- The paper introduces a fast streaming TTS framework that uses lagged multi-track input to eliminate buffering and reduce initial latency.
- It employs parallel multi-token prediction modules to simultaneously generate multiple tokens, significantly lowering first-token and first-packet latencies.
- The X-pred mean flow distillation technique minimizes neural function evaluations while ensuring high-fidelity mel-spectrogram synthesis across multiple languages.
FlashTTS: Fast Streaming TTS with MTP Acceleration and X-pred Mean Flow Distillation
Introduction
FlashTTS introduces a streaming-capable, low-latency text-to-speech (TTS) framework, architected to optimize for real-time end-to-end dialogue and conversational ASR-TTS systems. Its principal advances are a lagged multi-track input structure enabling streaming mode operation, parallel Multi-Token Prediction (MTP) blocks for decoding acceleration, and an X-pred Mean Flow matching decoder that ensures high-fidelity mel-spectrogram synthesis with minimal neural function evaluations. FlashTTS natively handles streaming input/output, breaking from the sentence-level buffering and autoregressive bottlenecks typical of LLM-based TTS systems.
System Architecture
FlashTTS segments its pipeline into two distinct training and architectural stages. In Stage 1, a decoder-only transformer receives parallel, stacked streams of speech, text, and language-specific embeddings, followed by a mean flow matching network for waveform reconstruction. Stage 2 freezes the LLM backbone and attaches lightweight, parallel MTP modules, each predicting multiple future tokens from a shared backbone hidden state, which facilitates quasi-non-autoregressive decoding and significantly lowers generation latency.
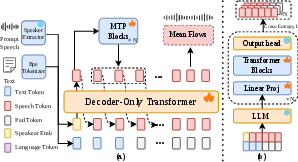
Figure 1: Architecture overview—Stage 1: training stacked parallel input tracks; Stage 2: MTP acceleration and X-pred mean flow decoding structure.
Uniquely, FlashTTS implements lagged multi-track streaming input, in contrast to the concatenated/interleaved token streams employed by prevailing TTS systems. This is operationalized by the use of stacked speech, text, and language tracks, all processed concurrently and lagged to enable streaming on incomplete input. Padding maintains alignment, and language conditioning is provided from start to finish. Consequently, FlashTTS does not require any sentence-level text buffering, greatly reducing first-packet and first-token latency.
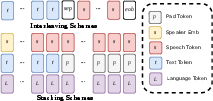
Figure 2: Comparisons of stacked (proposed), concatenated, and interleaved input schemes for TTS sequence modeling. Only the stacked format supports efficient streaming and minimal latency.
Acceleration via Multi-Token Prediction (MTP)
The MTP modules, inspired by parallel speculative decoding methods, each consist of a linear projection plus a Qwen2.5-style transformer block. Rather than sequential token-by-token autoregression, MTP predicts up to N−1 tokens simultaneously using frozen backbone representations. Granular loss is provided by matching each speculative token ‘branch’ against ground-truth with shifted cross-entropy, and only those tokens validated by the robust backbone LM are committed, securing quality even under speculative decoding.
This joint use of parallel prediction with decoder validation distinguishes FlashTTS from CosyVoice2 and related pipelines, which remain restricted by serial autoregressive bottlenecks despite employing efficient decoders.
X-pred Mean Flow Distillation
In the acoustic decoder, FlashTTS employs X-pred Mean Flow matching, an advanced instantiation of flow matching-based distillation. Distillation targets are constructed by explicit data prediction, with parameterization directly over the clean mel-spectrogram rather than velocity fields; average velocity is analytically derived. A block-wise attention mechanism further enables native streaming synthesis. The architecture is highly optimized, requiring only 2 neural function evaluations (2-NFE), underpinned by recent advances in few-step flow and velocity distillation generative modeling.
Experimental Results
Latency and Throughput
FlashTTS achieves substantial improvement over state-of-the-art baselines on several latency metrics. With the MTP-3 (2-NFE) configuration, end-to-end first-token latency (FTL) is reduced to 62ms, and first-packet latency (FPL) to 325ms—a significant reduction from the 843ms seen in CosyVoice2. Throughput, measured in tokens-per-second (TPS), increases by nearly 50% relative to strong non-commercial open-source systems. Notably, this acceleration comes without a commensurate degradation in WER or speaker embedding similarity (SIM). Real-Time Factor (RTF) also sees a marked reduction.
Multilingual, Zero-Shot, and Subjective Quality
Comprehensive evaluation on MiniMax and Seed test sets covering Chinese, English, Japanese, Korean, French, and German demonstrates stable WER/SIM across all supported languages. In English and Korean, FlashTTS shows lower or comparable error rates to all reference open-source baselines, with robust zero-shot voice fidelity maintained. French and German—unsupported by prior leading models—are handled with competitive intelligibility.
Subjective CMOS listening tests confirm no degradation in perceived quality relative to slower or larger systems, particularly when operating at the optimal MTP-3 (2-NFE) balance point.
Ablations
Ablation studies confirm the necessity of both MTP and X-pred modules for achieving speedup without compromising synthesis stability. Removing MTP or X-pred drastically regresses efficiency, and omitting the explicit language ID module leads to severe cross-lingual error rate increases.
Theoretical and Practical Implications
FlashTTS reifies the critical insight that the primary limiting factor for interactive, streaming speech dialogue is not the generative fidelity of LLM-driven token synthesis or flow matching in isolation, but their orchestration and sequence management under streaming conditions. By blending lagged, stack-based input sequencing, speculative parallel token generation, and minimal-step mean flow decoding, it renders real-time zero-shot and cross-lingual TTS feasible for practical deployments—a significant step towards fully end-to-end spoken dialogue pipelines with tight ASR-TTS coupling.
Algorithmically, FlashTTS sets a precedent for applying mean flow-based distillation under speculative decoding and for rigorous attention to streaming constraints in system design, which will likely inform architectural directions beyond TTS into broader generative multimodal model efforts.
Conclusion
FlashTTS advances the LLM-based TTS field by holistically addressing the architectural and inference bottlenecks that have precluded true real-time, streaming, low-latency speech synthesis in dialogue systems. The integration of lagged multi-track sequencing, parallel speculative MTP, and X-pred Mean Flow decoding robustly balances decoding speed, quality, and language coverage. These results underline the viability of FlashTTS as a scalable backbone for next-generation streaming applications across multilingual, zero-shot, and interactive deployment scenarios (2606.09141).

