- The paper presents a full-stream, zero-shot TTS system that achieves ultra-low first-packet latency of 102 ms.
- It utilizes an autoregressive architecture with incremental phoneme, temporal, and depth transformers to efficiently align text to audio tokens.
- Experimental results show that VoXtream delivers competitive quality and speaker similarity while running over 5× faster than real time.
VoXtream: A Full-Stream, Zero-Shot, Ultra-Low Latency Text-to-Speech System
Introduction
VoXtream introduces a fully autoregressive, zero-shot streaming text-to-speech (TTS) architecture designed for real-time applications requiring minimal first-packet latency. The system directly maps incoming phoneme streams to audio tokens using a monotonic alignment scheme and dynamic look-ahead, enabling speech synthesis to commence immediately after the first word is received. VoXtream is constructed from three core transformer modules—an incremental Phoneme Transformer, a Temporal Transformer, and a Depth Transformer—integrated to achieve both high-quality and low-latency synthesis. The model demonstrates competitive or superior performance to larger-scale baselines, despite being trained on a mid-scale 9k-hour corpus, and achieves a first-packet latency of 102 ms on GPU, which is the lowest reported among publicly available streaming TTS systems.
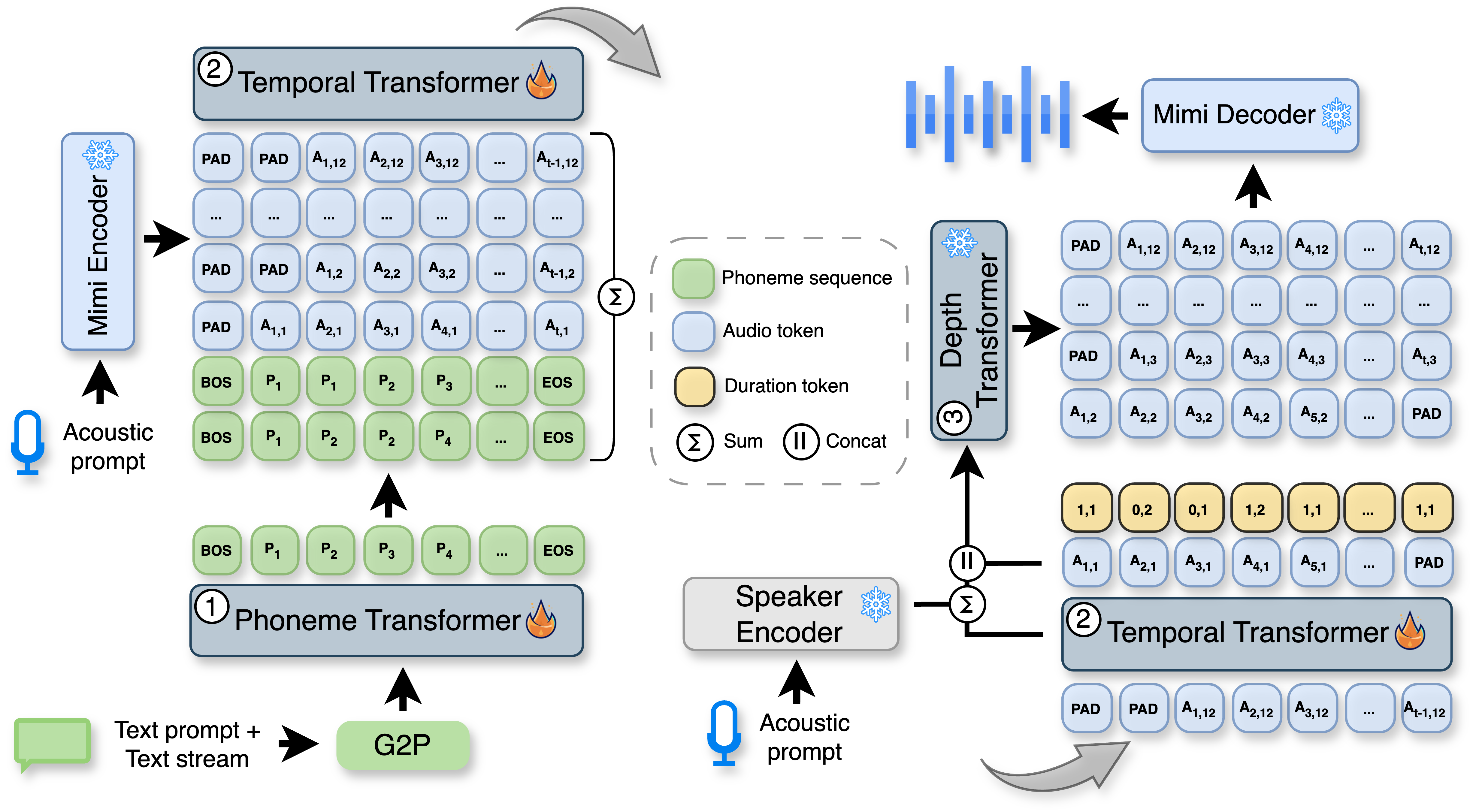
Figure 1: Overview of VoXtream, comprising an incremental Phoneme Transformer and Temporal and Depth Transformers.
Architecture and Methodology
The Phoneme Transformer (PT) is a decoder-only transformer that processes phoneme sequences incrementally. Each phoneme is embedded and the input grows as new words arrive in the text stream. The PT supports dynamic look-ahead (LA) up to 10 phonemes, but crucially, it does not require waiting for the LA window to fill before generating speech tokens. This enables immediate synthesis after the first word, minimizing input-side latency. Phoneme conversion is performed at the word level using g2pE.
