- The paper introduces a latent memory framework that compresses each multimodal evidence item into a single high-dimensional token, reducing generator token usage by up to 10×.
- It employs reconstruction, contrastive, and distillation losses to train a dedicated compressor, ensuring robust retrieval and accurate generation across QA benchmarks.
- Empirical results show that this method outperforms traditional retrieval-augmented generation pipelines in both efficiency and scalability, supporting resource-constrained environments.
Latent Memory: Compressing Multimodal Evidence into One Token for Efficient Question Answering
Introduction and Motivation
External memory augmentation, especially via Retrieval Augmented Generation (RAG), is a standard approach to boost the factuality, reasoning depth, and domain-transfer ability of LLMs and Vision-LLMs (VLMs) for question answering (QA). However, conventional memory-augmented pipelines feed retrieved, uncompressed text and image evidence directly into generators, resulting in high token usage and storage pressure, particularly for multimodal contexts. This becomes a critical bottleneck in resource-constrained settings such as edge devices or real-time assistants.
"One Token per Multimodal Evidence: Latent Memory for Resource-Constrained QA" (2606.10572) proposes a new paradigm termed Latent Memory, where each multimodal evidence item is compressed into a single high-dimensional latent token. The design goal is dual: minimize generator token usage and storage overhead, while maintaining competitive retrieval and generation performance.
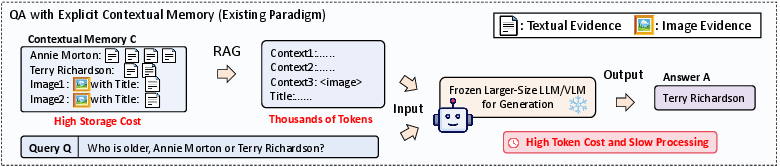
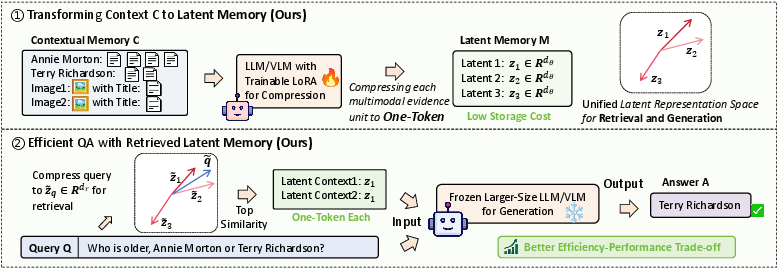
Figure 1: (a) Traditional memory-based generation incurs heavy token/storage cost; (b) Latent Memory compresses each piece of multimodal evidence into a single latent token, improving efficiency while sustaining retrieval/generation quality.
Latent Memory Framework
Latent Memory replaces each evidence unit (text or image) with a single, information-dense latent token generated by a dedicated compressor (a small LLM/VLM). The memory construction and QA answer-generation pipeline constitutes four steps:
- Memory Compression: Each evidence item xi is passed through a compressor, appending a learnable [MEM] embedding and extracting the final hidden state as the latent token zi.
- Unified Latent Retrieval: All latent tokens form a memory bank. A query is projected into the same latent space, enabling inner-product similarity search for top-k relevant tokens.
- Latent-Conditioned Generation: Retrieved latent tokens are projected into the generator hidden space and directly inserted into the frozen LLM/VLM input, replacing raw tokens/images.
- Optional Reconstruction: Latent tokens are optionally decodable back to text (via a decoder LLM) or to a CLIP image embedding (for image evidence).
