- The paper introduces a novel block-diffusion TTS architecture that uses prior-calibrated scoring to counteract silent token bias in streaming synthesis.
- It leverages an early-decoding schedule to unmask token positions in parallel, cutting denoising steps by up to 41% while maintaining quality.
- Extensive evaluation shows near-parity with state-of-the-art metrics and substantial throughput improvements compared to AR and NAR baselines.
Chatterbox-Flash: Prior-Calibrated Block Diffusion for Streaming Zero-Shot TTS
Introduction and Motivation
Chatterbox-Flash introduces a novel zero-shot text-to-speech (TTS) architecture that synthesizes speech in arbitrarily unseen voices, while addressing the significant bottleneck of inference latency in traditional autoregressive (AR) and non-autoregressive (NAR) models. The primary innovation centers on the integration of block-diffusion decoding into a pretrained AR backbone, enabling parallel token generation within each block and retaining block-by-block streaming capabilities. The work critically observes that direct transfer of diffusion LLMs (DLMs) to discrete speech tokens is nontrivial: speech token distributions are heavily skewed, with long-tail effects that bias decoding toward silence or other high-frequency events, leading to quality degradation.
To counteract these issues and maintain streaming efficiency, Chatterbox-Flash introduces two inference-time techniques—prior-calibrated scoring and an early-decoding schedule—which refine position selection and adaptive termination, respectively. This architecture configuration achieves near-parity with state-of-the-art baselines in objective and subjective quality metrics while supporting aggressive latency reduction.
Model Architecture and Block Diffusion
The core model architecture builds upon Chatterbox-TTS, a two-stage system consisting of a Llama-style Transformer decoder responsible for next-token prediction over discrete speech tokens, followed by a flow-matching vocoder for waveform generation. The contribution lies in adapting this AR architecture into a block-based diffusion paradigm by fine-tuning with masked denoising over blocks.
Each speech token sequence is partitioned into equally sized blocks, and at inference time, blocks are decoded sequentially but with all positions within a block generated in parallel. The hybrid attention scheme maintains causal attention over conditioning inputs, bidirectional attention within each block, and causal attention across blocks. This design ensures compatibility with streaming deployment and preserves the monotonic text-to-speech alignment crucial for high-quality synthesis.
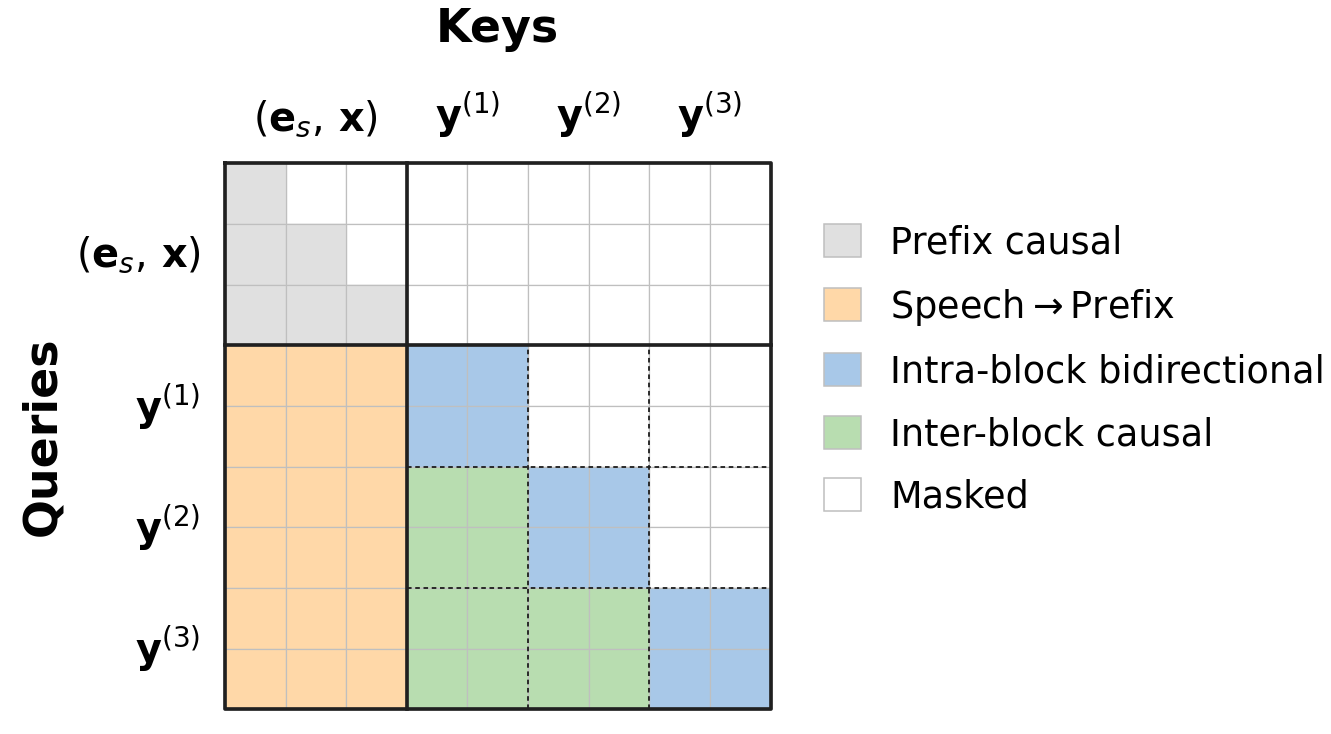
Figure 1: Hybrid block attention mask at D=2; query positions in each speech block can attend bidirectionally within their block, causally to prior blocks, and fully to the conditioning prefix.
