- The paper introduces DRPO, a divergence-regularized policy optimization that replaces binary masking with a smooth, advantage-weighted quadratic regularizer.
- It demonstrates how aligning the trust region with absolute probability shifts prevents instability from ratio-based methods and rare token effects.
- Empirical results validate DRPO’s superior performance and efficiency across diverse models and benchmarks in LLM reinforcement learning.
Rethinking Divergence Regularization in LLM RL
Introduction
The paper "Rethinking the Divergence Regularization in LLM RL" (2606.09821) systematically addresses instability and inefficiency in reinforcement learning (RL) optimization for LLMs caused by the mismatch between ratio-based trust-region constraints and the intrinsic geometry of high-dimensional, long-tailed LLM output distributions. The authors critique mainstream techniques, particularly ratio-based methods such as PPO and GRPO, and divergence-based hard-masked methods like DPPO. They introduce Divergence Regularized Policy Optimization (DRPO), which replaces DPPO's hard boundaries with a smooth, advantage-weighted quadratic regularizer on the absolute probability shift, fundamentally based on the Binary Total Variation (TV) distance. The approach is shown empirically to improve stability and sample efficiency in challenging RLHF training settings for LLMs.
Background and Limitations of Existing Methods
Mainstream LLM RL algorithms adapt trust-region policy optimization (TRPO), enforcing constraints on policy updates via divergence penalties or likelihood-ratio clipping. Because autogressive LLMs operate over vocabularies with heavy long tails, importance ratio (IR)–based constraints (as in PPO/SPO/GRPO) are misaligned with the effective distributional shift: small absolute changes to rare tokens yield large ratios, while large absolute changes to frequent tokens can correspond to modest ratios. Consequently, ratio-based controls either over-regularize exploration or allow pathological updates on meaning-critical tokens, leading to unstable training or degraded final accuracy (Figure 1).
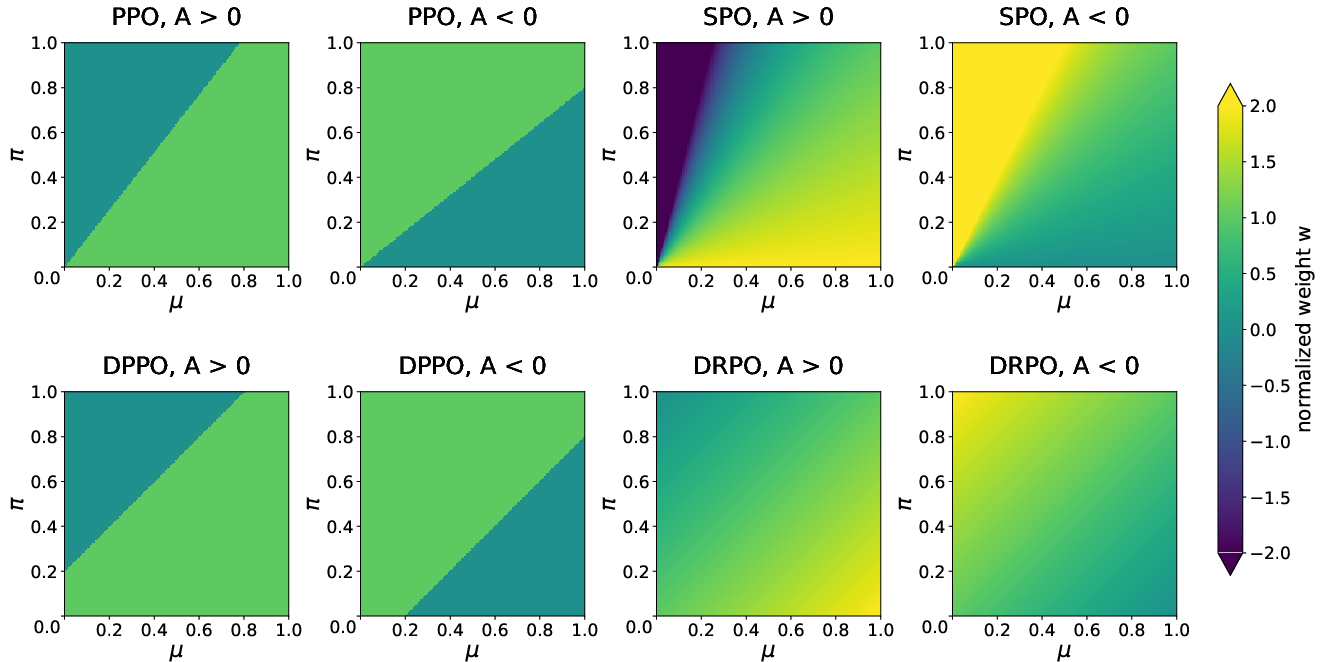
Figure 1: Per-token gradient weights for various algorithms as a function of the behavior and current policy probabilities. DRPO's weight remains bounded for all tokens, preventing instability on rare tokens.
