- The paper presents a structured taxonomy of 36 LLM reasoning families across compositional mechanisms and cognitive levels, identifying key methodological gaps.
- It demonstrates that LLM reasoning emerges from autoregressive next-token prediction, where explicit prompting and architectural interventions boost reliability.
- Emerging paradigms in chain-of-thought, retrieval-augmented, and agentic reasoning are examined, highlighting challenges in robustness and generalizability.
The Periodic Table of LLM Reasoning: A Structured Survey of Reasoning Paradigms, Methods, and Failure Modes
Introduction and Motivation
This paper presents a comprehensive, taxonomically-structured synthesis of reasoning capabilities, paradigms, methods, limitations, and emerging directions in LLMs (2606.11470). The authors collate insights from over 300 publications to dissect modern LLM performance on diverse reasoning problems—including chain-of-thought (CoT), multi-hop, mathematical, commonsense, multimodal, retrieval-augmented, tool-augmented, agentic, and reinforcement learning (RL)-based reasoning. A central question addressed is the extent to which robust, generalizable reasoning emerges from data-driven pretraining versus being contingent on explicit, structured interventions such as specialized prompting, architectural augmentation, or iterative self-improvement. The survey offers an explicit framework to evaluate the current state and open research questions of LLM reasoning, from methodological patterns to recurring failure modes and prospective research avenues.
Classification and Taxonomy of Reasoning Paradigms
An immediate contribution is the systematic taxonomy of LLM reasoning behaviors (Figure 1). The taxonomy organizes 36 reasoning families across two axes: the nature of their compositional mechanism (e.g., stepwise decomposition, domain-specific, learning/reflective, augmented, cross-boundary) and their cognitive spectrum (from foundational, low-level operation up to high-level abstraction and meta-reasoning).