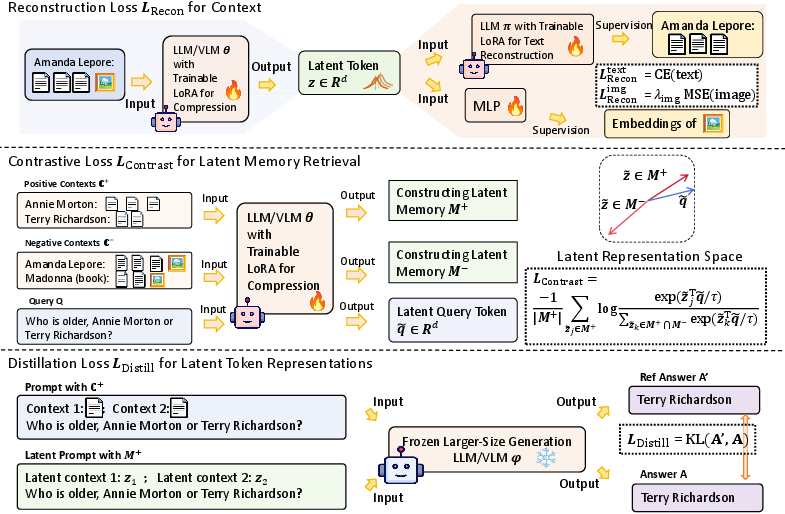
Figure 2: Compressor and decoder are jointly trained with reconstruction, contrastive, and distillation objectives to maximize latent informativeness for retrieval and generation.
The compressor is trained end-to-end with three loss terms:
- Reconstruction Loss (LRecon): Forces latent tokens to preserve enough information to reconstruct the original evidence.
- Contrastive Loss (LContrast): Encourages query embeddings to align with relevant latent tokens and repel unrelated ones, optimizing recall.
- Distillation Loss (LDistill): Matches the distribution of generator outputs conditioned on latent tokens to those on raw evidence, enforcing semantic fidelity.
Empirical Results and Analysis
Latent Memory is evaluated on seven text QA and several multimodal benchmarks (including HotpotQA, 2WikiMultihopQA, MuSiQue, and WebQA), using frozen LLMs/VLMs as generators with compressor models of 1B-4B scale. Baselines include full-context prompting, prompt compression (LLMLingua, ICAE, LCC), and retrieval-augmented generation with dense/sparse retrievers (BM25, Qwen).
Latent Memory consistently delivers competitive EM/F1 compared to advanced RAG baselines but with only 3× to 10× fewer generator tokens. For instance, on out-of-domain (OOD) benchmarks (2WikiMultihopQA, MuSiQue):
- At k=5, Latent Memory (1B) achieves 28.0 average F1 at 71 tokens, versus DSRAG/Qwen3-Embedding's 31.7 F1 using 219 tokens.
- Increasing the token count per latent evidence (up to 8) further narrows this gap, even surpassing top RAG baselines under equivalent or lower generator budget.
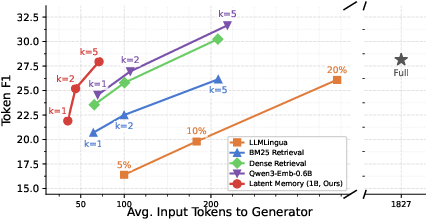
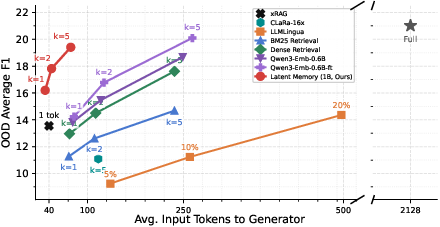
Figure 3: Trade-off curves show Latent Memory matches or exceeds OOD F1 of strong RAG baselines while using markedly fewer generator tokens.
Multimodal QA: Storage and Token Efficiency
In multimodal settings (WebQA), the compressed latent tokens yield major gains for image-grounded QA tasks:
- At k=5, Latent Memory (zi0B LLaVA generator) attains 69.4 image F1 at 82 tokens, compared to Nemo-Emb’s 53.0 F1 at 1885 tokens.
- Latent Memory achieves the best efficiency/accuracy trade-off for image evidence—raw image expansion in VLMs imposes substantial input cost in standard pipelines.
