CLaRa: Bridging Retrieval and Generation with Continuous Latent Reasoning
Abstract: Retrieval-augmented generation (RAG) enhances LLMs with external knowledge but still suffers from long contexts and disjoint retrieval-generation optimization. In this work, we propose CLaRa (Continuous Latent Reasoning), a unified framework that performs embedding-based compression and joint optimization in a shared continuous space. To obtain semantically rich and retrievable compressed vectors, we introduce SCP, a key-preserving data synthesis framework using QA and paraphrase supervision. CLaRa then trains the reranker and generator end-to-end via a single language modeling loss, with gradients flowing through both modules using a differentiable top-k estimator. Theoretically, this unified optimization aligns retrieval relevance with answer quality. Experiments across multiple QA benchmarks show that CLaRa achieves state-of-the-art compression and reranking performance, often surpassing text-based fine-tuned baselines.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI systems better at answering questions using information from large collections of documents, like Wikipedia. These systems are called “retrieval‑augmented generation” (RAG): they first retrieve helpful documents, then generate an answer. The authors introduce a new method called CLaRa (Continuous Latent Reasoning) that compresses documents into small, smart summaries the AI can both search and understand. This makes the whole process faster, more accurate, and easier to train as one connected system.
Key Objectives
Here are the main goals of the paper, explained simply:
- Combine document search and answer writing so they learn together instead of separately.
- Shrink long documents into short “memory” vectors that still keep the key ideas.
- Teach the system to pick the most useful documents for answering a question, not just the ones that look similar.
- Reduce the amount of text the AI needs to read, so it’s faster and uses less memory, without losing important facts.
Methods and Approach
Think of the AI like a student preparing for a test. CLaRa helps the student make good notes and use them wisely.
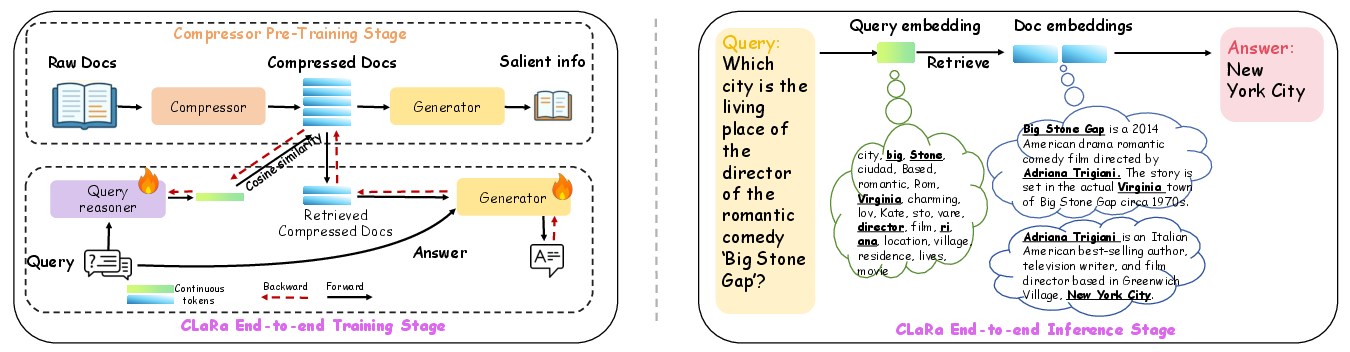
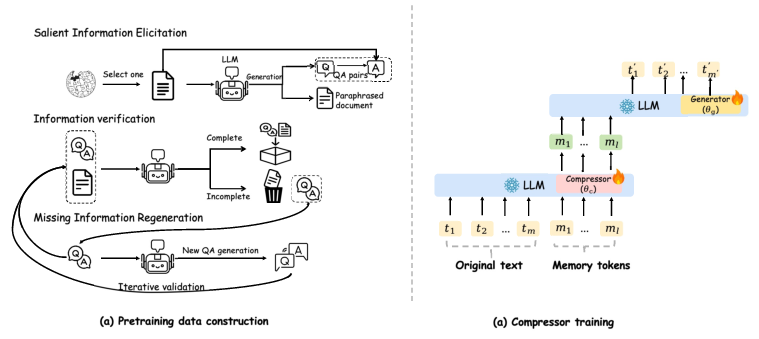
Step 1: Teaching the model to compress (SCP)
SCP stands for Salient Compressor Pretraining. “Salient” means “important.” The idea is to train a compressor that turns a long document into a few learned “memory tokens” (tiny vector summaries) that capture what matters.
How they teach this:
- They use a large set of Wikipedia pages.
- For each page, they ask a powerful AI to create:
- Simple Q&A pairs about single facts (keeps precise details).
- Complex Q&A pairs that connect multiple facts (teaches relationships).
- Paraphrases of the document (shows different ways to express the same meaning).
- They automatically check these Q&A and paraphrases to make sure they cover the document’s key information and are factually correct. If something’s missing, they generate more until coverage is good.
How the compressor learns:
- The document plus a small set of learnable “memory tokens” go into the model.
- The final hidden states of those memory tokens become the document’s compressed representation.
- The model is trained to generate the Q&A answers or paraphrases from only these memory tokens, so they must store the important information.
- A simple alignment loss nudges the compressed representation to stay close in meaning to the original document, like making sure your notes match the textbook.
Analogy: It’s like learning to write excellent index cards for a chapter—short but complete enough to answer questions.
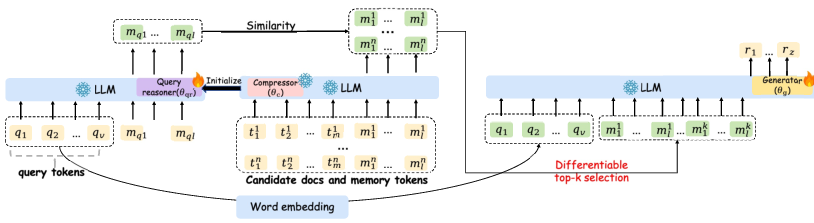
Step 2: Training retrieval and generation together (CLaRa)
Once documents are compressed, the system needs to:
- Turn a question into its own “query memory tokens.”
- Match the question’s tokens to the best document tokens (retrieval).
- Feed the top matches to the answer generator (generation).
