MilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
Abstract: Video generative models have become increasingly powerful, but long-range consistency remains challenging to achieve because even a few dozen frames require impractically long transformer sequence lengths. We show that this issue can be mitigated by generating video using coarse-to-fine rollout within a multi-scale token space. Our approach is simple: first, we pre-train an autoencoder that compresses each frame into a hierarchy of tokens, with levels ranging from the typical latent resolution to only a handful of tokens per frame. The coarsest levels capture the most consequential information, such as scene layout and semantics, while finer levels add high-frequency appearance and texture. Then, we train a video diffusion model to generate these tokens using coarse-to-fine rollout. By carefully controlling the level of detail at which frames are generated and used as context during each rollout step, we are able to preserve long-range consistency in geometry and object permanence while spending less compute on the long-range consistency of less perceptually relevant details. We validate this approach using a custom dataset of long Minecraft videos, where it produces substantially more consistent rollouts compared to existing baselines.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MilliVid: Making long videos that stay consistent
1) Big idea: what is this paper about?
This paper introduces a way to make AI-generated videos that stay consistent for a long time. “Consistent” means the world doesn’t randomly change: buildings don’t move, objects don’t vanish when they leave and re-enter the camera view, and the scene layout remains the same across hundreds of frames. The method is called MilliVid. It makes videos by first planning the big picture and then adding details, so the important parts are remembered even far into the future.
2) What questions were the researchers trying to answer?
They focused on three simple questions:
- How can we make long videos that don’t forget important things, without needing a supercomputer?
- Can we give the model a “smart memory” that keeps the big, important stuff (like where buildings and roads are) for a long time, and only add fine details (like textures) later?
- Is it better to learn a multi-level “summary” of each frame (a hierarchy) instead of just shrinking images the usual way?
3) How does the method work?
Think of making a drawing: you sketch the rough shapes first (where things are), then you add shading and textures. MilliVid does the same with video.
There are two main parts:
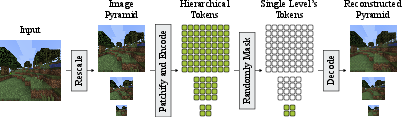
- A hierarchical autoencoder (the “smart compressor”)
- A video generator that works from coarse to fine (the “planner and painter”)
Here’s what those mean in everyday language:
- Autoencoder: A tool that learns to squeeze an image into a smaller form (encode) and then rebuild it (decode). If it’s good, the rebuild looks like the original.
- Tokens: Tiny pieces of information—like Lego bricks—that represent parts of a frame.
- Hierarchy: Several levels of tokens per frame, from coarse (very few tokens that capture the big picture) to fine (many tokens that capture tiny details).
- Transformer and diffusion model: Popular AI building blocks. You can think of diffusion as “starting from noisy fuzz and step-by-step denoising it into a clear image/video,” guided by a transformer (a powerful pattern finder).
What the autoencoder does:
- For every frame, it creates multiple levels:
- Coarse levels: just a handful of tokens that capture the scene layout and main objects.
- Fine levels: many tokens that add crisp textures and tiny details.
- Each level can be decoded on its own. Coarse levels give a clean, simple version; fine levels make it sharp and detailed.
- Importantly, these levels are learned (not just blurry downscaled images), so the coarse version still preserves meaningful structure.
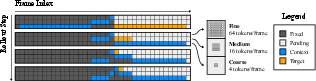
What the video generator does:
- It has a limited “attention span” (a fixed token budget). It can’t look at everything at once, especially for long videos.
- So it uses a coarse-to-fine rollout: 1) First, generate many future frames at the coarse level (cheap, because there are few tokens per frame). This keeps the big picture consistent far ahead. 2) Then, add medium details to a shorter range. 3) Finally, add fine details to the most recent frames.
- Crucially, when adding details, the model always sees:
- the latest high-detail frame (recent truth),
- plus future frames at coarse levels (long-term plan).
- This avoids contradictions, like guessing different text on a sign when zooming in later.