Figure 1: A taxonomy of LLM reasoning paradigms arranged in a 6×6 grid based on composition mechanism and cognitive abstraction.
Each cell in the taxonomy encapsulates a family of methods. This fine-grained classification enables precise mapping of recent advances—such as specialized chain-of-thought techniques, retrieval-augmented reasoning, program synthesis, or agentic planning—onto a common conceptual space, highlighting both methodological convergences and latent research gaps.
The LLM Reasoning Pipeline and Model Anatomy
The paper highlights that LLM “reasoning” is fundamentally realized via autoregressive next-token prediction, with intermediate inferences emerging as statistical artifacts of the generation mechanism (Figure 2). Reasoning, even in sophisticated prompting or planning frameworks, remains a sequence of chained conditional predictions, with “knowledge” divided between transient context, parametric memory, and attention-estimated dependencies.
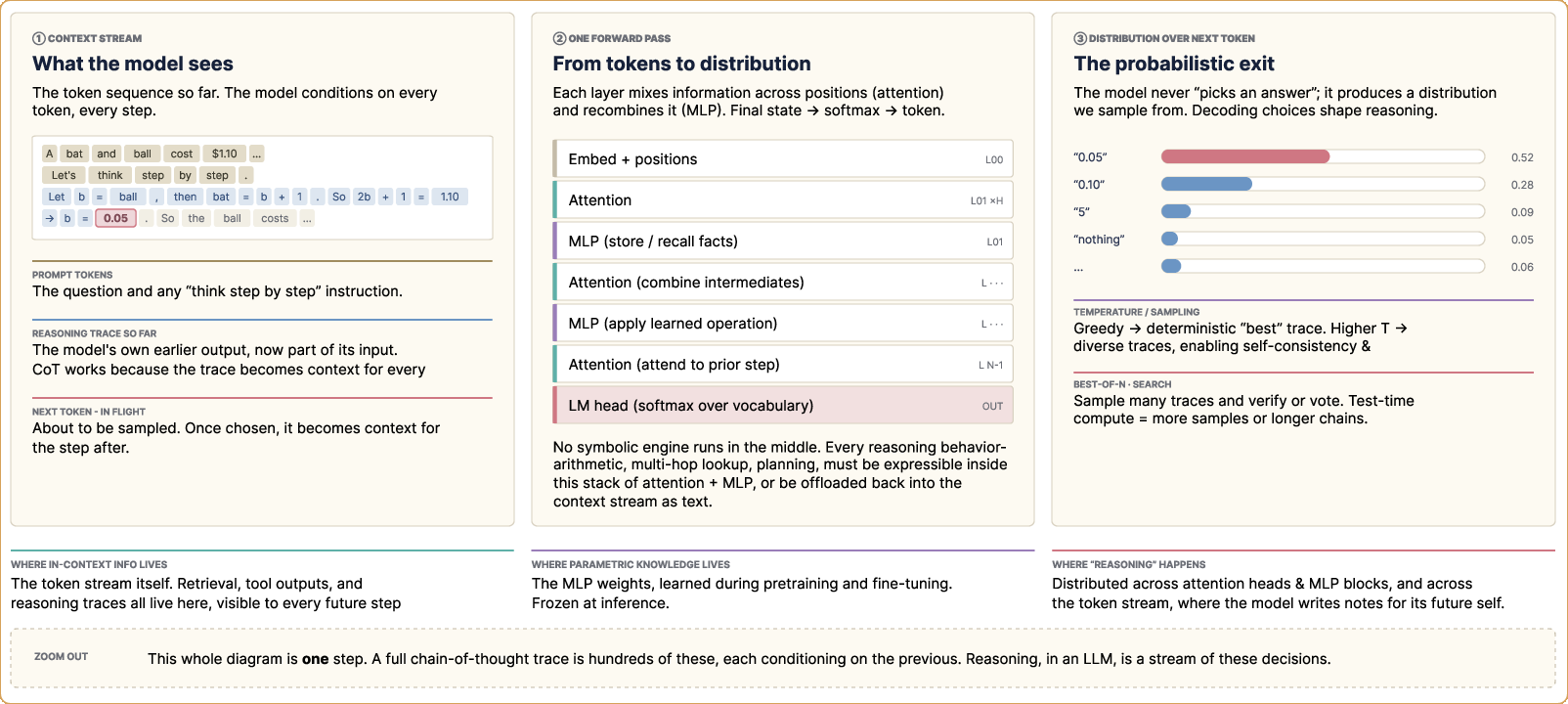
Figure 2: Foundational mechanism diagram—a forward pass indicating boundaries between in-context knowledge, parametric memory, and attention-based information propagation in LLMs.
The survey emphasizes that the repeated application of the token prediction process, across increasingly structured contexts induced by advanced prompting or architectural scaffolding, is the practical substrate from which current LLM reasoning emerges.
Unified Pipeline and Paradigm Commitments
A shared skeleton of modern LLM reasoning paradigms is distilled (Figure 3), mapping the canonical pipeline: Question → Decompose → Retrieve → Step → Verify → Aggregate → Answer. The comparative analysis displayed captures the “station stops” for each reasoning paradigm—showing, for example, that not all commit to evidence retrieval, verification, or aggregation, and that these omissions often directly correlate to failure modes in robustness or generalizability.
