- The paper introduces a flexible-length, coarse-to-fine video tokenization method that efficiently captures high-level semantics and motion with fewer tokens.
- The paper employs a time-causal Transformer with nested dropout to dynamically adjust the token granularity and enhance generative performance.
- The paper demonstrates that using 5–10× fewer tokens achieves competitive fidelity and alignment compared to traditional 3D grid tokenizers in long video generation.
VideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization
Introduction
VideoFlexTok introduces a paradigm shift in video tokenization for generative modeling by providing a representation that is both variable in length and organized in a coarse-to-fine manner. Conventional 3D grid-based tokenizers quantize videos into fixed local patches, requiring every downstream generative model (e.g., text-to-video) to reconstruct or generate all low-level details, leading to excessive computational demands and inefficiencies when the downstream task does not necessitate full fidelity. VideoFlexTok enables the abstraction of high-level semantics and motion using only a small number of tokens, while the remaining tokens incrementally introduce finer details. This approach dramatically enhances both representational efficiency and compute allocation for downstream video generation and modeling.

Figure 1: VideoFlexTok reconstructions from a variable number of tokens. The first few tokens capture semantic identities and motion, with details refined as more tokens are included.
Methodology
Encoding: Flexible-Length, Coarse-to-Fine Representation
The encoder operates on spatiotemporal VAE latents, augmented with learnable register tokens. The tokens are interleaved across the temporal axis and processed by a Transformer with a time-causal attention mechanism, producing a two-dimensional token structure: one axis for time, the other for abstraction level (coarse-to-fine). The coarse-to-fine structure is enforced via nested dropout, which randomly removes a subset of the least-important (finest-level) register tokens per frame.

Figure 2: VideoFlexTok overview. The encoder extracts coarse-to-fine video representations with nested dropout. The generative flow decoder enables reconstructions from arbitrary token counts.
To drive more abstract and semantic representations in the earliest tokens, VideoFlexTok employs a representation alignment loss with DINOv2 features (REPA). This semantic bias ensures that the early hierarchy levels capture global properties like objectness, geometry, and motion, rather than merely optimizing for pixel-level reconstruction.

Figure 3: Probing the first VideoFlexTok tokens reveals that early tokens encode scene motion and high-level identity, as demonstrated by preserving motion with isolated object edits.
Decoding: Generative Rectified Flow Decoder
The decoder is conditioned on the (possibly partial) register tokens, interleaved with noised VAE latents, and trained as a generative flow-based model using a rectified flow objective. Time-causal attention ensures autoregressive consistency and compatibility with streaming. The decoder is robust to the number of input tokens and can synthesize plausible, temporally consistent videos regardless of how much detail is present in the token representation.
AR Modeling and Generation
Downstream, VideoFlexTok tokens are modeled using a GPT-style autoregressive Transformer. For class- or text-conditioned generation, the AR Transformer operates in a time-first generation order, predicting the first (most abstract) token per frame, then the second, and so on. This coarse-to-fine generation order enables dynamic adjustment of computational budget at inference or training, supporting high-level generation with few tokens and fine-level detail as needed.

