Vibe Reasoning: Eliciting Frontier AI Mathematical Capabilities -- A Case Study on IMO 2025 Problem 6
Abstract: We introduce Vibe Reasoning, a human-AI collaborative paradigm for solving complex mathematical problems. Our key insight is that frontier AI models already possess the knowledge required to solve challenging problems -- they simply do not know how, what, or when to apply it. Vibe Reasoning transforms AI's latent potential into manifested capability through generic meta-prompts, agentic grounding, and model orchestration. We demonstrate this paradigm through IMO 2025 Problem 6, a combinatorial optimization problem where autonomous AI systems publicly reported failures. Our solution combined GPT-5's exploratory capabilities with Gemini 3 Pro's proof strengths, leveraging agentic workflows with Python code execution and file-based memory, to derive both the correct answer (2112) and a rigorous mathematical proof. Through iterative refinement across multiple attempts, we discovered the necessity of agentic grounding and model orchestration, while human prompts evolved from problem-specific hints to generic, transferable meta-prompts. We analyze why capable AI fails autonomously, how each component addresses specific failure modes, and extract principles for effective vibe reasoning. Our findings suggest that lightweight human guidance can unlock frontier models' mathematical reasoning potential. This is ongoing work; we are developing automated frameworks and conducting broader evaluations to further validate Vibe Reasoning's generality and effectiveness.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows a new way for people and AI to work together to solve very hard math problems. The authors call it “Vibe Reasoning.” The big idea: today’s best AI models already “know” a lot of math, but they often don’t know how, what, or when to use that knowledge. With a bit of light, non-technical guidance from a human—like a coach giving general tips—the AI can turn its hidden potential into real problem-solving skill.
They test this on a famously tough puzzle from the International Mathematical Olympiad (IMO) 2025, Problem 6. Almost all humans and all AI systems failed it. Using Vibe Reasoning, the team found the right answer (2112) and gave a full proof.
The puzzle they tackled
Imagine a giant checkerboard with 2025 rows and 2025 columns. You lay down rectangles (they must align with the grid lines) to cover the small squares, but each small square can be covered at most once. You want every row and every column to have exactly one small square left uncovered. The question: What is the smallest number of rectangles you need?
For (which equals ), they found the minimum is 2112, and they proved no smaller number works.
What questions the paper tries to answer
- Can a little bit of human guidance (with no math spoilers) help strong AI models solve extremely hard math problems?
- Which kinds of guidance help most: asking for checks with code, trying small cases, switching models, writing notes, or something else?
- Why do powerful AIs fail when they work alone on such problems?
- Can the same teamwork style work on other tough problems?
How Vibe Reasoning works (with everyday analogies)
Think of Vibe Reasoning like a sports team with a coach:
- The AI is the main player: it explores ideas, builds examples, and tries to prove things.
- The human is the coach: they don’t play, don’t tell the exact moves, but give general advice like “try small practice drills,” “double-check with a calculator,” or “write this down so we don’t forget.”
The approach has four parts:
- AI as the main reasoner: The AI does the heavy lifting—searching, guessing patterns, building proofs.
- Socratic meta-prompts: The human gives general nudges like “verify with code,” “try small cases,” “summarize,” or “this path doesn’t seem promising.” These tips are not math hints; they’re thinking strategies.
- Agentic grounding: The AI uses tools to avoid daydreaming and mistakes:
- Running Python code is like using a calculator or simulator to test ideas quickly and catch errors.
- File-based memory is like keeping a neat notebook so the AI remembers what worked and what didn’t across long sessions.
- Model orchestration: Different AIs have different strengths. One model (GPT-5) was better at exploring patterns and building constructions; another (Gemini 3 Pro) was better at writing careful, rigorous proofs. The “coach” decides when to switch.
What they actually did to solve the IMO problem
First, the team let GPT-5 explore. At the start, when asked for the answer, it was confidently wrong. But when the human said “check with code” and “try small sizes first,” GPT-5 wrote programs to search small boards and noticed its earlier formula didn’t match the real results. That simple nudge made the AI catch its own mistake.
Then came a key hint from the human—still very general: “2025 is . Maybe perfect squares are special. Focus on $4,9,16,25$.” This is like saying, “Look at special cases that often have patterns.” With that direction, GPT-5 found a clean pattern for square sizes and guessed a formula:
- For , .