Training trick:
- They train the model on many “slices” of this rollout schedule so it learns to handle both near-term fine detail and far-term coarse consistency. They also train it to predict farther into the future so it actually uses the distant coarse memory, not just the most recent frames.
A quick analogy:
- Imagine making a flipbook:
- First, you sketch the stick-figure story for many pages (coarse plan).
- Next, you add clothing and hair to the last few pages (medium detail).
- Finally, you add shading and texture to the very last page (fine detail).
- Because each step knows both what just happened in detail and what’s coming (as a sketch), the story stays consistent.
Data used:
- They built a special dataset called Loopcraft: long Minecraft videos (1024 frames each) at 256×256 resolution, with 200,000 examples.
- Minecraft is great for testing consistency because the camera often leaves an area and later returns. If the model remembers the world, it should regenerate the same place correctly.
4) What did they find, and why is it important?
Main results:
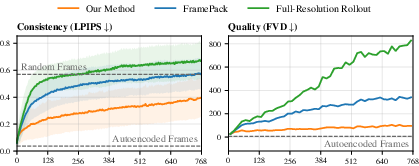
- MilliVid produced long videos that stayed consistent much better than strong baselines:
- FramePack (a state-of-the-art method that shrinks past frames to fit more context).
- Standard autoregressive rollout (generate a few frames at a time using only recent context).
- It recalled scene structure and objects over hundreds of frames, even when objects left the camera and returned later.
- It kept image quality competitive while greatly improving long-range consistency.
Simple evidence summary:
- On Loopcraft, MilliVid’s videos matched the ground-truth future much more closely over long time spans.
- Quality metrics (how sharp or pleasant frames look) were similar or better, while consistency metrics (do scenes match the correct world later on?) improved a lot.
Why the approach works:
- Learned hierarchical tokens beat simple downscaling: the coarse levels keep structure, not just blur.
- Making the model predict farther into the future pushes it to use long-range memory, not just the last frame.
- The careful “context mix” (latest fine frame + future coarse frames) prevents conflicts when zooming in later.
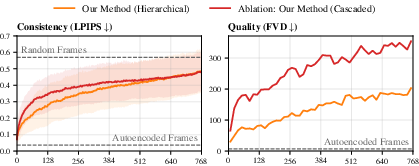
Ablation (what if we change parts?):
- Replacing the learned hierarchy with simple downscaled versions (a “cascaded” setup) made results worse in both consistency and quality.
- Variants of FramePack using the hierarchy or cascaded versions didn’t catch up.
- A “mirrored” FramePack that predicted farther into the future improved some consistency, supporting the idea that long-horizon prediction matters—but it still fell short of MilliVid.
5) Why does this matter? What could this change?
If AI can make long, consistent videos, it helps:
- Storytelling and animation: Characters and scenes stay stable across long sequences.
- Robotics and simulation: A robot’s “world model” video can keep track of places and objects over time.
- Games and virtual worlds: Persistent environments feel real when revisited.
- Research on “world models”: Better memory of the big picture without huge compute costs.
Limitations and future directions:
- MilliVid uses a custom hierarchical autoencoder, so directly fine-tuning giant pre-trained video models isn’t plug-and-play yet.
- It needs a few more rollout steps than some baselines (slower sampling), but the consistency gains are large.
- It could be combined with retrieval methods (bringing back key past frames) for even longer memories.
In short: MilliVid shows that planning the big picture first—and carefully adding details later—lets an AI remember the world over long videos while keeping compute manageable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, aimed to guide future research.
- Generalization beyond synthetic Minecraft: Validate MilliVid on diverse, real-world video domains (e.g., human-centric, dynamic scenes, fast motion, fine textures) to test whether long-range consistency holds under complex appearance changes, lighting, and occlusions.
- Broader conditioning modalities: Assess performance under text-to-video, image-to-video, audio-conditioned, and pose-conditioned generation; quantify if the hierarchical rollout maintains semantic alignment with high-level prompts, not just simple action controls.
