- The paper presents a unified framework integrating language models, neuro-symbolic methods, and formal verification to enhance mathematical reasoning.
- It details a methodological progression from numeric supervision to full formal verification, addressing issues like hallucination and adversarial perturbation.
- Empirical benchmarks demonstrate rapid progress, with models achieving >90% on math tasks, underscoring the shift towards verified, AI-driven discovery workflows.
Artificial Intelligence for Mathematical Reasoning: An Integrated Survey of LLMs, Neuro-symbolic Systems, and Verified Discovery
Introduction and Motivation
The survey "Artificial Intelligence for Mathematical Reasoning: An Integrated Survey of LLMs, Neuro-symbolic Systems, and Verified Discovery" (2606.08728) presents a comprehensive and technical panorama of mathematical reasoning as an AI grand challenge, mapping the evolution from early symbolic schemes to reasoning-model era LLMs, neuro-symbolic architectures, and AI-driven discovery workflows. The field’s uniqueness lies in the compositionality, verifiability, and cognitive centrality of mathematics, positioning it as both a technical frontier and an epistemic test for claims about machine intelligence.
The survey distinguishes four canonical axes:
- Informal reasoning over text and diagrams (MWP, geometry, multimodal reasoning)
- Formal reasoning in interactive theorem provers (formalization, tactic prediction, proof search)
- Mathematical discovery (algorithmic construction, bound improvement, attack on open problems)
- Supervision and verification techniques (chain-of-thought prompting, tool use, reinforcement learning with verifiable rewards)
The work highlights not just research progress, but the changing landscape of evaluation, the criticality of verification, and the emergence of workflows that integrate LLM inferential power with formal proof checking and evolutionary program search.
Methodological Progression and Taxonomy
The survey introduces a unifying taxonomy integrating methods, paradigms, task families, and supervisory constraints (Figure 1):
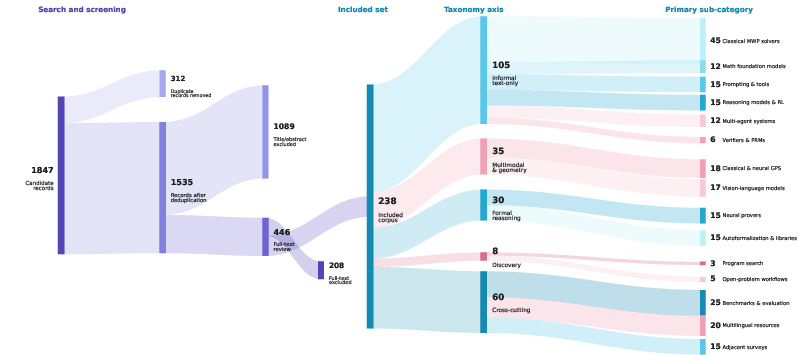
Figure 1: Search, screening, and taxonomy coding pipeline for the survey corpus, with clear demarcations of task families, methodological axes, and evolutionary trends in research coverage.
At the core is a supervision ladder, transitioning from final-answer supervision (numeric correctness) to intermediate artifact generation (symbolic programs, proof traces), to full formal verification (proof-assistant certification). This progression is directly reflected in robust empirical advances and in the field’s paradigm shifts:
- Early MWP solvers were symbolic and rule-driven, limited by handcrafted schemata and fragile to domain shift
- Neural sequence-to-sequence models and graph-based encoders refined the representation but struggled with compositional generalization and robustness
- LLMs with chain-of-thought (CoT) and tool augmentation, reinforced by verifiable rewards and process reward models (PRMs), achieved dramatic capability gains but exposed new vulnerabilities to hallucination and answer-only selection bias
- Modern neuro-symbolic and formal reasoning systems (e.g., DeepSeek-Prover, AlphaProof, LeanDojo) integrate procedure search, premise retrieval, formal language generation, and interactive proof repair
The survey positions the field’s current state as a convergence of these trajectories—an era where long-chain reasoning, verification-centric RL, and interoperable discovery pipelines define progress.
Benchmarking is centrally analyzed, with careful cataloging of MWP, competition, formal, multimodal, and multilingual datasets. The onset of the reasoning-model era is evidenced in the abrupt performance jumps on canonical math and competition datasets (Figure 2):
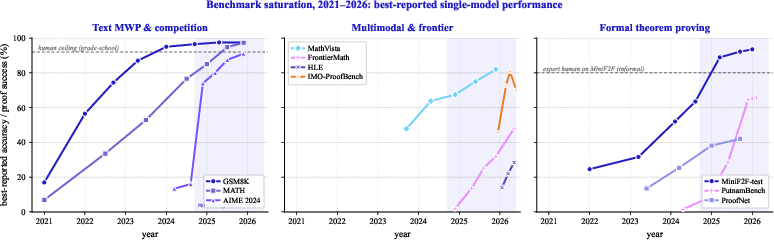
Figure 2: Benchmark saturation (2021--2026), showing rapid performance escalation on mathematical reasoning tasks, with notable inflection corresponding to the introduction of RLVR-trained reasoning models and advanced verification pipelines.