In most systems, retrieval and generation are trained separately. CLaRa trains them together from a single learning signal: predict the next word in the answer (“next token prediction”). This way, the generator’s feedback helps the retriever learn what to pick.
Analogy: Imagine a GPS that plans your route while also learning which roads actually get you to your destination faster. If the destination needs “Athens 1896,” the GPS learns to favor documents with clues like “first modern Olympics” and “Athens,” even if the question wording is different.
Key pieces:
- Query reasoner: a small adapter that turns the question into the same kind of memory tokens as the documents. It “thinks ahead” and encodes helpful clue words that might not be in the question but are needed for the answer.
- Shared space: both documents and questions live in the same continuous vector space, so they can be compared directly.
- End-to-end training: both the query reasoner and the generator are improved together using the same loss.
A note on “differentiable top‑k”
Usually, choosing the top‑k most relevant documents is a hard, discrete step—like picking the top 5 items from a list. That breaks learning signals from flowing backward. CLaRa uses a trick (a “Straight‑Through” estimator) that keeps the choice discrete for actual usage but makes it “soft” during training, so the generator’s feedback can teach the retriever which documents should be ranked higher next time.
Analogy: It’s like marking the top choices in bold for reading, but during practice, you also shade near-top choices lightly so you can learn what made them almost good.
Main Findings
To make the results easier to follow, here are the key takeaways:
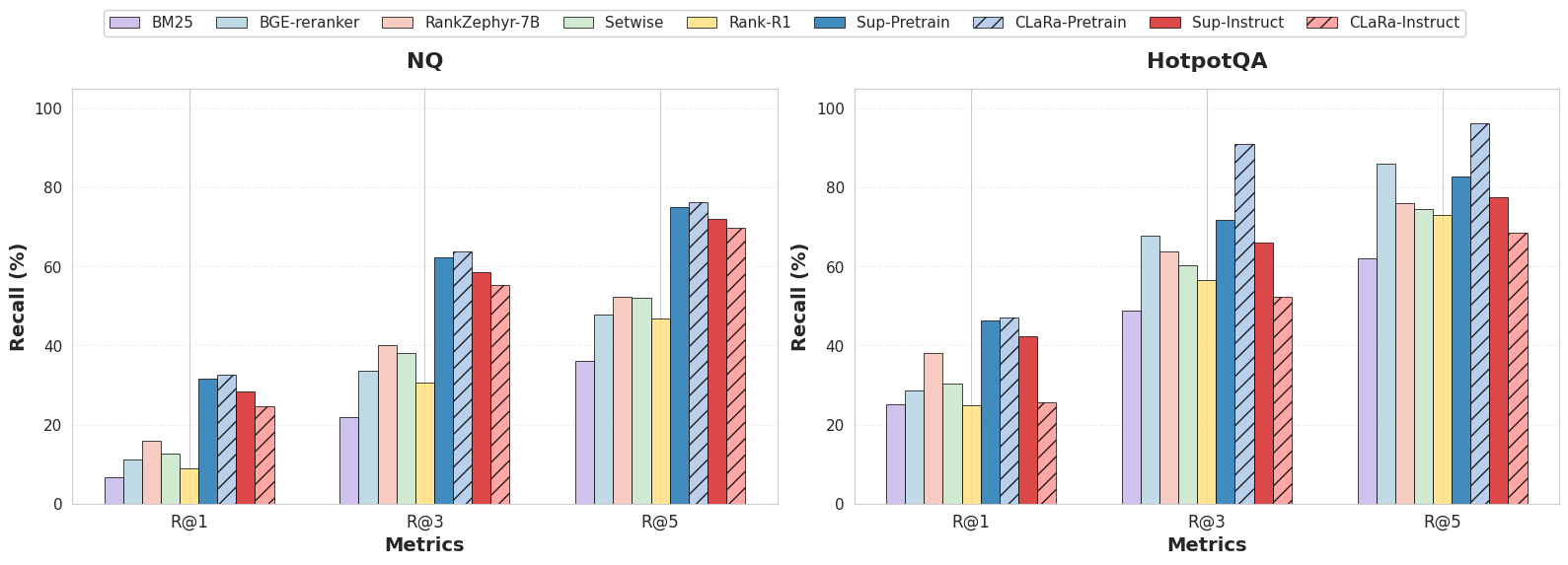
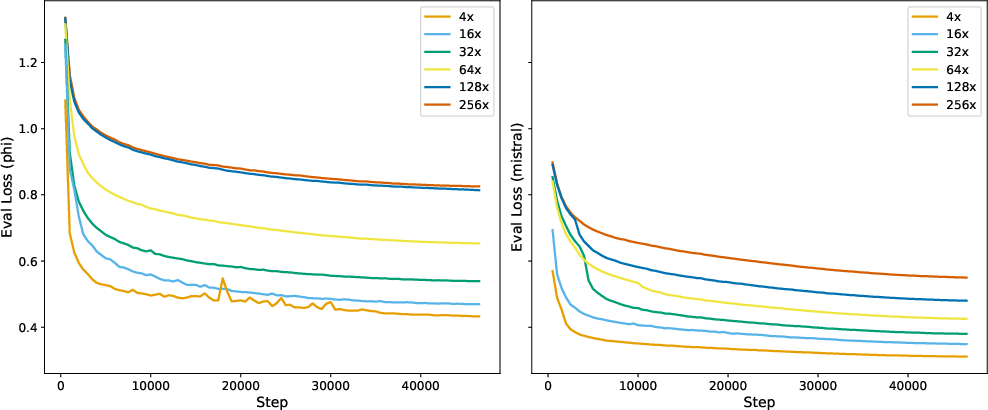
- The compression works very well: Their SCP method keeps important meaning even when shrinking documents by 4×, 16×, or more. In several tests, the compressed version actually beats using the full original text.