- Closed-loop generation and planning: Test without ground-truth actions (i.e., the model predicts actions or trajectory itself), measuring how the hierarchy affects compounding errors, drift, and long-term consistency in agent-driven or open-ended rollouts.
- Integration with retrieval mechanisms: Implement and evaluate retrieval-augmented versions of MilliVid (as suggested in Related Work), especially for content far beyond the coarsest-level temporal window, and quantify benefits vs. hierarchy-only approaches.
- Combination with 3D memory or geometry: Explore integrating explicit 3D scene representations (points, voxels, NeRFs) or camera pose for persistent memory; measure improvements in off-screen recall, occlusion handling, and geometric consistency with and without 3D priors.
- Adaptive token allocation across time and content: Replace fixed per-level rollout schedules with learned or dynamic policies (e.g., RL or bandit-based allocation) that adapt token budgets over time based on scene complexity, uncertainty, or task relevance.
- Cross-level decoding strategies: Investigate decoders that jointly consume multi-level tokens (rather than single-level decoding) to combine coarse structure and fine detail more effectively, and quantify effects on artifacts, texture fidelity, and robustness.
- Spatiotemporal tokenization: Extend beyond per-frame tokenization to hierarchical spatiotemporal tokens; compare whether modeling temporal structure at the encoding stage improves memory and reduces forgetting vs. frame-only latent hierarchies.
- Discrete vs. continuous latents and rate–distortion: Study discrete, entropy-coded tokenizers (e.g., VQ/VAE-like) and rate–distortion objectives to quantify actual compression gains (bits per frame) and their impact on long-range consistency and sampling cost.
- Scheduling and theoretical guarantees: Provide formal analysis of the coarse-to-fine context scheduling (e.g., when future-coarse and recent-fine frames suffice to avoid “stop/go” contradictions), and characterize failure modes under different uncertainty profiles.
- Expanded baselines and fair comparisons: Compare against more long-context baselines (e.g., TECO, FAR, retrieval-based methods, cascaded video diffusion pipelines), under matched token budgets and context horizons, to isolate where hierarchy confers unique advantages.
- Human evaluations for consistency vs. quality: Add user studies explicitly measuring perceived long-range consistency and acceptability of fine-detail drift; calibrate objective metrics (LPIPS, DINOv2, LightGlue, SSIM, PSNR, FVD/FID) against human judgments.
- Domain-specific consistency metrics: Develop metrics for object permanence, identity tracking, semantic recall, and 3D consistency (e.g., camera-pose-aware measures, trajectory overlap robustness) that are less sensitive to small misalignments than pixel metrics.
- Robustness to occlusions and off-screen recall: Create controlled benchmarks for objects leaving and re-entering the frame, varying occlusion duration and motion complexity, to stress-test hierarchical memory and quantify recall under adversarial sequences.
- Efficiency and scalability analysis: Provide detailed compute benchmarks (training/inference wall-clock, GPU memory, energy) across sequence lengths and hierarchy depths; optimize sampling to reduce the reported ~33% rollout overhead without losing consistency.
- Hyperparameter sensitivity and ablations: Systematically vary number of levels, per-level token counts, patch sizes, positional encodings, and loss functions (e.g., perceptual, adversarial, temporal consistency losses) to map performance–compute trade-offs.
- Fine-tuning from large pre-trained video models: Operationalize the proposed distillation path (aligning finest hierarchical latents to existing autoencoders) and empirically evaluate transfer from WAN, Hunyuan Video, etc., including stability and data requirements.
- Control over consistency–detail trade-off: Expose user-controllable knobs or automatic policies to prioritize long-range memory vs. fine texture fidelity per task, scene, or prompt; evaluate downstream task impacts where fine details are crucial (e.g., reading text).
- Long-horizon limits and failure characterization: Quantify how far into the future consistency holds at each level (e.g., >1k frames), identify failure cases (scene layout drift, identity swaps, texture flicker), and correlate breakdowns with token budget and motion.
- Streaming and real-time generation: Study latency and memory for online generation, including chunked decoding, key-frame hierarchies, and incremental updates; benchmark end-to-end throughput on commodity hardware.