- Plugging in gives $2025 + 90 - 3 = 2112$.
GPT-5 also drew ASCII diagrams and used code to check that its rectangle coverings really worked. This “show, don’t just tell” step built confidence.
Next, they switched to Gemini 3 Pro for the proof that 2112 is not only achievable, but also the best possible (you can’t do better). Gemini used a method called a “Fooling Set,” which is like picking a special set of cells so that each rectangle can cover at most one of them. If you can pick such cells, you need at least rectangles. To build such a set big enough, Gemini used a classic math idea called the Erdős–Szekeres theorem about sequences that go steadily up-right or down-right when you plot points. In simple terms, it says that when you arrange many points, you’re forced to have a long up-right chain or a long down-right chain. That fact helps prove the lower bound matches the 2112 they constructed.
Finally, the team had Gemini verify this construction with code on random examples—like stress-testing a bridge model before declaring it safe.
Main results and why they matter
- They solved the problem: the minimum number of rectangles for is 2112, and they gave a rigorous proof.
- They showed why strong AIs fail when alone:
- Overconfidence: They give neat-sounding answers without checking.
- Poor self-evaluation: They don’t know when to test their ideas with code.
- Strategy fixation: They keep trying the same kind of proof even when it keeps failing.
- Memory issues: They lose track of what worked across long sessions.
- They showed that light, generic human guidance fixes these problems. Simple prompts like “verify with code,” “try small cases,” “save results to a file,” and “now switch to proof mode” were enough to unlock the AI’s abilities.
- They demonstrated that using the right tool for the right job—switching between models—matters a lot.
What this could change going forward
This work suggests a practical recipe for tackling very hard problems:
- Let AI do the math-heavy exploration and building.
- Give small, general coaching hints about process, not content.
- Ground the AI with tools: run code to test ideas and keep good notes to avoid forgetting.
- Use different AI models for different phases, like having different players for offense and defense.
If this approach scales, we could see:
- AI study buddies that help students explore and double-check tough problems.
- Research assistants that try many ideas, record what works, and switch styles when needed.
- More reliable AI problem-solving in areas beyond math, wherever careful testing and strategic thinking are important.
In short, Vibe Reasoning shows that a little human “good judgment” plus AI’s raw skill can beat challenges that stumped each side alone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to enable concrete follow-up work:
- Limited generality: only a single case study (IMO 2025 P6). No evaluation across diverse problem families (e.g., number theory vs. geometry vs. algebra), non-mathematical tasks, or problems without convenient computational verification. Action: build a benchmark of “exploration + proof” problems to assess transfer.
- Lack of baselines and ablations: no controlled comparisons against established frameworks (e.g., Chain-of-Thought, ReAct, Tree-of-Thoughts, Debate, self-consistency) or single-model tool-augmented pipelines; no ablation isolating contributions of (a) meta-prompts, (b) Python execution, (c) file-based memory, and (d) model orchestration. Action: run systematic ablations and head-to-head baselines with matched budgets.
- Minimality of human guidance unquantified: “lightweight/generic meta-prompts” are asserted but not measured. No counts of interventions, time-on-task, token budgets, or specificity scores. Action: define metrics for human effort and prompt specificity; publish per-session intervention logs.
- Reproducibility and replicability gaps: proprietary, unspecified model versions (“GPT-5,” “Gemini 3 Pro”), no public prompts/scripts/seeds, and highly non-deterministic LLM behavior threaten reproducibility. Action: release a replication package (code, prompts, traces, seeds, orchestration scripts) and demonstrate reproducibility across runs and users; test with strong open models.
- Orchestration policy is ad hoc: the decision of when/how to switch models is left to human intuition; no learned or rule-based router, no cost–performance analysis. Action: design and evaluate automated routing policies (e.g., bandits/RL/meta-controllers) that optimize accuracy, cost, and latency.
- Agentic grounding scope unclear: Python verification works for small n and constructive checks; no plan for problems where verification is intractable, non-deterministic, or non-executable (e.g., hard proofs, undecidable properties). Action: study scaling limits and alternatives (formal proof assistants, SMT solvers, property-based testing).