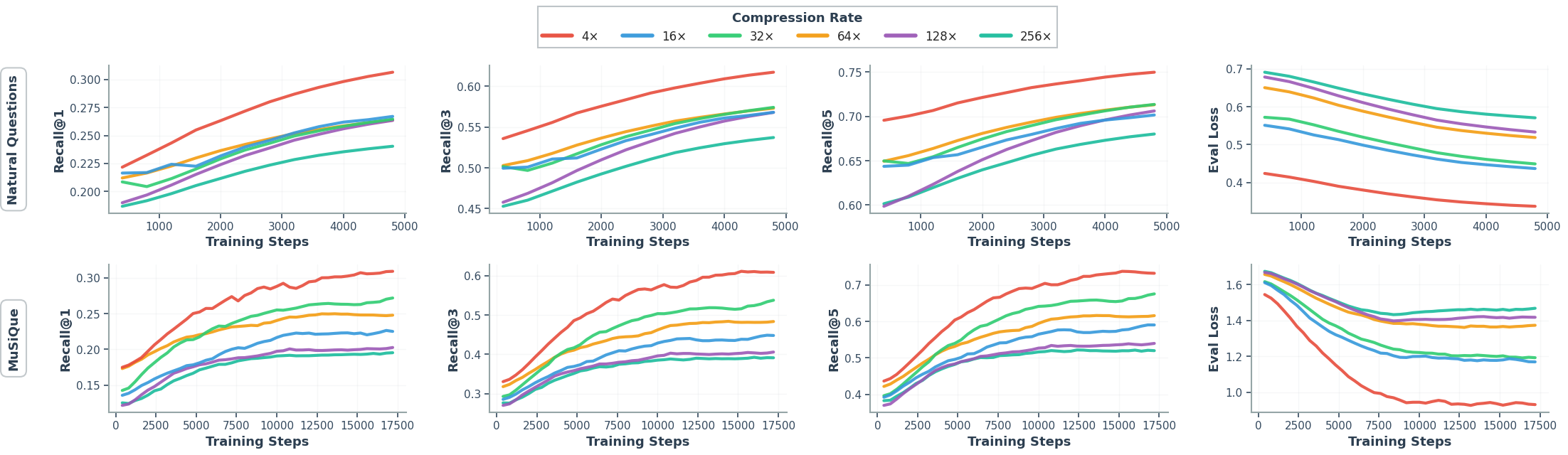
- Better retrieval: When trained end-to-end, the system learns to find the most helpful documents for answering, not just those with similar words. It achieved higher Recall@k (how often the right document is among the top-k) than strong supervised rerankers in some benchmarks.
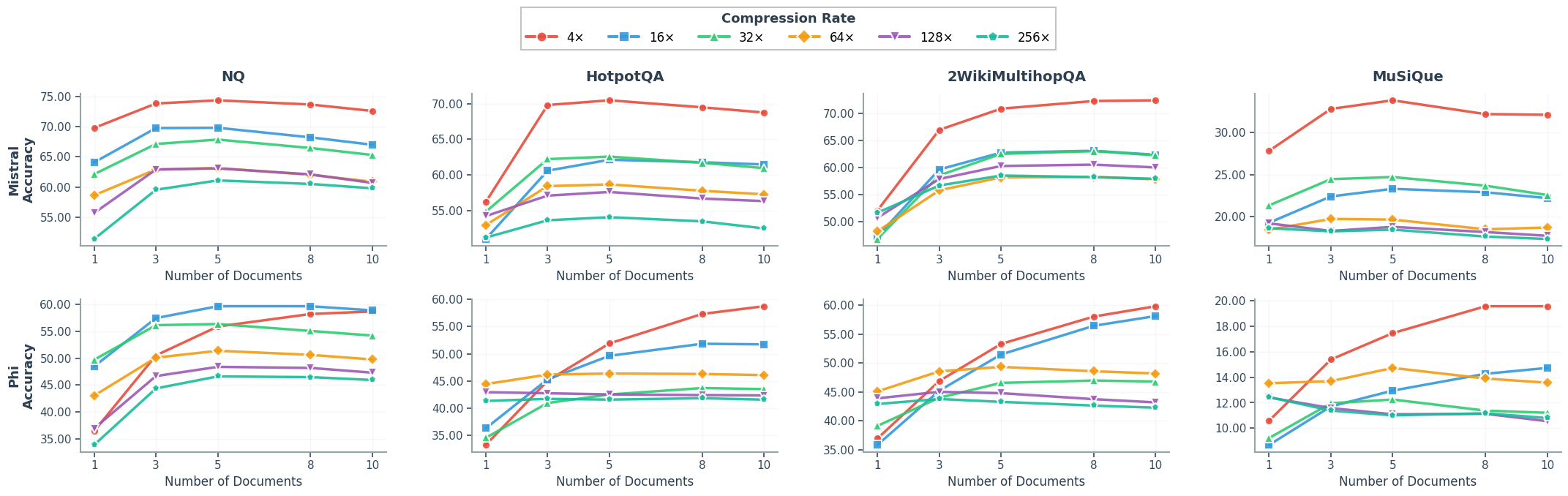
- Strong overall performance: Across popular question-answering datasets (Natural Questions, HotpotQA, MuSiQue, and 2WikiMultihopQA), CLaRa achieved state-of-the-art or competitive results while using much shorter inputs. In some cases, it surpassed text-based systems that read the full documents.
- Efficient and unified: Using the same compact representation for both retrieval and generation cuts down on computation, avoids context overflow, and keeps training aligned from end to end.
Why It Matters
This research shows a practical way to make AI question-answering smarter and faster:
- Faster answers with less text: Compressing documents into memory tokens means the AI reads far less while keeping key facts, saving time and resources.
- Better alignment: Training retrieval and generation together ensures the system looks for what actually helps answer the question, reducing mistakes and irrelevant context.
- Scales well: Because everything lives in one shared continuous space, it’s easier to train and deploy on large collections of documents.
- More reliable knowledge use: By focusing on salient facts and reasoning connections, the AI is less likely to hallucinate and more likely to give grounded answers.
In short, CLaRa brings RAG closer to how a good student studies: make great notes, learn what’s truly useful, and use your notes efficiently to produce accurate answers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and limitations that future work could address to strengthen and generalize the CLaRa framework.
- Domain generalization: The evaluation is limited to Wikipedia open-domain QA (NQ, HotpotQA, MuSiQue, 2Wiki). It remains unclear how CLaRa performs on non-Wikipedia corpora (e.g., legal, biomedical, code), non-English languages, or multilingual settings.
- End-to-end retrieval at scale: Retrieval effectiveness is largely assessed with “Oracle” candidate sets and relatively small pools (top-5/-20). There is no evaluation with full-corpus retrieval over millions of documents, end-to-end first-stage retrieval + reranking, or scaling behavior as corpus size grows.