- Safety and robustness: Examine adversarial or corrupt context frames, out-of-distribution prompts, and failure recovery mechanisms; explore guardrails to prevent the hierarchy from amplifying subtle inconsistencies over long rollouts.
- Dataset diversity and biases: Evaluate whether Loopcraft’s turn-biased trajectories overrepresent revisits (making recall easier); build alternative long-horizon datasets with varied motion patterns, fewer revisits, and richer semantics to avoid overfitting to the collection protocol.
Practical Applications
Immediate Applications
The following applications can be built now by adapting the paper’s released components (hierarchical tokenizer, coarse-to-fine rollout, training/sampling recipes) and by leveraging the demonstrated gains in long-range consistency without retrieval or explicit 3D memory.
- Long, coherent previsualization and animatics for film/TV and advertising
- Sectors: media/VFX, advertising, software tools
- What: Quickly generate multi-minute previz shots that preserve scene layout, character placement, and continuity across cuts and camera moves. Use coarse rollout for blocking and refine selectively with fine levels for hero shots.
- Tools/workflows: DCC plugins (e.g., Blender/Unreal) that expose “token budget sliders” to trade detail for temporal horizon; a “coarse-to-fine scheduler” node for video diffusion pipelines; batch previz generation with action/pose scripts.
- Assumptions/dependencies: Domain transfer from Minecraft-like training to real footage requires re-training on appropriate datasets; integration into existing diffusion backbones may need distillation to hierarchical latents; additional rollout steps (+~33%) must be budgeted.
- Game content previz and world continuity testing
- Sectors: gaming, simulation, QA
- What: Generate long, coherent camera flythroughs and NPC view simulations to test level continuity, object permanence, and landmark re-entry (e.g., open-world regressions).
- Tools/workflows: “Continuity bots” that traverse maps using scripted actions and produce long-range generative rollouts; automatic diff against ground-truth runs to flag layout inconsistencies.
- Assumptions/dependencies: Action/pose-conditioned inputs improve reliability (as in Loopcraft); retraining on in-engine captures recommended.
- Benchmarking and academic evaluation of long-range video consistency
- Sectors: academia, standards/benchmarking
- What: Use the Loopcraft protocol and metrics to evaluate forgetting/drift in new models; adopt LPIPS/DINOv2/LightGlue-based consistency dashboards alongside FVD/FID for quality.
- Tools/workflows: Public “long-context suite” with scripts that control context windows, rollout schedules, and report consistency vs. rollout length curves.
- Assumptions/dependencies: Access to the dataset generation pipeline or similar long, action-conditioned video corpora; metric robustness checks for minor trajectory drift.
- Robotics simulation rollouts with improved scene memory (research)
- Sectors: robotics, simulation, world modeling
- What: In simulated environments, generate long video predictions that preserve landmarks after they leave/re-enter view—useful for visual planning and model-based RL debugging.
- Tools/workflows: World-model training harnesses that plug in MilliVid’s tokenizer and sampler; ablations with/without retrieval or 3D memory to study complementary effects.
- Assumptions/dependencies: Real-world deployment will require domain adaptation and real sensory/action streams; evaluation must control for compounding dynamics errors.
- Video design assistants for education and training materials
- Sectors: education, instructional design, software
- What: Create long, consistent explanatory videos (e.g., lab walkthroughs, process flows) where background settings and objects remain stable across minutes.
- Tools/workflows: Authoring tools with “structure-first rollout” (coarse sequence for layout approval) followed by targeted refinement of fine details where learners focus.
- Assumptions/dependencies: Need curated training data for the target visual domain; human-in-the-loop approval to mitigate hallucinations.
- Scalable synthetic dataset generation for vision tasks requiring persistence
- Sectors: CV/ML, autonomy R&D
- What: Generate long synthetic videos with consistent landmarks and scene geometry for pretraining models on tracking, re-identification, and visual localization.
- Tools/workflows: Data generators that iterate: coarse rollout for long coverage → select spans → fine-level refinement only where annotations are required.