Key empirical milestones:
- Standard LLMs achieved >90% on GSM8K and MATH by 2025, saturating “classical” reasoning tests
- OpenAI o-series, DeepSeek-R1, and Kimi k1.5 established reasoning-specific LLMs with Pass@1 and majority-vote performance at or above IMO gold medal thresholds on contemporary competitions
- In formal proving, pass@k success rates on MiniF2F, PutnamBench, and formalized Olympiad problems climbed from sub-30% to above 85–90% in under two years, with neuro-symbolic systems like AlphaProof and DeepSeek-Prover-V2 closing previously formidable gaps
However, benchmark contamination and reporting ambiguity (exact-match versus pass@k/majority vote) are highlighted as persistent challenges, impacting cross-paper comparability and claims of progress.
Synthesis: Verification-Centered Progress and Failure Modes
A central argument is the decisive role of external verification in scaling mathematical reasoning. Process reward models, execution traces, and formal kernels are not peripheral but core to the current acceleration. The survey contrasts protocol families (majority voting, agentic debate, PRM selection, Lean kernel verification) and their distinctive failure modes, observing that the strongest future gains arise from integrating diverse search and robust external checking rather than relying solely on larger or more expressive generators.
The survey provides a rigorous treatment of failure modes:
- Persistent semantic brittleness under paraphrase, distraction, and adversarial perturbation—especially evident in benchmarks like SVAMP and GSM-Symbolic
- Hallucination of mathematical derivations and proofs, beyond what final-output gradings (pass@1/pass@k) can detect
- Multimodal grounding errors, where MLLMs ignore or misinterpret diagrammatic input, or improve when visual information is ablated
- Reward hacking in RLVR, shortcutting of answer-only metrics
- Correlated errors and high compute cost in multi-agent or orchestrated workflows
Mathematical reasoning is found to be uniquely demanding: the transition from plausible to correct requires mechanical adjudication at intermediate steps, not just fluency or path diversity.
AI-Driven Discovery and the Verified-Discovery Pipeline
The survey’s treatment of open-ended mathematical discovery is especially notable. Contemporary systems (FunSearch, AlphaEvolve, Aristotle/Lean workflows) are positioned as exemplars of the “verified-discovery” paradigm, where an LLM or program synthesizer proposes explicit candidates (e.g., new combinatorial constructions or proof skeletons), and correctness is established via automated execution, tool-based fitness evaluation, or full formal verification. The pipeline is further articulated to involve iterative feedback: failed formalizations or counterexamples refine subsequent proposals, and the end artifact is both human- and machine-checkable.
Such workflows have already contributed to nontrivial mathematical advances (e.g., the complex matrix multiplication problem, the resolution of select Erdős problems), but the authors cautions that novelty and formal soundness require careful human auditing and adherence to emerging standards for claiming genuine discovery.
Implications, Limitations, and Future Directions
The implications are multi-faceted:
- Practical: The supervisor is no longer a single grader, but a pipeline—LLMs, tool-augmented reasoning, autoformalization, and proof assistants.
- Theoretical: Verification-centered learning offers a more robust path to general mathematical reasoning than context-agnostic pretraining or pure prompt engineering.
- Sociotechnical: The compute and access costs of reasoning-scale inference necessitate investment in distillation, adaptive reasoning budgets, and open-weights deployments to avoid global disparities in access to AI-assisted mathematics.
- Infrastructure: The “de Bruijn factor”—the human cost of formalization—is rapidly decreasing, and progress in community-maintained formal libraries (especially Lean and mathlib) will be decisive for the next phase of automated formal mathematics.
Limitations include heterogeneous reporting protocols, incomplete public access to frontier models, and the evolving, sometimes ambiguous status of open-problem “solves” requiring human verification or formalization.
The authors identify ten urgent directions: robustness under paraphrase and adversarial modification, cross-language mathematical reasoning, multi-agent orchestration, neuro-symbolic system integration, adaptive inference, curriculum scheduling for RLVR, energy-efficient distillation, and community infrastructure for formalization.
Conclusion
The survey offers a highly technical synthesis and forward-looking perspective: the automation of mathematical reasoning is, at its current frontier, a matter of integrating expressive LLM generation with strict external verification, orchestrated search, and workflow design that couples machine and human creativity. Answer-level performance, while necessary, is inadequate without transparent, stepwise, and checkable reasoning. The verification bottleneck is not a roadblock, but the strongest source of supervision for sustained progress in AI for mathematics. Practitioners and researchers should focus on creating workflows and infrastructures that enable verified discovery, robust cross-domain generalization, and genuine augmentation of mathematical practice, as the field’s defining challenges for the coming years.

