive ablation study on major hyperparameters (V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)0, V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)1, kernel choice, noise dimension, number of generated samples) validates the method's robustness. Performance is sensitive to V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)2, warranting environment-specific tuning. Other parameters (kernel type, V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)3, noise dimension, V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)4) are broadly stable across varied tasks, confirming that the default configuration is robust and generalizes well. The actor's stochasticity, governed by noise and repulsion, ensures multimodal support without sacrificing convergence.
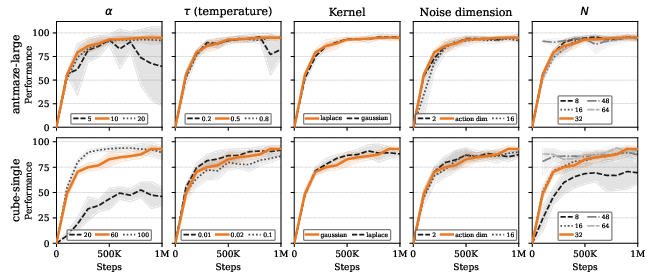
Figure 4: Ablation study: success rates versus training steps across hyperparameters; only the behavioral regularization weight (V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)5) materially affects performance late in training.
Theoretical and Algorithmic Implications
Drift Q-Learning represents a conceptual middle ground between deterministic regularization (TD3+BC) and high-capacity generative methods (diffusion/flow). It exploits kernel mean-shift transport for behavioral anchoring, but its ultimate mode concentration is determined by critic-driven value maximization. This architecture sidesteps the equilibrium ambiguities and symmetrization requirements intrinsic to unconditional drifting models, as the actor's stability is controlled via critic gradients and explicit hyperparameters.
The empirical anti-symmetry stress test—with deliberate imbalance between attraction and repulsion weights—demonstrates that the Q-critic absorbs the need for symmetrization: actor stability remains intact even when the drift field is severely mis-balanced.
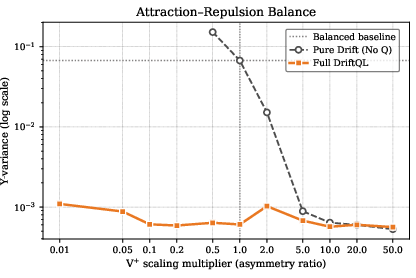
Figure 5: Anti-symmetry stress test: full-\ourMethod maintains low variance and stability across attraction-rescaling multipliers, while pure-drift diverges unless attraction overwhelmingly dominates.
Future Directions and Limitations
Drift Q-Learning opens avenues for adaptive drift fields (learned kernels, state-dependent normalization), integration with high-dimensional observation space (e.g., pixel-based RL), and efficient offline-to-online policy refinement. Current limitations include training-time complexity for large V(a^i)=a+−a^i−k=i∑wik−(a^k−a^i)6, restriction to continuous box-bounded action spaces, and absence of theoretical guarantees transferring from unconditional mean-shift models. Extending joint actor-critic drifting to richer modalities and action layouts remains an open challenge.
Conclusion
Drift Q-Learning advances offline RL by combining generative regularization with critic-driven policy improvement, yielding robust performance, inference efficiency, and expressivity without auxiliary components. Its unified stochastic actor captures multimodal support, and empirical evaluation substantiates competitive or superior gains across diverse settings. The architecture's adaptability, practical efficiency, and theoretical clarity position it as a strong candidate for future research and deployment in real-world RL scenarios (2606.00350).