- Proof rigor and completeness concerns: the lower-bound verification reports “98% success” on random permutations, which is incompatible with a universal lower bound claim; the constant term “−3” is not justified with a full formal argument in-text. Action: provide a complete, formal, machine-checkable proof (e.g., Lean/Isabelle) and reconcile empirical checks with universal claims.
- Unresolved general case (non-squares): the paper gives a formula for (i.e., ) but does not address that are not perfect squares. Action: propose tight bounds or exact formulas for arbitrary , and analyze continuity/monotonicity and near-square behavior.
- “Residue block” structure not formalized: the construction for is described informally with examples; no formal definition, algorithm, or correctness proof is provided. Action: formalize the structure, give a constructive algorithm, and prove optimality.
- Dependence on selection of “special cases”: success hinged on focusing on perfect squares; the heuristic is compelling but unformalized. Action: develop general policies for selecting “special cases” (squares, primes, powers of two) and quantify their impact on discovery rates.
- File-based memory design unspecified: the memory mechanism (naming, chunking, retrieval policies, conflict resolution) is not described or compared to alternatives (vector databases, agent memories). Action: specify the memory schema and evaluate memory designs on coherence, error propagation, and task completion.
- Error analysis not at scale: the paper presents anecdotes (e.g., “guard scheme” failures) but lacks systematic error taxonomy and rates across many tasks. Action: collect and categorize failure modes across a suite of problems; report incidence, causes, and remediation effectiveness.
- No independence checks or formal verification pipeline: same/model-adjacent systems generate and verify artifacts, risking correlated errors; no integration with proof assistants or external checkers beyond Python tests. Action: incorporate independent validators (cross-model adjudication, proof assistants, certified checkers) and quantify disagreement rates.
- Data contamination and provenance risks: no audit of whether models were exposed to the problem/solutions in training; references to public solutions suggest potential leakage. Action: conduct decontamination audits and use held-out, private tasks to ensure integrity.
- Cost and efficiency unreported: no accounting of API/tool compute time, cost, or human time; no comparison of cost-effectiveness versus alternatives. Action: report detailed resource metrics and study accuracy–cost trade-offs.
- Robustness and sensitivity unmeasured: outcomes may depend on prompt phrasing, model temperature, or human style; stability across runs and users is unknown. Action: perform sensitivity analyses and measure variance under prompt/model perturbations.
- Generalization beyond mathematics is untested: claims are framed broadly, but only math is demonstrated. Action: evaluate on domains like program synthesis, scientific hypothesis testing, planning, and engineering design, where verification modalities differ.
- Safety and security of agentic workflows: executing model-written code and reading/writing files introduces risks (sandbox escapes, prompt/file injection, state poisoning). Action: articulate and test a security model (sandboxing, permissions, audit logs, taint tracking).
- Interface and UX questions: how to scaffold “Socratic meta-prompts” for non-experts, present memory artifacts, and manage model switches is not studied. Action: run user studies on learnability, cognitive load, and outcome quality with different UIs.
- Theoretical foundations missing: no formal model of why/when meta-prompts + tools + orchestration improve success or convergence; no guarantees on error detection or search efficiency. Action: develop task–agent models and derive bounds on detection probability, sample complexity, and switching policies.
- Negative cases and failure boundaries: the paper focuses on a success story; it does not delineate where Vibe Reasoning breaks (e.g., tasks with misleading heuristics, no verifiable subgoals, highly deceptive local optima). Action: map the method’s applicability frontier with counterexamples and stress tests.
- Comparative model coverage is narrow: only two (proprietary) frontier models are examined, with anecdotal strengths. Action: broaden to diverse models (including open-source) and quantify specialization profiles to inform orchestration.
- Credit and authorship norms: roles of human vs. AI contributions are described informally; no principled framework for attribution, accountability, or academic credit. Action: propose and test authorship and credit protocols for human–AI co-creation.
- Benchmarking and standardization: no standardized tasks, metrics, or protocols for “vibe reasoning” are offered. Action: release a public benchmark suite, evaluation harnesses, and standardized reporting checklists.
Practical Applications
Overview
Below are practical, real-world applications derived from the paper’s Vibe Reasoning paradigm—its findings, methods, and innovations. Each bullet specifies actionable use cases, sectors, potential tools/workflows, and key assumptions or dependencies. Applications are grouped into those deployable now versus those requiring further R&D or scaling.
