Voxtral TTS
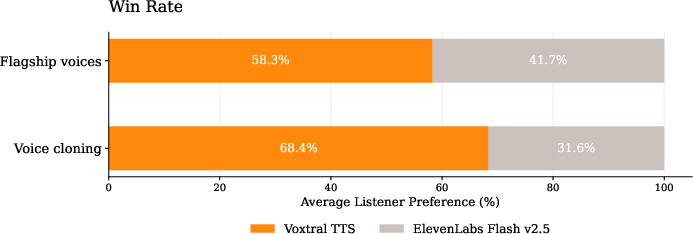
Abstract: We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Voxtral TTS, a system that turns written text into speech that sounds natural and expressive, and can copy a person’s voice from just a very short audio clip (as little as 3 seconds). It works in 9 languages and is designed to be fast enough for live use, like reading chat messages out loud or powering voice assistants.
What questions does the paper try to answer?
The authors focus on three simple questions:
- How can we make computer-generated speech sound more like a real person—with emotion, rhythm, and style—while staying clear and understandable?
- Can we copy a new voice (someone the system has never seen before) from just a few seconds of audio, without special training for that person?
- Can we build a system that’s both high quality and fast, so it can stream audio in real time?
How does Voxtral TTS work? (Explained with everyday ideas)
Think of speech as having two parts:
- What is being said (the “meaning” of the words and phrasing).
- How it sounds (the tone, accent, emotion, and small details like breathiness).
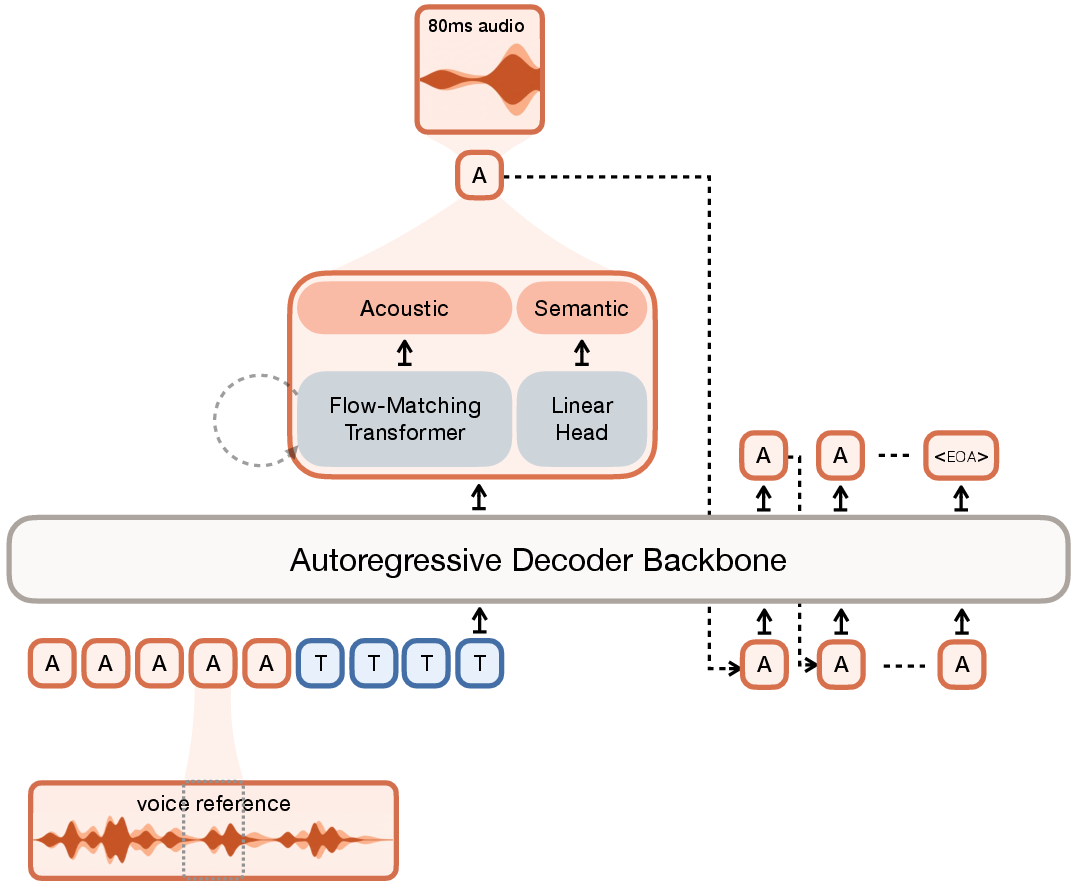
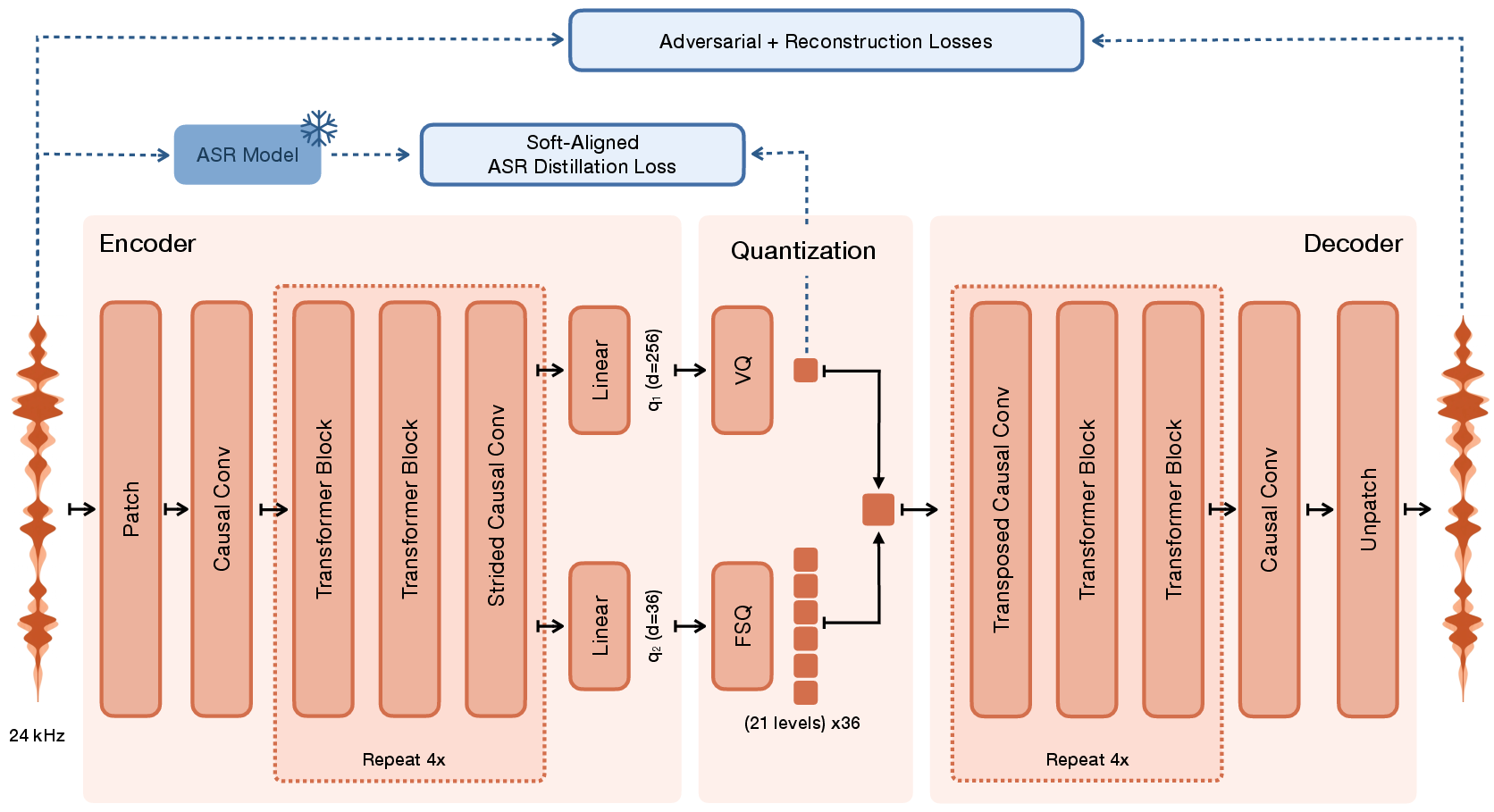
Voxtral TTS splits speech into these two parts using a special “audio codec” called Voxtral Codec. Then it uses two different tools to generate speech:
The key pieces
- Voxtral Codec: Like turning an audio clip into a set of tiny LEGO blocks (called “tokens”). It makes:
- Semantic tokens: These represent the meaning of the speech—like the words and timing.
- Acoustic tokens: These add the sound details—like voice color, accent, emotion, and texture.
- Decoder backbone (a transformer model): This is the part that writes the “story” of the speech by predicting semantic tokens one step at a time. “Auto-regressive” just means it builds the speech token by token, always looking back at what it wrote before to stay consistent.