- Efficiency claims lack measurements: While the paper argues reduced context and computation, it does not report wall-clock latency, throughput, memory footprint, GPU hours, or on-device feasibility. Concrete efficiency benchmarks (per query/epoch) are missing.
- Frozen compressor assumption: The compressor is frozen during joint training. The trade-offs of unfreezing (e.g., potential drift vs. stronger alignment), stability over prolonged training, and whether partial or periodic updates help are unexplored.
- Compression hyperparameters and capacity: The number of memory tokens, hidden dimensions, and compression rate (CR) are not systematically analyzed. There is no guidance for selecting CR per domain/task, nor exploration of variable-length or adaptive compression per document.
- Adaptive compression and per-query needs: The system uses fixed compression regardless of query difficulty or required reasoning depth. Methods to dynamically allocate memory tokens or selectively “decompress” for hard queries are not investigated.
- Retrieval selection relaxation: The Straight-Through (ST) top-k estimator’s bias, temperature schedules, gradient stability, and sensitivity to k are not systematically characterized. Comparisons to alternative differentiable relaxations (e.g., Gumbel-TopK, SoftSort, Sinkhorn, Perturb-and-MAP) are missing.
- Theoretical guarantees: The gradient coupling analysis is intuitive but does not provide formal convergence or consistency guarantees (e.g., conditions under which NTP-based supervision reliably improves retrieval). Assumptions and limitations of the derivation are not rigorously stated.
- Weak supervision failure modes: Training the retriever only via NTP may favor documents that help guessing answers without proper grounding. The paper lacks systematic evaluation of source attribution, faithfulness, and grounding (beyond anecdotal logit-lens cases).
- Attribution and explainability: Compressed vectors are not directly human-readable; there is no mechanism to present supporting passages or citations. Methods to map compressed representations back to verifiable text snippets, and metrics for citation accuracy, are missing.
- Robustness to distractors and adversarial retrieval: The setup does not test robustness to contradictory or noisy documents, adversarial distractors, or domain shifts. Stress tests and failure analyses are absent.
- Multi-hop reasoning structure: Multi-hop tasks are handled by concatenating compressed vectors. There is no explicit path/graph reasoning over evidence, nor analysis of whether the model composes facts across documents reliably as k grows.
- Reranker benchmarks: Retrieval comparisons omit strong cross-encoder baselines (e.g., ColBERT v2, state-of-the-art commercial rerankers). It is unclear how the query reasoner compares under rigorous reranking settings with competitive large models.
- Instruction-tuning trade-offs: Instruction-tuning improves generation but appears to harm retrieval quality relative to pretraining-initialized models. Strategies to balance or multi-objective train for both retrieval and generation are not explored.
- Hyperparameter sweeps: Key hyperparameters (e.g., λ in MSE alignment, ST temperature τ, LoRA ranks, number of memory tokens) lack sensitivity analyses and ablations across tasks and compression budgets.
- Data synthesis quality and bias: SCP relies on Qwen-32B to generate QA and paraphrases, then verifies with the same LLM. The risk of model-induced biases, self-consistency illusions, and domain skew is not quantified. Human evaluation or cross-model verification is absent.
- Coverage and fidelity auditing: Although the pipeline iterates to ensure coverage, the paper does not provide quantitative audits of coverage, factuality, and error rates of synthetic QA/paraphrases, nor their downstream impact on compression quality.
- Updateability and streaming corpora: The offline compression pipeline does not address incremental updates (new/changed documents), re-indexing costs, or mechanisms for low-latency corpus refresh in production settings.
- Long-document handling: The method’s behavior for very long documents (e.g., book-length, technical specs) is not examined. How compression scales with document length and whether semantic drift increases are open questions.
- Security and privacy: Compressing documents into dense vectors may leak sensitive information or complicate access controls. Privacy implications and mitigation (e.g., differential privacy, encryption) are not discussed.
- Hallucination and factuality: The paper claims RAG reduces hallucinations but does not provide explicit hallucination or factuality metrics under compressed inputs. Empirical measures (e.g., truthfulness, consistency) are missing.
- Integration with standard RAG stacks: Practical guidance for integrating CLaRa with existing retrieval/indexing systems (vector databases, hybrid sparse+dense retrieval) and fallback to raw text is absent.
- Generalization across LLMs/scales: Results are on Mistral-7B and Phi-4-mini. Scaling laws, behavior with larger models (e.g., 13B–70B), and architectural portability (Transformer variants) are untested.
Practical Applications
Practical Applications of CLaRa (Continuous Latent Reasoning) and SCP (Salient Compressor Pretraining)
Below we translate the paper’s findings into practical, real-world applications. We group actionable use cases into immediate and longer-term opportunities, link them to sectors, suggest tools/workflows that could emerge, and note assumptions and dependencies that affect feasibility.
Immediate Applications
These applications are deployable now with existing tooling (e.g., LoRA-capable LLMs, vector databases, standard RAG frameworks) and the open-source release.
- Enterprise knowledge bases with “compressed latent” RAG
- Sector: software/enterprise IT
- What: Replace raw-text ingestion with SCP-compressed memory-token representations; run retrieval and generation in a shared continuous space to reduce context length (e.g., 4–16×) and inference cost.
- Tools/workflows:
- Latent indexer (offline SCP preprocessing of documents into memory tokens)
- Vector DB integration to store and search compressed embeddings (FAISS/ScaNN/Weaviate/Pinecone)
- End-to-end fine-tuning of the query reasoner + generator under NTP loss with differentiable top‑k
- Assumptions/dependencies: Base LLM supports LoRA and memory tokens; document compression can be done offline and frozen; retrieval candidate generation remains available; domain coverage in the compressed corpus.
- Label-free retriever alignment using generation feedback
- Sector: search/IR, applied NLP
- What: Train rerankers (query reasoners) without relevance labels, using the generator’s next-token prediction (NTP) as weak supervision via Straight‑Through top‑k.
- Tools/workflows: Differentiable top‑k training component; “retriever-from-generator” fine-tuning job; logging of gradient-informed relevance shifts.
- Assumptions/dependencies: High-quality answer supervision available; generator produces stable signals; infrastructure for end-to-end training.