Figure 4: Flexible-length autoregressive text-to-video generation. Generations with fewer tokens preserve semantics and motion, while more tokens progressively add visual details.
Experimental Results
Representation Quality and Efficiency
Qualitative evaluation indicates that just a handful of coarse tokens suffice to reconstruct salient semantic and motion cues of a video, with only additional tokens needed for finer visual details (Figures 1, 12–15). Probing experiments show that the earliest tokens robustly encode motion, supporting abstractions that are suitable for efficient downstream modeling.
In class-to-video and text-to-video generation tasks, VideoFlexTok achieves comparable gFVD and ViCLIP/Cls. alignment metrics relative to 3D grid tokenizers, while using an order of magnitude fewer model parameters and training tokens. Notably, in settings where token and compute budgets are fixed, VideoFlexTok allows for longer videos or increased abstraction without additional computational overhead.
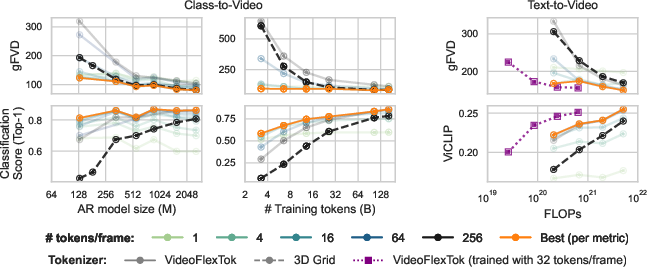
Figure 5: Compute-efficient AR training with VideoFlexTok. Comparable or superior fidelity and alignment can be achieved with models that are 5–10× smaller or trained on 5–10× fewer tokens relative to grid tokenizers.
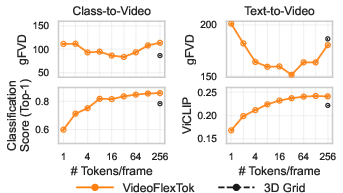
Figure 6: Flexible-length generation. For both class-to-video and text-to-video, VideoFlexTok matches or exceeds grid baselines in fidelity and alignment with as few as 2–4 tokens per frame.
An ablation on hierarchical (coarse-to-fine) versus raster (flat grid) generation at matched sequence lengths indicates that hierarchical generation with VideoFlexTok yields substantially better alignment scores and generation fidelity in the absence of classifier-free guidance, highlighting the effectiveness of the proposed 2D token structure.
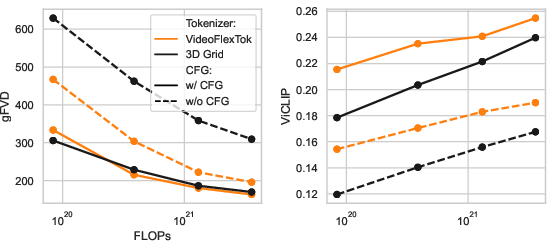
Figure 7: Hierarchical vs. raster-order generation. VideoFlexTok achieves better alignment and higher fidelity compared to 3D grid tokenizers at the same token count.
Long Video Generation and Inference Scaling
By dynamically adjusting the number of required tokens, VideoFlexTok enables direct modeling of long, temporally consistent videos (e.g., 10 seconds, 81 frames) with only 672 tokens, compared to 5376 for typical grid-based approaches—an 8× improvement.

Figure 8: Long text-to-video generation. Generation of coherent 10-second, 81-frame video sequences using only 672 tokens.
A comprehensive FLOPs analysis reveals that allocating compute toward fewer AR-generated tokens and more decoder denoising steps yields optimal performance under realistic cost constraints. This efficient allocation is not available in grid-based tokenization frameworks.
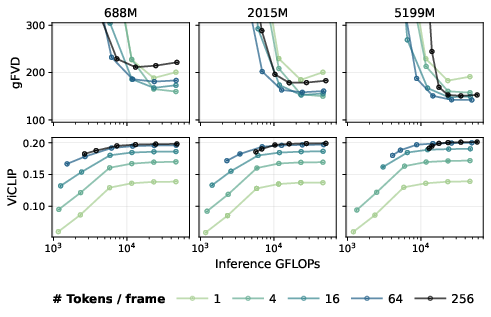
Figure 9: Text-to-video inference cost analysis. For all AR model sizes, the best performance at given compute is obtained using fewer tokens and more decoder steps.
Theoretical Implications and Future Directions
The proposed coarse-to-fine variable-length tokenization paradigm has far-reaching implications for abstract and hierarchical video representation learning. By decoupling the modeling of semantics/motion from pixel-level details, VideoFlexTok enables efficient allocation of modeling capacity, supports long-horizon temporal reasoning, and is better aligned with the requirements of multimodal and embodied intelligence systems where abstraction and controllable detail are critical.
Such representations facilitate future architectures where generative or reasoning models adaptively select an appropriate level of abstraction, potentially in conjunction with reinforcement learning or planning, enabling new capabilities in semantic reasoning and efficient large-scale video generation. Additionally, the approach harmonizes with trends toward modeling in semantic feature spaces, which is expected to be prominent in next-generation video foundation models.
Conclusion
VideoFlexTok establishes a highly efficient, semantically ordered, and flexible framework for video tokenization, enhancing generative modeling's tractability and adaptability. Through its variable-length, coarse-to-fine structure, VideoFlexTok improves both training and inference efficiency, supports high-quality long-video generation under stringent compute budgets, and offers competitive or superior alignment and fidelity across a broad spectrum of downstream tasks (2604.12887). Its methodology is immediately relevant for scalable video foundation models and paves the way toward more abstract, resource-aware video generative architectures.