- Flow-matching transformer: This is a smart painter for sound details. It starts with “noise” and guides it into the right acoustic shape that matches the target voice and emotion. Think of it like gradually shaping a blur into a sharp picture using hints from the decoder.
How does the codec learn “meaning” well?
They teach the codec’s semantic tokens using a strong speech-recognition model (Whisper) as a “teacher.” This is like having a coach guide the model about which parts of the audio match which words, so the tokens actually capture useful language information—not just raw sounds.
Training with preferences (DPO)
After basic training, they use Direct Preference Optimization (DPO). In simple terms:
- The model creates several versions of the same speech.
- A judging system picks which ones are better (clearer words, closer voice match, more natural).
- The model learns to prefer the better examples next time.
They adapted DPO to work with both the “meaning” part (semantic tokens) and the “sound details” part (acoustic flow-matching).
Why this mixed design?
- Auto-regressive generation keeps long sentences consistent and coherent (good for meaning).
- Flow-matching fills in rich details quickly without doing the slow “one tiny step at a time” process for all sound layers (good for texture and speed).
- Result: expressive speech that sounds like the reference voice, but generated faster.
What did they find?
Here are the main takeaways:
- Voice cloning with tiny prompts: Voxtral TTS can copy a voice from as little as 3 seconds of audio.
- Human preference: In blind listening tests with native speakers, Voxtral TTS was preferred over ElevenLabs Flash v2.5 for zero-shot voice cloning 68.4% of the time across 9 languages.
- Strong intelligibility and naturalness: Automatic tests show the speech is clear, and people rate it as natural and expressive.
- Fast and streamable: The system is optimized for low-latency streaming. It starts playing audio quickly and scales to many users at once on a single GPU.
- A better codec: Their Voxtral Codec compresses audio smartly and outperforms a popular baseline (Mimi) at similar bitrates on several quality measures.
Why is this important?
Many uses—like audiobooks, accessibility tools, video dubbing, and virtual assistants—need voices that sound real and can reflect emotions, not just read text robotically. Voxtral TTS shows that:
- You don’t need long voice recordings to clone a voice well.
- You can combine two modeling styles (auto-regressive for meaning and flow-matching for sound) to get both expressivity and speed.
- Careful training with preferences (DPO) helps reduce mistakes like skipping words or fading volume, making the speech more reliable.
What could this lead to?
- More personalized and natural-sounding voices for apps and games—even when the available voice sample is short.
- Better multilingual tools that speak in your voice across different languages.
- Faster and more responsive voice systems for live conversations or streaming.
- Open research and development: The model weights are released (for non-commercial use), so researchers can build on this to improve speech quality, emotion control, and fairness across voices and languages.
In short, Voxtral TTS is a step toward making computers speak like humans—not just in what they say, but in how they sound—quickly and in many languages, with very little voice input required.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what the paper leaves missing, uncertain, or unexplored. Each point is phrased to be directly actionable for future research.
Data, coverage, and ethics
- Quantify the training corpus: hours per language, domain/source mix, accent/age/gender diversity, and noise conditions; report how much pseudo-labeled vs. human-labeled audio is used.
- Assess language balance and coverage for the 9 supported languages, including dialectal breadth and script/orthography variation (e.g., Arabic diacritics, Hindi transliteration).
- Evaluate code-switching and mixed-language inputs, which are common in multilingual settings but untested here.
- Analyze the effect of pseudo-label quality from Voxtral Mini Transcribe on training outcomes (especially per-language WER and hallucinations), and compare to training with gold transcripts.
- Provide ethical documentation on data consent/rights, speaker privacy, and opt-out mechanisms for voice data used during training.
- Investigate demographic fairness: measure performance variations across gender, age, and accent groups; report bias analyses and mitigation strategies.
Evaluation design and validity
- Report statistical significance (CIs, p-values) and inter-annotator agreement for all human preference studies; include sample sizes per language and emotion condition.
- Provide absolute MOS tests in addition to pairwise preference to calibrate perceived quality across systems and languages.
- Ensure experimental parity in emotion “explicit steering” comparisons: Voxtral is steered via alternative voice prompts while competitors use text instructions; quantify the effect of steering modality on outcomes.
- Evaluate robustness to text domain (conversational, news, read speech, dialogue), and provide stratified results.
- Validate speaker similarity metrics (ECAPA) across languages/genders and check correlation with human judgments.
- Include long-form evaluations (minutes-long passages) for stability, drift, and prosodic consistency, not just short prompts.
Generalization and robustness
- Quantify performance as a function of reference clip length and quality: 3s vs. 10s vs. 30s, varying SNR, reverberation, channel mismatch, and far-field microphones.