- Cost and latency reduction for chat assistants
- Sector: consumer/mobile, productivity software
- What: On-device or edge assistants that query large corpora through compressed continuous representations to avoid long contexts and duplicated encoding.
- Tools/workflows: Offline SCP compression of device-resident documents; compact indices; shared encoder/decoder pipelines to avoid re-encoding raw text on every query.
- Assumptions/dependencies: On-device inference capability for chosen LLM; memory budget for storing compressed vectors; privacy constraints for local corpora.
- Customer support chatbots with better retrieval–generation coupling
- Sector: customer service, SaaS
- What: Compress help-center articles, incident runbooks, and troubleshooting FAQs; fine-tune retriever alignment to the answer style and constraints using NTP.
- Tools/workflows: Ticket logs for instruction tuning; compressed KB index; CLaRa training loop that optimizes reranking and generation jointly.
- Assumptions/dependencies: Domain-specific QA pair synthesis quality; guardrails for factuality; PII handling and auditing.
- Education assistants for textbooks and lecture notes
- Sector: education/EdTech
- What: Build course-level assistants that retrieve multi-hop evidence from textbooks and syllabi via compressed embeddings and a query reasoner that infers intermediate concepts.
- Tools/workflows: SCP QA/paraphrase synthesis from curricula; academic content compression; differentiable top‑k reranking integrated into a learning platform.
- Assumptions/dependencies: Availability of clean instructional content; teacher-model outputs or reference answers; evaluation for pedagogical correctness.
- Legal e‑discovery and case-law research
- Sector: legal
- What: Use compressed corpora for large statutes/precedents; train the query reasoner to prefer legally relevant evidence using NTP feedback to reduce spurious retrieval.
- Tools/workflows: Latent-case law indices; joint optimization pipeline with document provenance tracking.
- Assumptions/dependencies: Risk of nuance loss at extreme compression; interpretability requirements; validation against gold contexts; strict compliance.
- Clinical guidelines and protocol retrieval
- Sector: healthcare
- What: Compress long clinical guidelines and protocols to support clinician QA; align retrieval with answer generation for lower hallucination risk.
- Tools/workflows: Domain QA generation for compressor pretraining; latent guideline index; NTP-aligned retriever–generator pair; safety checking.
- Assumptions/dependencies: Medical QA synthesis quality and coverage; robust evaluation; regulatory guardrails; human-in-the-loop review.
- Retrieval reranker improvement for existing RAG stacks
- Sector: search/IR, platform teams
- What: Add differentiable top‑k to train reranking components directly from generative performance (recall@k gains reported).
- Tools/workflows: Drop-in ST top‑k module; training dashboards to monitor retrieval–generation coupling; rollout to production ranking.
- Assumptions/dependencies: Stable training regimes; seamless integration with existing retrievers; temperature and masking strategies tuned per domain.
- Compressed memory caches for recurring tasks
- Sector: developer tooling/MLOps
- What: Maintain “latent caches” of frequently used documents (e.g., specs, playbooks) to reduce repeated tokenization and encoding costs in pipelines.
- Tools/workflows: Offline SCP processor; cache invalidation/versioning; compressed-to-generator adapters.
- Assumptions/dependencies: Version control and data drift handling; shared latent space remains aligned across updates.
- Synthetic QA/paraphrase data generation as a service
- Sector: data engineering, ML services
- What: Offer SCP-style data synthesis (simple/complex QA + paraphrase + coverage verification and regeneration) for client corpora to improve compressor fidelity.
- Tools/workflows: QA/paraphrase generator and verifier; coverage metrics; iterative regeneration pipeline.
- Assumptions/dependencies: Access to a capable local LLM (e.g., Qwen-32B) or equivalent; domain adaptation; cost control for large-scale synthesis.
Long-Term Applications
These require further research, scaling, domain adaptation, safety validation, or standardization.
- Standardized latent document format (LDF)
- Sector: software infrastructure
- What: A shared specification for memory-token representations to enable interoperability across vector DBs, RAG frameworks, and LLM providers.
- Tools/workflows: LDF schema and converters; “latent store” APIs; compatibility tests.
- Assumptions/dependencies: Community consensus; security and IP handling for compressed representations; version compatibility.
- Privacy-preserving, on-device continuous RAG
- Sector: healthcare, finance, mobile
- What: Keep compressed corpora on-device and train retrievers label-free via NTP, reducing server-side exposure and enabling private QA.
- Tools/workflows: Federated or local fine-tuning of query reasoners; encrypted latent stores; privacy auditing.
- Assumptions/dependencies: Resource constraints on devices; DP or secure aggregation; thorough safety and bias evaluations.
- Multimodal latent compression
- Sector: robotics, media, education
- What: Extend SCP to compress images, audio, and video into shared memory tokens for unified retrieval and generation (e.g., visual QA with text).
- Tools/workflows: Multimodal encoder/decoder adapters; cross-modal query reasoners; differentiable selection across modalities.
- Assumptions/dependencies: Multimodal pretraining data; architecture support; evaluation benchmarks for compositional reasoning.
- Adaptive, query-aware compression rates
- Sector: cloud services, IR
- What: Dynamically adjust compression (e.g., 4× to 32×) per query to balance fidelity and cost, guided by downstream NTP performance.
- Tools/workflows: Compression controllers; training curricula for variable memory token budgets; cost-aware scheduling.
- Assumptions/dependencies: Stability across compression regimes; controller design; monitoring to prevent degradation.
- Continual learning for retrieval–generation co-evolution
- Sector: enterprise platforms
- What: Update latent representations and query reasoners as knowledge changes, with gradients coupling retriever and generator in production.
- Tools/workflows: Incremental compression updates; retriever–generator co-training; drift detection and rollback.
- Assumptions/dependencies: Safe online training practices; robust A/B evaluation; avoiding catastrophic forgetting.
- Government information access and legislative support
- Sector: public policy/government
- What: Build FOIA and legislative drafting assistants that retrieve compressed statutes, regulations, and reports with better alignment to drafting tasks.
- Tools/workflows: Government-grade latent indices; provenance-aware generation; policy-specific evaluation suites.
- Assumptions/dependencies: Rigorous legal validation; transparency requirements; public record constraints.
- Energy-efficient retrieval at data-center scale
- Sector: energy/IT operations
- What: Reduce token throughput and redundant encoding via compressed latent representations, lowering energy usage in large RAG deployments.
