- The paper introduces a Bayesian framework for evolving LLM agent harness skills using posterior evidence to guide reliable skill updates.
- It employs benchmark-verified feedback and interpretable repair actions (explore, patch, split, compress, retire) to improve procedural accuracy and cost efficiency.
- Experimental results reveal significant accuracy gains across diverse benchmarks, underscoring the framework’s backend-agnostic applicability.
Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
Motivation and Context
The increasing sophistication of LLM agents has shifted the performance bottleneck from model weights to the agent harness, encapsulating prompts, SOPs, tool interfaces, and skills. Modern harnesses determine agent reliability and failure characteristics, yet updates to these assets are typically guided by ad hoc heuristics or uncalibrated reflection mechanisms. The Bayesian-Agent framework formalizes the treatment of skills and SOPs as evidence-based hypotheses, advancing from heuristic prompt/skill accumulation to auditable, posterior-guided evolution under uncertainty. This paradigm reframes skill maintenance as a Bayesian inference and decision policy problem, orthogonal to model parameter optimization.
Bayesian Skill Evolution Framework
Bayesian-Agent introduces a categorical Bayesian evidence model tied to reusable harness assets. For each skill, the system collects verified trajectories derived from benchmark-type feedback, instantiates feature-conditioned posteriors over observed successes and failures, and grounds all harness edits in this Bayesian belief state. The evidence aggregation is explicitly context and feature-bucketed, capturing granular mode and cost statistics and supporting robust posterior inference even in sparse regimes.
The Bayesian decision layer exposes a compact set of skill-edit actions: explore, patch, split, compress, and retire, determined by interpretable policy thresholds on accumulated evidence and posterior estimates. These actions operationalize the belief state, turning repeated failure signatures into model-facing patches/guardrails, or triggering skill compression and retirement when statistical support demands. Critically, all evidence is benchmark-verified and auditably separated from model self-assessment, preventing premature or noisy updates within the harness.
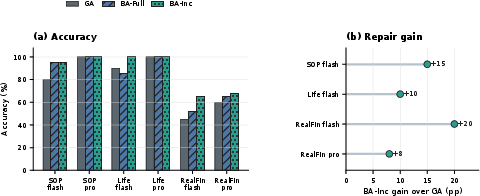
Figure 1: Visual analysis of Bayesian-Agent on DeepSeek backbones. Panel (a) compares GA, BA-Full, and BA-Inc accuracy across benchmark-model settings. Panel (b) summarizes BA-Inc's final accuracy gain over GA for the non-zero repair settings.
The backend-agnostic design supports native execution and adapters for existing harnesses (GenericAgent, mini-swe-agent, Claude Code), provided they yield verifiable trajectories and support skill-context injection.
Empirical Evaluation and Results
The experimental suite spans SOP-Bench, Lifelong AgentBench, and RealFin-Bench, combined with both DeepSeek and Claude model backbones. Evaluation protocols include three arms:
- GenericAgent (GA): Baseline execution without Bayesian skill adaptation.
- Bayesian-Agent Full (BA-Full): Online, from-scratch, posterior-guided registry evolution.
- Bayesian-Agent Incremental (BA-Inc): Posterior-guided repair applied only to failures of a baseline GA run.
The results show robust accuracy improvements via BA-Inc and BA-Full, particularly in settings with high procedural error rates and nontrivial recurring failure modes. On deepseek-v4-flash, BA-Full lifts SOP-Bench from 80% to 95% accuracy and RealFin-Bench from 45% to 52%, with incremental repair (BA-Inc) realizing up to 65% on RealFin-Bench (an improvement of +20 points over GA). Lifelong AgentBench is taken from 90% (GA) to 100% final accuracy via targeted incremental repair. Stronger model backbones cause saturation (GA and BA variants all 100%), highlighting the calibration of benefit to the presence of recoverable procedural errors in the skill substrate.
Backend Ablation and Generality
A four-way backend ablation covering native, GenericAgent, mini-swe-agent, and Claude Code demonstrates that Bayesian-Agent's evidence logic is not harness- or model-specific; any system with verifiable error signals and skill-context injection capability is directly compatible. Across all harnesses, posterior-guided repair provides accuracy gains wherever recoverable failures remain after the baseline pass.
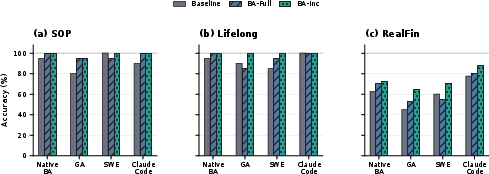
Figure 2: Backend ablation on deepseek-v4-flash. Native BA, GenericAgent (GA), mini-swe-agent (SWE), and Claude Code compare baseline, BA-Full, and BA-Inc final accuracy.
The agent does not rely on idiosyncrasies of any agent runtime, and repair policies act on local evidence rather than global model affordances. This separation is a critical property for maintaining evidence locality and debugability, supporting robust cross-system deployment.
Cost Analysis and Policy Dynamics
Token accounting across benchmarks establishes the repair cost dynamics: BA-Inc supplements the initial run with targeted repair tokens (as low as 84k for full recovery on Lifelong AgentBench, 2.02M on RealFin-Bench). The cumulative approach (adding initial baseline cost) contextualizes end-to-end efficiency and supports explicit trade-off reasoning in system deployment.
The tendency for BA-Full to underperform GA in some full-mode online settings (e.g., Lifelong AgentBench on flash) is diagnostic and underscores the impact of sparse-ordering effects and the necessity for cautious, auditable policy design. The Bayesian layer preserves conservative policy defaults and explicit posterior tracking, emphasizing transparency and debuggability.
Interpretability: Traceable Skill Evolution
Every Bayesian skill action and harness edit is explained by explicit before/after posterior audit trails, linking task outcomes, evidence features, and policy-driven skill modifications (“patch”, “retire”, etc.). This provides an interpretable provenance of all harness changes, supports at-a-glance inspection of evolving guardrails or compressed skills, and captures recurrent negative cases where further repair is unwarranted and “retirement” is indicated.
Implications and Future Directions
The Bayesian-Agent approach represents a shift toward explicit, evidence-calibrated harness evolution, with agent reliability rooted in observable, auditable statistics rather than opaque or self-referential skill updates. By making skill adjustment a probabilistic, context-sensitive policy problem, this framework enables robust skill reuse, repair, and compression across long agent deployments. This methodology aligns with an emerging consensus in LLM agent design: future performance ceilings are determined less by weights and more by the intelligent management of harness assets.
Theoretically, the formal Bayesian approach—distinguishing prior, likelihood, and posterior over skill success—opens opportunities for richer, structured decision policies including hierarchical evidence models, skill transfer incentives, and multi-agent belief sharing. From a practical perspective, the auditability of all actions and the generality of the backend interface position Bayesian-Agent as a foundation for standardized, evidence-driven agent improvement protocols.
Conclusion
Bayesian-Agent systematizes skill and SOP evolution for LLM agents through a posterior-guided framework, replacing heuristic- or reflection-centric updates with calibrated, interpretable, and auditable policies. Empirical evidence demonstrates reliable performance gains in non-saturated settings, cost efficiency in incremental repair, and backend-agnostic applicability. The framework incorporates interpretability as a first-class concern, positioning agent harness maintenance as an explicit probabilistic reasoning problem. This work establishes a direction for future agent engineering: reliable, efficient, and interpretable skill evolution predicated on rigorous evidence accumulation and Bayesian inference.
References
See (2606.08348) for full details and source code.