- Test out-of-domain languages, including tonal (e.g., Mandarin), morphologically rich (e.g., Turkish), and low-resource languages to assess extensibility beyond the current nine.
- Evaluate resilience to “in-the-wild” artifacts (music in background, overlapping speech, compression) and report degradation curves.
- Measure stability on long utterances: word skipping, volume drift, prosody drift, and timing alignment (including <EOA> correctness).
- Assess code-switching and mixed-script inputs (e.g., “Hinglish”, Arabic–English), which are not currently evaluated.
Controllability and expressivity
- Add and evaluate text-based controllability (emotion/style tags, prosody, pitch, speed, pace, pauses); current method relies on swapping the voice prompt to steer emotion.
- Provide mechanisms for explicit duration/tempo control and alignment to punctuation; evaluate timing adherence and speaking rate control.
- Explore fine-grained prosody control (e.g., per-sentence or word-level emphasis) and measure objective prosody metrics (F0, energy contours, pause patterns).
- Evaluate non-speech vocalizations (laughter, sighs) and singing, which are not covered.
Modeling and training methodology
- Analyze the impact of the ASR-distillation objective on semantic token quality: ablate against self-supervised distillation and no-distillation baselines, and report alignment accuracy to text (e.g., word/phoneme boundaries).
- Probe whether joint modeling or alternative factorization of semantic/acoustic streams improves coherence vs. the current hybrid AR+FM split.
- Compare flow-matching to alternative non-AR decoders with quantitative results (e.g., MaskGIT, depth-wise AR) rather than anecdotal preference; include latency-quality trade-offs.
- Examine the effect of discretization granularity: number of FSQ acoustic dimensions and levels (36 × 21) on quality, bitrate, and latency; produce rate–distortion curves.
- Investigate sampling strategies for the AR semantic path (temperature, top-k/p) and their interaction with flow-matching CFG on acoustic detail; report quality/WER/speaker-similarity trade-offs.
- Study the per-frame conditional CFG used in FM: does independent frame-wise guidance introduce temporal incoherence? Compare with sequence-aware conditioning or learned CFG schedules.
DPO and preference optimization
- Detail the composition and quality of DPO preference data (how many pairs per language, per-emotion, average lengths); quantify dependence on auto-metrics (WER, UTMOS) vs. human preference labels.
- Analyze why Hindi regresses with DPO and formulate cross-language stability strategies (e.g., language-specific β, curriculum DPO, or filtering).
- Compare flow-DPO to alternative post-training methods (reinforcement learning with human feedback, reward models, pairwise rankings with human raters).
- Evaluate generalization of DPO improvements to unseen speakers, extreme styles, and noisy prompts; report overfitting risks to synthetic preference distributions.
Codec and representation learning
- Compare Voxtral Codec against a wider set of baselines (e.g., Encodec, SoundStream variants) under matched bitrates and latency, including subjective MOS tests.
- Validate the semantic/acoustic split with interpretability analyses: how much linguistic vs. speaker/style information is captured in each token type?
- Report the latency and computational profile of codec encode/decode in streaming settings, including chunk boundary artifacts and cross-chunk coherence.
- Provide alignment quality measurements for the ASR-distilled semantic tokens (e.g., correlation with word timestamps or phoneme boundaries) and robustness across languages.
Inference, deployment, and scaling
- Benchmark on commodity GPUs and CPUs, not only H200s; provide memory footprint, throughput, and RTF under quantization/pruning.
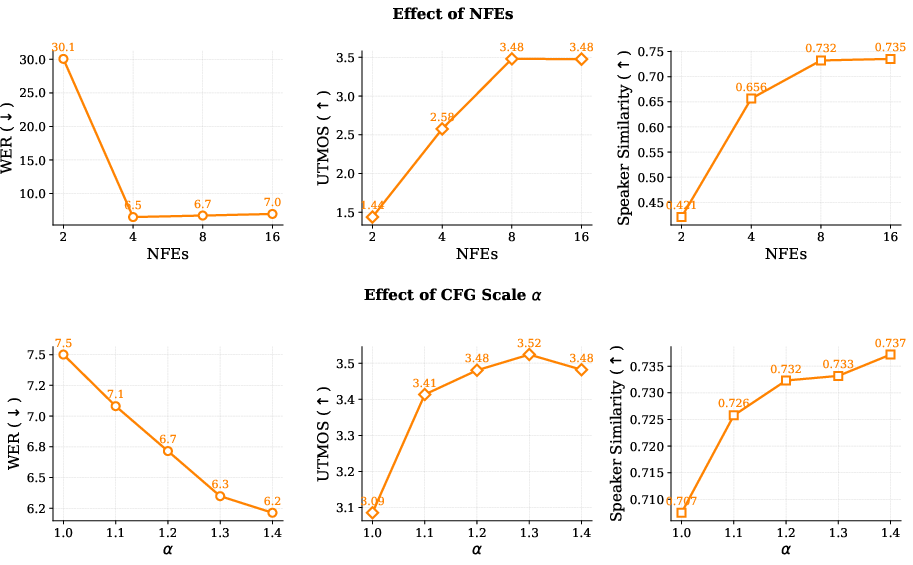
- Explore alternative ODE solvers and NFEs vs. quality trade-offs for FM; current work uses Euler with 8 NFEs but does not compare solver types.