- Tools/workflows: Energy monitoring and reporting; compressed-context schedulers; green-compute SLAs.
- Assumptions/dependencies: Measurable energy benefits under real workloads; cost–performance trade-off analyses.
- Compliance and auditability via gradient-informed provenance
- Sector: compliance, risk
- What: Use differentiable retrieval signals to document why certain evidence was selected (gradient coupling with generator), supporting audit trails.
- Tools/workflows: Retrieval provenance logs; interpretability reports for query reasoner; compliance dashboards.
- Assumptions/dependencies: Methods to translate gradients/selections into human-readable rationales; regulatory acceptance.
- Financial research and due diligence assistants
- Sector: finance
- What: Compress filings, earnings calls, analyst reports; jointly optimize retrieval for complex multi-hop financial QA.
- Tools/workflows: Latent financial corpora; domain QA synthesis; risk-aware generation with guardrails.
- Assumptions/dependencies: Domain-specific coverage and timeliness; compliance (e.g., material nonpublic information handling).
- Benchmarks and shared evaluation suites for compressed RAG
- Sector: academia/NLP research
- What: Community datasets and protocols that test compression fidelity, retrieval–generation alignment, and long-context reasoning under various compression rates.
- Tools/workflows: Benchmark creation; public leaderboards; ablation libraries.
- Assumptions/dependencies: Broad participation; reproducibility across models and memory token designs.
- Integrated developer tooling for reasoning-aware queries
- Sector: developer experience
- What: IDE/notebook plugins that visualize decoded query-reasoner topics (logit lens) to help engineers debug retrieval intent and compression fidelity.
- Tools/workflows: Interactive token/topic lenses; query embedding inspectors; retrieval heatmaps.
- Assumptions/dependencies: Model hooks to decode memory tokens; UX for non-experts; privacy of intermediate signals.
- Latent-memory marketplaces and content distribution
- Sector: content platforms
- What: Distribute documents directly as compressed latent packages for downstream retrieval/generation (e.g., publishers supplying compressed indices).
- Tools/workflows: Publisher pipelines to produce certified latent packages; licensing and usage reporting.
- Assumptions/dependencies: IP/legal frameworks for compressed representations; quality assurance; standards for integrity and updates.
In summary, CLaRa and SCP unlock practical gains in retrieval–generation coupling and efficiency by moving RAG into a shared continuous representation space. Immediate wins include lower cost, better retrieval alignment without labels, and simpler pipelines; long-term opportunities span privacy, multimodality, adaptive compression, and standardization. Each application’s feasibility depends on domain data quality, base-model support (LoRA/memory tokens), the robustness of synthetic QA/paraphrase supervision, and safety/compliance in high-stakes sectors.
Glossary
- BM25: A classical term-weighting algorithm in information retrieval that ranks documents based on keyword frequency and document length. "we compare with BM25, BGE-Reranker \citep{bge_m3}, RankZephyr-7B \citep{pradeep2023rankzephyreffectiverobustzeroshot}, Setwise \citep{10.1145/3626772.3657813}, and Rank-R1 \citep{zhuang2025rankr1enhancingreasoningllmbased}."
- CLaRa (Continuous Latent Reasoning): A unified framework that compresses documents into continuous embeddings and jointly optimizes retrieval and generation in the same latent space. "we propose CLaRa (Continuous Latent Reasoning), a unified framework that performs embedding-based compression and joint optimization in a shared continuous space."
- Contrastive learning: A training paradigm that brings representations of related pairs closer and pushes unrelated pairs apart. "Note that can also be pre-trained independently using contrastive learning over positive and negative document--query pairs and , following the DPR framework \citep{zhou2025optimizingretrievalragreinforced}."
- Cosine similarity: A similarity measure between two vectors based on the cosine of the angle between them. "We use cosine similarity to determine the relevance between query and documents:"
- Cross-entropy loss: A standard loss function for training probabilistic models, measuring the negative log-likelihood of the target tokens. "Only the generator LoRA is trained via cross-entropy loss:"
- Dense Passage Retriever (DPR): A neural retrieval framework that embeds queries and passages into a dense vector space for similarity search. "following the DPR framework \citep{zhou2025optimizingretrievalragreinforced}."
- Dense retrievers: Neural retrieval models that use dense embeddings rather than sparse term matches to find relevant documents. "Dense retrievers rank documents in embedding space, whereas generators still consume raw text"
- Differentiable top-k selection: A technique to make selecting the top-k items differentiable so gradients can flow through retrieval. "Optimization-wise, continuous representations enable differentiable top- selection via Straight-Through estimation"
- End-to-end training: Jointly optimizing multiple components of a system using a single objective so gradients flow through the entire pipeline. "Achieving end-to-end training, however, requires a retrieval space that is both stable and computationally manageable"
- Gumbel-softmax: A reparameterization trick that enables differentiable sampling from categorical distributions. "Differentiable reranking \citep{huang-etal-2025-gumbel} enables gradient-based selection via Gumbel-softmax but likewise processes full documents at every step, leaving the representation mismatch and context length issues unresolved."