DPPO addresses this by masking gradients for tokens whose absolute probability shift, measured by Binary-TV, exceeds a preset threshold in a harmful direction, thereby aligning the constraint to a measurable distributional shift. However, the binary gradient mask in DPPO results in abrupt discontinuities at the trust-region boundary and provides no corrective gradient for tokens that have crossed it—impairing convergence and training robustness.
DRPO: Divergence-Regularized Policy Optimization
DRPO is constructed by reframing the trust region from the ratio-based regime to a divergence-based regime, specifically targeting the sampled token's absolute probability shift ∣π(yt∣st)−μ(yt∣st)∣ (Binary-TV). This is realized by adapting the regularization principle of SPO to this geometry, yielding the following objective: LDRPO=Ey∼μ(⋅∣x)[t∑rtA^t−2δ∣A^t∣μ(yt∣st)(rt−1)2]
where rt is the importance ratio, A^t is the advantage estimate, and δ is the Binary-TV trust-region threshold.
This quadratic penalty ensures that the effective gradient for each token is governed by a bounded, continuous weight,
wt=1−sign(A^t(rt−1))δ∣π(yt∣st)−μ(yt∣st)∣,
suppressing divergent updates as the trust region boundary is approached while providing restorative gradients for tokens outside it. Unlike ratio-based approaches, this ensures that the weight does not diverge on rare tokens (Figure 1), which empirically represents a significant stabilizing factor across LLM RL settings.
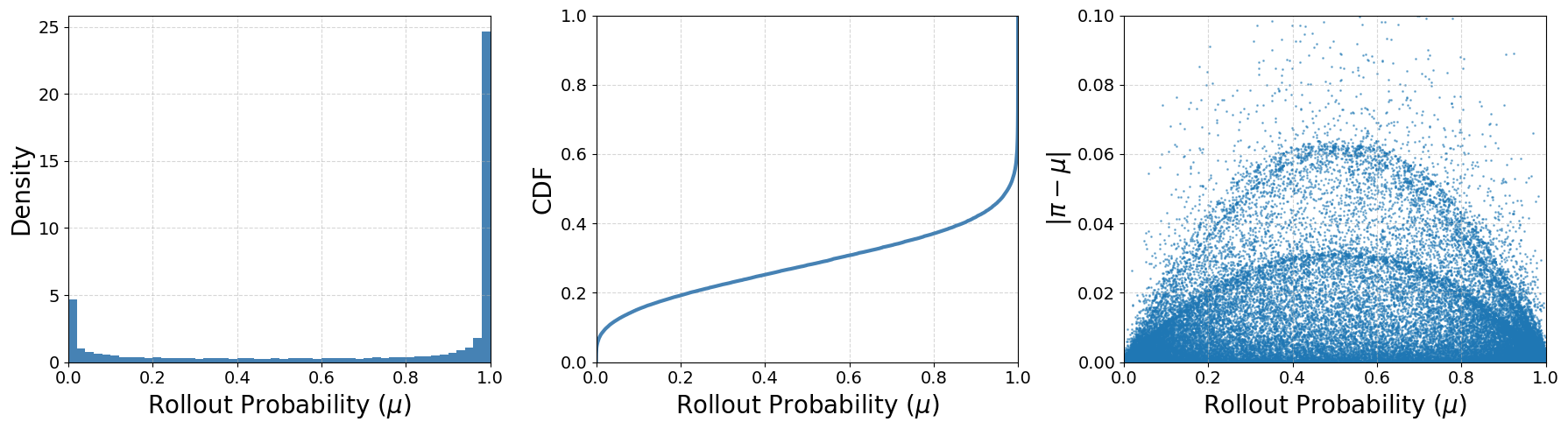
Figure 2: Distribution of rollout probabilities and corresponding absolute probability shifts in Qwen3-30B-A3B-Base, highlighting the prevalence of low-probability tokens.