- Quantify audio artifacts at chunk boundaries in streaming (despite overlap), using perceptual and objective coherence metrics.
- Characterize scalability with longer texts, multiple concurrent users beyond 32, and varying reference lengths; report tail latencies and jitter.
- Measure energy consumption and environmental impact of inference and training; explore quantization-aware training or distillation for lower-cost deployment.
Safety, misuse, and watermarking
- Propose and evaluate watermarking or provenance signals for generated audio to deter spoofing and misuse; test robustness to post-processing.
- Include anti-impersonation safeguards (e.g., voice-owner consent checks, ASV-based matching filters) and measure false accept/reject rates.
- Study adversarial or malicious inputs (prompted content or noisy references) that could induce undesirable behavior or privacy leaks.
Reproducibility and release
- Provide full training details: optimizer schedules, compute budget, steps/epochs, curriculum, and ablation results referenced but not shown.
- Release data preparation scripts (text normalization, VAD, LLM rewrites), and evaluation pipelines to reproduce reported numbers.
- Clarify which components (codec, FM transformer, inference stack) are released and under what license constraints; detail what is necessary to reproduce end-to-end results given CC BY-NC weights only.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed with the released Voxtral TTS weights and the serving stack described in the paper (vLLM‑Omni), subject to the CC BY‑NC license and other practical constraints.
- Industry | Media & Localization: Rapid multilingual dubbing and audiobooks with consistent speaker identity
- What: Zero‑shot voice cloning from 3–25 s prompts to produce expressive audiobooks, podcasts, trailers, and ad creatives across 9 languages.
- Why enabled: Hybrid AR (semantic) + flow‑matching (acoustic) yields natural prosody and high speaker similarity; streaming with sub‑second TTFB; strong human preference vs ElevenLabs Flash v2.5.
- Tools/workflows: Use Voxtral TTS weights + vLLM‑Omni for chunked streaming; batch production pipelines with CUDA‑graph‑accelerated flow matcher; prompt libraries per emotion/persona via carefully selected reference clips.
- Dependencies/assumptions: CC BY‑NC restricts commercial use; high‑quality 3–25 s reference audio; currently 9 languages; GPU‑backed serving (e.g., H200) for low latency.
- Industry | Contact Centers and IVR: Branded voices for voicebots and call flows
- What: Deploy expressive, branded voices for IVR menus and agent handover messages; fine‑tune prompt selection for cheerful, neutral, or calming delivery without text tags (implicit steering).
- Why enabled: Low latency streaming (RTF 0.1–0.3) and high speaker similarity; implicit emotion steering performs well in human evaluations.
- Tools/workflows: vLLM‑Omni streaming in telephony stack; reference‑prompt catalogs tied to intent (e.g., billing vs support); CFG/NFE presets for latency/quality trade‑offs.
- Dependencies/assumptions: No explicit emotion tags; quality relies on reference‑prompt selection; licensing for commercial deployment; GPU inference.
- Accessibility | Screen readers and assistive speech
- What: Personalized, expressive voices for screen readers and text‑to‑speech aids; voice banking for users with degenerative speech conditions using short recordings.
- Why enabled: Zero‑shot cloning from a few seconds of audio; strong intelligibility and naturalness; low‑latency streaming.
- Tools/workflows: Voice banking UI to collect 3–30 s samples; on‑device client streaming from server; parameter presets (NFEs=8, CFG≈1.2) for clarity vs expressivity.
- Dependencies/assumptions: Clinical/ethical consent; stable internet/GPU backend; CC BY‑NC for non‑commercial assistive use or separate commercial license.
- Education | Language learning and courseware narration
- What: Multilingual, expressive narration for lessons, with consistent tutor voices across languages; pronunciation‑focused readings.
- Why enabled: 9‑language support; good WER and human‑rated naturalness; high speaker similarity for consistent identity.