- Hallucination: The tendency of LLMs to produce plausible-sounding but incorrect or fabricated information. "By incorporating external evidence, RAG mitigates key weaknesses of LLMs such as hallucination"
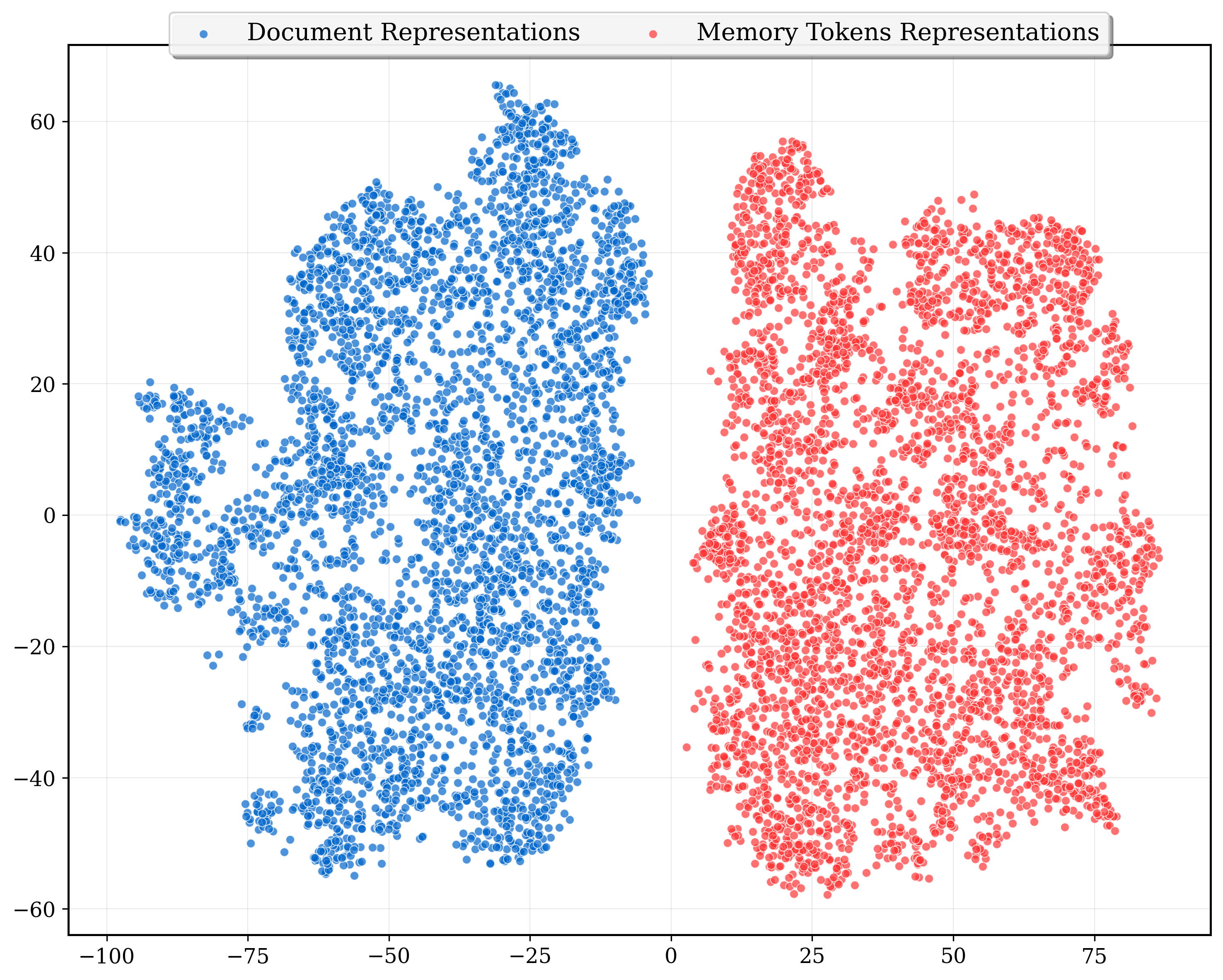
- Information bottleneck: A principle where a compact representation is learned that retains essential information while discarding irrelevant details. "Learning such a mapping from original text to paraphrased text through an information bottleneck of continuous representation will enable the learned representation to focus on the semantics."
- Instruction tuning: Fine-tuning a model with task-specific instructions and responses to improve adherence and performance on downstream tasks. "Similar to the compressor pretraining stage, we jointly finetune the LoRA adapters of both the compressor and the answer generator during this instruction-tuning process."
- Latent representations: Internal continuous vector encodings that capture semantic information about inputs. "we encourage their latent representations to remain aligned."
- Logit lens: An analysis technique that decodes intermediate representations by projecting them through the model’s output head. "we adopt the logit lens analysis technique~\citep{nostalgebraist2020logitlens}."
- LoRA adapters (Low-Rank Adaptation): Parameter-efficient modules that adapt large models by training small low-rank matrices. "we adopt a shared base model equipped with multiple LoRA adapters for modular control"
- Masking (for selection): A mechanism to exclude or mark items during selection so they are not chosen again. "Given cosine similarities , temperature , and masking for previously selected items, the soft and hard selections are defined as:"
- Mean squared error (MSE): A loss function measuring the squared difference between predicted and target vectors, used here to align compressed and original representations. "Therefore, we minimize the mean squared error (MSE) between the averaged hidden states of document tokens and memory tokens:"
- Memory tokens: Learnable tokens appended to inputs whose final-layer states serve as compact document embeddings. "we append learnable memory tokens and activate only the compressor LoRA ."
- Multi-hop QA: Question answering that requires reasoning across multiple pieces of evidence or documents. "We evaluate CLaRa on four single-hop and multi-hop QA benchmarks with Mistral-7B and Phi-4B."
- Next-token prediction (NTP) loss: The language modeling objective that maximizes the likelihood of the next token, used to provide weak supervision to retrieval. "we propagate the next-token prediction (NTP) loss from the generator to the retriever"
- Oracle setting: An evaluation setup where the correct document is guaranteed to be included in the candidate set, isolating downstream effects from retrieval errors. "We evaluate our document compressor under two settings: Normal and Oracle."
- Paraphrase supervision: Training signals derived from paraphrased versions of documents to preserve semantics while altering surface form. "we introduce SCP, a key-preserving data synthesis framework using QA and paraphrase supervision."
- Query reasoner: A learned query encoder that embeds queries into the same memory-token space as documents and anticipates relevant content for retrieval. "We then train a query reasoner (), a LoRA adapter initialized from , to represent queries in the same space and with the same number of memory tokens as document representations."
- Recall@k: A retrieval metric measuring whether a relevant item is found among the top-k results. "Retrieval performance (Recall@1/3/5) on the Mistral-7B model across different reranking methods under compression ratios = 4 and various initialization settings on NQ and HotpotQA datasets."
- Reinforcement learning (RL) sampling: Using RL to select documents or actions via sampled trajectories, often unstable and computationally heavy. "allowing generator gradients to update the retriever directly through gradient descent rather than inefficient RL sampling."
- Reranker: A model that reorders a set of retrieved documents to prioritize the most relevant ones. "CLaRa then trains the reranker and generator end-to-end via a single language modeling loss"
- Retrieval-Augmented Generation (RAG): A paradigm that augments LLMs with external documents retrieved at inference time to improve accuracy and reduce hallucinations. "Retrieval-Augmented Generation (RAG) has become a powerful paradigm for enhancing LLMs across diverse NLP tasks"
- Reranking labels: Supervised annotations indicating which documents are relevant for a given query, used for training rerankers. "without explicit reranking labels."