Immediate Applications
The following applications can be deployed today with currently available models, tools (e.g., Python, notebooks, IDEs), and basic orchestration.
- AI research co-pilot for STEM labs (academia; software/AI research)
- Use case: Structure problem-solving sessions with generic meta-prompts (e.g., “enumerate small cases,” “verify with code,” “save to file”), tool-integrated code execution, and persistent “scratch-paper” files to track hypotheses and verified results.
- Tool/workflow: A “Vibe Notebook” extension for Jupyter/VS Code that enforces verification steps, auto-creates and maintains summary.md and proof_sketch.md, and routes tasks to specialized models (exploration vs proof).
- Assumptions/dependencies: Access to capable LLMs; sandboxed Python execution; storage for artifacts; minimal human oversight for when/what/how prompts.
- Reliable analytics and data science workflows (industry data teams; finance; energy; marketing)
- Use case: Hypothesis generation via LLM + automatic verification via code on small subsets; log all intermediate results in persistent files; auto-flag claims lacking code-backed checks.
- Tool/workflow: “Trust-but-verify” pipelines in notebooks: meta-prompt templates, test/data generators, result logging, cross-model checks for conclusions.
- Assumptions/dependencies: Clean data access; CI-like testing; model router; compute budget for repeated verification.
- Software engineering pair programming with enforced verification (software)
- Use case: LLM generates code/design ideas; automated unit tests and static analysis verify; persistent design notes capture decisions; route to specialized models (creative generation vs rigorous checker).
- Tool/workflow: IDE plug-in that injects vibe meta-prompts (“write tests first,” “prove invariants,” “store rationale”), runs code in a sandbox, and uses a secondary verifier model.
- Assumptions/dependencies: Integration with test frameworks; static analyzers; security sandbox; model orchestration API.
- Education: Socratic math and CS tutors with code-grounded verification (education)
- Use case: Tutors guide students with generic prompts (“try special cases,” “visualize,” “verify with code”), auto-generate ASCII or plot visualizations, and store learning artifacts for spaced review.
- Tool/workflow: Classroom LMS plugin or student app with meta-prompt scaffolding, code execution cells, and two-model mode (explainer vs checker).
- Assumptions/dependencies: Safe code environments; curriculum integration; educators’ acceptance of meta-prompt pedagogy.
- Compliance, audit, and technical writing with verifiable artifacts (policy; regulated industries)
- Use case: Draft policies or technical reports where every quantitative claim is tagged with a verification cell, data source, and stored trace; use different models for creative synthesis vs rigorous cross-check.
- Tool/workflow: “ProofTrace” document system embedding executable cells; model router for generation and verification; auto-generated audit trails.
- Assumptions/dependencies: Access to source data; governance over data provenance; sign-off workflows.
- Decision support in operations and logistics (industry; supply chain)
- Use case: LLM proposes heuristics for routing/scheduling; MILP/CP-SAT solver verifies feasibility/optimality on small instances; results and failures recorded to guide model pivots.
- Tool/workflow: Hybrid planner integrating LLM ideation, solver verification, and file-based memory for scenario comparisons.
- Assumptions/dependencies: Solver integration; representative test instances; human timing for phase transitions.
- Personal assistants with “verify-first” planning (daily life)
- Use case: Plan travel/finances with meta-prompts (“simulate costs,” “check calendar conflicts,” “save comparison”), and run simple scripts or API checks; maintain a scratch file of vetted decisions.
- Tool/workflow: Assistant app with verification steps, API calls (calendar, maps, budgets), and persistence.
- Assumptions/dependencies: API access; privacy controls; basic scripting capabilities.
Long-Term Applications
These applications require additional research, standardization, safety validation, model reliability improvements, or domain-specific integration before broad deployment.
- Autonomous scientific discovery platforms using vibe orchestration (academia; pharmaceuticals; materials; energy)
- Use case: Multi-agent systems that generate hypotheses, design experiments, run code/simulations, store artifacts, and pivot strategies without heavy human guidance.
- Potential product: “VibeOS” for scientific agents—an orchestration layer combining meta-prompt libraries, memory, verification tooling, and task-model routing.
- Assumptions/dependencies: More reliable self-evaluation; robust simulators/labs; safety constraints; reproducibility standards.