The Temporal Transformer (TT) is an autoregressive module conditioned on both the audio tokens and the phoneme sequence. Audio tokens are extracted using the Mimi codec at 12.5 Hz, with up to two phonemes assigned per audio frame. Alignment is achieved via the Montreal Forced Aligner, and a one-step acoustic delay is introduced for stability. The TT predicts both semantic tokens (first codebook of Mimi) and duration tokens, the latter encoding a shift flag (stay/go) and the number of phonemes (1 or 2) per frame. This joint prediction is performed by a single classification head, and tokens are sampled from the joint distribution.
The Depth Transformer (DT) is conditioned on the TT output and semantic tokens, generating the remaining acoustic tokens (codebooks 2–12 of Mimi). The DT is also conditioned on a speaker embedding from ReDimNet, supporting zero-shot speaker adaptation. The DT is initialized from a pre-trained CSM model and kept frozen during VoXtream training, leveraging knowledge transfer for improved quality and speaker similarity.
Streaming Synthesis Pipeline
The Mimi decoder reconstructs 80 ms of speech per frame from the semantic and acoustic tokens, enabling streaming output. Training minimizes the negative log-likelihood of TT and DT outputs. The architecture is optimized for both latency and quality, with all modules implemented as Llama-style transformers.
Experimental Setup
Data and Training
VoXtream is trained on a 9k-hour English corpus, combining the Emilia and HiFiTTS-2 datasets, with additional filtering for diarization, transcript validity, and quality (NISQA). Phoneme alignments are obtained with MFA, and speech tokenization uses the Mimi codec at 24 kHz. The TT has 12 layers and 16 heads; the PT and DT have 6/4 layers and 8 heads, respectively. Training is performed on two NVIDIA A100-80GB GPUs with a batch size of 128 per GPU for 9 epochs, using AdamW with a peak learning rate of 5×10−4.
Baselines
Comparisons are made against both large-scale and mid-scale AR and NAR TTS models, including CosyVoice, Spark-TTS, Llasa, VoiceStar, VoiceCraft, XTTS, CosyVoice2, and FireRedTTS-1S. Streaming baselines include XTTS and CosyVoice2, with evaluation in both output-streaming and full-streaming modes.
Evaluation Metrics
Objective metrics include WER (Whisper-large-v3 and HuBERT-based ASR), speaker similarity (SPK-SIM, cosine similarity of ECAPA-TDNN embeddings), and UTMOS (MOS predictor). Subjective evaluation is conducted via MUSHRA-style naturalness ratings and preference tests on Prolific, with careful control for WER and attention checks.
Latency is measured as first-packet latency (FPL) and real-time factor (RTF), with all models evaluated in FP16 on A100 GPUs.
Results
Quality and Latency
VoXtream achieves the best SPK-SIM and UTMOS among mid-scale models and is competitive in WER. The streaming variant introduces only minor degradations relative to the non-streaming version. In short-form streaming, VoXtream outperforms XTTS and is second only to CosyVoice2 in output streaming. In full-stream mode, VoXtream delivers lower WER than CosyVoice2 on long-form LibriSpeech, with subjective naturalness preference significantly favoring VoXtream (p<5×10−10).
VoXtream achieves a first-packet latency of 102 ms with torch.compile, outperforming all baselines. The real-time factor is 0.17, indicating more than 5× faster-than-real-time synthesis. This is achieved without specialized acceleration, and the system runs in real time on commodity GPUs.
Ablation Study
Ablation experiments demonstrate that the use of a frozen, pre-trained CSM-DT and ReDimNet speaker encoder significantly improves quality and speaker similarity. The baseline (no foundation models) achieves the best WER, but the final system's slight WER increase is not statistically significant, and the gains in SPK-SIM and UTMOS are substantial.
Discussion
VoXtream's architecture demonstrates that full-stream, zero-shot TTS with ultra-low latency is achievable without large-scale training data or complex multi-stage pipelines. The integration of dynamic phoneme look-ahead, monotonic alignment, and foundation model components enables immediate synthesis with minimal context, addressing both input- and output-side latency. The system's performance is robust across both short- and long-form streaming scenarios, and subjective evaluations confirm its competitiveness with larger, non-streaming models.
The use of pre-trained modules (CSM-DT, ReDimNet) is validated as an effective strategy for knowledge transfer, improving speaker similarity and synthesis quality in zero-shot settings. The architecture is modular and amenable to further scaling and adaptation.
Implications and Future Directions
Practically, VoXtream enables real-time, interactive TTS applications such as voice assistants, live translation, and conversational AI, where minimal latency is critical. The system's ability to begin synthesis after the first word and maintain high quality throughout streaming input is a significant advancement for user experience in these domains.
Theoretically, VoXtream demonstrates that autoregressive, monotonic alignment with dynamic look-ahead can match or exceed the performance of more complex or data-intensive approaches. The results suggest that further scaling of training data, explicit control over prosody and speaking rate, and improved long-form streaming capabilities are promising directions for future research.
Conclusion
VoXtream establishes a new state-of-the-art for streaming, zero-shot TTS with extremely low latency. Its unified, autoregressive architecture, foundation model integration, and efficient streaming pipeline enable immediate, high-quality speech synthesis from text streams. The system's strong empirical results and low resource requirements position it as a practical solution for real-time speech generation, with clear avenues for further enhancement and scaling.