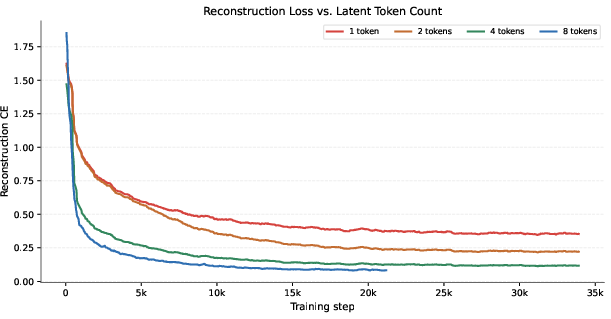
Ablation and Token-Budget Scaling
Qualitative Analysis
Case studies on WebQA show retrieval chains containing all needed evidence via latent tokens, and reconstructions demonstrate the faithful encoding of essential information (not merely shallow hashing).
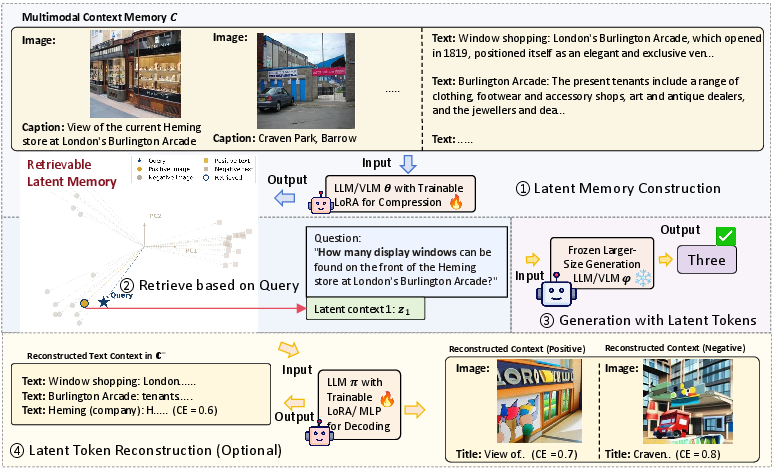
Figure 5: A real WebQA example: multimodal evidence is compressed to latent tokens, retrieved for answering, and optionally reconstructed for interpretability.
Theoretical and Practical Implications
- Unified Representation and Retrieval: Latent Memory unifies representation space for both retrieval and generation. This contrasts with previous compression work that optimizes only for prompt shortening or only for retrieval (often in text-only settings).
- Scalability and On-device Deployment: The paradigm very significantly reduces storage and generator input requirements, especially for images—critical for deployment on edge/embedded devices, mobile, or scenarios with hard latency/throughput constraints.
- Generalization: Latent Memory’s latent tokens, when trained on one domain (HotpotQA), show robust transfer on OOD and heterogeneous datasets, an indicator of strong representation capacity. Notably, the approach is not tightly coupled to a specific generator and can be transferred across compatible models.
- Limitations: The current approach treats each evidence as an atomic unit; it is not optimized for evidence types where global relational structure is essential (e.g., tables, long-form video, spatially organized documents). Future work must extend latent memory to encode and retrieve structured and hierarchical information.
Prospects for Future Development
- Handling Structured/Interdependent Modalities: Augmenting latent memory with relational structure (position, layout, temporal dependencies) is required for tabular, document, and video QA.
- Agentic and Long-term Memory: Integrating latent external evidence representations with agent-generated memory for complex agentic reasoning remains an open area.
- Unified Multi-modal Compression Standards: As more modalities enter retrieval/generation pipelines, universal compression and retrieval standards across text, image, and beyond are needed.
- Orthogonal Integration with Efficient Reasoning: Synergy with chain-of-thought compression, soft-token reasoning, and reinforcement learning for budgeted inference may yield further resource savings.
Conclusion
The Latent Memory paradigm presents a practical, theoretically principled solution for efficient, scalable, and multimodal question answering. By compressing each evidence item—text or image—into a highly informative, retrievable latent token, the approach achieves robust QA performance with sharply reduced token and storage burden. This strategy shows substantial promise for future developments in efficient memory design for LLM/VLM, especially under real-world resource constraints, and opens several avenues for integrated reasoning over highly compressed, multi-modal knowledge.