Analysis of Trust-Region Geometry and Gradient Dynamics
Through both theoretical and empirical investigation, the authors demonstrate that DRPO's trust region is strictly aligned with the Binary-TV criterion, yielding clear, interpretable boundary behavior:
- For updates moving away from the behavior policy, gradients are smoothly attenuated and reverse outside the region, providing direct regularization back to permissible policy space.
- For convergent updates, the gradient is proportionally amplified, encouraging rapid correction.
This is contrasted with the instability of ratio-based regularization (PPO/SPO), whose gradient weights can diverge on rare tokens due to their 1/μ(yt∣st) scaling (Figure 2), and with the abrupt, information-losing suppression of DPPO's mask.
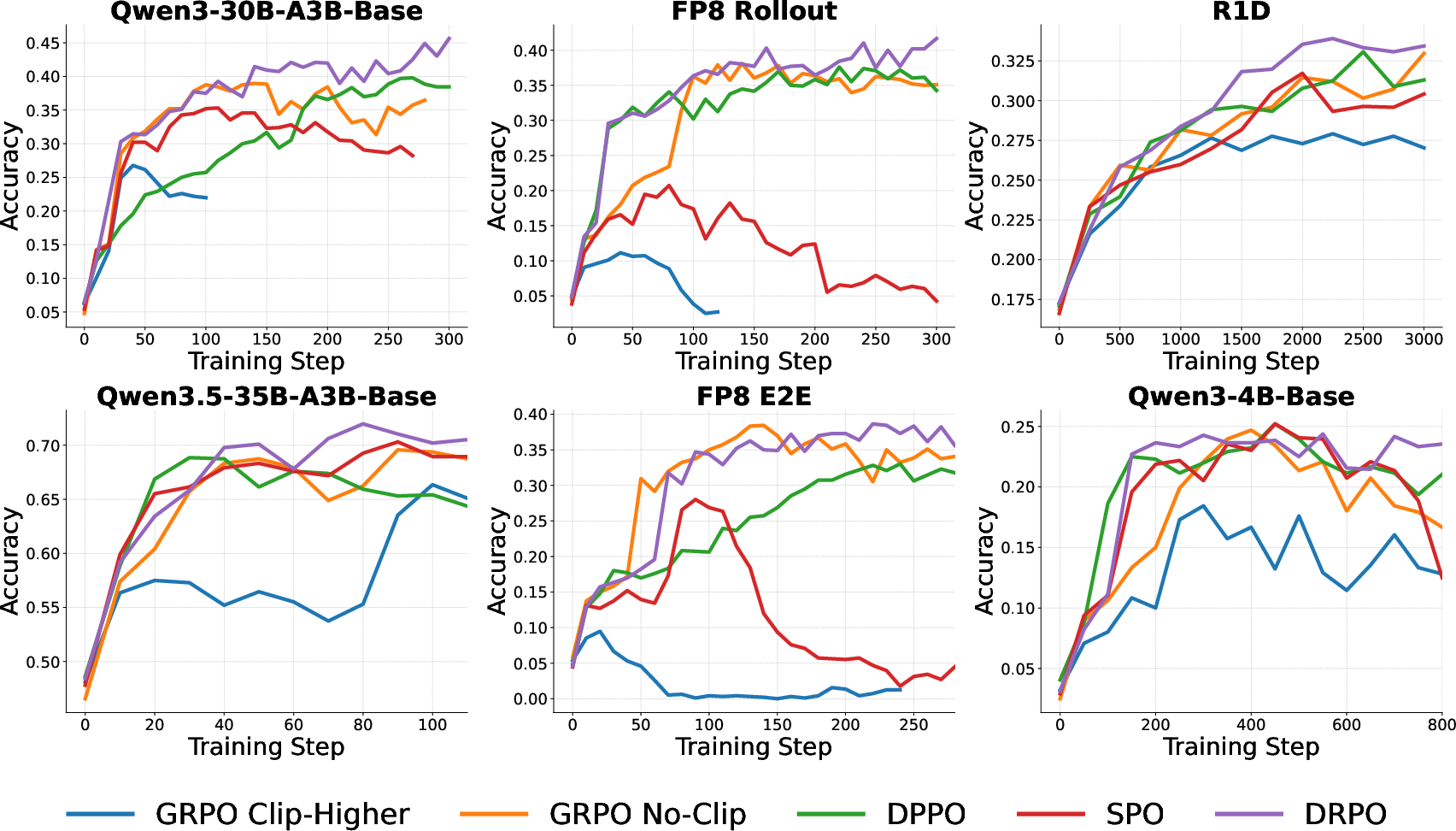
Figure 3: DRPO enables superior and more stable performance across multiple models and settings on the AIME24/AIME25 benchmarks.