- Safety-critical decision support with formal verification (healthcare; robotics; energy grids; aviation)
- Use case: Split creative and rigorous roles—LLM proposes care plans or control policies; formal methods/verifiers (e.g., model checking, theorem provers, certified solvers) validate constraints before deployment.
- Potential tools: Clinical co-pilots with guideline provers; robot planners with formal safety guarantees; grid optimizers blending LLM heuristics with proof-backed feasibility checks.
- Assumptions/dependencies: High-precision domain models; regulatory compliance; formal verification integration; fail-safe execution environments.
- Regulatory standards for AI “proof-of-capability” artifacts (policy; governance)
- Use case: Require executable traces, verification logs, and independent model checks for high-stakes AI outputs (finance trades, medical recommendations, legal analyses).
- Potential policy: Certification profiles specifying agentic grounding (code execution, memory), model orchestration, and minimum verification coverage.
- Assumptions/dependencies: Public/private sector consensus; auditing infrastructure; independent model diversity to avoid correlated errors.
- Industry-wide multi-model routers and task taxonomies (software; platforms)
- Use case: Standardized routing frameworks that classify tasks (exploration vs proof vs retrieval) and select best-in-class models accordingly.
- Potential tools: RouterBench-like services with telemetry on error modes and success rates; SLAs for task-model matching.
- Assumptions/dependencies: Model capability profiling; API stability; reliability metrics.
- Curriculum and pedagogy built on meta-cognitive prompts (education)
- Use case: Teach students and professionals how/what/when to guide AI via generic meta-prompts; integrate verification-first practices and artifact tracking into coursework.
- Potential program: “Socratic AI Literacy” modules in STEM and policy programs; instructor toolkits for vibe-based assignments.
- Assumptions/dependencies: Teacher training; assessment methods; accessible compute tools.
- Legal and contract drafting with multi-model verification (legal)
- Use case: Generative drafting paired with precedent and clause-compliance checkers; maintain persistent case files and reasoning artifacts to trace obligations and risks.
- Potential tools: Contract copilot with embedded verification cells, clause libraries, and independent checker models.
- Assumptions/dependencies: High-quality legal corpora; jurisdiction-aware verifiers; audit-friendly artifact storage.
- Finance: model risk management with agentic grounding (finance)
- Use case: LLM-generated investment rationales verified by quantitative engines; store risk calculations and stress tests; orchestrate models for narrative vs numeric rigor.
- Potential tools: Portfolio co-pilots with executable risk notebooks and independent model ensembles to reduce correlated hallucinations.
- Assumptions/dependencies: Market data access; robust quantitative libraries; regulatory alignment.
- Cross-domain AI memory and provenance systems (software; platforms)
- Use case: Standardized file-based memory formats for long-running AI projects, enabling cross-session coherence, hand-offs between models, and reproducibility.
- Potential tools: Artifact registries; provenance dashboards linking prompts, code, outputs, and decisions.
- Assumptions/dependencies: Data governance; interoperability standards; storage and versioning.
- Large-scale optimization with LLM-generated heuristics (energy; logistics; telecommunications)
- Use case: LLMs propose structure-aware heuristics (e.g., “residue blocks” analogs) for specific problem families; validators test on representative instances; insights codified into production solvers.
- Potential tools: Heuristic discovery platforms blending exploratory LLMs with solver-backed verification and benchmarking suites.
- Assumptions/dependencies: Domain datasets; solver integration and benchmarking infra; organizational adoption.
Cross-cutting assumptions and dependencies
- Access to frontier or capable models and APIs, ideally with diversity (to reduce correlated errors).
- Secure, sandboxed code execution and reliable tool integrations (solvers, analyzers, domain APIs).
- Persistent memory and artifact management (files, registries) for cross-session coherence and auditability.
- Human oversight for meta-level “how/what/when” judgments until self-evaluation improves.
- Compute resources and CI-like verification budgets; privacy/security for sensitive data.
- Domain-specific verifiers or formal methods for safety-critical deployments.
- Organizational workflows and incentives that value verification-first practices and rigorous provenance.