- Salient Compressor Pretraining (SCP): A pretraining scheme that teaches a compressor to retain essential semantic content via QA and paraphrase signals. "we propose SCP (Salient Compressor Pretraining), which enhances semantic fidelity by constructing QA pairs that emphasize salient document content beyond surface reconstruction."
- Semantic alignment: Ensuring that compressed and original representations occupy similar semantic spaces. "where balances semantic alignment and generative quality."
- Semantic fidelity: The degree to which compressed representations preserve the meaning of the original text. "we propose SCP (Salient Compressor Pretraining), which enhances semantic fidelity by constructing QA pairs that emphasize salient document content beyond surface reconstruction."
- Shared continuous space: A unified embedding space used for both retrieval and generation to enable joint optimization. "a unified framework that performs embedding-based compression and joint optimization in a shared continuous space."
- Stop-gradient operator: An operation that prevents gradients from flowing through a tensor, used to implement Straight-Through estimators. "where denotes the stop-gradient operator."
- Straight-Through estimator: A technique that uses discrete operations in the forward pass but substitutes differentiable approximations for backpropagation. "we introduce top K selector via Straight-Through (ST) estimator"
- Temperature (softmax temperature): A scaling parameter in softmax that controls the sharpness of the distribution over selections. "Given cosine similarities , temperature , and masking for previously selected items, the soft and hard selections are defined as:"
- Token-level reconstruction loss: A loss that forces models to reconstruct original tokens, which may waste capacity on surface details. "Previous methods \citep{louis-etal-2025-pisco, 10.5555/3737916.3741392} typically use token-level reconstruction loss to learn doc representation."
- Top-K selector: The mechanism that selects the k highest-scoring items for retrieval. "we introduce top K selector via Straight-Through (ST) estimator"
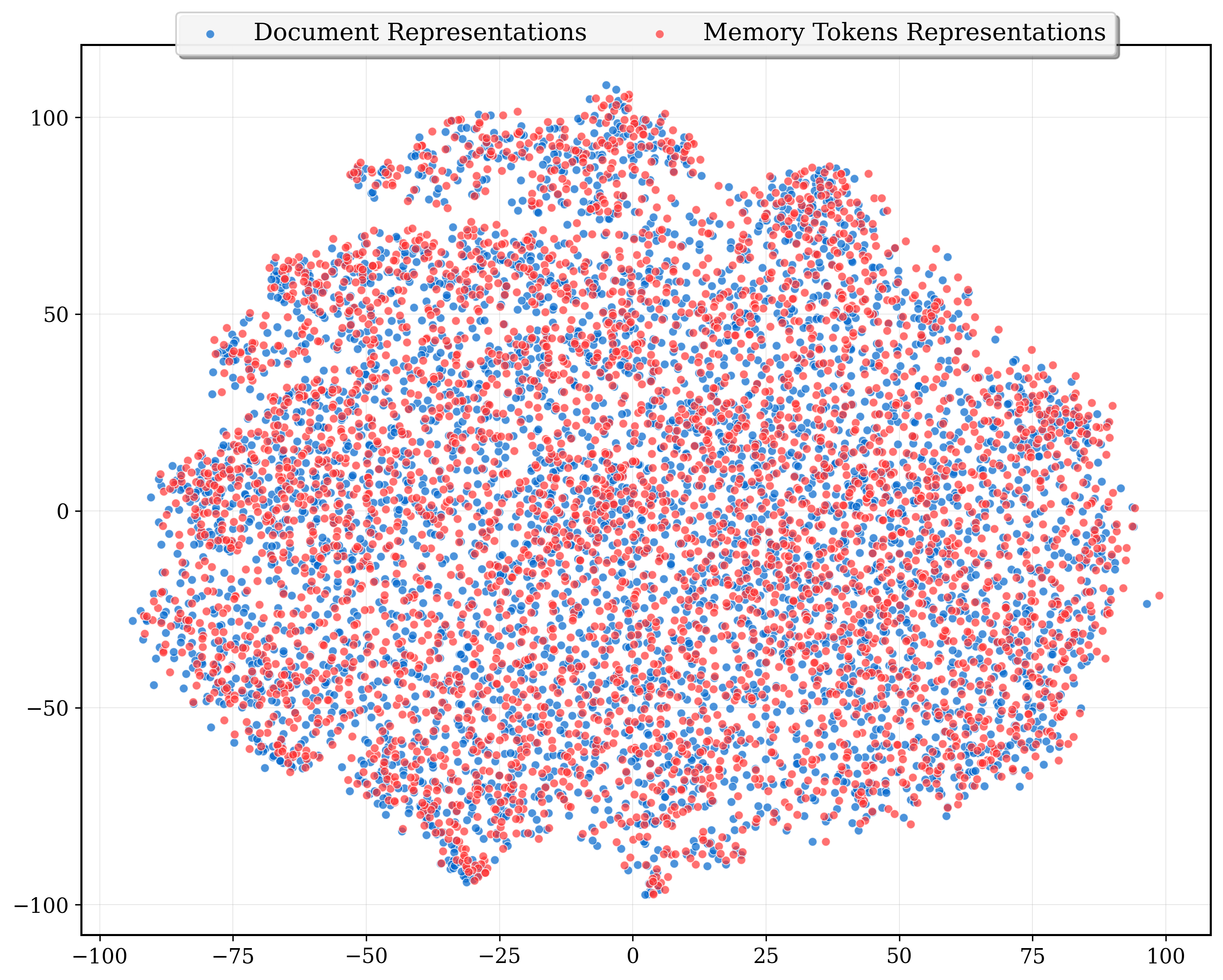
- t-SNE: A dimensionality reduction technique used to visualize high-dimensional embeddings. "we visualize 4K document embeddings and their corresponding compressed representations using t-SNE (Figure~\ref{fig:mse_loss} in Appendix)."
- Weak supervision: Training signals that do not rely on explicit labels, such as using the language modeling loss to guide retrieval. "this allows the retriever (implicitly represented by ) to learn through weak supervision from the generation objective, without explicit reranking labels."
Collections
Sign up for free to add this paper to one or more collections.