- Tools/workflows: LMS integration with TTS microservice; curated reference prompts per “teacher persona”.
- Dependencies/assumptions: Coverage limited to supported languages; GPU serving; licensing constraints.
- Software & Product | In‑app TTS and creator tools
- What: Add “speak in my voice” or “brand voice” features in video editors, slideware, and writing apps; create voice‑consistent product tours or summaries.
- Why enabled: 3–25 s reference prompts; low‑bitrate token stream enables efficient server‑side streaming.
- Tools/workflows: App plugin calls vLLM‑Omni endpoint; token‑level chunked streaming for instant preview; prompt management for tone control.
- Dependencies/assumptions: User consent for voice cloning; GPU serving costs; CC BY‑NC limitations.
- Games & Interactive Media | Dynamic NPC voices
- What: Generate consistent, emotive NPC speech on the fly from dialogue scripts; maintain identity across story branches.
- Why enabled: High speaker similarity and expressivity; sub‑second TTFB fits interactive cycles.
- Tools/workflows: Runtime server stream to game engine; pre‑indexed reference prompts per character; latency budgets tuned via NFEs/CFG.
- Dependencies/assumptions: Online connectivity or local GPU; emotion via prompt selection rather than text tags.
- Research & Academia | Benchmarking and methodology transfer
- What: Study hybrid discrete‑continuous generation (AR semantics + flow‑matching acoustics), preference‑aligned TTS (flow‑DPO), and ASR‑distilled semantic tokenizers.
- Why enabled: Open weights and detailed training/inference design; strong zero‑shot performance for controlled comparisons.
- Tools/workflows: Ablation studies on NFEs/CFG; evaluation on SEED‑TTS/MiniMax; integrate STAB/ESTOI/PESQ pipelines.
- Dependencies/assumptions: Access to GPUs; adherence to non‑commercial license; availability of Voxtral Codec weights within the release.
- Security & Testing | ASR and speaker‑verification robustness
- What: Generate hard negative samples to stress‑test ASR and anti‑spoofing systems across languages and voices.
- Why enabled: High‑similarity voice cloning and expressive variation produce challenging adversarial‑like inputs.
- Tools/workflows: Synthetic corpora with diverse prompts and CFG/NFE sweeps; measure EER/FAR in SV systems.
- Dependencies/assumptions: Ethical use restrictions; non‑commercial research; careful dataset governance.
- Communications | Low‑bitrate TTS streaming in constrained channels
- What: Server‑side token streaming (2.14 kbps) for bandwidth‑constrained scenarios (e.g., remote education or rural services).
- Why enabled: Voxtral Codec’s low‑bitrate semantic+acoustic tokenization; asynchronous chunking ensures continuity.
- Tools/workflows: Transmit tokens instead of waveform; decode at edge or server; overlap windows for coherence.
- Dependencies/assumptions: Both endpoints share codec/TTS stack; license terms; error‑resilience mechanisms for packet loss.
- Public Sector | Multilingual public announcements and alerts
- What: Rapid, consistent voice messaging in multiple languages for civic information and emergency updates.
- Why enabled: Strong intelligibility, naturalness, and streaming at scale (30+ concurrent streams on single H200).
- Tools/workflows: Gov CMS → TTS pipeline with language routing; pre‑vetted reference prompts for neutral/authoritative tone.
- Dependencies/assumptions: Operational GPU infra; governance for consent and authenticity disclosures.
Long-Term Applications
These use cases will benefit from further research, broader language support, explicit controllability, on‑device optimization, standardization, or policy development.
- Real‑time speech‑to‑speech translation preserving speaker identity
- What: End‑to‑end pipeline (ASR → NMT → Voxtral TTS) to translate live speech while retaining the speaker’s voice and expressive cues.
- Why future: Requires tight latency budgets, robust cross‑lingual prosody transfer, and integration across components.
- Dependencies: High‑quality ASR/NMT; improved emotion control; scalable serving; safety safeguards for misuse.
- Fine‑grained controllability of emotion, style, and prosody via text prompts
- What: Add explicit tags or free‑form instructions (e.g., anger, warmth, formality) rather than relying solely on reference prompts.
- Why future: Current system excels at implicit steering; adding explicit control needs model/UX extensions and training data.
- Dependencies: Supervised style labels or RLHF/DPO data with emotion tags; interface changes; robust cross‑language calibration.
- On‑device and embedded TTS for mobile/IoT/robotics
- What: Run a compressed Voxtral TTS stack on edge devices (assistive devices, robots) for offline, private, low‑latency speech.
- Why future: 4B TTS + codec currently targets GPU servers; on‑device use needs distillation, quantization, pruning, or smaller variants.