- Assumptions/dependencies: Annotation pipelines must accept hierarchical decoding; simulation domain bias must be addressed for downstream tasks.
- Efficient token budgeting in video diffusion serving
- Sectors: AI platforms, MLOps
- What: Serve long-form video generation on constrained GPUs by allocating tokens preferentially to long-horizon coarse frames and fewer fine-detail frames.
- Tools/workflows: Inference “token-budget controller” that exposes S (sequence-length) budgeting as a runtime knob; monitoring for consistency metrics at target horizons.
- Assumptions/dependencies: Serving stacks must support shared-transformer, multi-scale sampling; QoS policy defines when to “spend” tokens on refinements.
- Continuity checking for editorial pipelines
- Sectors: media production, broadcast, QC
- What: Use generative rollout to predict expected re-entries of props/scenes and detect continuity errors across long sequences (e.g., wardrobe/prop placement inconsistencies).
- Tools/workflows: Compare predicted vs. actual frames on re-entry events; flag mismatches for editor review.
- Assumptions/dependencies: Requires controlled capture or proxy footage to prime context; human review remains necessary.
Long-Term Applications
These opportunities are promising but require additional research, domain data, scaling, or integration (e.g., combining with retrieval, 3D memory, or large pre-trained models).
- Long-horizon video editing (inpainting, relighting, style) with global consistency
- Sectors: creative tools, VFX, software
- What: Apply edits consistently over minutes—keeping identities, lighting, and layout stable through occlusions and camera moves.
- Tools/products: “Coarse-to-fine edit propagator” that binds global structure at coarse levels and applies localized refinements at finer levels; timeline-aware editing UIs.
- Dependencies: Robust conditioning on masks/text prompts; alignment of hierarchical latents with mainstream video VAEs; strong identity/appearance priors.
- Autonomous driving simulation and rare-event training
- Sectors: automotive, safety engineering
- What: Generate long, coherent street scenes for sim-to-real training, preserving distant landmarks and re-entries at intersections or loops.
- Tools/products: Scenario banks where the simulator “remembers” scene layout over kilometers; token-efficient online generators to scale coverage at lower compute.
- Dependencies: High-fidelity, multi-sensor training corpora; integration with physics/dynamics; regulatory validation of synthetic training efficacy.
- On-robot long-horizon world models for planning and SLAM support
- Sectors: robotics, industrial automation, logistics
- What: A streaming generative memory that maintains object permanence to assist long-range planning or loop closure in challenging environments.
- Tools/products: Robot stack modules that fuse hierarchical video memory with retrieval and 3D maps; “consistency-aware” planners that query coarse memory first.
- Dependencies: Real-time constraints, sensor fusion, safety validation; robustness to viewpoint/illumination changes; occasional re-anchoring with 3D geometry.
- Telepresence/AR scene persistence and predictive rendering
- Sectors: AR/VR, telepresence, collaboration
- What: Predictively render occluded or off-screen content consistently (e.g., around corners) to reduce latency and improve user experience during long sessions.
- Tools/products: Client-side hierarchical buffers that stream coarse future context and refine when bandwidth allows (token-adaptive streaming).
- Dependencies: Tight integration with SLAM/scene graphs; low-latency model variants; privacy-preserving on-device inference.
- Personalized long-form media generation (storytelling, vlogging assistants)
- Sectors: consumer apps, entertainment
- What: Maintain character identity, wardrobe, and setting across episodes or chapters to produce coherent story arcs or vlog series.
- Tools/products: “Series generator” that stores persistent coarse tokens as show memory; episodic editing tools that reuse global structure across episodes.
- Dependencies: Ethical safeguards, consent/identity protections; robust identity conditioning; large-scale, domain-specific pretraining.
- Long-range consistent medical simulation and training videos
- Sectors: healthcare, medical education
- What: Generate extended, anatomically consistent endoscopy/surgery simulations for trainees, preserving spatial relationships as the camera loops and re-enters regions.