Inference: Prior-Calibrated Scoring and Early Decoding
A key obstacle for blockwise parallel decoding in discrete speech is marginal token bias—the dominance of high-frequency tokens (notably silence), which can disrupt prosodic and acoustic continuity when committed prematurely. To mitigate this, Chatterbox-Flash adopts a prior-calibrated scoring mechanism. Each candidate token's commitment score is computed as the difference between its contextual log-probability and its unconditional block-level marginal log-probability (PMI). This effectively discounts the influence of dominant, context-independent tokens and re-ranks positions for unmasking based on genuine contextual evidence, not just frequency bias.
In tandem, an early-decoding schedule adapts the number of positions unmasked per step by leveraging the calibrated scores: masked positions exceeding an adaptive quantile threshold are unmasked, and the threshold decays as the decoding proceeds. This combination allows the model to terminate the iterative denoising steps for a block substantially before reaching the maximum budgeted steps when confidence is high, thus reducing inference latency.
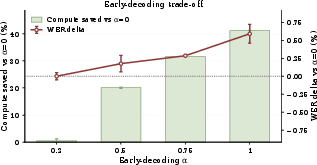
Figure 2: Early-decoding trade-off showing number of steps saved (bars) and WER change (line) relative to baseline; up to 41% step reduction with only marginal WER increase.
Experimental Results
Objective Evaluation
Chatterbox-Flash is comprehensively evaluated on LibriSpeech-PC and Seed-TTS test-en zero-shot TTS benchmarks. Under a canonical configuration (D=16, K=8), it achieves:
- SIM-o: 0.717 (LibriSpeech-PC), 0.704 (Seed-TTS); higher than its AR backbone and competitive with NAR baselines.
- WER: 1.67 (LibriSpeech-PC), 1.96 (Seed-TTS); significantly improved over direct AR decoding and close to best-in-class NAR approaches.
- UTMOS: 4.29 (LibriSpeech-PC), 4.09 (Seed-TTS).
The results confirm that block-diffusion decoding with prior calibration does not just match, but can improve upon AR baselines in perceptual similarity and intelligibility, while operating with substantially fewer denoising steps.
Latency and Real-Time Streaming
Streaming efficiency experiments reveal rapid synthesis rates: time-to-first-packet (TTFP) of 118 ms and a real-time factor (RTF) of 0.107—outperforming strong AR streaming systems like Qwen3-TTS on throughput by 2.4× to 3.8× at comparable block sizes and conditions. As block size and early decoding become more aggressive, the RTF drops further (down to 0.076), corresponding to roughly 13× real-time synthesis even on a single concurrent request.
Human Evaluation
Side-by-side listening tests against ElevenLabs v3 demonstrate that Chatterbox-Flash achieves comparable mean naturalness (NMOS) and outperforms in speaker similarity (SMOS).
Ablation Studies
Ablations on block size reveal that quality remains stable for D≤16, but sharp WER degradation occurs beyond D=24—indicating that speech token parallel-unmasking remains challenging for overly large blocks despite recalibrated inference. Ablations on denoising steps (K) show that quality saturates by K=6, supporting aggressive early termination.
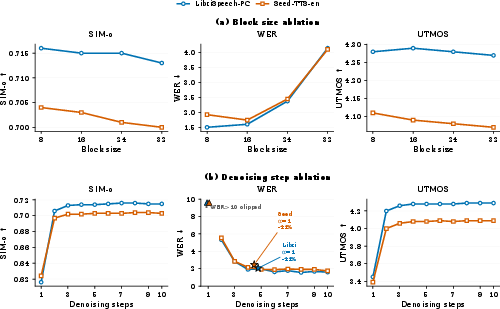
Figure 3: Inference-time ablations, showing the effect of block size and step budget on quality metrics on both benchmarks.
Exploration of temperature scaling, position sampling, and guidance scale further confirm that the major quality/computation trade-off is governed by block size, denoising steps, and the early-decoding parameter—while the choice between TS schedule and PMI decoding is secondary except on challenging or out-of-distribution utterances.
Discussion and Theoretical Implications
Chatterbox-Flash demonstrates the feasibility of block-diffusion architectures for discrete, highly-structured domains like speech, provided that inference is equipped with strong marginal bias correction and per-position confidence calibration. The presented prior-calibrated scoring can be understood as a practical instance of PMI-based selection for structured denoising, which may have implications beyond TTS for other token generation tasks dominated by long-tail distributions.
On saturated benchmarks, the early-decoding schedule leverages the flatness of the performance plateau to offer aggressive compute savings, and in harder prosodic/expressive tasks, prior calibration yields direct improvements in intelligibility that conventional schedules miss. Notably, the approach achieves streaming synthesis natively—a regime where most full-sequence diffusion architectures falter or must fall back on ad hoc chunking.
There remain, however, open research problems: scaling block size while retaining prosodic coherence, and the integration of confidence-driven inference with training objectives, to better support extreme parallel decoding.
Conclusion
Chatterbox-Flash establishes block-diffusion with prior calibration as a competitive and efficient approach for streaming zero-shot TTS on discrete codec tokens. Its combination of parallel blockwise decoding, marginal-bias correction via PMI, and adaptive early unmasking achieves quality on par with or better than both AR and NAR baselines, with substantive improvements in latency and throughput. These properties position the method as a compelling solution for production-grade, real-time zero-shot TTS and motivate future work into deeper integration of calibration-aware scheduling and blockwise parallelism in speech generation.