Glossary
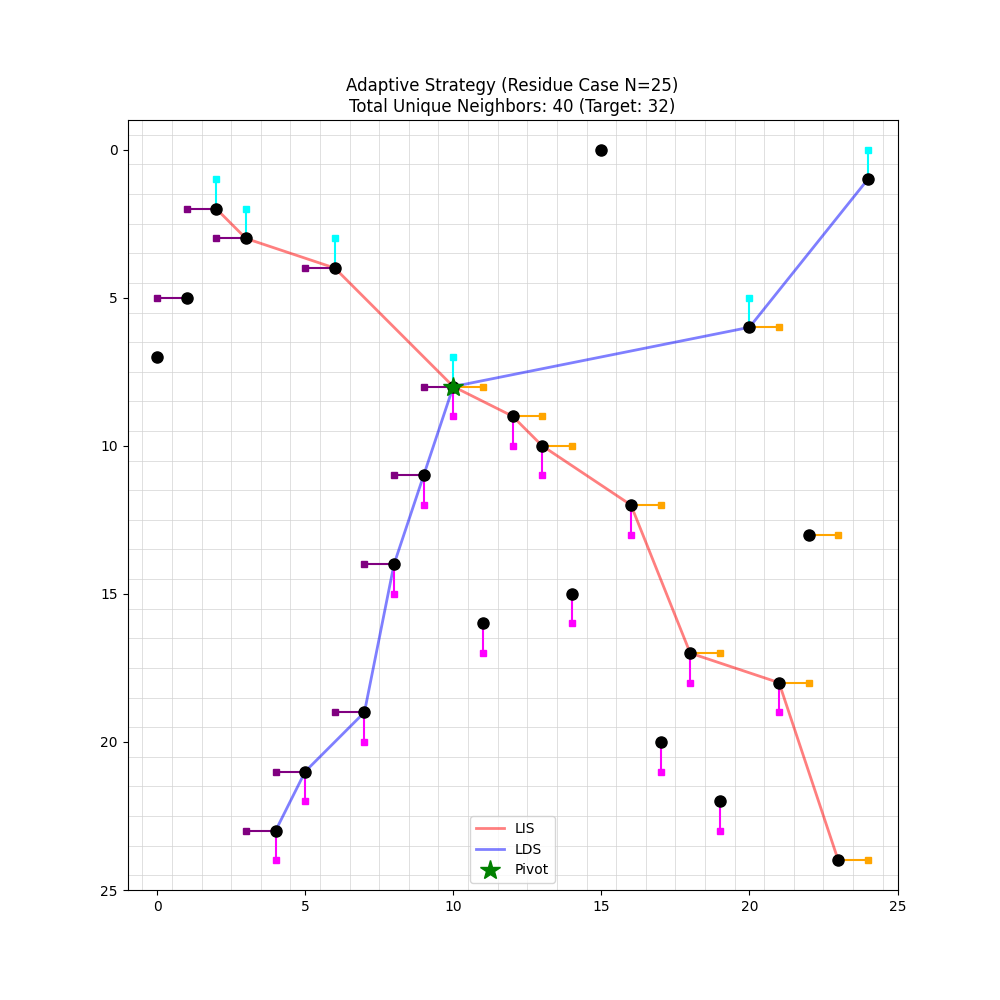
- Adaptive Orthogonal Fanning: A specific constructive strategy that selects cells in orthogonally “fanned” directions to enforce the fooling-set property. "Testing ``Adaptive Orthogonal Fanning'' strategy: for with 100 random permutations, 98\% success rate; for , the random permutation result of 40 far exceeds the lower bound 32; for the residue permutation (), 100\% success with Fooling Set size = 32."
- Agentic Grounding: The use of external tools (e.g., code and persistent files) to ground, verify, and structure AI reasoning beyond pure text generation. "(3) Agentic grounding: Python execution for computation/verification catches hallucinations by testing conjectures and validating constructions. File-based memory compensates for limited context windows, enabling coherent multi-session reasoning."
- Agentic workflows: Tool-using AI processes that execute code and manage state/memory to carry out multi-step reasoning tasks. "leveraging agentic workflows with Python code execution and file-based memory, to derive both the correct answer (2112) and a rigorous mathematical proof."
- Backtracking: A systematic search technique that incrementally builds candidates and abandons them when they violate constraints. "I'll write an exact enumeration script using backtracking..."
- Communication complexity: A field studying the amount of communication required to compute functions; here, it provides the fooling-set framework for lower bounds. "as well as the Fooling Set framework from communication complexity that require broad mathematical training."