- Tools/products: Curriculum generators with action/pose scripts; fidelity checkpoints that enforce plausible anatomy at coarser levels before refining textures.
- Dependencies: Regulated clinical datasets; expert validation; strong priors to avoid hallucinated pathology; compliance and safety evaluation.
- Scientific/industrial process visualization
- Sectors: energy, manufacturing, R&D training
- What: Long-form synthetic videos of plant operations or lab procedures that maintain equipment layout and state continuity across cycles.
- Tools/products: Operator training simulators with coarse-to-fine generators; anomaly-insertion tools for rare event drills.
- Dependencies: Process-specific data; coupling with physics and control signals; sign-off from safety and compliance teams.
- Retrieval-augmented, hierarchical video generators for minute-scale consistency
- Sectors: AI research, platforms
- What: Combine this paper’s hierarchy with retrieval of very old frames to push consistency to much longer timescales without exploding compute.
- Tools/products: “Memory broker” that selects what to store as hierarchical tokens vs. retrieve as frames; scheduler that balances retrieval vs. refinement.
- Dependencies: Memory indexing, relevance scoring, and deduplication; stability of long rollouts; evaluation protocols for multi-minute horizons.
- Distillation bridges from large video models (WAN, Hunyuan Video) to hierarchical latents
- Sectors: foundation models, model serving
- What: Align popular VAEs to hierarchical latents so existing large models benefit from coarse-to-fine rollout and longer effective context.
- Tools/products: Distillation toolkits that map fine latents to hierarchical scales; adapters that let a single transformer serve multiple scales.
- Dependencies: Access to base model weights; stable multi-scale training; backward-compatible decoders and safety guardrails.
- Content policy and standards for long-context generative video
- Sectors: policy/standards, trust & safety
- What: Establish benchmarks and disclosures for “temporal consistency” in generative media (e.g., minimum horizons, continuity metrics), aiding provenance and misuse assessment.
- Tools/products: Standardized test suites (LPIPS/DINOv2/LightGlue against held-out trajectories); reporting templates for model cards.
- Dependencies: Multi-stakeholder consensus; datasets with controlled re-entry events; alignment with provenance standards (e.g., C2PA).
Notes on feasibility across applications:
- Key dependencies: domain-aligned training data, action/pose conditioning signals, compute budgets for extra rollout steps, and integration with or distillation from existing video VAEs/diffusion models.
- Assumptions: Coarser levels truly capture semantics/layout well enough to anchor long-horizon predictions; evaluation metrics remain robust to minor trajectory drift.
- Risks/trade-offs: More rollout steps increase latency; domain gaps can reduce consistency; stronger consistency may also improve realism of malicious deepfakes—requiring parallel advances in detection and provenance.
Glossary
- 3D point cloud: A collection of spatial points in 3D space used to represent geometry; often built incrementally from images. Example: "build an incremental 3D point cloud and use camera pose to retrieve past frames most relevant to the current target frames."
- action-conditioned: A model conditioned on action inputs (e.g., controls or commands) to guide generation. Example: "All models are action-conditioned; the action space consists of a single ternary value that indicates whether the agent is turning left, turning right, or moving forward."
- autoregressive rollout: Generating sequences step-by-step where each chunk conditions on recently generated outputs, often leading to forgetting distant context. Example: "Current models are largely designed for autoregressive rollout, generating long videos chunk by chunk, with the most recent chunk serving as context for the next."
- cascaded diffusion models: Multi-stage diffusion pipelines that generate coarse outputs first and then progressively refine them at higher resolutions. Example: "cascaded diffusion models~\cite{ho2022cascaded,mukhopadhyay2026scale}"
- coarse-to-fine rollout: A generation strategy that first produces low-detail (coarse) representations over long horizons and then refines them with higher-detail (fine) information. Example: "We show that this issue can be mitigated by generating video using coarse-to-fine rollout within a multi-scale token space."
- context length: The number of prior tokens/frames a model can condition on at once. Example: "A straightforward solution to this problem is to increase the context length."