This formal framework is further compared against alternative divergence regularizations (KL, TV, etc.), showing that only the advantage-weighted quadratic penalty with respect to absolute probability shift delivers a bounded-gradient, geometry-aligned trust region (Table: method comparison, Section 3.2).
Empirical Results
Experiments span several scales (Qwen3-4B, Qwen3-30B-A3B, Qwen3.5-35B-A3B, DeepSeek-R1D), data regimes (math reasoning, rule-based verification), and precision settings (BF16, FP8). Training is conducted using VeRL and high-throughput inference engines to expose training-inference mismatch and staleness. The authors consistently observe:
- DRPO achieves the highest or equal-best accuracy across diverse benchmarks and precision settings, outperforming both ratio-based methods (GRPO, SPO) and hard-masked divergence-based baselines (DPPO).
- Ratio-based methods exhibit pronounced instability, especially under low-precision or MoE architectures, often failing to reach competitive accuracy.
- Hard-mask methods are outperformed or converge more slowly than DRPO, especially when optimization is noisy or the model is large.
- The trust-region-free policy-gradient surrogate is strong but unreliable, suffering catastrophic drops in several configurations, confirming the necessity (but not sufficiency) of trust-region control.
- Ablation on the advantage weight ∣A^t∣ in the regularizer demonstrates that removing it leads to severe performance degradation and instability (Figure 4).
- Alternative sampled regularizers (KL, TV, K3, etc.) underperform DRPO, as their gradients either re-introduce ratio-based boundaries or result in binary weights, further supporting the necessity of a smooth, probability-shift-based regularizer (Figure 5).
- Experiments applying the DRPO regularizer only outside the DPPO trust region reveal that the main performance contribution stems from providing corrective gradients where DPPO's mask would “shut off” learning (Figure 6).
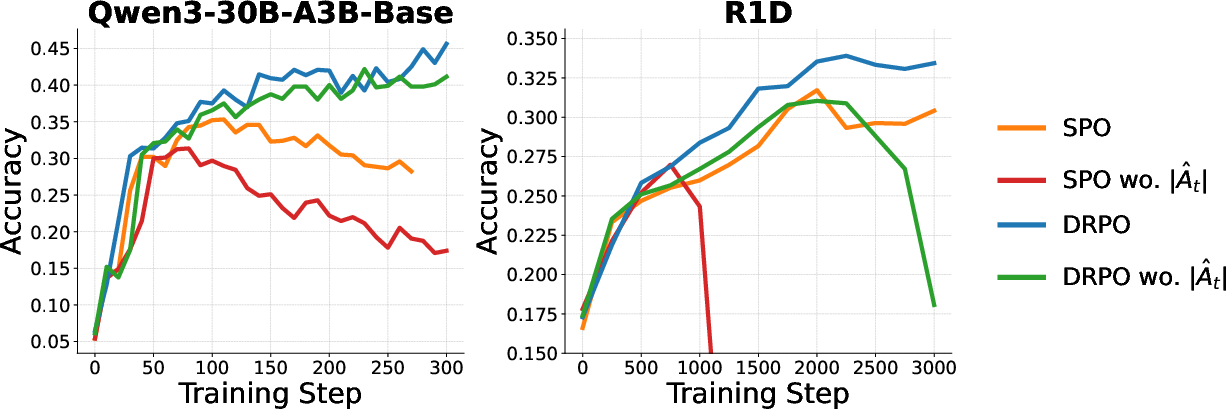
Figure 4: Ablation on the advantage weight. Removing ∣A^t∣ destabilizes training and degrades accuracy.