- Dependencies: Model compression; hardware accelerators; memory/latency budgets; energy constraints.
- Standardized token‑based speech transport in VoIP and conferencing
- What: Use semantic/acoustic token streams as an interoperable low‑bitrate layer for telephony or RTC systems.
- Why future: Requires standards bodies buy‑in, error‑correction, encryption, and compatibility across vendors.
- Dependencies: Open codec specs, IETF/3GPP standardization, royalty/licensing model, resilience to network jitter.
- Safety, consent, and provenance infrastructure for voice cloning
- What: Organization‑wide frameworks to manage consented voices, detect synthetic audio, and watermark/prove provenance.
- Why future: Paper focuses on generation quality and serving; operational safeguards and legal standards require cross‑industry alignment.
- Dependencies: Watermarking/signature schemes for audio, detection benchmarks, consent management APIs, regulatory guidance.
- Healthcare | Advanced personalized voice prosthetics and therapy
- What: Real‑time AAC devices that reproduce a patient’s voice with nuanced expressivity in noisy, mobile environments.
- Why future: Demands on‑device low‑latency, robustness to context/noise, clinical integration, and regulated workflows.
- Dependencies: Edge deployment; validated clinical studies; safety/efficacy evidence; reimbursement frameworks.
- Customer Experience | Empathetic conversational agents with reliable emotion control
- What: Agents that adapt tone/emotion to customer state with fine‑grained, consistent control and guardrails.
- Why future: Needs explicit controllability, emotion detection links, and policy/ethics tooling to avoid manipulation.
- Dependencies: Emotion classifiers; human‑in‑the‑loop; DPO/RLHF on emotion labels; compliance frameworks.
- Academic Research | Generalizing hybrid discrete‑continuous generation
- What: Transfer the AR‑semantic + flow‑acoustic approach to music, environmental audio, or multimodal speech‑gesture synthesis.
- Why future: Requires domain‑specific tokenizers, training data, and evaluation protocols.
- Dependencies: New datasets/codecs; modality‑specific losses; community benchmarks and shared tasks.
- Evaluation Policy | Procurement and benchmarking standards for TTS
- What: Codify combined human+automatic evaluation (WER, speaker similarity, UTMOS, preference tests) for public procurement or academic challenges.
- Why future: Needs consensus standards and multilingual panels; reproducible protocols; bias and accessibility audits.
- Dependencies: Cross‑institution committees; multilingual rater pools; open evaluation suites; governance.
Cross‑cutting Assumptions and Dependencies
- Licensing: The released weights are CC BY‑NC; commercial deployments require a separate license or alternative models.
- Hardware: Reported latency/throughput assume modern GPUs (e.g., NVIDIA H200). CPU/on‑device support will need model compression and engineering.
- Language coverage: Current support is 9 languages; broader deployment requires additional training and evaluations.
- Prompting: Best quality arises from 3–25 s high‑quality voice prompts. Emotion control is primarily via prompt selection (implicit), not explicit tags.
- Safety and ethics: Voice cloning requires robust consent, disclosure, and anti‑abuse measures irrespective of sector.
- Serving stack: Low latency depends on vLLM‑Omni’s two‑stage streaming, CUDA graphs for FM integration, and chunked token streaming. Integration effort is non‑trivial for new environments.
Glossary
- Adaptive LayerNorm (AdaLN): A conditioning technique that modulates layer normalization parameters based on external inputs, often used in diffusion/DiT-style models. "DiT style adaptive LayerNorm (AdaLN) layers~\citep{dit}"
- ALiBi positional bias: A method for biasing attention scores to improve extrapolation to longer input lengths without learned positional embeddings. "ALiBi positional bias~\citep{press2021train}"
- ASR distillation loss: An auxiliary training objective that transfers knowledge from an automatic speech recognition model to guide representation learning. "we adopt an auxiliary ASR distillation loss."
- Asynchronous chunked streaming: A serving approach that emits and consumes chunks of tokens with overlap across stages to enable low-latency streaming. "an asynchronous chunked streaming protocol is introduced."
- Auto-regressive (AR) modeling: Generating each token conditioned on previously generated tokens in sequence. "the decoder backbone auto-regressively generates semantic token outputs."
- Classifier-free guidance (CFG): A technique that interpolates between conditional and unconditional model predictions to control generation strength. "classifier-free guidance (CFG)~\citep{cfg}"
- Cosine distance loss: A loss based on cosine similarity used to align representations by minimizing angular distance. "using a cosine distance loss:"
- Cross-attention weights: Attention weights from a decoder attending to encoder representations, often used for alignment. "decoder hidden states and cross-attention weights."