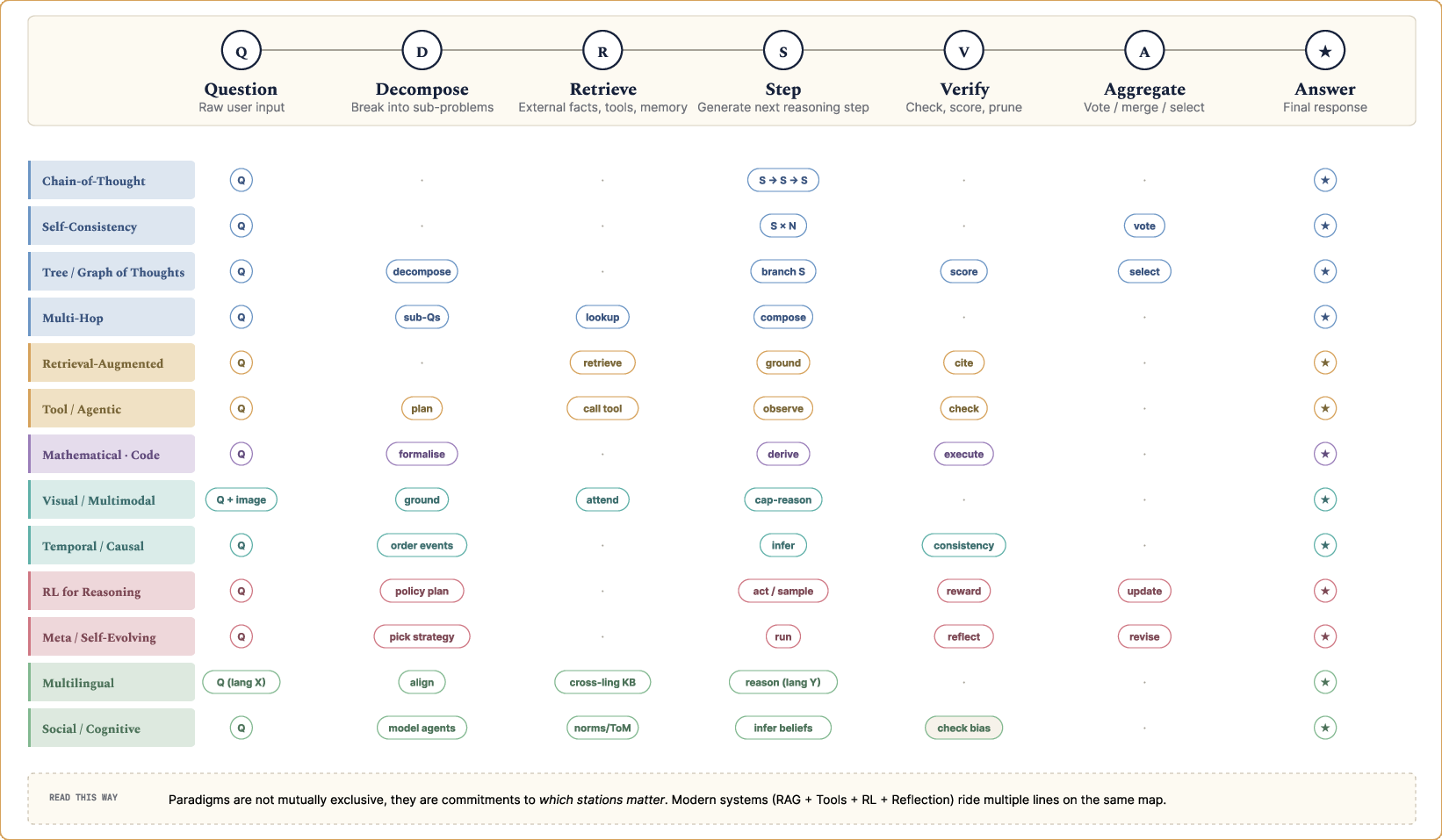
Figure 3: Reasoning pipeline skeleton illustrating paradigm-specific commitments across decomposition, retrieval, verification, aggregation, and answer generation stations.
Families of LLM Reasoning
Chain-of-Thought and Multi-Hop Reasoning
Chain-of-thought (CoT) methods elicit interpretable, multi-step trajectories for problems with latent compositional structure (e.g., arithmetic, symbolic reasoning, multi-part question answering). Experimental results indicate clear gains for symbolic and compositional problems, but negligible or even negative impact in tasks where verbalization disrupts implicit reasoning or invites overthinking.
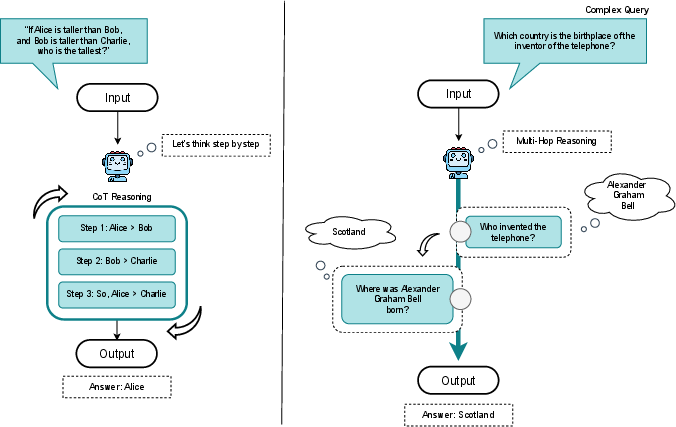
Figure 4: Interaction of CoT and multi-hop reasoning, illustrating the propagation of intermediate results across chained inferences.
Multi-hop reasoning, which requires the integration of distributed evidence often spread across multiple documents or locations, remains particularly fragile. The “utilization gap” presented—improved performance on the first hop (retrieval) vs. significantly weaker performance on subsequent hops—demonstrates that reasoning depth is not trivially restored with model or context window scale.
Mathematical Reasoning
Mathematical reasoning exposes acute limitations in structural abstraction, logical consistency, and symbolic manipulation. Advances here leverage curated pretraining corpora, architectural modifications (e.g., memory-, verification-augmented), and process-level feedback (RL, process-supervision, MCTS-based search). Evaluation tightly couples process-level robustness measures (perturbation benchmarks, out-of-distribution analysis, volatility of embedding dynamics) with classical accuracy, exposing brittleness to problem restatement and out-of-domain generalization.




