- The paper introduces an event-level framework that converts sparse clues from long videos into unified, multi-modal memory cards for coherent question answering.
- It employs session-aware segmentation and adaptive resolution allocation to organize visual evidence, achieving up to 21.8% accuracy improvement on benchmark tests.
- Ablation studies demonstrate that each multimodal component—topic cues, speech transcripts, and temporal metadata—is essential for optimal performance.
MemoryCard: Topic-Aware Multi-Modal Clue Compression for Long-Video Question Answering
Motivation and Limitations of Frame-Centric Video QA
The persistent challenge in long-video question answering (QA) for vision-LLMs (VLMs) is the sparsity and dispersion of answer-relevant evidence across lengthy temporal context. Existing approaches primarily utilize frame-centric strategies—uniform sampling, query-aware selection, token compression, and adaptive resolution—to mitigate visual noise and token budget constraints. However, these approaches fundamentally rely on isolated and fragmentary frames, severely limiting semantic density and impeding event-level reasoning. Frame-level representations lack explicit event boundaries and semantic continuity, restricting VLMs from organizing coherent events and degrading their performance in long-range and compositional tasks.

Figure 1: A motivational example illustrating the differences between Memory Cards and existing frame-based evidence construction methods.
The MemoryCard Framework: Event-Level Evidence Construction
MemoryCard is a video-memory-based augmentation framework that transforms sparse visual clues from lengthy videos into self-contained, multimodal, event-level Memory Cards. The methodology consists of:
- Session-Aware Video Segmentation: Triggered through a self-read process, a VLM segments the video and aligned utterances into semantically coherent sessions representing distinct events/topics. Segmentation leverages both video content and temporal speech transcripts, creating temporally grounded semantic units.
- Event-Level Video Gists and Representative Moments: For each session, the VLM generates a compact event-level gist that encapsulates semantic context (topic, aligned utterances, timestamps) and selects session-representative frames.
- Unified Memory Card Rendering: Selected visual moments, event gist, and temporal metadata are rendered into unified image-based Memory Cards. These units embody high-density multimodal evidence, explicitly organizing clues by event rather than timestamp.
Memory Cards are constructed independently of downstream questions, enabling efficient reuse and robust retrieval across queries.
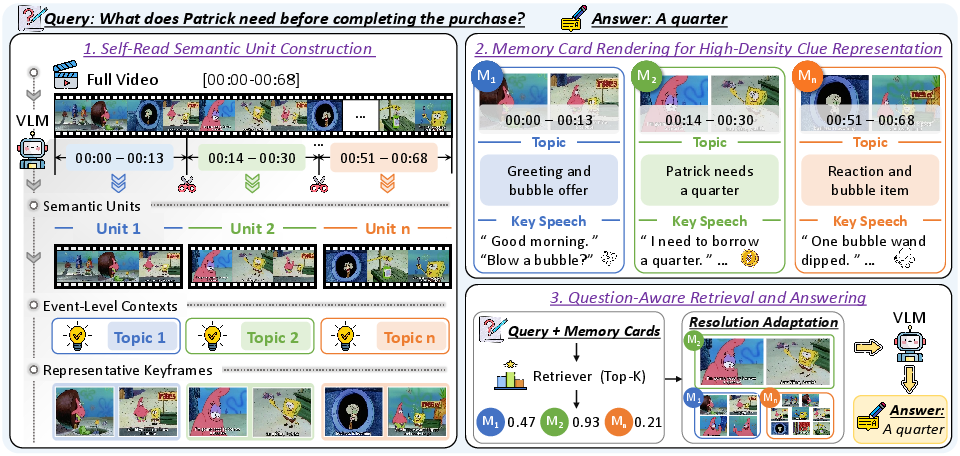
Figure 2: Overview of the framework: semantic unit construction, gist rendering, Memory Card generation, adaptive resolution assignment/reordering, and VLM answering.
MemoryCard employs a retrieve-then-answer pipeline, utilizing a CLIP-style retriever to select question-relevant cards from the constructed memory bank. Retrieval scores inform adaptive input resolution allocation: the most relevant cards are fed into the answering VLM at high resolution, less relevant ones at lower resolution, balancing local detail preservation and event coverage under fixed computational budgets.
Contrasted with uniform sampling, session-aware MemoryCard construction ensures evidence is organized by event structure, resulting in far more semantically aligned visual units. Uniform approaches distribute frames at fixed intervals, often missing vital event transitions and semantic cues.