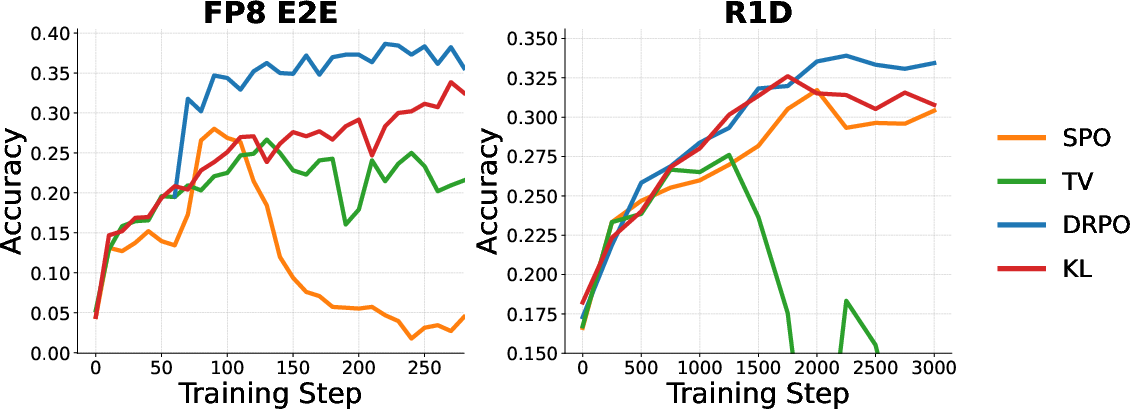
Figure 5: Ablation on alternative divergence regularizers. DRPO with Binary-TV consistently yields the best results.
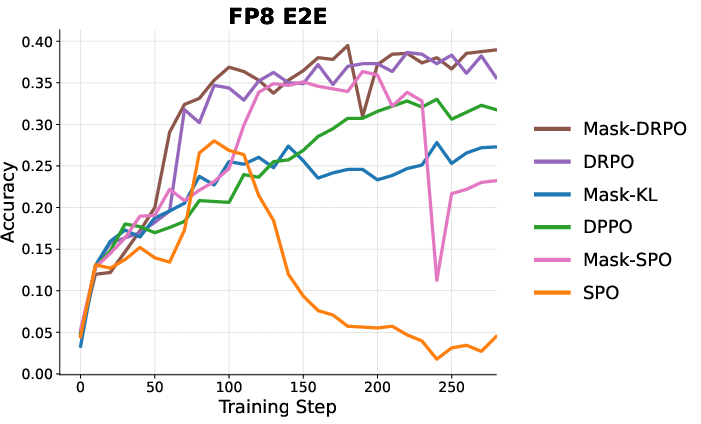
Figure 6: Applying DRPO's regularizer only outside DPPO's hard boundary preserves most of the performance gain, emphasizing the importance of smooth corrective signals.
Theoretical and Practical Implications
The findings suggest that, for LLM RL, the geometry induced by the regularizer's gradient is a critical determinant of stable and efficient learning, dominating the nominal divergence being minimized. Regularizers that do not induce a bounded, smooth, probability-shift–aligned gradient either fail to robustly enforce a trust region (KL, ratio-based methods) or impede optimization through binary masking (hard-mask methods). The empirical results and analysis recommend three practical criteria for trust-region regularization:
- Stable, geometry-aligned boundaries (absolute probability shift rather than ratio).
- Bounded per-token gradient weights to prevent instability driven by long-tail vocabulary effects.
- Smooth, corrective gradients in the out-of-region regime to enable recovery.
DRPO uniquely satisfies these requirements in the context of current LLM RL settings.
Future Work
The methodology outlined by DRPO invites several promising directions:
- Extension to more expressive, higher-order divergence proxies that better capture semantic drift in LLM rollouts.
- Principled design of token-wise or group-wise adaptive thresholds based on model scale, reward variance, or rollout entropy.
- Integration with advanced RLHF reward modeling, especially for tasks with noisy or multimodal reward landscapes.
- Hardware-aware adaptation, refining precision/mixed-precision deployment to further mitigate training-inference gap and off-policy effects.
Conclusion
This work advances the design of trust-region mechanisms for LLM RL by introducing DRPO—a divergence-aligned, advantage-weighted quadratic regularizer defined by absolute probability shift. DRPO is shown to deliver significant improvements in efficiency, stability, and final accuracy compared to both ratio-based and hard-mask trust-region techniques. The contribution resides not only in the Binary-TV trust-region criterion but in the insight that the induced per-token gradient structure is more impactful than the explicit divergence choice in the objective function. This has implications for all future LLM RL systems operating in high-dimensional, off-policy, and noisy-update settings, providing a new foundation for robust RLHF at scale.