- Context windows: The maximum span of text a model can attend to at once; limited windows constrain long, multi-session reasoning. "File-based memory compensates for limited context windows, enabling coherent multi-session reasoning."
- Cross-Free Set: An alternative name for a fooling set, where pairwise “crossing” rectangles are forbidden. "I'll use the Fooling Set (or Cross-Free Set) method:"
- Erdős–Szekeres theorem: A combinatorial theorem relating sequence length to LIS/LDS sizes; used to derive a bound. "The lower bound proof requires connecting the problem to the Erd\H{o}s-Szekeres theorem, which lies in the tail of standard mathematical knowledge distributions, as well as the Fooling Set framework from communication complexity that require broad mathematical training."
- Exhaustive search: Trying all possibilities to find an exact solution; quickly infeasible in large combinatorial spaces. "Yet even with code execution, exhaustive search becomes infeasible for rather small (e.g., ), leaving only a handful of data points for pattern recognition."
- File-based memory: Persisting notes and results in files to maintain context across long or multi-model sessions. "File-based memory compensates for limited context windows, enabling coherent multi-session reasoning."
- Fooling Set: A set of cells guaranteeing that no single rectangle can cover two of them; its size lower-bounds the number of rectangles needed. "I'll use the Fooling Set (or Cross-Free Set) method:"
- Foundation models: Large pretrained models that serve as general-purpose reasoners across tasks. "Vibe Reasoning fundamentally depends on sufficiently capable foundation models."
- Geometric intuition: Insight derived from spatial or visual structure, essential here for patterns like LIS/LDS axes and tiling layouts. "Geometric intuition is essential."
- Hallucinations: Confident but incorrect model outputs that require external verification to detect. "Python execution for computation/verification catches hallucinations by testing conjectures and validating constructions."
- Longest Decreasing Subsequence (LDS): The longest subsequence of a permutation with strictly decreasing values; paired with LIS in the proof. "the geometric interpretation of longest increasing/decreasing subsequences (LIS/LDS) as coordinate axes in the grid"
- Longest Increasing Subsequence (LIS): The longest subsequence of a permutation with strictly increasing values; central to applying Erdős–Szekeres. "the geometric interpretation of longest increasing/decreasing subsequences (LIS/LDS) as coordinate axes in the grid"
- Model orchestration: Coordinating multiple models, each used where its strengths best fit the subtask. "(4) Model orchestration: deploying different models for different subtasks."
- Model specialization: Recognizing and exploiting distinct strengths and weaknesses across models. "GPT-5 proof failures; identified model specialization need."
- Orthogonal Fanning: A structured selection of cells “fanning” out horizontally and vertically along LIS/LDS to enforce crossings. "Using the ``Orthogonal Fanning'' strategy based on the Longest Increasing Subsequence (LIS) and Longest Decreasing Subsequence (LDS)."
- Permutation matrix: A binary matrix with exactly one 1 in each row and column, representing a permutation (here, the hole positions). "The holes form a permutation matrix, try thinking about LIS/LDS"
- Python execution: Running Python code from within the workflow to compute, verify, and visualize constructions. "Python execution for computation/verification catches hallucinations by testing conjectures and validating constructions."
- Residue block: A block-structured pattern in optimal permutations, grouped by modular residues, that yields minimal tilings. "the ``residue block'' pattern in optimal permutations"
- Residue permutation: A specific permutation exhibiting the residue-block structure used for constructive and verification purposes. "for the residue permutation (), 100\% success with Fooling Set size = 32."
- Search space pruning: Focusing exploration on promising subspaces (e.g., perfect squares) to find tractable patterns. "This is an example of search space pruning---the AI has data for many values, but lacks the judgment to identify which subset holds the key insight."
- Socratic meta-prompts: Generic, domain-agnostic instructions that induce reflection and verification without giving solutions. "Socratic meta-prompts---generic directives like ``verify with code'' that prompt AI reflection without revealing solutions"
- Vibe Reasoning: A human-AI collaborative paradigm where minimal, generic guidance elicits and grounds AI’s latent capabilities. "We introduce Vibe Reasoning, a human-AI collaborative paradigm for solving complex mathematical problems."
Collections
Sign up for free to add this paper to one or more collections.