- CUDA graphs: A CUDA feature that captures and replays GPU operation graphs to reduce kernel launch overhead. "the entire ODE solver is captured into CUDA graphs."
- Depth Transformer: A transformer that autoregresses across codec depth (levels/codebooks) rather than time. "Depth Transformer \citep{defossez2024moshi}"
- Dither-style FSQ: A training trick adding small uniform noise during finite scalar quantization to stabilize learning. "we apply dither-style FSQ~\citep{parker2024scaling}"
- Direct Preference Optimization (DPO): A post-training method that directly optimizes model outputs using preference comparisons (winner/loser pairs). "We use Direct Preference Optimization (DPO)~\citep{dpo} to post-train the model"
- Dynamic Time Warping (DTW): An algorithm for aligning sequences with varying speeds, used here for aligning speech frames to tokens. "via dynamic time warping (DTW)~\citep{berndt1994dtw}"
- ECAPA-TDNN: A neural architecture for extracting speaker embeddings used to assess speaker similarity. "ECAPA-TDNN model~\citep{ecapa}"
- End of Audio token (<EOA>): A special token indicating the end of generated audio in the token sequence. "a special End of Audio token (<EOA>)."
- Euler method: A first-order numerical method for integrating ordinary differential equations in generative flows. "we use the Euler method to integrate the velocity vector field"
- Extended Short-Time Objective Intelligibility (ESTOI): An objective metric estimating speech intelligibility from time–frequency representations. "extended short-time objective intelligibility (ESTOI)"
- Feature-matching loss: A GAN-related loss that matches intermediate discriminator features between real and reconstructed data. "An -based feature-matching loss is computed"
- Finite Scalar Quantization (FSQ): Quantizing each scalar dimension to a finite set of uniformly spaced levels. "finite scalar quantization (FSQ;~\citep{fsq})"
- Flow matching: A generative modeling approach that learns a velocity field to transport noise to data; used here for acoustic tokens. "a lightweight flow-matching model predicts the acoustic tokens"
- Function evaluations (NFEs): The number of velocity field evaluations used when integrating an ODE in flow-based generation. "using 8 function evaluations (NFEs)"
- LayerScale: A stabilization technique that scales residual branches in transformers with learnable factors. "LayerScale~\citep{touvron2021going} initialized at 0.01."
- MaskGIT: A non-autoregressive masked generative transformer that iteratively fills in tokens. "MaskGIT \citep{maskgit}"
- Multi-resolution discriminator: A GAN discriminator ensemble operating at multiple spectral resolutions to improve audio fidelity. "A multi-resolution discriminator with 8 STFT sizes (2296, 1418, 876, 542, 334, 206, 126, 76)"
- Patchified waveforms: Representing raw audio as fixed-size patches for transformer-based tokenization. "our audio tokenizer operates on ``patchified'' waveforms."
- Perceptual Evaluation of Speech Quality (PESQ): A standardized objective metric for perceived speech quality. "perceptual evaluation of speech quality (PESQ)"
- QK-norm: Normalization applied to the query/key vectors in attention to stabilize training. "QK-norm, and LayerScale~\citep{touvron2021going}"
- Real-time factor (RTF): The ratio of processing time to audio duration; values <1 indicate faster-than-real-time synthesis. "real-time factor (RTF)"
- Residual Vector Quantization (RVQ): A quantization approach using multiple sequential codebooks to encode residuals. "Mimi uses an RVQ design for acoustic codebooks"
- Short-Time Fourier Transform (STFT): A time–frequency transform used for spectral losses and discriminator inputs in audio models. "STFT magnitudes"
- Sliding window attention: Attention constrained to a local window to reduce complexity and enable streaming. "sliding window attention (window sizes "
- Stop-gradient operator: An operation that prevents gradients from flowing through a tensor during backpropagation. "where denotes the stop-gradient operator."
- UTMOS-v2: A neural predictor of mean opinion score (MOS) for speech, used as an automated quality metric. "UTMOS-v2~\citep{utmos}"
- Vector Quantization (VQ): Mapping continuous vectors to discrete codebook entries to create tokens. "learned vector quantizer (VQ;~\citep{van2017neural})"
- VQ commitment loss: A penalty encouraging encoder outputs to commit to selected codebook vectors in VQ. " is the VQ commitment loss~\citep{van2017neural}"
- Voice Activity Detection (VAD): Automatically determining which frames contain speech versus silence. "as determined by a voice-activity-detection (VAD) model"
Collections
Sign up for free to add this paper to one or more collections.