Figure 5: Mathematical reasoning flow from problem input to symbol extraction, formula application, arithmetic execution, and final verification.
Commonsense and Multimodal Reasoning
Commonsense reasoning is evaluated through world-knowledge activation, causal inference, and plausibility judgement protocols. The results indicate that models are heavily dependent on context artifacts and benchmark design, with meaningful advances primarily appearing when knowledge artifacts (graphs, highlights, tags) are tightly scaffolded through the reasoning process.



Figure 6: Commonsense reasoning pipeline showing world-knowledge activation, causal chain construction, and inference.
Emerging multimodal reasoning research combines vision-language pretraining with explicit grounding, algorithmic tool integration, and external retrieval, targeting visual, temporal, and spatial abstraction.

Figure 7: Multimodal reasoning pipeline comprising image encoding, cross-modal fusion, and visual intent inference.
Temporal and Code Reasoning
Temporal reasoning combines linguistic extraction, event ordering, and timeline synthesis. Explicit temporal graph induction and symbolic timeline construction substantially improve robustness relative to purely generative approaches.

Figure 8: Temporal reasoning flow with time expression parsing, timeline construction, and duration calculation.
Code reasoning incorporates intent mapping, algorithmic decomposition, program synthesis, and verification through test execution, capturing the nontrivial interaction of symbolic logic and software engineering tasks.




Figure 9: Code reasoning pipeline showing problem concept mapping, logic planning, code generation, and test-based verification.
Retrieval-Augmented and Agentic Reasoning
RAG frameworks augment a model’s parametric knowledge by integrating external retrieval, with recent advances moving from static IR pipelines to unified and autoregressive retrieval-generation architectures that optimize retrieval planning via action policies—mirroring multi-step “planning” in human reasoning. Failure to structurally ground retrieval and evidence integration leads to factuality and robustness collapse.

Figure 10: Retrieval-augmented reasoning pipeline including query embedding, document retrieval, reranking, prompt fusion, and answer generation.
Agentic and tool-augmented reasoning move LLMs toward interactive, action-oriented problem solving, necessitating explicit planning, orchestration, self-correction, compute/resource allocation, and adversarial robustness. Multi-agent strategies (debate, consensus, specialization) show performance improvements but remain compute-intensive when not distilled.
Limitations and Emerging Directions
The survey repeatedly emphasizes the fragility and lack of principled generalization in current LLM reasoning, especially under distribution shift, adversarial perturbation, and increasing problem complexity. Specific failure modes recur: hallucinated or inconsistent reasoning traces, collapse under long-context or multi-step requirements, brittle performance on rephrased or structurally perturbed inputs, and unreliable transfer across modalities or languages. Benchmark inflation, “shallow” process artifacts, and confidence–robustness mismatches are highlighted as critical analytical gaps.
Key future directions include meta-reasoning (revising/controlling one’s own reasoning process), process-level and stepwise supervision (e.g., reward models, process rubrics), modular and agentic architectures for robust compositionality, multi-modal and multi-lingual path alignment, and interpretability tools for auditing reasoning chains.
Theoretical and Practical Implications
This taxonomy and synthesis have practical consequences for both research and deployment. On the methodological front, the necessity of structured process supervision, robust prompt design, engineered artifact integration, external symbolic scaffolds, and reinforcement-based optimization is consistently underscored for applications requiring reliability and transparency. Theoretically, the survey posits that scaling alone is insufficient; architectural and procedural interventions are required to move from pattern-based emulation to compositional, abstract reasoning.
The implications are that future progress will likely center on hybrid architectures that integrate symbolic reasoning, modular retrieval, memory systems, agentic planning, and self-improvement loops—all governed by process-level auditing and verification to ensure both interpretability and robustness.
Conclusion
This paper offers a foundational framework for reasoning in LLMs, providing rigorous taxonomy, comparative analysis, and synthesis of methodologies and failure cases. The recurring theme is that, despite impressive gains through scale and prompting, genuine, robust reasoning has not yet emerged as an automatic consequence of generic large-scale pretraining. Reliable, generalizable reasoning in LLMs—a requirement for trustworthiness in critical applications—demands explicit architectural, procedural, and evaluative commitments to structured, transparent, and consistent multi-step inference. This survey sets explicit research priorities for future development in modular, interpretable, and provably robust LLM reasoning systems.