Figure 3: Uniform Sampling vs. Session-Aware Self-Read Construction under the same visual token budget, organizing evidence by event rather than uniform spacing.
Empirical Analysis and Ablations
Comprehensive evaluation across Video-MME, MLVU, and LongVideoBench demonstrates consistent gains from MemoryCard integration with three answering backbones (Qwen2-VL-7B, Qwen3-VL-8B, MiniCPM-V-4.5). MemoryCard delivers up to 21.8% relative improvement in accuracy under comparable visual-token budgets. Ablation studies confirm that improvements arise not merely from retrieval but from the rendered evidence units: removing topic, speech transcript, or temporal span individually degrades performance, underscoring the necessity of multimodal clue encapsulation.
Memory Unit Construction and Task Breakdown
Session-aware semantic units outperform uniform, fixed-length, and shot-based units, validating the importance of content-aware segmentation over simple visual partitioning. Event-level clues facilitate reasoning in diverse task categories (perception, recognition, OCR, information synopsis), though counting and reasoning remain more challenging and may require denser temporal coverage or more sophisticated aggregation.
Adaptive Resolution and Retrieval Ordering
Resolution allocation experiments show that relevance-aware assignment (4 high, 8 mid, 32 low resolution cards) maximizes accuracy by balancing local visual detail and broad event context. Temporal ordering of retrieved cards (restoring chronological sequence) further outperforms strict relevance or random ordering, supporting coherent reasoning across event progression.
Qualitative Visualization: Retrieval and Answering Pipeline
MemoryCard’s session-aware retrieval delivers answer-relevant Memory Cards in multiresolution batches, supporting both fine-grained perception and event-level synthesis for multiple-choice QA.
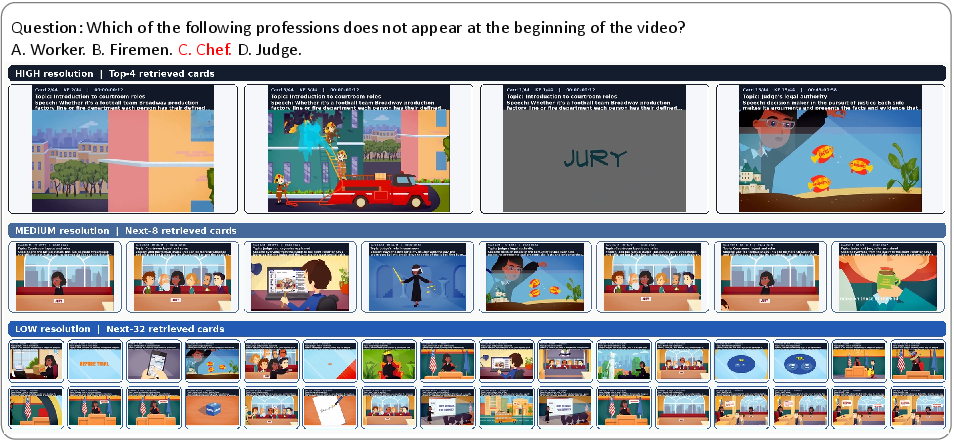
Figure 4: Question-conditioned Memory Card retrieval; visualization includes adaptive resolution and ground-truth highlighting for VLM answering.

Figure 5: Question-conditioned Memory Card retrieval; visualization shows input organization for answering VLM and correct answer annotation.
Implications and Future Directions
MemoryCard advances the long-video QA paradigm by shifting evidence construction from isolated frame selection to multimodal, semantically-coherent event-level clues. It demonstrates robust improvements across state-of-the-art VLMs without task-specific fine-tuning, reinforcing the hypothesis that event-centric memory units are crucial for scalable video language modeling. Future research may focus on optimizing Memory Card construction efficiency (reducing preprocessing cost), enhancing clue density for motion-dynamic questions, and integrating more sophisticated memory aggregation mechanisms to further improve multi-hop and compositional reasoning performance.
Conclusion
MemoryCard proposes the construction and retrieval of explicit, reusable, multimodal evidence units for long-video QA, systematically overcoming the fragmentation and sparsity issues inherent in previous frame-based approaches. The framework’s session-aware segmentation, event-level gist rendering, and adaptive resolution allocation substantially improve QA performance across challenging benchmarks. Its design principles lay the foundation for more semantically dense and efficient memory augmentation strategies, with broad implications for future VLM architectures and retrieval-based video reasoning.