- context window: The set of past tokens/frames available to the model at a given step. Example: "even if that content remains in its compressed context window."
- denoise: To predict and remove noise from corrupted latent variables during diffusion model training/sampling. Example: "supervise the model on its ability to denoise the {generated} tokens"
- DINOv2 class token cosine similarity: A consistency metric based on the cosine similarity of DINOv2’s class token embeddings between frames. Example: "DINOv2 class token cosine similarity"
- FID (Fréchet Inception Distance): A measure of image generation quality based on distributional distance between generated and real images’ features. Example: "We measure quality using FID and FVD."
- FVD (Fréchet Video Distance): A measure of video generation quality based on distributional distance between generated and real videos’ features. Example: "We measure quality using FID and FVD."
- frame tokenizer: A module that encodes each video frame into a sequence of discrete or continuous tokens for downstream modeling. Example: "Our frame tokenizer can be considered a multi-scale variant of ElasticTok"
- hierarchical autoencoder: An encoder-decoder that represents inputs at multiple scales/levels, each decodable independently. Example: "Our hierarchical autoencoder consists of a multi-resolution encoder-decoder pair."
- hierarchical latent space: A multi-level latent representation where coarser levels capture global structure and finer levels add detail. Example: "we train an autoencoder with a hierarchical latent space, in which each level represents an image using a specific number of tokens."
- hierarchical tokenizer: A learned tokenization scheme that outputs representations at multiple scales, preserving salient structure under compression. Example: "we find that training a hierarchical tokenizer yields compression that better preserves relevant detail."
- LightGlue: A learned feature matching method used here to count high-confidence keypoint matches for consistency evaluation. Example: "Our LightGlue match metric counts the number of keypoint matches detected by LightGlue with confidence greater than 0.5."
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric that compares images using deep features to assess similarity. Example: "the highest-resolution reconstruction is supervised using MSE and LPIPS"
- mean-pooled: A downsampling operation where features are averaged over neighborhoods to reduce resolution. Example: "defined as downscaled (mean-pooled) versions of the finest level"
- multi-resolution image pyramid: A stack of the same image at progressively lower resolutions, used for multi-scale processing. Example: "The encoder receives a multi-resolution image pyramid as input."
- novel view synthesis: Generating images of a scene from new viewpoints given observed images and possibly geometry. Example: "accelerate 3D scene generation for novel view synthesis."
- patchification: Converting an image into a grid of non-overlapping patches (tokens) for transformer-based processing. Example: "varying patchification of full-resolution latents"
- positional encodings: Extra signals added to tokens to encode their location (e.g., row, column, frame, level) for transformers. Example: "add positional encodings for each token's row, column, and level index"
- PSNR (Peak Signal-to-Noise Ratio): A distortion-based metric comparing a generated image to a reference based on pixel-wise differences. Example: "We measure consistency using PSNR, LPIPS, SSIM"
- SSIM (Structural Similarity Index): A metric assessing image similarity by comparing structural information between images. Example: "We measure consistency using PSNR, LPIPS, SSIM"
- temporal horizon: The span of future or past time steps a model reasons over or must maintain consistency across. Example: "different visual information needs to persist over different temporal horizons."
- token budget: A fixed limit on the number of tokens a transformer can process, allocated across frames/scales. Example: "explicitly allocate a transformer's fixed token budget across scales"
- transformer sequence length: The maximum number of tokens a transformer can attend over in a single pass. Example: "The fundamental constraint that our model is designed around is a transformer's sequence length ."
- unpatchify: Reconstructing images from patch-based token representations by reversing patchification. Example: "and unpatchify the output, mirroring the encoder's patchification."
- unprojection: Mapping 2D image features back into 3D space using camera geometry. Example: "use unprojection and projection into a 3D voxel grid for persistent 3D scene memory."
- voxel grid: A 3D grid of volumetric cells (voxels) used to store features or geometry. Example: "use unprojection and projection into a 3D voxel grid for persistent 3D scene memory."
Collections
Sign up for free to add this paper to one or more collections.

